") 標(biāo)準(zhǔn)的機器學(xué)習(xí)流程如何玩出新花樣
標(biāo)準(zhǔn)的機器學(xué)習(xí)流程如何玩出新花樣

近日,CSDN與數(shù)字經(jīng)濟人才發(fā)展中心聯(lián)合主辦的第一屆CTA核心技術(shù)及應(yīng)用峰會在杭州開啟。首屆CTA核心技術(shù)及應(yīng)用峰會圍繞人工智能,邀請技術(shù)領(lǐng)航者,與開發(fā)者共同探討機器學(xué)習(xí)和知識圖譜的前沿研究及應(yīng)用。在本次機器學(xué)習(xí)專場中,來自海康威視研究院前研技術(shù)部的負責(zé)人謝迪為我們帶來了題為《How to Explore in Machine Learning Pipeline》(機器學(xué)習(xí)流程研究)的精彩演講。
在機器學(xué)習(xí)時代,AI相關(guān)工作都是聚焦于具體的流程,如數(shù)據(jù)收集、模型訓(xùn)練、模型配置等。AI從業(yè)/從事人員眾多,但大家做的事情很多都大同小異,這其實可以總結(jié)成一個標(biāo)準(zhǔn)的pipeline。但是,如何在機器學(xué)習(xí)的流水線上做出和別人不一樣的工作,還是需要很多技巧。這次,謝迪將會為大家分享如何在標(biāo)準(zhǔn)的機器學(xué)習(xí)流水線上,通過多年積累獲得的洞見,提升對于具體應(yīng)用的認識。
標(biāo)準(zhǔn)機器學(xué)習(xí)Pipeline

如圖所示,這是一個標(biāo)準(zhǔn)的機器學(xué)習(xí)流水線,我們可以收集數(shù)據(jù)、提取特征、訓(xùn)練分類器等。幾年前深度學(xué)習(xí)還沒有火的時候,我們靠人工提取算子,之后進行訓(xùn)練,最后得到我們想要的模型,去解決具體問題。
隨著深度學(xué)習(xí)的興起,中間的兩塊已經(jīng)被神經(jīng)網(wǎng)絡(luò)統(tǒng)一,但是我們認為在工業(yè)界,要得到真正工作的機器學(xué)習(xí)pipeline,還有兩個環(huán)節(jié)我們需要特別注意。其中包括數(shù)據(jù)的環(huán)節(jié),因為數(shù)據(jù)并不是現(xiàn)成的,實際上現(xiàn)在人工智能深入發(fā)展,對公司來說很大部分的工作還是集中在數(shù)據(jù)標(biāo)定上,有了標(biāo)定的數(shù)據(jù)之后才能進行訓(xùn)練,最后得到一個模型。在海康威視,很多的應(yīng)用以前是放在后端的,但現(xiàn)在都在逐漸向往邊緣端轉(zhuǎn)移,所以我們有相當(dāng)一部分的工作是在邊緣端的深度神經(jīng)模型以及工業(yè)機器人的配置上。
機器學(xué)習(xí)pipeline實踐

今天,我將和大家分享三個方面的工作,聚焦于標(biāo)注、訓(xùn)練和部署,這三個環(huán)節(jié)分別代表了信息的生成、提煉、重新整合以及信息的去冗余。
▌1. 標(biāo)注
通用函數(shù)近似器

