") CVPR 2019競(jìng)賽第一解決方案分享
CVPR 2019競(jìng)賽第一解決方案分享
CVPR 2019細(xì)粒度圖像分類workshop的挑戰(zhàn)賽公布了最終結(jié)果:中國(guó)團(tuán)隊(duì)DeepBlueAI獲得冠軍。本文帶來(lái)冠軍團(tuán)隊(duì)解決方案的技術(shù)分享。
近日,在Kaggle上舉辦的CVPR 2019 Cassava Disease Classification挑戰(zhàn)賽公布了最終結(jié)果,國(guó)內(nèi)團(tuán)隊(duì) DeepBlueAI 獲得冠軍。
國(guó)際計(jì)算機(jī)視覺(jué)與模式識(shí)別會(huì)議(CVPR)是IEEE一年一度的學(xué)術(shù)性會(huì)議,CVPR是世界頂級(jí)的計(jì)算機(jī)視覺(jué)會(huì)議之一,會(huì)議的主要內(nèi)容是計(jì)算機(jī)視覺(jué)與模式識(shí)別技術(shù)。CVPR 2019 在洛杉磯長(zhǎng)灘舉行,F(xiàn)GVC6 Workshop也將作為 CVPR 2019 的一部分如期召開(kāi)。FGVC6 Workshop 共有十個(gè)挑戰(zhàn)賽,每個(gè)都代表了細(xì)粒度視覺(jué)分類在某個(gè)細(xì)分領(lǐng)域的挑戰(zhàn)。
FGVC全稱為Fine-Grained Visual Categorization,細(xì)粒度圖像分類,即區(qū)分不同的動(dòng)物和植物、汽車和摩托車模型、建筑風(fēng)格等,是機(jī)器視覺(jué)社區(qū)剛剛開(kāi)始解決的最有趣和最有用的開(kāi)放問(wèn)題之一。細(xì)粒度圖像分類在于基本的分類識(shí)別(對(duì)象識(shí)別)和個(gè)體識(shí)別(人臉識(shí)別,生物識(shí)別)之間的連續(xù)性。相似的類別之間的視覺(jué)區(qū)別通常非常小,因此很難用當(dāng)今的通用識(shí)別算法來(lái)解決。
今年是FGVC舉辦的第六屆比賽,往屆比較著名的比賽諸如iNaturalist和iMaterialist,前者側(cè)重于區(qū)分自然界不同的生物,后者則是側(cè)重于區(qū)分不同的人造物體。
不同于傳統(tǒng)的廣義上的分類任務(wù),F(xiàn)GVC的挑戰(zhàn)致力于子類別的劃分,需要分類的對(duì)象之間更加相似,例如區(qū)分不同的鳥(niǎo)類、不同的植物、不同的日用品等。
賽題介紹
Cassava Disease Classification挑戰(zhàn)賽是一個(gè)根據(jù)木薯的葉子區(qū)分不同種類的木薯疾病的任務(wù)。Cassava 譯為木薯,是非洲第二大碳水化合物供應(yīng)者,因?yàn)槠淠軌虺惺軔毫拥沫h(huán)境。因此木薯是小農(nóng)種植的一種關(guān)鍵的糧食安全作物,在撒哈拉以南非洲,至少80%的小農(nóng)家庭種植木薯,而病毒性疾病是低產(chǎn)量的主要來(lái)源。
在這次比賽中,主辦方引入一個(gè)包含5種類別的木薯葉疾病的數(shù)據(jù)集,該數(shù)據(jù)集源于在烏干達(dá)定期調(diào)查中收集到的9436標(biāo)記圖像,主要從農(nóng)民在自家田地里拍攝的圖片,然后由國(guó)家作物資源研究所(NaCRRI)與Makarere大學(xué)的人工智能實(shí)驗(yàn)室共同對(duì)圖像進(jìn)行標(biāo)注。
