") Python爬蟲繞過登錄的小技巧
Python爬蟲繞過登錄的小技巧
前言
很多時(shí)候我們做 Python 爬蟲時(shí)或者自動(dòng)化測試時(shí)需要用到 selenium 庫,我們經(jīng)常會(huì)卡在登錄的時(shí)候,登錄驗(yàn)證碼是最頭疼的事情,特別是如今的文字驗(yàn)證碼和圖形驗(yàn)證碼。文字和圖形驗(yàn)證碼還加了干擾線,本文就來講講怎么繞過登錄頁面。
登錄頁面的驗(yàn)證,比如以下的圖形驗(yàn)證碼。
還有我們基本都看過的 12306 的圖形驗(yàn)證碼。
繞過登錄方法
繞過登錄基本有兩種方法,第一種方法是登錄后查看網(wǎng)站的 cookie,請求 url 的時(shí)候把 cookie 帶上,第二種方法是啟動(dòng)瀏覽器帶上瀏覽器的全部信息,包括添加的書簽和訪問網(wǎng)頁的 cookie 信息。
第一種 cookie 方法我們要分析別人網(wǎng)站的 cookie 值,找出相應(yīng)的值然后添加進(jìn)去,對于我們不熟的網(wǎng)站,他們可能也會(huì)做加密或者動(dòng)態(tài)處理,所以有些網(wǎng)站也不是那么好操作。如果是自己公司的網(wǎng)站需要測試,我們可以詢問對應(yīng)的開發(fā)那個(gè) cookie 值是區(qū)分獨(dú)立用的值,拿出來放在請求里面就行。
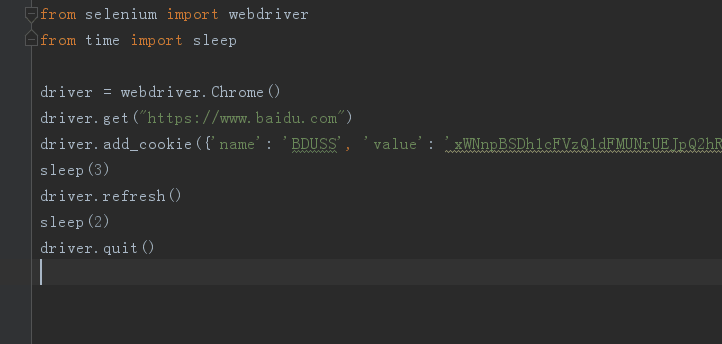
添加 cookie 繞過登錄
比如我們登錄百度賬號(hào)比較費(fèi)勁,每次都需要登錄也比較繁瑣,我們 F12 打開頁面調(diào)試工具,登錄后找到 www.baidu.com 文件,在 cookie 中,我們發(fā)現(xiàn)很多值,其中圖中圈起來的就是我們要找的值。
我們在訪問 baidu 鏈接的時(shí)候加上這個(gè) cookie 值,這樣就是直接登錄后的百度賬號(hào)了。
下載瀏覽器驅(qū)動(dòng)
我們要 selenium 啟動(dòng)瀏覽器時(shí),需要下載后對應(yīng)的驅(qū)動(dòng)文件并放在 Python 安裝的根目錄下,比如我會(huì)用到谷歌 Chrome 瀏覽器和 Firefox 火狐瀏覽器。

谷歌瀏覽器驅(qū)動(dòng)下載地址:
http://chromedriver.storage.googleapis.com/index.html
火狐瀏覽器驅(qū)動(dòng)下載地址:
https://github.com/mozilla/geckodriver/releases/
啟動(dòng) Chrome 瀏覽器繞過登錄
我們每次打開瀏覽器做相應(yīng)操作時(shí),對應(yīng)的緩存和 cookie 會(huì)保存到瀏覽器默認(rèn)的路徑下,我們先查看個(gè)人資料路徑,以 chrome 為例,我們在地址欄輸入 chrome://version/