這是第一項工作。我們知道,深度神經(jīng)網(wǎng)絡(luò)相比于傳統(tǒng)的 SVM 或其他的線性模型,更類似于全局函數(shù)近似器,即輸入 ground truth,它就能輸出你想要的結(jié)果。
我們可以給定一個標(biāo)注,輸入更多信息量,比如一個人在圖中的位置、關(guān)鍵點集合,甚至是一個非常稠密的網(wǎng)格。這是一個信息從少到多的過程,無論信息多復(fù)雜,在神經(jīng)網(wǎng)絡(luò)下都可以輸出你想要的結(jié)果。換一個角度理解,神經(jīng)網(wǎng)絡(luò)對數(shù)據(jù)是非常敏感的。
多尺度對GT的影響
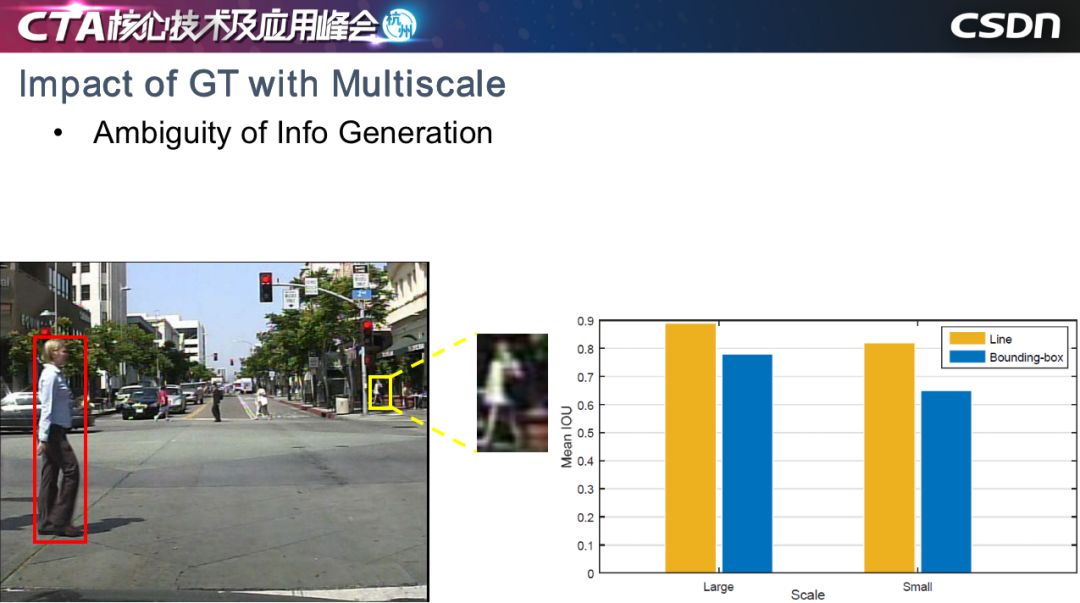
在安防場景中,我們最關(guān)心的是人和車。以行人檢測為例,在一個場景中,我們會關(guān)心各個尺度的行人,但是神經(jīng)網(wǎng)絡(luò)對不同對象比較敏感,我們現(xiàn)在檢測的框架是基于邊界框的,對于大尺度的行人來說,紅框標(biāo)定行人沒有問題,但是小尺度的行人標(biāo)定存在兩個問題,第一個問題是小尺度的對象本身提供的信息非常有限,第二個是小尺度對象的真值框差異非常大。
如右圖所示,我們做了一個實驗,讓10個標(biāo)定人員進行標(biāo)定,藍色表示 Bounding-box (邊界框)標(biāo)定方法,黃色是基于線段的標(biāo)定方法,對于大尺度對象和小尺度對象,ground truth 的平均 IOU顯示如圖所示。可以看到,大尺度對象明顯優(yōu)于小尺度對象。基于神經(jīng)網(wǎng)絡(luò)對信息產(chǎn)生的方式非常敏感的前提來說,我們認為影響小目標(biāo)檢測的問題之一,可能是在于信息生成方式的歧義性。
TLL小尺度行人檢測

為此我們提出了TLL。它的核心想法非常簡單,即 Bounding-box 表示方法會影響極小目標(biāo)的檢出率,所以我們需要為小目標(biāo)單獨設(shè)計一種生成信息的方式,我們通過 Bounding-box 上下兩點中心,做了一個連線,即把原來用一個 Bounding-box 表示一個物體的表示方式,變成了用一個線段表示一個人體,上端表示頭,下端表示人與頭之間的中心。
網(wǎng)絡(luò)結(jié)構(gòu)我們使用了 Hourglass 的沙漏結(jié)構(gòu)。當(dāng)然,多尺度是影響目標(biāo)檢測的原因,所以我們也是使用了多尺度信息聚合的方式。