數(shù)據(jù)集包括木薯植株的葉子圖像,9,436張帶注釋的圖像和12,595張未標(biāo)記的圖像。參與者可以選擇使用未標(biāo)記的圖像作為額外的訓(xùn)練數(shù)據(jù)。目標(biāo)是學(xué)習(xí)一個(gè)模型,使用訓(xùn)練數(shù)據(jù)中的圖像將給定的圖像分類為這4個(gè)疾病類別或健康葉子的類別。
團(tuán)隊(duì)成績(jī)
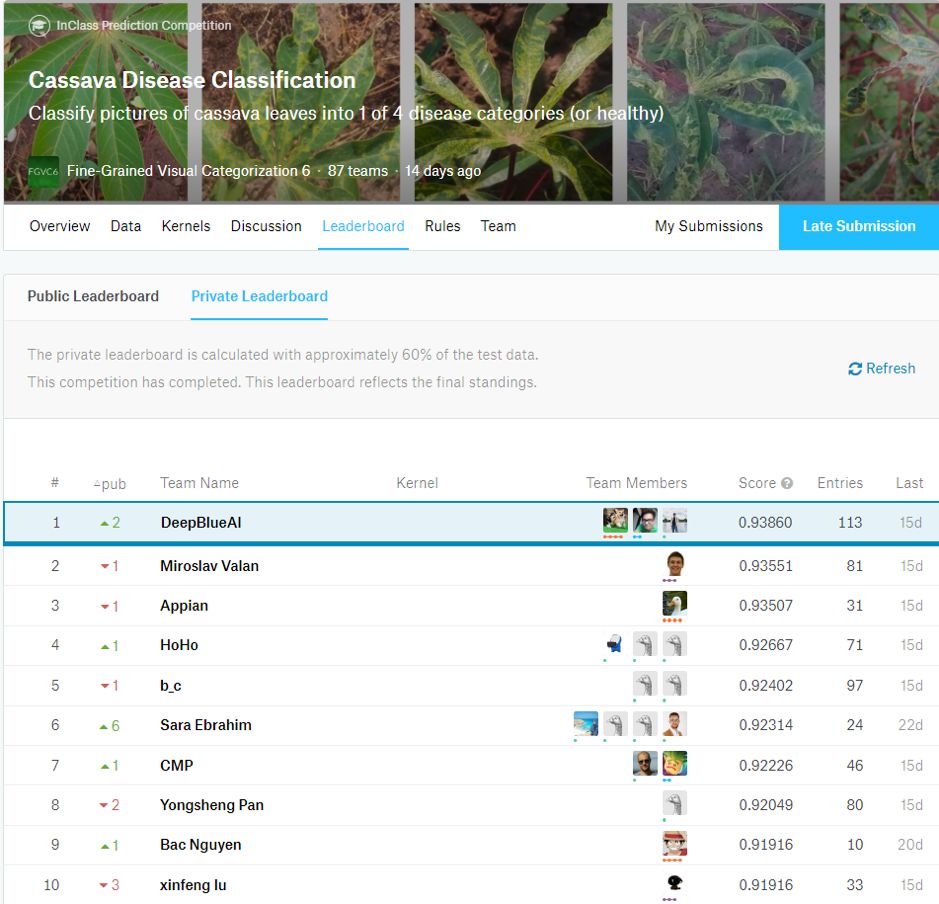
題目特點(diǎn)以及常用方法
細(xì)粒度圖像分類 (Fine-grained imagecategorization), 又被稱作子類別圖像分類 (Sub-category recognition)。其目的是對(duì)屬于同一基礎(chǔ)類別的圖像進(jìn)行更加細(xì)致的子類劃分, 但由于子類別間細(xì)微的類間差異以及較大的類內(nèi)差異, 更傳統(tǒng)的圖像分類任務(wù)相比, 細(xì)粒度圖像分類難度明顯要大很多。從下圖中的木薯的葉子可以看出,不同的葉子病變情況長(zhǎng)相非常相似,此外同一類別由于姿態(tài),背景以及拍攝角度的不同,存在較大的類內(nèi)差異。
細(xì)粒度圖像分類的常用方法可以分為兩種,分別是基于強(qiáng)監(jiān)督信息的方法和僅使用弱監(jiān)督信息的方法。前者需要使用對(duì)象的邊界框和局部標(biāo)注信息,后者僅使用類別標(biāo)簽,Cassava Disease Classification是一種弱監(jiān)督信息的細(xì)粒度識(shí)別,一般采用預(yù)訓(xùn)練模型finetune,并結(jié)合訓(xùn)練技巧對(duì)模型精調(diào)。
實(shí)驗(yàn)?zāi)P停篠ENet、ResNet、DenseNet
ResNet是CNN歷史上一個(gè)里程碑事件,模型深度達(dá)到了152層,這和之前CNN的層數(shù)完全不在一個(gè)量級(jí)上。ResNet中的identity的這條線類似一條電路上的短路(shortcuts,skip connection),使得模型學(xué)習(xí)更加容易,深層可以直接得到淺層的網(wǎng)絡(luò)特征。
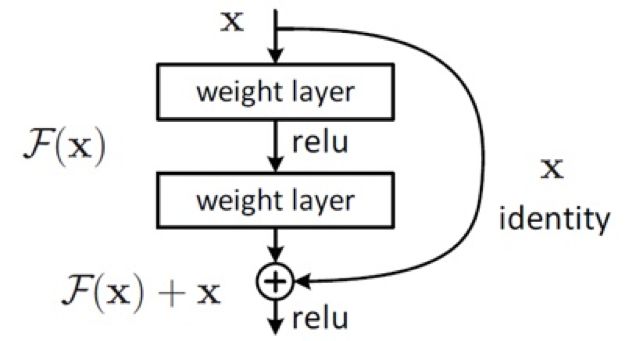
DenseNet的原理不同于ResNet通過(guò)加深網(wǎng)絡(luò)層數(shù)以及Inception通過(guò)加寬網(wǎng)絡(luò)寬度來(lái)提高模型識(shí)別能力,而是利用特征重用和類似ResNet的Bypass的方式,減少了網(wǎng)絡(luò)參數(shù)和緩解了梯度消失的問(wèn)題。

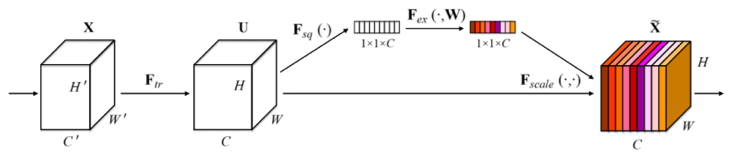
SENet提出了Sequeeze and Excitation block,該模塊于傳統(tǒng)網(wǎng)絡(luò)的最大區(qū)別在于其側(cè)重于構(gòu)建通道之間的依賴關(guān)系,利用global average pooling來(lái)Sequeeze特征圖,并用Excitation對(duì)前者進(jìn)行非線性變換,最后再疊加到輸入特征上。可以自適應(yīng)的校準(zhǔn)通道的相應(yīng)特征,并且該模塊可以嵌入到現(xiàn)有的網(wǎng)絡(luò)結(jié)構(gòu)中,實(shí)現(xiàn)精度的提升。
