 電子發燒友App
電子發燒友App


AMD的Phoenix SoC在移動和小型化領域取得了重要突破,這將改變很多東西。

●AMD的Ryzen?7040
AMD的移動和小型化之路曾一度艱辛。早在2010年代初期,英特爾在能效方面取得了巨大的進步,而AMD的基于Bulldozer的CPU核心在這方面沒有機會。Zen架構縮小了差距,但AMD仍然需要付出大量努力。空閑功耗仍然不及英特爾。GPU方面,由于AMD收購了ATI,所以它在這方面更強大,但AMD的集成GPU常常使用過時的圖形架構。即使在獨立的GCN GPU上市后,APU上仍然使用Terascale 3架構。2021年,AMD推出了搭載Vega(改進的GCN)顯卡的Ryzen 7 5800H,但當時桌面GPU已經過渡到使用RDNA 2。
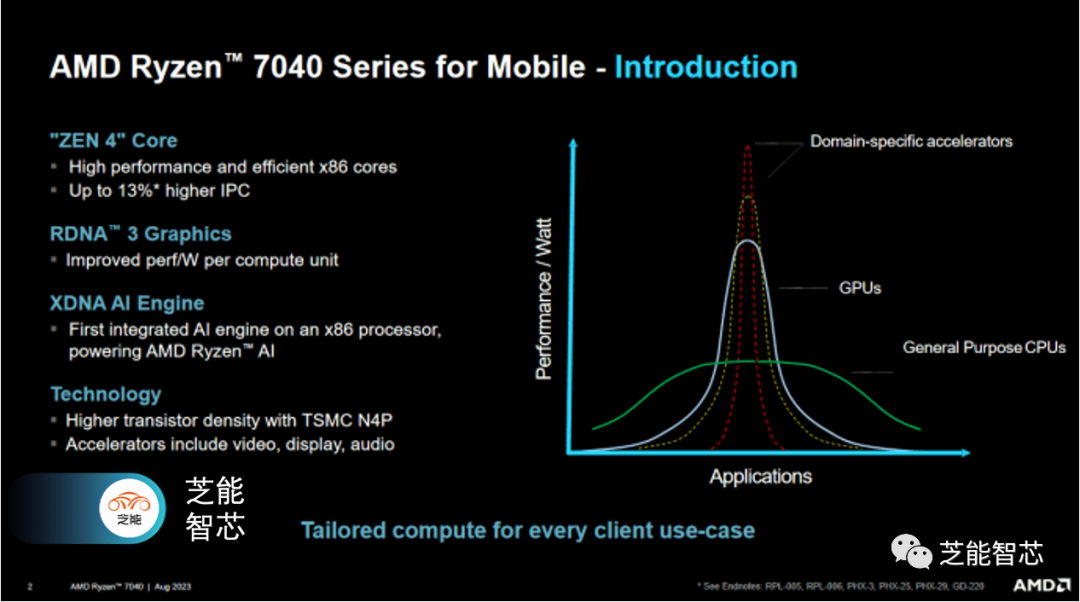
AMD的產品已經扭轉了這一局面。Van Gogh(Steam Deck APU)和Rembrandt終于將RDNA 2引入了集成GPU中。而Phoenix則邁出了正確方向的又一步,將當前一代的Zen 4核心和RDNA 3顯卡整合到了一個強大的芯片中。除了使用最新架構的重要CPU和GPU之外,Phoenix還集成了各種加速器,以提高特定應用程序的能效。英特爾早已整合了像GNA AI加速器這樣的加速器,而AMD則希望迎頭趕上。XDNA加速器有助于機器學習推理,音頻控制器則可以卸載CPU的信號處理。對于移動SoC來說,Phoenix還配備了強大的視頻引擎。