我們的網(wǎng)絡(luò)輸出是三個特征圖,分別表示人頭、兩腳和人體的分圖。最后,我們用后處理的方法,通過二分圖匹配得到最終的匹配結(jié)果,即圖中虛線所示直線。
但在實際場景中,我們發(fā)現(xiàn)當(dāng)人群密度比較密的時候,使用二分圖匹配會出現(xiàn)如圖所示的交叉結(jié)果,所以我們引入了馬爾科夫隨機場,不鼓勵交叉情況的產(chǎn)生,這樣就可以獲得更好的結(jié)果,有效地避免了交叉產(chǎn)生。
在測試中,我們希望小目標(biāo)的分辨率能夠在10像素以下,越小越好,因為越小越能體現(xiàn)算法的優(yōu)勢,而對于檢測過程中的幀漏檢,相比基于光流的顯示聚合方法,隱式的信息聚合方法可以進一步的提高檢出率。

這是量化的結(jié)果,顯示性能非常好。有個非常有趣的現(xiàn)象,我們僅僅是簡單地改變了標(biāo)注的方式,本質(zhì)上即信息生成的方式,在嚴重遮擋的情況下,依然取得了更好的性能。

可以看到,無論在嚴重遮擋、遠景,還是不規(guī)則的長寬比的配置下,這個方法還是有一定的優(yōu)勢。

這是定性的一些結(jié)果,像圖中這樣檢測難度非常大的情況也可以檢測出,稠密的行人也沒有漏檢。我們在一些目標(biāo)項目中落地了這一方法,如在上海陸家嘴的環(huán)形天橋上,攝像頭能夠精確地統(tǒng)計天橋上行人的數(shù)量。

這個工作我們從 2017 年開始做,最初的目標(biāo)檢測用到了兩階段的方法,代表有 FastCNN。一步檢測的代表框架有 SSD 和 YOLO,現(xiàn)在甚至有人在關(guān)注 Anchor-free 的方法,包括 FCOS、ReqPoints 等。這都是大家嘗試找到一種不一樣的邊界框產(chǎn)生方式,能夠更好地指導(dǎo)網(wǎng)絡(luò)進行訓(xùn)練,并挖掘出原始數(shù)據(jù)中有價值的信息并用到具體的應(yīng)用中。
▌2. 訓(xùn)練
神經(jīng)網(wǎng)絡(luò)訓(xùn)練洞見

我分享的第二個工作是如何訓(xùn)練神經(jīng)網(wǎng)絡(luò),或者神經(jīng)網(wǎng)絡(luò)的本質(zhì)是什么。訓(xùn)練神經(jīng)網(wǎng)絡(luò)有很多初始化方法和優(yōu)化器,在訓(xùn)練中對信息進行歸一化。
從信息傳播的角度看,我們認為這些方法本質(zhì)上是保持訓(xùn)練過程中或訓(xùn)練初始階段的恒常性。恒常性可以分為兩種,一種是靜態(tài)恒常性,一種是動態(tài)恒常性。靜態(tài)恒常性一般用在初始階段,也就是初始化即可;動態(tài)恒常性就是優(yōu)化的過程中,每一輪迭代都讓信息的某種統(tǒng)計量保持不變。大家比較熟悉的初始化方法,包括Xavier、MSra、LSUV都屬于靜態(tài)恒常性,所有層保持在固定的數(shù)量級上,讓初始權(quán)重的某些統(tǒng)計量保持在統(tǒng)一數(shù)量級上;動態(tài)恒常性包括 WN、BN、LN 等。但無論是哪種方式,無非就是設(shè)計某種規(guī)劃,能夠讓信息的量級在某一個傳播方向上保持不變,當(dāng)然不是數(shù)字上的不變,而是統(tǒng)計量上的不變,因為神經(jīng)網(wǎng)絡(luò)的訓(xùn)練有點類似于蝴蝶效應(yīng),所以恒常性非常重要。
四個觀點

