 電子發燒友App
電子發燒友App


1 簡介
在DMA控制器加入仲裁模塊,對多個傳輸請求進行排序,通過存儲器配置模式減少CPU 的配置時間和中斷次數,但還不能保證對多任務傳輸的寬帶需求;也有把傳輸任務分為實時任務和非實時任務的,按實時優先級實現系統的實時傳輸,但是仍需系統對任務進行優先級排序,占用系統處理時間;分別通過預存取和寫循環、加入重排列單元、鏈模式和雙緩沖器以及采用不同大小的緩存等方法提高 DMA 控制器的傳輸效率。但這些改進方法均只能保證 DMA 控制器在同一時間傳輸單一任務,為了實現系統多任務實時傳輸,本文擬引入Crossbar 交換結構,并設計相應的多通道傳輸 DMA控制器,保證系統多任務傳輸的同時提高系統響應的實時性
為了具體介紹本多通道 DMA 控制器的設計方案,下面首先對基于 Crossbar 的多通道 DMA 控制器的工作原理進行詳細分析,接著具體說明各個模塊的設計實現,然后對設計進行驗證和分析比較實驗結果,并進行總結。
2 多通道DMA控制器
傳統 DMA 控制器是采用共享總線方式來實現數據傳輸的,系統實現數據傳輸的過程為:(1)首先設備向 DMAC 發出 DMA 請求。(2)DMAC 接到設備請求后,向 CPU 發出總線請求,請求接管系統總線。(3)CPU 在執行完當前指令周期后,向 DMAC發出總線響應信號。(4)CPU 脫離對系統總線的控制,DMAC 接管控制系統總線。(5)DMAC 向設備發出應答信號。(6)DMAC 在存儲器與設備之間進行數據傳輸。(7)當設定的數據傳輸完后,DMAC 撤銷總線請求信號,同時脫離對總線的控制,CPU 檢測到總線請求信號變為無效后,撤銷總線響應信號,恢復對系統總線的控制,同時跳回到中斷前的狀態。
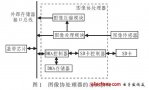
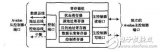
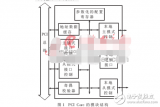
但對于如圖 1 所示的典型多媒體應用系統,內部有哈夫曼解碼模塊(Huffman Decoder)、圖像解碼模塊 (MPEG Decoder)、USB 模塊、SPI 模塊、SD 卡控制模(SDC)和數模轉換模塊(DAC)等,哈夫曼解碼模塊和圖像解碼模塊需要跟 USB 模塊、SD卡控制模塊或 SPI 模塊通信,即同時存在幾路數據傳輸并且傳輸數據的模塊是變化的,采用共享總線的 DMA 控制器無法同時處理多個通道任務,現有的多通道 DMA 控制器交換數據的設備只能是固定的,因而無法勝任這種系統需求。對于這類應用需要,本文引入了 Crossbar 互聯結構,用 Crossbar 總線來代替共享總線。Crossbar 被稱為交叉開關矩陣或縱橫式交換矩陣,不會因為帶寬資源不夠而產生阻塞 [8]。圖 2 所示是全 Crossbar 總線拓撲結構的原理圖。由于全 Crossbar 總線所需連接線數量較多, 在實際中經常簡化為部分 Crossbar 總線拓撲結構, 即將不需要通信的模塊間的連接去掉,以節省面積。
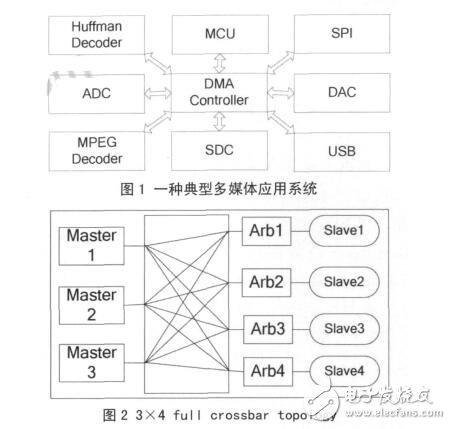