Phoenix采用了TSMC的N4工藝制造,占據了178平方毫米的面積。芯片擁有254億個晶體管,將Zen 4核心與RDNA 3圖形整合在一起。除了重要的CPU和GPU之外,AMD還添加了一些支持性的IP塊,用于加速機器學習推理和信號處理。Phoenix的芯片尺寸比AMD之前的Rembrandt要小,可以容納在相同的25x35毫米BGA封裝中。

●CPU方面
Phoenix擁有8個Zen 4核心的集群,Phoenix采用了不同的高速緩存設置,只有16MB的L3緩存(而不是通常的32MB)。AMD可能將L3切片縮小到每個核心2MB,以減少芯片面積的使用。
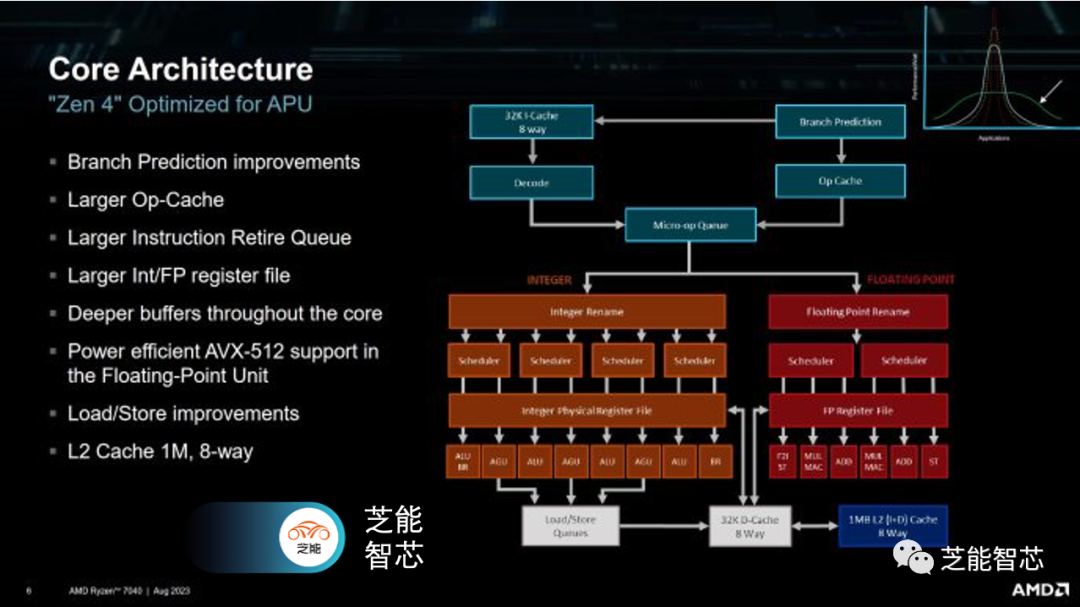
根據測試,延遲與臺式機上的Zen 4相同。實際的延遲可能會稍微差一些,因為臺式機上的Zen 4頻率更高。例如,Ryzen 9 7950X3D的非VCache芯片在16MB的測試大小下延遲為8.85納秒。而Ryzen 7 7840HS在10MB的測試大小下延遲為10.92納秒。部分差距是因為HP堅持將時鐘速度限制在4.5 GHz,盡管7840HS應該能夠提升至5.1 GHz。
Phoenix的內存控制器支持DDR5和LPDDR5。對于功耗至關重要的手持設備來說,LPDDR5尤其有用。與LPDDR5一起的內存延遲更高,為119.81納秒。然而,與Van Gogh相比,AMD已經大幅改進了LPDDR5的延遲,Van Gogh在CPU核心訪問DRAM時延遲很高。
Infinity Fabric 帶寬