先講我們的四個觀點:
第一,我們訓(xùn)練一個真正深的網(wǎng)絡(luò),批歸一化是一個必要條件;
第二,相較于靜態(tài)恒常性,動態(tài)恒常性更加重要;
第三,相較于單個方向保持動態(tài)恒常性,在訓(xùn)練時保持兩個方向,同時保持動態(tài)的恒常性,才是解決這個問題的關(guān)鍵;
最后,如果模型非常深,可能還需要顯示對傳播的信號進行調(diào)控。
退化問題
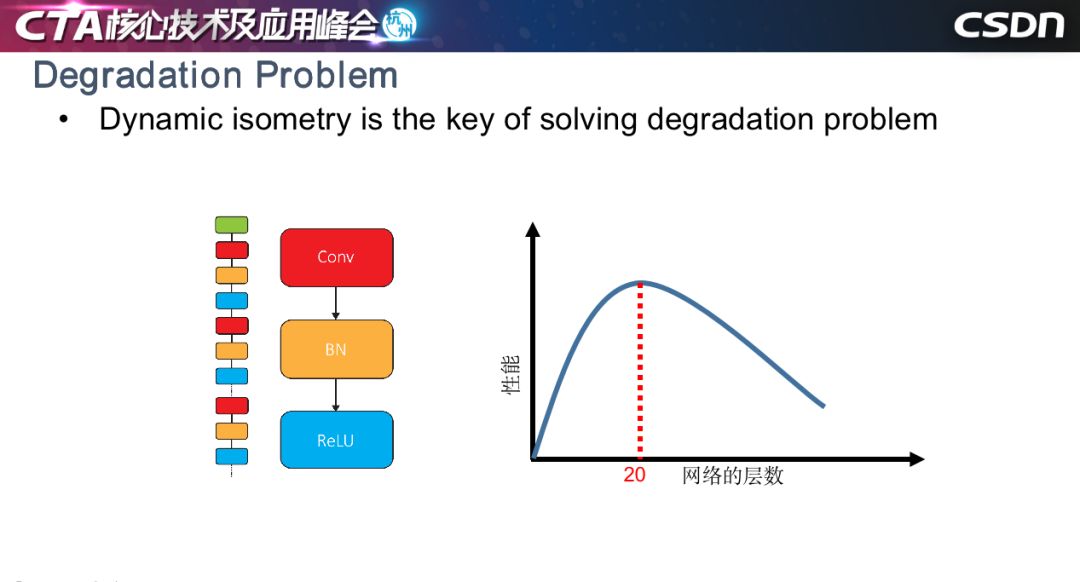
大家可能說,用了ResNet 好像沒有發(fā)生很難訓(xùn)練的情況,但是康奈爾大學(xué)的一篇文章指出,ResNet 本質(zhì)上是指數(shù)級淺網(wǎng)絡(luò)的聚合,如左圖所示,我們的工作是對沒有任何殘差結(jié)構(gòu)網(wǎng)絡(luò)的訓(xùn)練方法。這種方法訓(xùn)練過程中會產(chǎn)生退化問題,即當(dāng)以網(wǎng)絡(luò)的層數(shù)作為橫坐標(biāo)、性能作為縱坐標(biāo),結(jié)果會如右圖所示,網(wǎng)絡(luò)層數(shù)小于等于20層時,簡單堆疊網(wǎng)絡(luò)層數(shù)會產(chǎn)生增益性能,但層數(shù)超過20,收斂率會大大下降,性能變差,這就是著名的深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練退化的問題。我們的工作其實沒有解決這個問題,只是緩解了這一問題,但希望可以給從業(yè)人員一些啟發(fā)。
內(nèi)在因素