圖中的個(gè)人資料路徑就是我們需要的,我們?nèi)サ艉竺娴?Default,然后在路徑前加上「–user-data-dir=」就拼接出我們要的路徑了。
profile_directory=r'--user-data-dir=C:UsersxxxAppDataLocalGoogleChromeUserData'
接下來,我們啟動(dòng)瀏覽器的時(shí)候采用帶選項(xiàng)時(shí)的啟動(dòng),這種方式啟動(dòng)瀏覽器需要注意,運(yùn)行代碼前需要關(guān)閉所有的正在運(yùn)行 chrome 程序,不然會(huì)報(bào)錯(cuò)。全部代碼如下。

selenium 自動(dòng)化啟動(dòng)瀏覽器后我們會(huì)發(fā)現(xiàn)我之前保存的書簽完整在瀏覽器上方,baidu 賬號(hào)也是登錄的狀態(tài)。
啟動(dòng) Firfox 瀏覽器繞過登錄
Firfox 火狐瀏覽也可以這樣啟動(dòng)它,設(shè)置略有不同。
首先,查看配置文件的存儲(chǔ)路徑,查看方法:幫助–故障排除信息–配置文件夾,把里面的路徑復(fù)制過來就行。
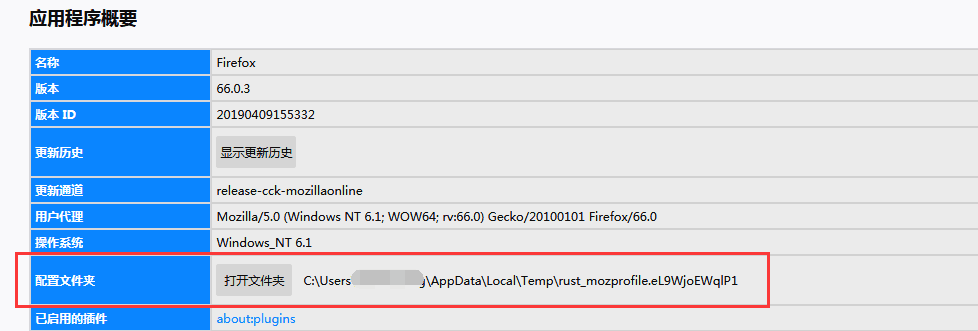
同樣,我們把路徑放在變量中。
profile_path=
我們也在火狐瀏覽器中登錄好百度的賬號(hào),用 selenium 自動(dòng)化啟動(dòng)帶配置文件的火狐瀏覽器,也會(huì)發(fā)現(xiàn)啟動(dòng)時(shí)已經(jīng)啟動(dòng)了瀏覽器安裝的插件和登錄好的百度賬號(hào)。
繞過圖形驗(yàn)證碼的網(wǎng)站
文中第一個(gè)圖是簡書登錄時(shí)的圖形驗(yàn)證碼,我們登錄簡書后(cookie 有一定的時(shí)效,貌似有 10 天半個(gè)月左右),把上面代碼中的鏈接換成簡書的,再用上面的方法覺可以實(shí)現(xiàn)繞過登錄頁的圖形驗(yàn)證碼。
比如我直接打開我的簡書個(gè)人主頁
https://www.jianshu.com/u/52353ffa8b86
自動(dòng)化啟動(dòng)后也是保留了登錄的狀態(tài)。
網(wǎng)站的登錄大門已被打開,接下來就可以做自己想做的事情了,比如爬蟲、自動(dòng)化測試驗(yàn)證之類的。
PS:以上技巧對有些網(wǎng)站可能不管用,但是對大部分網(wǎng)站還有適用的,覺得本文小技巧有用的自己趕緊試試吧。
-
瀏覽器
+關(guān)注
關(guān)注
1文章
1040瀏覽量
36119 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86268 -
爬蟲
+關(guān)注
關(guān)注
0文章
83瀏覽量
7394
原文標(biāo)題:講講Python爬蟲繞過登錄的小技巧
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Python數(shù)據(jù)爬蟲學(xué)習(xí)內(nèi)容
Python爬蟲與Web開發(fā)庫盤點(diǎn)
0基礎(chǔ)入門Python爬蟲實(shí)戰(zhàn)課
Python爬蟲簡介與軟件配置
python網(wǎng)絡(luò)爬蟲概述


python爬蟲入門教程之python爬蟲視頻教程分布式爬蟲打造搜索引擎
python爬蟲框架有哪些
Python爬蟲:使用哪種協(xié)議的代理IP最佳?
python實(shí)現(xiàn)簡單爬蟲的資料說明






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論