 電子發(fā)燒友App
電子發(fā)燒友App


一、前言?
Linux調(diào)度器神秘而充滿誘惑,每個Linux工程師都想深入其內(nèi)部一探究竟。不過中國有一句古話叫做“相由心生”,一個模塊精巧的內(nèi)部邏輯(也就是所謂的“心”)其外延就是簡潔而優(yōu)雅的接口(我稱之為“相”)。通過外部接口的定義,其實我們也可以收獲百分之六七十的該模塊的內(nèi)部信息。因此,本文主要描述Linux調(diào)度器開放給用戶空間的接口,希望可以通過用戶空間的調(diào)度器接口來理解Linux調(diào)度器的行為。
二、nice函數(shù)
nice函數(shù)用來修改調(diào)用進程的nice value,其接口定義如下:
#include?
?????? int nice(int inc);
為了方便說明該接口的作用,我們還是舉實際的例子說明。程序調(diào)用nice(3),則將當前進程的nice value增加3,這也就是意味著該進程的優(yōu)先級降低3個level(提升nice value也就是對別人更加nice,自己的優(yōu)先級就會低)。如果程序調(diào)用nice(-5),則將當前進程的nice value減去5,這也就是意味著該進程的優(yōu)先級提升5個level。當調(diào)用錯誤的時候返回-1,調(diào)用成功會稍微有一些歧義。POSIX標準規(guī)定了nice函數(shù)返回新的nice value,但是linux的系統(tǒng)調(diào)用和c庫都是采用了操作成功返回0的方式。這樣的處理方式使得在調(diào)用nice函數(shù)的時候無法得到當前的優(yōu)先級,如果想要得到當前優(yōu)先級,需要調(diào)用getpriority函數(shù),我們在下一小節(jié)描述。
雖然說nice函數(shù)是用來調(diào)整優(yōu)先級,實際上調(diào)整nice value就是調(diào)整調(diào)度器分配給該進程的CPU時間,具體是如何影響cpu time的呢?我們在后面描述內(nèi)核代碼的時候再詳聊。此外,需要注意的是:根據(jù)POSIX標準,nice value是一個per process的設定,但是在linux中,nice value沒有遵從這個標準,它是per-thread的一個屬性。
三、getpriority/setpriority函數(shù)
從上節(jié)的描述中,我們了解到了nice的函數(shù)的限制,例如只能修改自己的nice value,無法獲取當前的nice value值等,為此我們給出加強版本的nice接口,也就是getpriority/setpriority函數(shù)了。getpriority/setpriority函數(shù)定義如下:
#include?
#include?
int getpriority(int which, int who);?
int setpriority(int which, int who, int prio);
你說接口增加功能是好事,怎么就把名字也改了呢?為何不是getnice/setnice呢?其實從上節(jié)的描述也看出稍許端倪,我們并沒有區(qū)分調(diào)度優(yōu)先級和nice value這兩個值,歷史上,首先被使用的是nice value,很快大家覺得這個詞不是那么好理解,特別是對于初學者,因此改成優(yōu)先級(priority)這樣的名詞可以讓用戶更好的理解這個API的作用,當然,事實證明這個改動并不是非常理想,我們后面會描述。
getpriority/setpriority功能比較強大,能處理多種請求,不同的請求通過which和who這兩個參數(shù)來制定。當which等于PRIO_PROCESS的時候,who需要傳入一個process id的參數(shù),getpriority將返回指定進程的nice value。當which等于PRIO_PGRP的時候,who需要傳入一個process group id的參數(shù),此時getpriority將返回指定進程組中優(yōu)先級最高的那個(BTW,nice value是最小的)。當which等于PRIO_USER的時候,who需要user id的信息,這時候,getpriority將返回屬于該user的所有進程中nice value最小的那個。who等于0說明要get或者set的對象是當前進程(或者當前進程組,或者當前的user)。