我們認為原因可能有兩個,第一是批歸一化的偽歸一化問題,前面的信號傳遞沒有問題,在每一層卷積以后,信號雖然有時會被放大,有時會被縮小,但是經(jīng)過批歸一化以后,分布又能夠被拉回來。但是如果推導(dǎo)反向評估顯示,會發(fā)現(xiàn)當(dāng)層數(shù)非常深時,誤差累積的效應(yīng)會讓反向傳播誤差的分布越來越偏,造成訓(xùn)練出問題。

第二個原因可能更加深刻一點,我們知道反向傳播的信號其實是和輸出相對于輸入息息相關(guān)。一般的工作可能推導(dǎo)到卷積層,我們還考慮了 BN 層,推導(dǎo)如圖所示,在 MXM 層的方陣里面,左上角兩個數(shù)值很有可能取到 0 或近似 0。底部的示意圖表示一個信息量比較豐富的信號,在反向傳播時,一層一層往回傳會造成信號特定維度上的信息丟失。我們認為信息的丟失也會破壞動態(tài)恒常性,造成沒有殘差結(jié)構(gòu)深度網(wǎng)絡(luò)難以訓(xùn)練。
解決方案1:正規(guī)化

找到實用且有效的方法非常難,我們首先想到了一個數(shù)學(xué)公式,如果線性變化位于一個正交權(quán)上,就能獲得輸入和輸出向量之間范數(shù)上的幅值等價性。但是我們發(fā)現(xiàn),如果強制要求權(quán)重位于正交基上,很大程度會限制神經(jīng)網(wǎng)絡(luò)解空間的范圍。我們用正交正則的思路替代 LR,去解決這個問題。

我們希望在反向傳播時,信號的幅值能夠位于比較穩(wěn)定的范圍內(nèi)。由于各種應(yīng)用不同,卷積神經(jīng)網(wǎng)絡(luò)會對應(yīng)不同的超參數(shù),輸入和輸出通道的不同等原因也會使得維度上出現(xiàn)一些問題。比如,在三維空間中找到四個相互正交的向量,在數(shù)學(xué)上是不可行的。對于輸入維度小于輸出的情況,需要要進行分組,讓每個組的 din 大于等于 dout。
解決方案2:調(diào)制

第二個解決方案想法比較簡單,就是對信號進行調(diào)制。在我們推導(dǎo)的公式中,為每一層設(shè)計一個符合該層的放大因子或縮小因子,該因子取值由該層的誤差輸出和輸入的比值決定。此方法可以在訓(xùn)練一個沒有殘差的一百層網(wǎng)絡(luò)的初始階段使用。
實驗結(jié)果
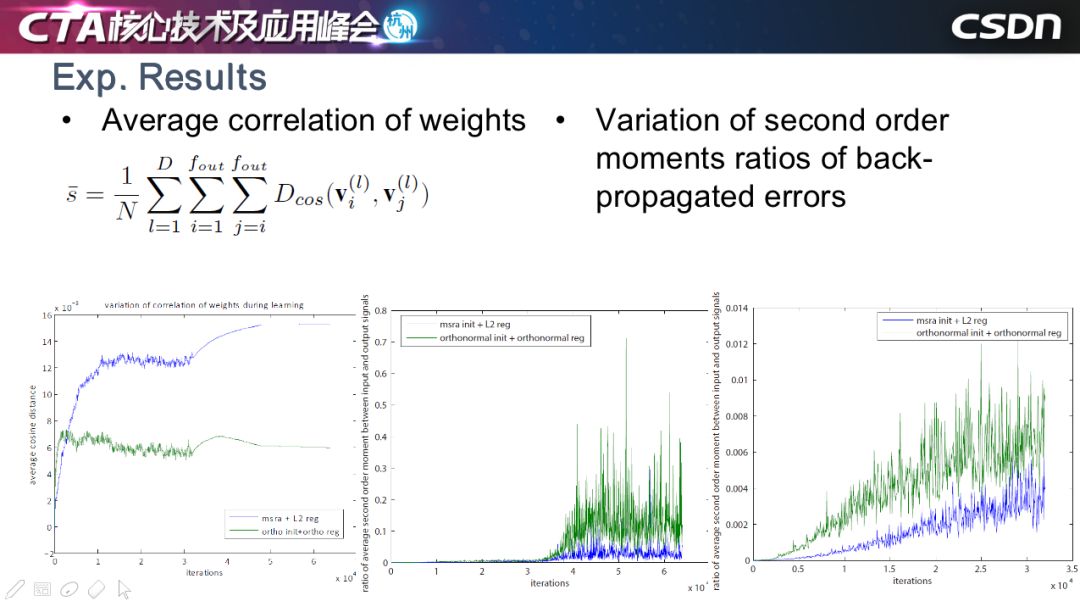
這是我們的一些實驗的結(jié)果,最左圖是每一層的 weights 相關(guān)度的曲線圖,大家可以看到,綠色表示正交正則,藍色表示權(quán)重衰減,用了正交正則以后,位置之間的夾角較大,夾角越大,相關(guān)度越低,此方法有效地保持了 weights 之間的低相關(guān)度。
右邊的兩幅圖是反向傳播的誤差性浮值的曲線。同樣地,藍色是權(quán)重衰減的方法,綠色是正交正則方法,可以看到正交正則可以適當(dāng)放大信號,有效保留反向傳播中有用的信號,這些有用的部分,我們認為是能夠讓網(wǎng)絡(luò)正常訓(xùn)練的關(guān)鍵因素。

