") 谷歌研究人員利用3D卷積網(wǎng)絡(luò)打造視頻生成新系統(tǒng)
谷歌研究人員利用3D卷積網(wǎng)絡(luò)打造視頻生成新系統(tǒng)

谷歌研究人員利用3D卷積網(wǎng)絡(luò)打造視頻生成新系統(tǒng),只需要視頻的第一幀和最后一幀,就能生成完整合理的整段視頻,是不是很神奇?
漫畫書秒變動(dòng)畫片了解一下?
想象一下,現(xiàn)在你的手中有一段視頻的第一幀和最后一幀圖像,讓你負(fù)責(zé)把中間的圖像填進(jìn)去,生成完整的視頻,從現(xiàn)有的有限信息中推斷出整個(gè)視頻。你能做到嗎?
這可能聽起來像是一項(xiàng)不可能完成的任務(wù),但谷歌人工智能研究部門的研究人員已經(jīng)開發(fā)出一種新系統(tǒng),可以由視頻第一幀和最后一幀生成“似是而非的”視頻序列,這個(gè)過程被稱為“inbetween”。
“想象一下,如果我們能夠教一個(gè)智能系統(tǒng)來將漫畫自動(dòng)變成動(dòng)畫,會(huì)是什么樣子?如果真實(shí)現(xiàn)了這一點(diǎn),無疑將徹底改變動(dòng)畫產(chǎn)業(yè)。“該論文的共同作者寫道。“雖然這種極其節(jié)省勞動(dòng)力的能力仍然超出目前最先進(jìn)的水平,但計(jì)算機(jī)視覺和機(jī)器學(xué)習(xí)技術(shù)的進(jìn)步正在使這個(gè)目標(biāo)的實(shí)現(xiàn)越來越接近。”
原理與模型結(jié)構(gòu)
這套AI系統(tǒng)包括一個(gè)完全卷積模型,這是是受動(dòng)物視覺皮層啟發(fā)打造的深度神經(jīng)網(wǎng)絡(luò),最常用于分析視覺圖像。它由三個(gè)部分組成:2D卷積圖像解碼器,3D卷積潛在表示生成器,以及視頻生成器。
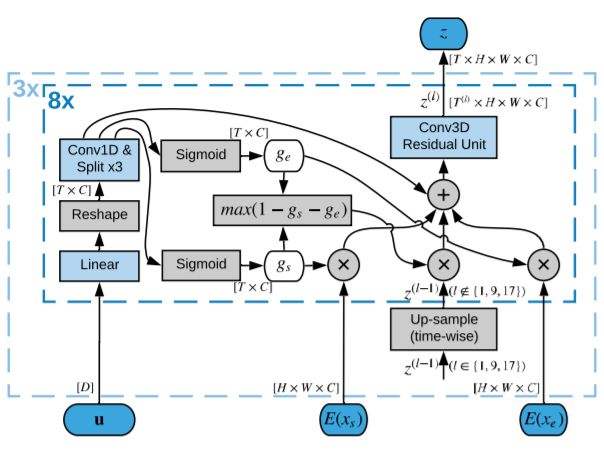
圖1:視頻生成模型示意圖
圖像解碼器將來自目標(biāo)視頻的幀映射到潛在空間,潛在表示生成器學(xué)習(xí)對(duì)包含在輸入幀中的信息進(jìn)行合并。最后,視頻生成器將潛在表示解碼為視頻中的幀。
研究人員表示,將潛在表示生成與視頻解碼分離對(duì)于成功實(shí)現(xiàn)中間視頻至關(guān)重要,直接用開始幀和結(jié)束幀的編碼表示生成視頻的結(jié)果很差。為了解決這個(gè)問題,研究人員設(shè)計(jì)了潛在表示生成器,對(duì)幀的表示進(jìn)行融合,并逐步增加生成視頻的分辨率。
圖2:模型生成的視頻幀序列圖,對(duì)于每個(gè)數(shù)據(jù)集上方的圖表示模型生成的序列,下方為原視頻,其中首幀和尾幀用于生成模型的采樣。
實(shí)驗(yàn)結(jié)果
為了驗(yàn)證該方法,研究人員從三個(gè)數(shù)據(jù)集中獲取視頻 - BAIR機(jī)器人推送,KTH動(dòng)作數(shù)據(jù)庫和UCF101動(dòng)作識(shí)別數(shù)據(jù)集 - 并將這些數(shù)據(jù)下采樣至64 x 64像素的分辨率。每個(gè)樣本總共包含16幀,其中的14幀由AI系統(tǒng)負(fù)責(zé)生成。
