 電子發燒友App
電子發燒友App


4、單表關聯
前面的實例都是在數據上進行一些簡單的處理,為進一步的操作打基礎。“單表關聯”這個實例要求從給出的數據中尋找所關心的數據,它是對原始數據所包含信息的挖掘。下面進入這個實例。
4.1 實例描述
實例中給出child-parent(孩子——父母)表,要求輸出grandchild-grandparent(孫子——爺奶)表。
樣例輸入如下所示。
file:
child parent
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
家族樹狀關系譜:
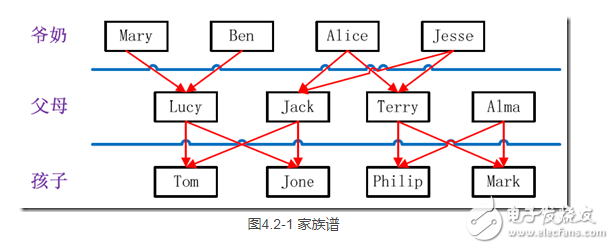
樣例輸出如下所示。
file:
grandchild grandparent
Tom Alice
Tom Jesse
Jone Alice
Jone Jesse
Tom Mary
Tom Ben
Jone Mary
Jone Ben
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
4.2 設計思路
分析這個實例,顯然需要進行單表連接,連接的是左表的parent列和右表的child列,且左表和右表是同一個表。
連接結果中除去連接的兩列就是所需要的結果——“grandchild--grandparent”表。要用MapReduce解決這個實例,首先應該考慮如何實現表的自連接;其次就是連接列的設置;最后是結果的整理。
考慮到MapReduce的shuffle過程會將相同的key會連接在一起,所以可以將map結果的key設置成待連接的列,然后列中相同的值就自然會連接在一起了。再與最開始的分析聯系起來:
要連接的是左表的parent列和右表的child列,且左表和右表是同一個表,所以在map階段將讀入數據分割成child和parent之后,會將parent設置成key,child設置成value進行輸出,并作為左表;再將同一對child和parent中的child設置成key,parent設置成value進行輸出,作為右表。為了區分輸出中的左右表,需要在輸出的value中再加上左右表的信息,比如在value的String最開始處加上字符1表示左表,加上字符2表示右表。這樣在map的結果中就形成了左表和右表,然后在shuffle過程中完成連接。reduce接收到連接的結果,其中每個key的value-list就包含了“grandchild--grandparent”關系。取出每個key的value-list進行解析,將左表中的child放入一個數組,右表中的parent放入一個數組,然后對兩個數組求笛卡爾積就是最后的結果了。
4.3 程序代碼
程序代碼如下所示。
package com.hebut.mr;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class STjoin {
public static int time = 0;
/*
* map將輸出分割child和parent,然后正序輸出一次作為右表,
* 反序輸出一次作為左表,需要注意的是在輸出的value中必須
* 加上左右表的區別標識。
*/
public static class Map extends Mapper《Object, Text, Text, Text》 {
// 實現map函數
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String childname = new String();// 孩子名稱
String parentname = new String();// 父母名稱
String relationtype = new String();// 左右表標識
// 輸入的一行預處理文本
StringTokenizer itr=new StringTokenizer(value.toString());
String[] values=new String[2];
int i=0;
while(itr.hasMoreTokens()){
values[i]=itr.nextToken();
i++;
}
if (values[0].compareTo(“child”) != 0) {
childname = values[0];
parentname = values[1];
// 輸出左表
relationtype = “1”;
context.write(new Text(values[1]), new Text(relationtype +
“+”+ childname + “+” + parentname));
// 輸出右表
relationtype = “2”;
context.write(new Text(values[0]), new Text(relationtype +
“+”+ childname + “+” + parentname));
}
}
}
public static class Reduce extends Reducer《Text, Text, Text, Text》 {
// 實現reduce函數
public void reduce(Text key, Iterable《Text》 values, Context context)
throws IOException, InterruptedException {
// 輸出表頭
if (0 == time) {
context.write(new Text(“grandchild”), new Text(“grandparent”));
time++;
}
int grandchildnum = 0;
String[] grandchild = new String[10];
int grandparentnum = 0;
String[] grandparent = new String[10];
Iterator ite = values.iterator();
while (ite.hasNext()) {
String record = ite.next().toString();
int len = record.length();
int i = 2;
if (0 == len) {
continue;
}
// 取得左右表標識
char relationtype = record.charAt(0);
// 定義孩子和父母變量
String childname = new String();
String parentname = new String();
// 獲取value-list中value的child
while (record.charAt(i) != ‘+’) {
childname += record.charAt(i);
i++;
}
i = i + 1;
// 獲取value-list中value的parent
while (i 《 len) {
parentname += record.charAt(i);
i++;
}
// 左表,取出child放入grandchildren
if (‘1’ == relationtype) {
grandchild[grandchildnum] = childname;
grandchildnum++;
}
// 右表,取出parent放入grandparent
if (‘2’ == relationtype) {
grandparent[grandparentnum] = parentname;
grandparentnum++;
}
}
// grandchild和grandparent數組求笛卡爾兒積
if (0 != grandchildnum && 0 != grandparentnum) {
for (int m = 0; m 《 grandchildnum; m++) {
for (int n = 0; n 《 grandparentnum; n++) {
// 輸出結果
context.write(new Text(grandchild[m]), newText(grandparent[n]));
}
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 這句話很關鍵
conf.set(“mapred.job.tracker”, “192.168.1.2:9001”);
String[] ioArgs = new String[] { “STjoin_in”, “STjoin_out” };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println(“Usage: Single Table Join 《in》 《out》”);
System.exit(2);
}
Job job = new Job(conf, “Single Table Join”);
job.setJarByClass(STjoin.class);
// 設置Map和Reduce處理類
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
// 設置輸出類型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 設置輸入和輸出目錄
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.4 代碼結果
1)準備測試數據
通過Eclipse下面的“DFS Locations”在“/user/hadoop”目錄下創建輸入文件“STjoin_in”文件夾(備注:“STjoin_out”不需要創建。)如圖4.4-1所示,已經成功創建。
?