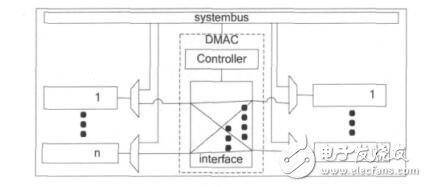
Crossbar 的互聯結構實現在 MDMAC 的接口模塊中,作為 DMA 傳輸的局部總線,DMA 傳輸不再占用系統總線,因此可以和 CPU 并行工作。所有需要采用 DMA 式傳輸數據的設備都直接掛接在該接口模塊上,而由于這些設備也需要同系統總線通信,所以每個設備需要附加一個多路選擇單元,以選擇來自系統總線的信號或是來自 MDMAC 的信號。MDMAC 的接口模塊實現了全 Crossbar 的互聯結構,其和設備的連接及系統總線的連接方式如圖 3所示,處于圖中左邊的任意設備可以和圖中右邊的任意設備進行 DMA 方式的數據傳輸。由于可以根據具體的應用來設計接口模塊中設備端口的個數,所以可以保證系統中所有的 DMA 傳輸都能并行進行,而不需要像傳統 DMA 控制器,要通過一定的仲裁算法來對多個傳輸請求進行排序,使得傳輸時間不能保證,并且仲裁模塊會引入較大的延時,使得傳輸響應變慢。
3 設計與實現方案
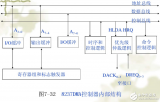
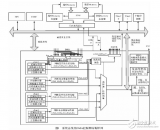
根據上述多通道 DMA 控制器的基本原理,可以按如圖 4 結構來設計實現該多通道 DMA 控制器,其組成模塊可以分為 4 部分:寄存器模塊Registers, 控 制 模 塊 Controlunit, 地 址 產 生 模 塊Addressgen 和接口模塊 Interface。下面詳細介紹各模塊的具體設計與實現方案。

3.1 寄存器模塊
Registers 寄存器模塊集合了控制器的各種寄存器,包括全局寄存器和各個通道的專用寄存器,控制器和系統微處理器的交互主要靠這些寄存器來完成。全局寄存器對所有的通道都有效,包括配置寄取,不需要 CPU 的參與,直到整個描述符鏈表執行完再產生中斷通知 CPU,而傳統的 CPU 配置模式每執行完一個任務都要產生中斷,讓 CPU 對下一個任務進行配置。每次傳輸的發起可以有兩種模式,一種是軟件使能方式,即只要將寄存器的 start 位置 1 就開始脫離 Idle 狀態;另一種是硬件握手方式,寄存器的 start 位置 1 后,還需要有傳輸請求的模塊發來申請并等待 MDMAC 確認后傳輸才開始。軟件使能方式適用于數據復制操作,CPU 將某一地址區間的數據轉移到另一地址區間。硬件握手方式是傳統的DMA 工作方式。
3.3 地址產生模塊
Addressgen 地址產生模塊主要由加法器組成,產生傳輸的源地址和目的地址,加法器的設計采用兩級流水線技術,以減少運算的延時。源地址和目的地址的控制邏輯是獨立的,但它們都受傳輸量的約束,當傳輸完成時它們都保持著當前地址,直到被重新賦值或復位。源地址和目的地址可以配置為兩種變化模式。一種是逐步加 1 模式,由最初設定的起始操作地址開始,每對外讀取或者寫入一個地址單元后輸出地加 1,適合于對連續地址空間搬移數據。另一種是保持不變模式,即在傳輸過程中輸出地址一直保持最初設定的起始操作地址,此種模式適用于對象是緩存器 FIFO 的情況,因為 FIFO 只有一個入口寄存器,通過對這個入口寄存器操作就可以訪問 FIFO 內部的數據。輸出地址的各個位都設置了屏蔽功能,這樣在對某個連續地址區間寫入數據時,可以通過屏蔽某些地址位來保護某些地址單元的值不被覆蓋。