模型訓(xùn)練與評(píng)測(cè)
原圖 VerticalFlip HorizontalFlip RandomRotateRandomCrop
RandomErasing
CutOut
由于訓(xùn)練集樣本過(guò)少,對(duì)比分析后對(duì)輸入數(shù)據(jù)采取 VerticalFlip,HorizontalFilp 、RandomRotate和RandomCrop的增強(qiáng)操作。此外,還使用了RandomErasing和Cutout,方法會(huì)在原圖隨機(jī)選擇一些矩形區(qū)域,改變?cè)搮^(qū)域的像素值,通過(guò)這些數(shù)據(jù)增強(qiáng)的方式,訓(xùn)練集的圖片會(huì)被不同程度的遮擋,這樣可以進(jìn)一步降低過(guò)擬合的風(fēng)險(xiǎn)并提高模型的魯棒性。
同樣的,為了增強(qiáng)模型的魯棒性減少過(guò)擬合,本次比賽我們利用5-fold crossvalidation,交叉驗(yàn)證有效利用了有限的數(shù)據(jù),并且評(píng)估結(jié)果能夠盡可能接近模型在測(cè)試集上的表現(xiàn)。用crossvalidation之后,SE_ResNeXt50測(cè)試集準(zhǔn)確率提升0.01016,ResNet34測(cè)試集準(zhǔn)確率提升0.01142。

這次比賽中,我們還使用了Mixup和label smoothing的訓(xùn)練策略。Mixup顧名思義就是將兩張圖片按一定比例融合起來(lái)作為輸入,計(jì)算loss時(shí),針對(duì)兩張圖片的標(biāo)簽分別計(jì)算,然后按比例加權(quán)求和。Mixup是一種抑制過(guò)擬合的策略,通過(guò)增加了一些數(shù)據(jù)上的擾動(dòng),從而提升了模型的泛化能力。
實(shí)驗(yàn)證明,該方式能將Top1準(zhǔn)確率提高近一個(gè)百分點(diǎn)。對(duì)于分類問(wèn)題,常規(guī)做法時(shí)將類別換成one-hot vector。由于標(biāo)簽是類別的one-hot vector,這樣做易導(dǎo)致過(guò)擬合使得模型泛化能力下降;同時(shí)這種做法會(huì)將所屬類別和非所屬類別之間的差距盡可能大,因此很難調(diào)優(yōu)模型。
為此,可以用label smoothing對(duì)標(biāo)簽進(jìn)行平滑處理,軟化one-hot類型標(biāo)簽,使得計(jì)算損失函數(shù)時(shí)能有效抑制過(guò)擬合現(xiàn)象。
訓(xùn)練以Adam為optimiser,學(xué)習(xí)率的設(shè)置為階梯狀,共四個(gè)取值,[3e-4, 1e-4,1e-5, 1e-6],設(shè)置patience為4來(lái)衰減學(xué)習(xí)率,即模型連續(xù)4個(gè)epoch在驗(yàn)證集上效果沒(méi)有提升則衰減學(xué)習(xí)率,訓(xùn)練總的epcoh在20次左右。本實(shí)驗(yàn)使用的GPU為4卡2080Ti,并行訓(xùn)練一個(gè)模型,batchsize通常設(shè)為32,較大的模型根據(jù)實(shí)際情況適當(dāng)減小。