CPU集群通過每個時鐘周期32字節的Infinity Fabric鏈路與系統的其余部分進行通信。與臺式機設計不同,其中寫路徑是寬度的一半,CPU到Fabric的寫路徑也可以處理每個周期32字節。這在實際工作負載中幾乎不太可能影響性能,因為我沒有看到任何單個核心需要超過30 GB/s的寫入帶寬的工作負載。多線程的工作負載可能需要更多的帶寬,但也可以分配到不同的CCX。
AMD已經實現了寫入優化,以減少Infinity Fabric的流量。通過使用CLZERO清零緩存行時,單個7950X3D CCD的寫入帶寬可以超過68 GB/s。清零內存是相當常見的,因為程序將初始化內存以確保新分配的內存處于已知狀態。操作系統通常也會這樣做。如果應用程序使用已識別的方法清零內存,可以看到比通用測試所建議的更高的有效寫入帶寬。
Infinity Fabric 優化
Infinity Fabric是AMD的一種一致性互連。在功耗方面,它至關重要,因為互連功耗可能占芯片功耗的相當大一部分,特別是在不是完全推動計算的工作負載中。AMD對各種工作負載進行了分析,并根據工作負載是否受到計算限制、IO限制或具有非常特定的特征(如視頻會議)來設置Phoenix的Infinity Fabric,使其進入不同的操作模式。
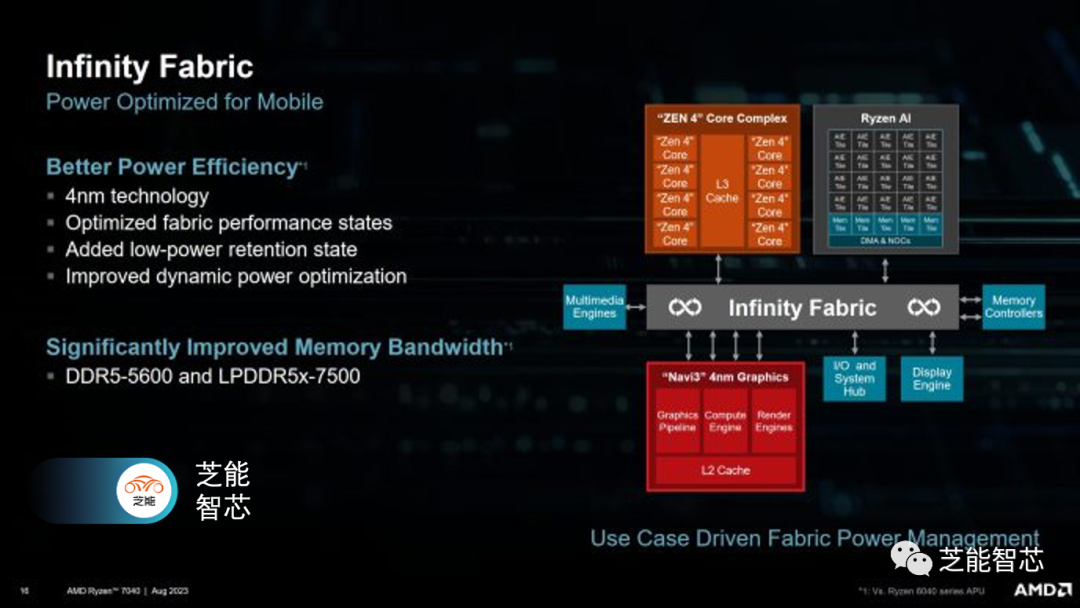
這些優化避免了Van Gogh的問題,因為它在CPU側帶寬上限制在約25 GB/s,這要歸功于一個在有限的功耗預算內高度優化用于游戲的Infinity Fabric實現。在Cheese的HP筆記本上,根據工作負載不同,Infinity Fabric時鐘也會有所變化:

AMD在GPU拉取大量帶寬時使用低速Fabric時鐘以提高能效。GPU具有四個32B/周期的端口與Fabric相連,即使在低速Fabric時鐘下,也可以獲得足夠的內存帶寬。由于客戶程序通常對延遲比帶寬更敏感,因此CPU工作負載獲得了更高的Fabric時鐘,從而改善了延遲。與Renoir不同,Phoenix的可變Infinity Fabric時鐘與生成內存流量的組件無關時都會降至1.6 GHz。
為了進一步節省功耗,AMD積極追求功耗和時鐘門控的機會。新的Z8睡眠狀態允許在短暫的閑置期間進行功耗和時鐘門控,例如在按鍵之間,而不會感知到喚醒時間。在視頻播放期間,Phoenix可以實現較高的Z8狀態停留,這表明媒體引擎的緩沖區和高速緩存足夠大,可以允許它進行短暫的內存訪問。

來自優化各種物理接口也帶來了額外的節能。內存控制器可以根據需要動態更改時鐘和電壓狀態。多年來一直在使用的USB 2.0接口竟然具有許多功耗優化機會,因此AMD也進行了調整。
GPU方面
Phoenix的GPU基于AMD當前一代的RDNA 3架構,獲得了合適的“Radeon 780M”名稱,而不僅僅是被稱為Vega或gfx90c。它具有六個WGPs,總共有768個SIMD單元,每個周期能夠執行1536個FP32操作。這些單元分為兩個著色器數組,每個著色器數組具有256KB的中級高速緩存。2MB的L2高速緩存有助于隔離iGPU與DRAM,對iGPU的性能非常重要。與Van Gogh相比,Phoenix的L2高速緩存多一倍,內存帶寬稍多,并且具有50%更多的SIMD單元。