setpriority類似與nice,當然功能要強那么一點點,因為它可以接收PRIO_PROCESS,PRIO_PGRP或者PRIO_USER參數(shù)用來設定一組進程的nice value。setpriority的返回值和其他函數(shù)類似,0表示成功,-1表示操作失敗,不過getpriority就稍微有一點繞了。作為linux程序員,我們都知道的nice value是[-20, 19],如果getpriority返回這個范圍,那么這里的-1優(yōu)先級就有點尷尬了,因為一般的linux c庫接口函數(shù)返回-1表示調(diào)用錯誤,我們是如何區(qū)分-1調(diào)用錯誤的返回還是優(yōu)先級-1的返回值呢?getpriority是少數(shù)返回-1也是有可能正確的接口函數(shù):在調(diào)用getpriority之前,我們需要首先將errno清零,調(diào)用getpriority之后,如果返回-1,我們需要看看errno是否還是保持0值,如果是,那么說明返回的是優(yōu)先級-1,否則說明發(fā)生了錯誤。
四、操作rt priority的接口
傳統(tǒng)的類unix內(nèi)核,調(diào)度器是采用round-robin time-sharing的算法:如果有若干個進程是runnable的,那么不著急,大家排排隊、吃果果,每個進程分配一個cpu時間片,大家輪流按照分配的時間片來獲取cpu資源,所有的時間片用完,那么就重新一輪的分配。在這樣的模型下面,間接影響cpu時間片的nice接口函數(shù)就夠用了。當然,分配了更多的時間片也就是意味著有更高的優(yōu)先級,因此nice vlaue也被稱為進程的優(yōu)先級。
但是,新的需求層出不窮(人類的欲望是無窮D),特別是實時性方面的需求,因此,POSIX標準(2008版本)增加了實時調(diào)度的內(nèi)容,并且提供了POSIX realtime scheduling API來讓用戶空間來修改調(diào)度策略和調(diào)度優(yōu)先級。這下子有點尷尬了,原來的nice value大家已經(jīng)習慣稱之為進程優(yōu)先級了,現(xiàn)在真正的進程優(yōu)先級登場了,怎么區(qū)分?為了解決這個問題,我們引入一個新的名詞叫做調(diào)度策略(scheduling policy)。調(diào)度器在運作的時候往往設定一組規(guī)則來決定何時,選擇哪一個進程進入執(zhí)行狀態(tài),執(zhí)行多長的時間。那些“規(guī)則”就是調(diào)度策略。
好的調(diào)度策略依賴于對進程的分類,有一類進程是大家都灰常的熟悉了就是普通進程,使用時間片輪轉(zhuǎn)算法的那些進程。當然這類進程還可以細分,例如運算密集型進程(SCHED_BATCH,調(diào)度器最好不要太經(jīng)常的喚醒這種進程),例如idle類進程(SCHED_IDLE),idle類進程優(yōu)先級非常低,也就是說如果系統(tǒng)有其他事情要處理就去干別的事情(調(diào)度其他進程執(zhí)行),實在沒有活干了,再考慮IDLE類型的進程。不論哪一種普通進程,其優(yōu)先級使用nice value這樣一個調(diào)度參數(shù)來描述就OK了。
除了普通進程,還有一類是嚴格按照優(yōu)先級來調(diào)度的進程,如果熟悉RTOS的話,對priority-base的調(diào)度器應該不會陌生,官大一級壓死人,只要優(yōu)先級高的進程是runnable的,那么優(yōu)先級低的進程是根本沒有機會執(zhí)行的。這里的優(yōu)先級才是真正意義的優(yōu)先級,但是nice value已經(jīng)被稱為進程優(yōu)先級了,因此這里的優(yōu)先級被叫做rt priority。rt進程的調(diào)度又被細分成兩類:SCHED_FIFO和SCHED_RR。這兩種調(diào)度策略在相同rt priority的時候稍有差別,SCHED_FIFO是誰先到誰先獲取cpu資源,并且一直占用,直到主動讓出cpu或者退出,相同rt priority的進程才有機會執(zhí)行。SCHED_RR稍微人性化了一點,相同rt priority的進程有時間片,大家輪流執(zhí)行。對于實時進程而言,rt priority這個調(diào)度參數(shù)就描述了全部。
介紹到這里,是時候總結一下了:進程優(yōu)先級有兩個范圍,一個是nice value,用前兩個小節(jié)的API來set或者get。另外一個優(yōu)先級是rt priority,完全碾壓nice value這種優(yōu)先級,操作rt priority的接口就在這一小節(jié)描述。
OK,經(jīng)過漫長的鋪墊過程,我們終于可以介紹realtime process scheduling API了,具體API定義如下:
#include
int sched_setscheduler(pid_t pid, int policy, const struct sched_param *param);
int sched_getscheduler(pid_t pid);
int sched_get_priority_max(int policy);--返回指定policy的最大的rt priority?