模型在預(yù)測(cè)時(shí)采用了數(shù)據(jù)增強(qiáng)的方式Test time augmentation(TTA),即將樣本圖像進(jìn)行多個(gè)不同的變換獲得多個(gè)不同的預(yù)測(cè)結(jié)果,再將預(yù)測(cè)結(jié)果進(jìn)行平均,提高精度。本次任務(wù)利用3*TTA,包括 RandomCrop, RandomCrop+HorizontalFlip 和RandomCrop+VerticalFlip 。
模型集成是算法比賽中常用的提高模型精度方法,本次比賽我們訓(xùn)練了大量在ImageNet上表現(xiàn)優(yōu)良的模型,其中表現(xiàn)較好的模型如下表所示、在采取多種融合方式之后,最終發(fā)現(xiàn)SE_ResNeXt50、SE_ResNeXt101、SENet154以及DenseNet201按照歸一化后權(quán)重的融合效果最好,在測(cè)試集上的準(zhǔn)確率達(dá)到了0.92516。
| 模型 | 測(cè)試集準(zhǔn)確率 |
| SE_ResNeXt50 | 0.92251 |
| SE_ResNeXt101 | 0.92384 |
| SENet154 | 0.92384 |
| DenseNet201 | 0.91721 |
| MobileNetV2 | 0.91601 |
| ResNet152 | 0.91710 |
| SE_ResNeXt50+SE_ResNeXt101+SENet154+DenseNet201 | 0.92516 |
本次比賽主辦方提供了12595張未帶label的額外數(shù)據(jù)集,為了充分利用該數(shù)據(jù)集,利用在測(cè)試集表現(xiàn)最好的融合模型給這些數(shù)據(jù)集貼上偽標(biāo)簽。然后利用訓(xùn)練集和偽標(biāo)簽數(shù)據(jù)集訓(xùn)練模型,為了防止模型在偽標(biāo)簽上過(guò)擬合,我們對(duì)偽標(biāo)簽采取了一定的篩選操作。
采取的思路是:用多個(gè)不同概率閾值的過(guò)濾所得到的偽標(biāo)簽進(jìn)行線下實(shí)驗(yàn),看哪個(gè)閾值下的數(shù)據(jù)在線下的表現(xiàn)最好,就用通過(guò)該閾值篩選過(guò)濾出的數(shù)據(jù),最終以0.95的閾值篩選出一半的數(shù)據(jù)作為添加到訓(xùn)練集的偽標(biāo)簽數(shù)據(jù)。
實(shí)驗(yàn)證明這種半監(jiān)督的學(xué)習(xí)方法具有更強(qiáng)的泛化能力。

| 模型 |
測(cè)試集準(zhǔn)確率 (public leaderboard) |
Private leaderboard |
| SE_ResNeXt50 | 0.92251 | 0.93012 |
| SE_ResNeXt50 with pseudo data | 0.92195 | 0.93512 |
| SE_ResNeXt101 | 0.92384 | 0.93134 |
| SE_ResNeXt101 with pseudo data | 0.92202 | 0.93409 |
| SENet154 | 0.92384 | 0.93054 |