3.4 接口模塊
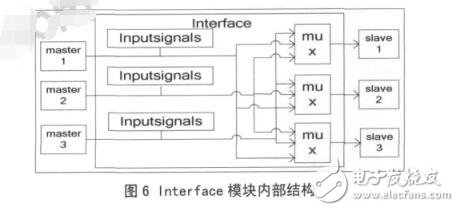
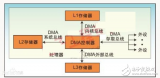
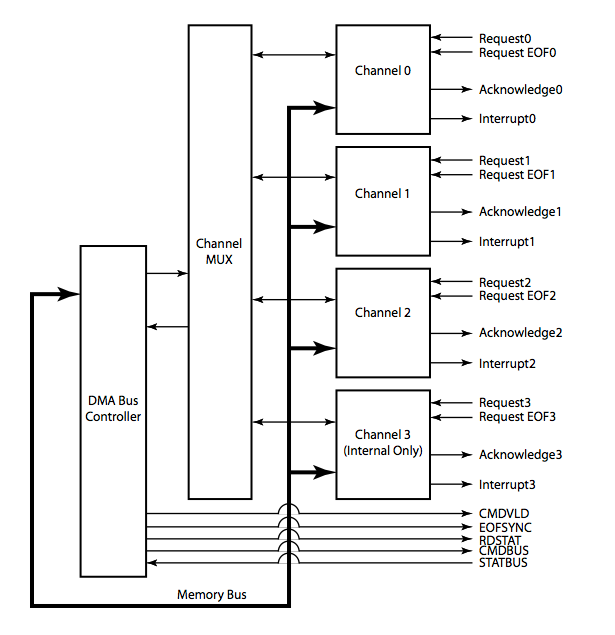
Interface 接口模塊內部結構框圖如圖 6 所示,實現接口的 Crossbar 互聯結構,向外界輸出多路源和目的設備的地址、數據和讀寫控制等信號,這些信號由圖中的 Inputsignals 部分輸入。mux 部分根據控制寄存器的配置選通連 接的 master 和 slave。本MDMAC 不同于共享總線型的 DMAC,它可以同時傳輸幾個任務,并且任意設備間都可以進行任務傳輸,而不是固定某兩個模塊間才能進行通信。本文實現了一個可以同時處理 3 個通道的控制器,3 個源連接端口和 3 個目的連接端口,默認連接是源端口0 連接目的端口 0,源端口 1 連接目的端口 1,源端口 2 連接目的端口 2。在使用過程中可以通過寄存器設置任意的源端口連接任意的目的端口,即是一個 3×3 的全 Crossbar 連接。這三個通道是互相獨立的,傳輸任務互不影響,也不必同時開始工作。
4 實驗結果
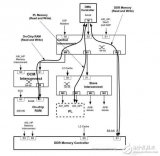
本文首先在 modelsim6.5 中對設計進行仿真,3個源端口和 3 個目的端口分別連接著一個存儲器RAM。分別仿真了單個通道操作,多個通道同時操作,多個通道不同時操作,通過系統總線配置,通過描述符配置,軟件使能傳輸,硬件握手傳輸等模式。本文設計了一個系統在 FPGA 上運行,系統的內部框圖如圖 7 所示,采用 Xilinx 的 virtex5 開發板。圖中的 USB 模塊是一個 USB1.1 主機控制器,里面包含一個64字節的緩存器 FIFO。USB 主機控制器和存儲器 Memory3 連接在 MDMAC 的源端口,存儲器Memory1 和存儲器 Memory2 連接在目的端口。USB主機控制器從 U 盤讀取數據到其內部的 FIFO,然后使能MDMAC 把 FIFO 中 的 數 據 搬 移 到 Memory1中,與此同時,另一個通道把 Memory2 中的數據復制搬移到 Memory3 中,然后通過串口把搬移后的數據輸出到 PC 機上的超級終端顯示出來。圖 8 上顯示的是從 U 盤第 0 扇區讀出的內容,由于編程直接使用 keil 軟件提供的打印函數,該函數顯示的數據是 16 位的,故圖中每個數據的后兩個數字都是無效的。用 winhex 軟件讀取 U 盤里面的內容,傳輸前后的內容一致。
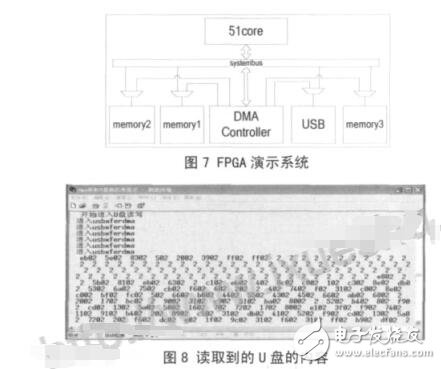