然后在本地建立一個txt文件,通過Eclipse上傳到“/user/hadoop/STjoin_in”文件夾中,一個txt文件的內容如“實例描述”那個文件一樣。如圖4.4-2所示,成功上傳之后。
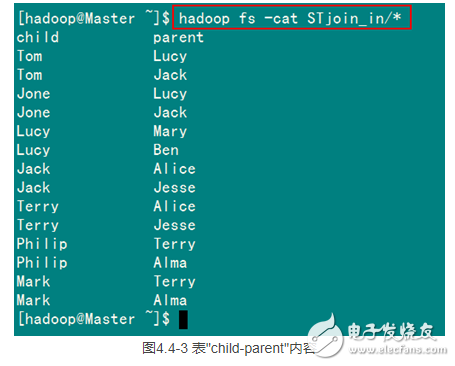
從SecureCRT遠處查看“Master.Hadoop”的也能證實我們上傳的文件,顯示其內容如圖4.4-3所示:
?
2)運行詳解
(1)Map處理:
(2)Shuffle處理
在shuffle過程中完成連接。
(3)Reduce處理
首先由語句“0 != grandchildnum && 0 != grandparentnum”得知,只要在“value-list”中沒有左表或者右表,則不會做處理,可以根據這條規則去除無效的shuffle連接。
然后根據下面語句進一步對有效的shuffle連接做處理。
// 左表,取出child放入grandchildren
if (‘1’ == relationtype) {
grandchild[grandchildnum] = childname;
grandchildnum++;
}
// 右表,取出parent放入grandparent
if (‘2’ == relationtype) {
grandparent[grandparentnum] = parentname;
grandparentnum++;
}
針對一條數據進行分析:
《Jack,1+Tom+Jack,
1+Jone+Jack,
2+Jack+Alice,
2+Jack+Jesse 》
分析結果:左表用“字符1”表示,右表用“字符2”表示,上面的《key,value-list》中的“key”表示左表與右表的連接鍵。而“value-list”表示以“key”連接的左表與右表的相關數據。
根據上面針對左表與右表不同的處理規則,取得兩個數組的數據。
然后根據下面語句進行處理。
for (int m = 0; m 《 grandchildnum; m++) {
for (int n = 0; n 《 grandparentnum; n++) {
context.write(new Text(grandchild[m]), new Text(grandparent[n]));
}
}
處理結果如下面所示:
Tom Jesse
Tom Alice
Jone Jesse
Jone Alice
其他的有效shuffle連接處理都是如此。
3)查看運行結果
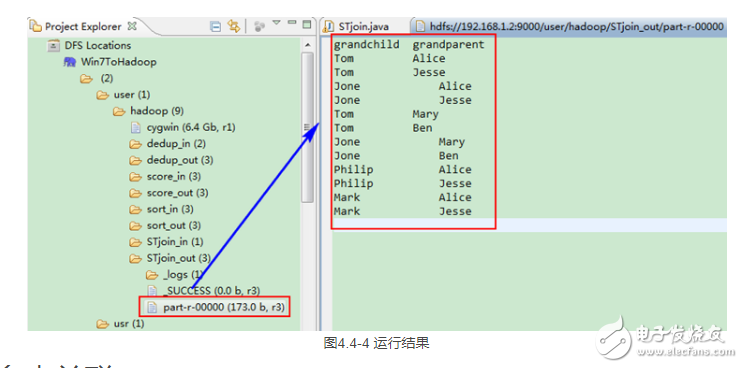
這時我們右擊Eclipse 的“DFS Locations”中“/user/hadoop”文件夾進行刷新,這時會發現多出一個“STjoin_out”文件夾,且里面有3個文件,然后打開雙 其“part-r-00000”文件,會在Eclipse中間把內容顯示出來。如圖4.4-4所示。
?











 工商網監
工商網監
評論