| SE_ResNeXt154 with pseudo data | 0.92283 | 0.93428 |
|
SE_ResNeXt50+SE_ResNeXt101+ SENet154+DenseNet201 |
0.92516 | 0.93727 |
|
SE_ResNeXt50+SE_ResNeXt101+ SENet154+DenseNet201 with pseudo data |
0.92516 | 0.93860 |
進(jìn)一步工作
針對(duì)細(xì)粒度圖像分類,MSRA有一個(gè)結(jié)論:分析該問(wèn)題時(shí)圖像的形態(tài)、輪廓特征原沒(méi)細(xì)節(jié)紋理特征重要,而傳統(tǒng)的CNN模型都是在構(gòu)建輪廓特征,因此在構(gòu)建神經(jīng)網(wǎng)絡(luò)時(shí),應(yīng)該更加精確地找到圖像中最有區(qū)分度的子區(qū)域,然后再對(duì)這些區(qū)域采用高分辨率、精細(xì)化特征的方法,這樣可以進(jìn)一步提高細(xì)粒度圖像分類的準(zhǔn)確率。
另外對(duì)數(shù)據(jù)本身我們可能需要做更多的工作,在任務(wù)初期沒(méi)有做足夠的探索性數(shù)據(jù)分析,例如數(shù)據(jù)的分布、類型、輸入圖像的尺寸等都是影響結(jié)果的因素,因此數(shù)據(jù)分析也是后面的一個(gè)嘗試點(diǎn)。
-
圖像
+關(guān)注
關(guān)注
2文章
1094瀏覽量
41090 -
人工智能
+關(guān)注
關(guān)注
1805文章
48843瀏覽量
247482 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46626
原文標(biāo)題:CVPR 2019細(xì)粒度圖像分類競(jìng)賽中國(guó)團(tuán)隊(duì)DeepBlueAI獲冠軍 | 技術(shù)干貨分享
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何在ctd解決方案中使用FRS (ccg2,3)?
挑戰(zhàn)具身機(jī)器人協(xié)同操作新高度!地瓜機(jī)器人邀你共戰(zhàn)CVPR 2025雙臂協(xié)作機(jī)器人競(jìng)賽


電摩電機(jī)控制器解決方案
【藍(lán)橋杯物聯(lián)網(wǎng)STM32WLE5】第一章 競(jìng)賽規(guī)則及說(shuō)明

一種使用LDO簡(jiǎn)單電源電路解決方案
解決方案 | 基于TSMaster的平板電腦解決方案

中國(guó)科大-云知聲聯(lián)合團(tuán)隊(duì)斬獲CVPR2024開(kāi)放環(huán)境情感行為分析競(jìng)賽三項(xiàng)季軍
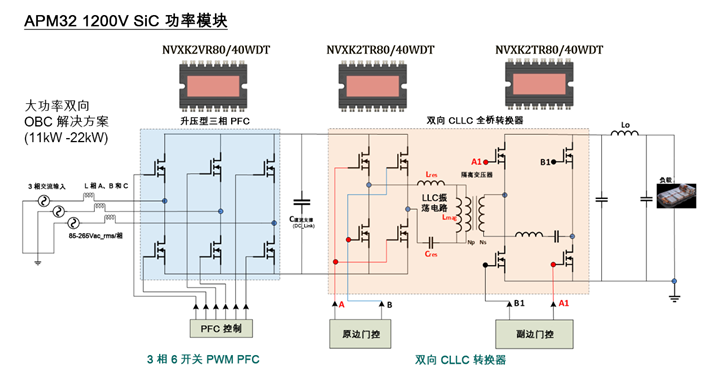
安森美OBC系統(tǒng)解決方案設(shè)計(jì)指南
炬芯科技第一代K歌音箱單芯片解決方案量產(chǎn)
潤(rùn)和軟件連續(xù)四年蟬聯(lián)數(shù)字業(yè)務(wù)類解決方案市場(chǎng)第一名
潤(rùn)和軟件連續(xù)三年蟬聯(lián)互聯(lián)網(wǎng)金融服務(wù)類解決方案市場(chǎng)占有率第一

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論