我們對 SGD、正交正則和其他的一些自適應(yīng)方法等進行比較,發(fā)現(xiàn)我們的方法能夠獲得較好的性能,當(dāng)層數(shù)到達 110 層時,很多方法已經(jīng)無法訓(xùn)練了,但我們的方法還是可以繼續(xù)收斂,并可以用在殘差網(wǎng)絡(luò)里,但是對性能的提升不是很明顯。

在其他人的工作中,我們也發(fā)現(xiàn)了類似的結(jié)論。BigGan 提到正交正則有利于 Gan 網(wǎng)絡(luò)的穩(wěn)定性。LARS 也提出了分層學(xué)習(xí)力的思想,只不過它使用了 weight 幅值與其梯度幅值的比值。
部署
▌模型壓縮方法

以下的工作是模型部署。我們有很多攝像頭產(chǎn)品,所以壓縮方法是重中之重。

我今天要講的是輕量級算子的相關(guān)工作,動機在于卷積是信息聚合的一種方式,可以分成兩個階段,一個是確定感受野,第二是確定兩個向量之間的內(nèi)積。3X3 的卷積既能滿足感受野,也能兼顧 flops,所以大多數(shù)卷積是 3X3。

但是,我們是否能找到一個 1X1 的方式替代原來的卷積神經(jīng)網(wǎng)絡(luò)呢?答案是有的。那就是Shift操作,它可以把某一層的特征圖進行平移,然后用 1X1 進行信息聚合,好處是沒有額外的計算量。

因為最初的 shift CNN 需要人工確定平移的方向和大小,但我們想要通過自適應(yīng)去學(xué)習(xí)平移方向,同時保持特征圖不動,因為特征圖移動會產(chǎn)生一定代價,所以我們用雙向性插值,把平移的量切換為連續(xù)的浮點值,然后增加了一個鼓勵稀疏的正則。