研究人員為每對(duì)視頻幀運(yùn)行100次模型,并對(duì)每個(gè)模型變量和數(shù)據(jù)集重復(fù)10次,在英偉達(dá)Tesla V100顯卡平臺(tái)上的訓(xùn)練時(shí)間約為5天。結(jié)果如下表所示:

表1:我們報(bào)告了完整模型和兩個(gè)基線的平均FVD,對(duì)每個(gè)模型和數(shù)據(jù)集重復(fù)10次,每次運(yùn)行100個(gè)epoch,表中FVD值越低,表示對(duì)應(yīng)生成視頻的質(zhì)量越高。
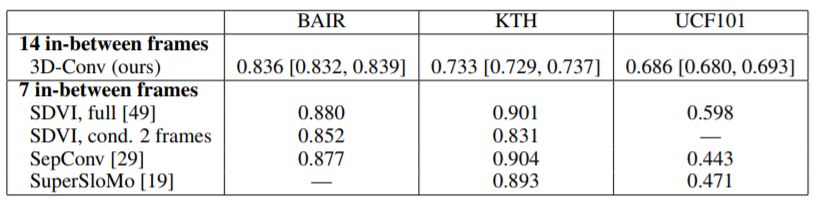
表2:使用直接3D卷積和基于的替代方法的模型的平均SSIM
RNN(SDVI)或光流(SepConv和SuperSloMo),數(shù)值越高越好。
研究人員表示,AI生成的視頻幀序列在風(fēng)格上與給定的起始幀和結(jié)束幀保持一致,而且看上去說得通。“令人驚喜的是,這種方法可以在如此長的時(shí)間段內(nèi)實(shí)現(xiàn)視頻生成,”該團(tuán)隊(duì)表示,“這可能給未來的視頻生成技術(shù)研究提供了一個(gè)有用的替代視角。”
-
解碼器
+關(guān)注
關(guān)注
9文章
1173瀏覽量
41907 -
谷歌
+關(guān)注
關(guān)注
27文章
6231瀏覽量
107995 -
智能系統(tǒng)
+關(guān)注
關(guān)注
2文章
407瀏覽量
73271
原文標(biāo)題:谷歌AI動(dòng)畫接龍:只用頭尾兩幀圖像,片刻生成完整視頻!
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
4K、多模態(tài)、長視頻:AI視頻生成的下一個(gè)戰(zhàn)場,誰在領(lǐng)跑?
NVIDIA助力影眸科技3D生成工具Rodin升級(jí)
騰訊混元3D AI創(chuàng)作引擎正式上線
阿里云通義萬相2.1視頻生成模型震撼發(fā)布
OpenAI暫不推出Sora視頻生成模型API
中國電信發(fā)布自研視頻生成大模型
OpenAI推出AI視頻生成模型Sora
OpenAI開放Sora視頻生成模型
Google DeepMind發(fā)布Genie 2:打造交互式3D虛擬世界
卷積神經(jīng)網(wǎng)絡(luò)的實(shí)現(xiàn)工具與框架
字節(jié)跳動(dòng)自研視頻生成模型Seaweed開放
今日看點(diǎn)丨Vishay裁員800人,關(guān)閉上海等三家工廠;字節(jié)跳動(dòng)發(fā)布兩款視頻生成大模型
火山引擎推出豆包·視頻生成模型
阿里通義將發(fā)布視頻生成大模型
歡創(chuàng)播報(bào) 騰訊元寶首發(fā)3D生成應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論