圖9 是3個通道同時操作的仿真波形圖,其中源端口 0 連接目的端口 1,源端口 1 連接目的端口2,源端口 2 連接目的端口 0,圖中的 m 表示源端口,s 表示目的端口。對于傳統 DMA,必 須等待一個任務傳輸完畢后才能傳輸下一個任務,因此不能保證將相關數據實時地傳輸到目的地址,圖 9 顯示了本文設計的 MDMAC 能夠同步地處理多個任務,因此比傳統 DMAC 更能適應實時性系統的要求。

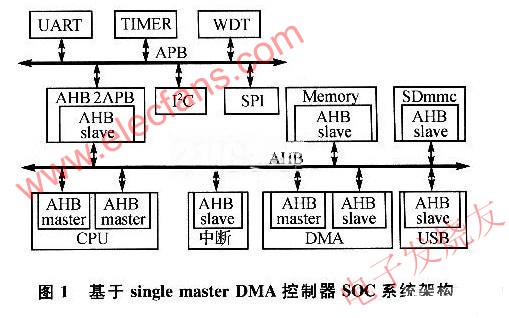
本文設計的 MDMAC 在 Xilinx 的 xc5vlx110t 上實現的最大頻率是 232MHZ,每兩個時鐘周期可以傳輸一個字節的數據,若3個通道同時工作,則最大的 數 據 吞 吐 率 可 達 348MB/s, 表1給出幾種DMAC 在 FPGA 上實現的最大吞吐率的對比。其中文獻[6]得出的結論是采用其提出的鏈模式對于提高數據吞吐率的貢獻在于減少了相連傳輸任務之間的中斷服務時間,本文提出的多通道模式不但在單個通道的實現上采用了類似的優化方式,而且多通道同時工作的模式也包含了類似的優化思想,因為這省去了傳統 DMA 機制中多個設備同時發起請求時仲裁排序和切換服務對象的時間,并且,由于多個通道同時工作,整個系統的數據吞吐率得到了很大的提高。
本文采用標準的180nmCMOS工藝庫 ,在Design Compiler中對MDMAC進行了綜合 ,在300MHZ的時鐘頻率下 ,綜合出的面積是104322.6μm2,功耗是 13.1mW。為了進行比較,本文還設計了一個沒有 Crossbar 互聯接口功能而其他功能完全一樣的 DMAC,在同樣的約束環境下,在300MHZ 的 時 鐘 頻 率 下 綜 合 出 的 面 積 是46037. 4μm2,功耗是 6.5mW。數據吞吐率的提高有可能是以面積或功耗為代價的,為了說明數據吞吐率的改進效率,本文采用在每單位消耗(面積或功耗)上數據吞吐率的相對大小來衡量,本文定義一個變量 η 為數據吞吐率和面積的比,即每單位面積的平均數據吞吐率,ζ 為數據吞吐率與功耗的比,即每單位功耗的平均數據吞吐率。設傳統DMAC的數據吞吐率,功耗和面積都為 1,則 ηt=1,t=1,其中下標 t 表示傳統 DMAC。本 MDMAC 當 3 個通道同時工作時其數據吞吐率達到最大,為 3,面積為104322.6 /46037.4 = 2.3,則其 ηc = 3/2.266 = 1.3,下標 c 表示本文設計的 MDMAC,功耗為 13.1/6.5 =2.0,則其 c = 3/2.0 = 1.5,兩種 DMAC 的比較結果如表 2 所示。可見,本 MDMAC 比幾個傳統 DMAC協同使用更有效率,這是因為省去了仲裁單元并且某些控制邏輯可以復用。

5 結論
本文給出了一種基于 Crossbar 的多通道DMA方案,并用硬件實現了這種 DMA 控制器,它可以同時服務多個通道,接口采用了全 Crossbar 的拓撲結構。所設計的方案在 virtex5 開發板上通過了驗證,其最大的數據吞吐率可達 348MB/s,經采用標準180nm 工藝綜合,其吞吐率和面積比是傳統 DMA控制器的 1.3 倍,吞吐率和功耗比達到 1.5 倍。















 工商網監
工商網監
評論