我們根據(jù)這個基本思想設(shè)計了一些基本模塊,結(jié)合了下采樣、多尺度融合等。
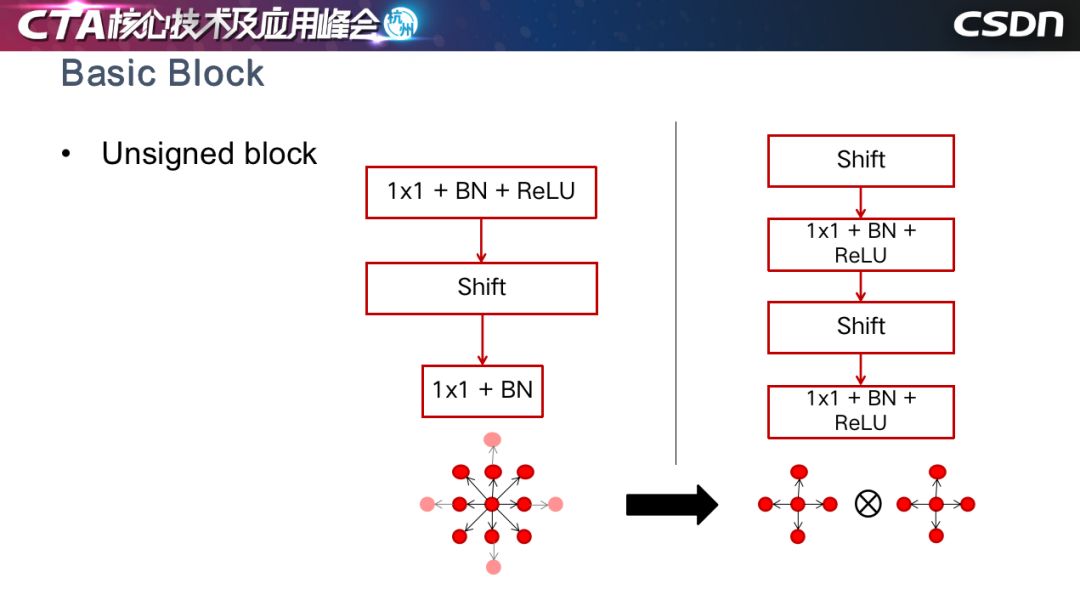
這是基于Unsigned Block做融合,用 4 領(lǐng)域的 shift 操作代替了 8 領(lǐng)域的 shift 操作。
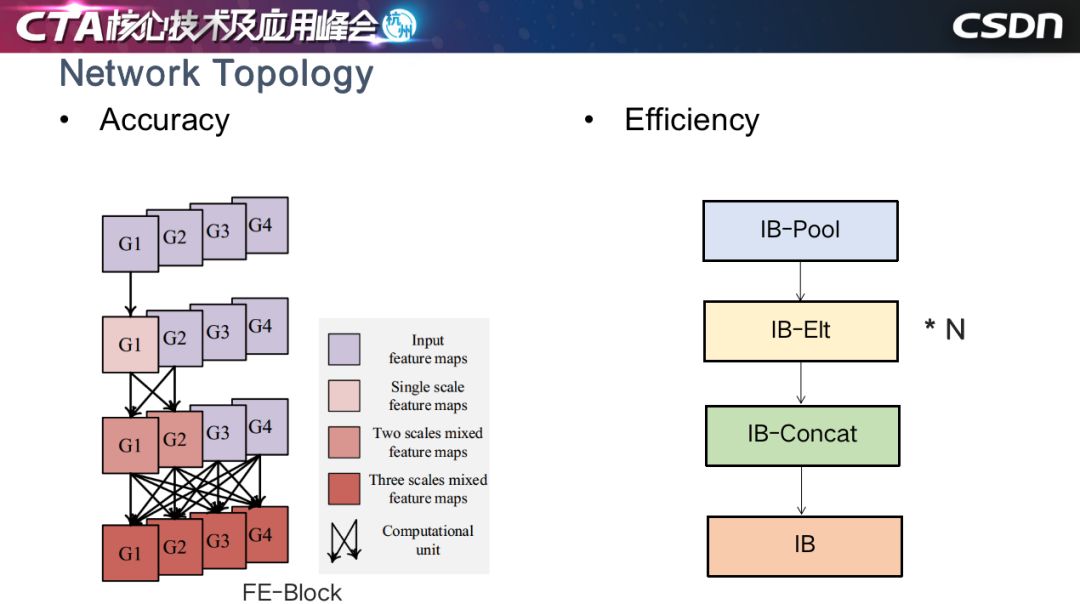
我們還設(shè)計了兼顧效率的網(wǎng)絡(luò)結(jié)構(gòu),以一種反規(guī)約的順序進行 shift 卷積,增加了感受野的復(fù)雜度和聚合的復(fù)雜度,產(chǎn)生更好的效果,效率提升,跑得速度更快。