int sched_get_priority_min(int policy);--返回指定policy的最小的rt priority
int sched_setparam(pid_t pid, const struct sched_param *param);?
int sched_getparam(pid_t pid, struct sched_param *param);
sched_get_priority_max和sched_get_priority_min分別返回了指定調(diào)度策略的最大和最小的rt priority,不同的操作系統(tǒng)實現(xiàn)不同的優(yōu)先級數(shù)量。在linux中,實時進程(SCHED_FIFO和SCHED_RR)的rt priority共計99個level,最小是1,最大是99。對于其他的調(diào)度策略,這些函數(shù)返回0。
sched_getscheduler函數(shù)可以獲取指定進程的scheduling policy(如果pid等于0,那么是獲取調(diào)用進程的調(diào)度策略)。sched_setscheduler函數(shù)是用來設定指定進程的scheduling policy,對于實時進程,該接口函數(shù)還可以設定rt priority。如果設定進程的調(diào)度策略是非實時的調(diào)度策略的時候(例如SCHED_NORMAL),那么param參數(shù)是沒有意義的,其sched_priority成員必須設定為0。sched_setparam/sched_getparam非常簡單,大家自己看man page好了。
五、一統(tǒng)江湖的接口
看起來前面小節(jié)描述的API已經(jīng)夠用了,然而,故事并未結束。經(jīng)過前面關于調(diào)度接口的討論,基本上我們對調(diào)度器的行為也已經(jīng)有了了解:調(diào)度器就是按照優(yōu)先級(指rt priority)來工作,優(yōu)先級高的永遠是優(yōu)先調(diào)度。范圍落在[1,99]的rt priority是實時進程,而rt priority等于0的是普通進程。對于普通進程,調(diào)度器還要根據(jù)nice value(這個也曾經(jīng)被稱為優(yōu)先級,不要和rt priority弄混了)來進行調(diào)整。用戶空間的進程可以通過各種前面描述的接口API來修改調(diào)度策略、nice value以及rt priority。一切看上去已經(jīng)完美,CFS類型的調(diào)度器處理普通的運算密集形(例如編譯內(nèi)核)和用戶交互形的應用(例如vi編輯文件)。如果有應用有實時需求,可以考慮讓rt類型的調(diào)度器來運籌帷幄。但是,如何混合了一些realtime的應用以及有一些timing要求的應用的時候,SCHED_FIFO和SCHED_RR并不能解決問題,因為在這種調(diào)度策略下,高優(yōu)先級的任務會永遠的delay低優(yōu)先級的任務,如果低優(yōu)先級的任務有一些timing的需求,這時候,你根本控制不了調(diào)度延遲時間。
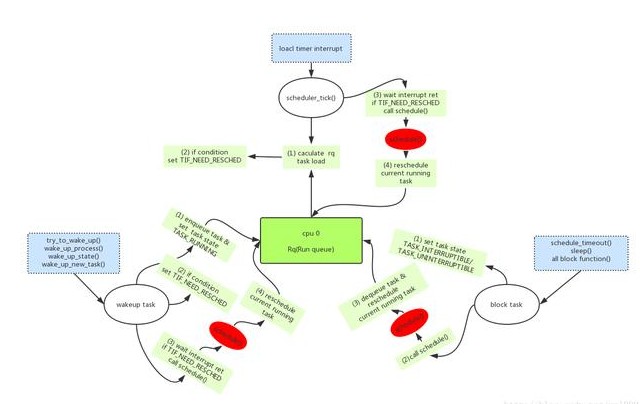
為了解決上一節(jié)中描述的問題,一類新的進程被定義出來,這類進程的優(yōu)先級比實時進程和普通進程的優(yōu)先級都要高,這類進行有自己的特點,參考下圖:
這類進程的特點就是每隔固定的周期都會起來干活,需要一定的時間來處理事務。這類進程很牛,一上來就告訴調(diào)度器,我可是有點脾氣的進程,和其他的那些妖艷的進程不一樣的,我每隔一段時間(period)你就得固定分配給我一定的cpu資源(computer time),當然,分配的cpu time必須在該周期內(nèi)執(zhí)行完畢,因此就有deadline的概念。為了應對這種需求,3.14內(nèi)核引入了一類新的進程叫做deadline進程,這類進程的調(diào)度策略是SCHED_DEADLINE。調(diào)度器對這類進程也會高看一眼,每當一個周期的開始時間到來的時候(也就是該deadline進程被喚醒的時間),調(diào)度器要優(yōu)先處理這個deadline進程對cpu timer的需求,并且在某個指定的deadline時間內(nèi)調(diào)度該進程執(zhí)行。執(zhí)行了指定的cpu time后,可以考慮調(diào)度走該進行,不過,當下一個周期到來的時候,調(diào)度器仍然要奮不顧身的在deadline時間內(nèi),再次調(diào)度該deadline進程執(zhí)行。
雖然deadline進程優(yōu)先級高于其他兩類進程,但是用“優(yōu)先級”來描述這類進程當然是不合理的,應該使用下面的三個參數(shù)來描述:
(1)周期時間(上圖中的period)
(2)deadline時間(上圖中的relative deadline)
(3)一次調(diào)度周期內(nèi)分配多少的cpu時間(上圖中的comp. time)
至此,估計您也已經(jīng)發(fā)現(xiàn),前面描述的接口其實都是不適合設定這些參數(shù)的,因此,GNU/linux操作系統(tǒng)中增加了下面的接口API:
#include
int sched_setattr(pid_t pid, const struct sched_attr *attr, unsigned int flags);?
int sched_getattr(pid_t pid, const struct sched_attr *attr, unsigned int size, unsigned int flags);
attr這個參數(shù)的數(shù)據(jù)類型是struct sched_attr,這個數(shù)據(jù)結構囊括了一切你想要的關于調(diào)度的控制參數(shù):policy,nice value,rt priority,period,deadline等等。用這個接口可以完成所有前面幾個小節(jié)描述API能完成的任務,唯一的不好的地方就是這個接口是linux特有的,不是posix標準,是否應用這個接口就是見仁見智了。更細節(jié)的知識這里就不描述了,大家還是參考man page好了。
六、其他
上面描述的接口API都是和調(diào)度器參數(shù)相關,其實Linux調(diào)度器還有兩類接口。一個是sched_getaffinity和sched_setaffinity,用于操作一個線程的CPU affinity。另外一個接口是sched_yield,該接口可以讓出CPU資源,讓Linux調(diào)度器選擇一個合適的線程執(zhí)行。這些接口很簡單,大家仔細學習就OK了。
參考文檔:
1、POSIX標準2008
2、linux下的各種man page
3、linux 4.4.6內(nèi)核源代碼













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論