這是與 Mobilenet 和 ShuffleNet 性能比較。

這是我們對隨機選取的六層網(wǎng)絡(luò)進行可視化的結(jié)果,圈越大表示特征圖越多,占比越高。統(tǒng)計顯示,約 70% 的分類問題特征圖是不需要移動的,這非常有趣。
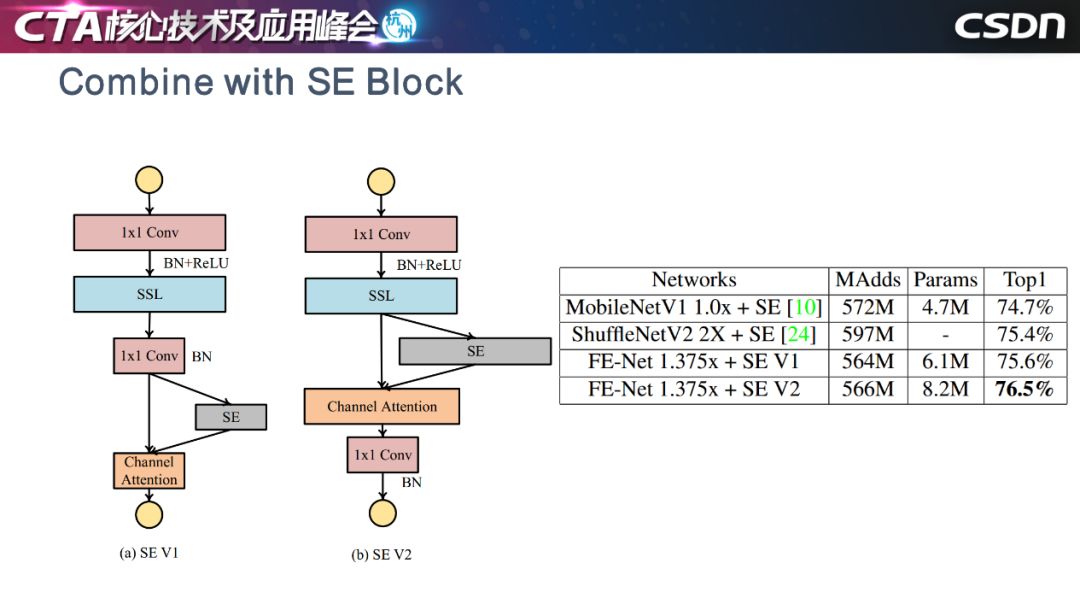

這是上個月 MobileNetV3 的工作,我們的想法與之不謀而合:模塊放置在深度濾波器的拓展之后,以將注意力應(yīng)用于最大的表示......

最后是四點總結(jié):
第一點,我們認為現(xiàn)在的深度學(xué)習(xí)框架中,模型對信息生成的方式非常敏感,可以考慮在把信息“喂”給模型之前,如何讓信息的呈現(xiàn)方式歧義變小,這樣可以獲得更好的結(jié)果。
第二點,邊界框可能已經(jīng)過時了,我們需要想一些更加優(yōu)雅、優(yōu)美的表示方式。
第三點,我們認為訓(xùn)練神經(jīng)網(wǎng)絡(luò)時,動態(tài)恒常性是一個關(guān)鍵因素。
最后一點,對于芯片設(shè)計者來說,過多的算子會導(dǎo)致電路更復(fù)雜,就像檢測框架會趨向于過程簡化,我們認為算子也會進行收斂,以后的神經(jīng)網(wǎng)絡(luò)可能只有 1X1 的卷積,加上其他的操作就能夠進行各種智能應(yīng)用。
-
AI
+關(guān)注
關(guān)注
88文章
34691瀏覽量
276673 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8499瀏覽量
134290
原文標(biāo)題:如何在標(biāo)準(zhǔn)的機器學(xué)習(xí)流程上玩出新花樣?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論