與RX 7600相比,L0、L1和L2的延遲與RX 7600相比相當相似,盡管由于更高的時鐘速度,獨立顯卡稍微快一些。DDR5使iGPU的每個SIMD操作的帶寬比臺式機GPU更高,因此無法證明將區域分配給另一級緩存。 DDR5的帶寬確實不容忽視。使用DDR5-5600或LPDDR5-5600,Phoenix可以實現比幾年前的Nvidia GDDR5配備的GTX 1050 3 GB更高的GPU端DRAM帶寬。每個引腳的5.6千兆位也比早期的GDDR5實現更快。
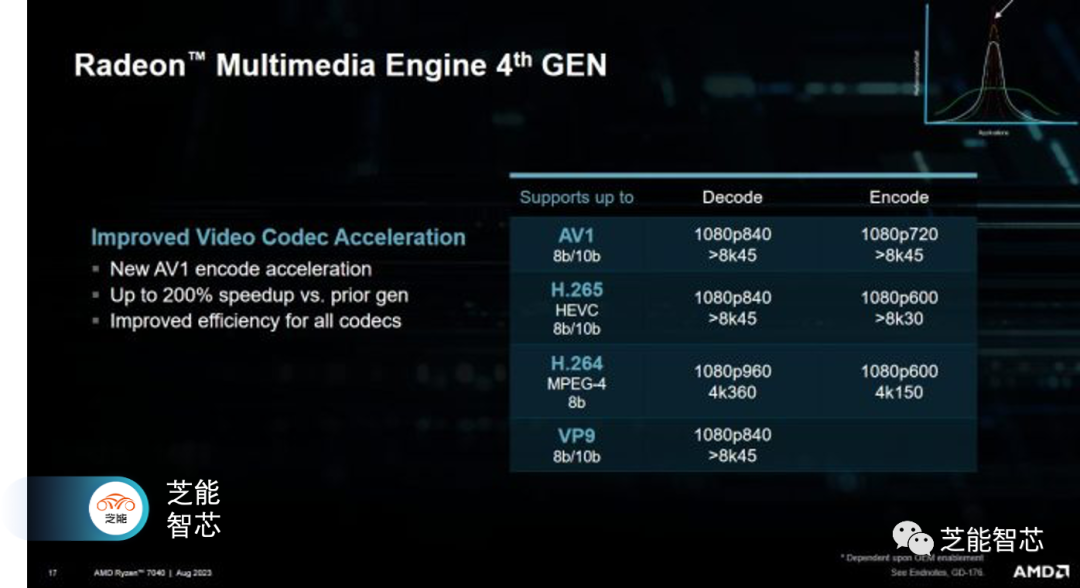
視頻引擎
RDNA 3配備了一個支持AV1的視頻引擎,這使得Phoenix更加具備未來的可擴展性,因為下一代視頻編解碼器開始獲得廣泛應用。雖然該引擎并不是新的,但AMD透露它使用了一種“競爭至空閑”的方案來節省電能。它還具有足夠的吞吐量,可以處理多個同時的視頻流,這對于視頻會議非常重要。
XDNA AI引擎
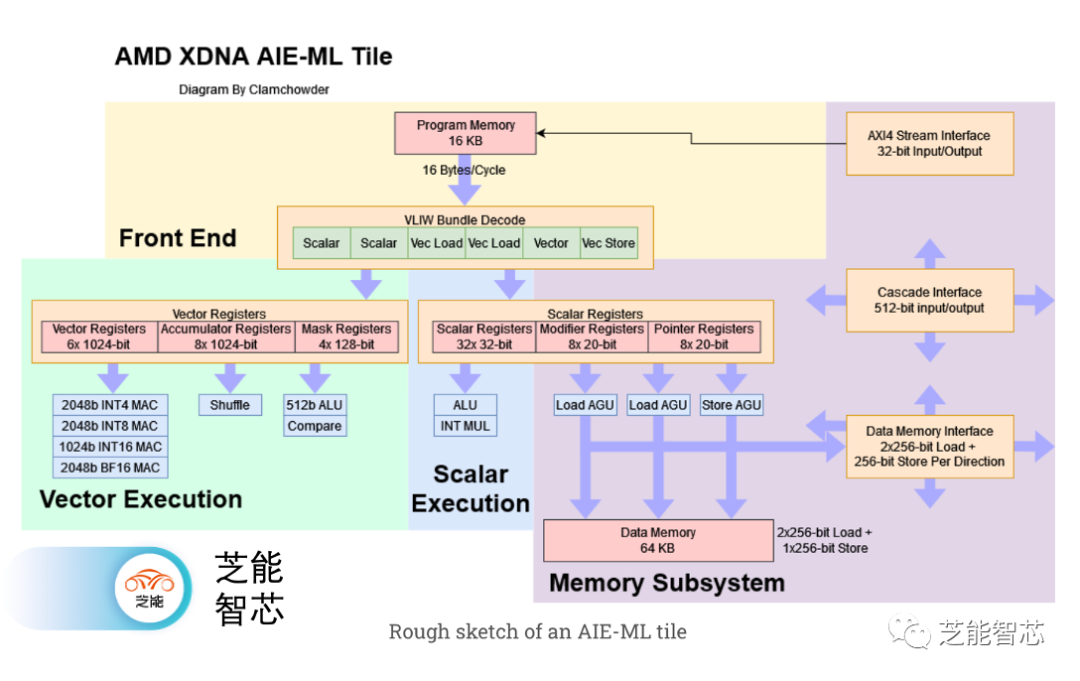
機器學習已經取得了很大的進展,AMD在Phoenix上加入了一個AI引擎(XDNA)來加速推斷。XDNA是使用Xilinx開發的架構構建的AIE-ML瓦片構建而成。Phoenix的XDNA實現具有16個AIE-ML瓦片,并且可以在空間上分區,以讓多個應用程序共享AI引擎。

XDNA的目標是實現足夠的吞吐量,以處理小型ML負載,同時實現非常高的能效。它以非常低的時鐘頻率運行,并使用非常寬的矢量執行。文檔表明,它的時鐘頻率為1 GHz,但Phoenix的XDNA可能以1.25 GHz運行,因為AMD表示支持BF16,具有5 TFLOPS的吞吐量。為了驅動非常寬的矢量單元,XDNA具有兩個矢量寄存器文件。
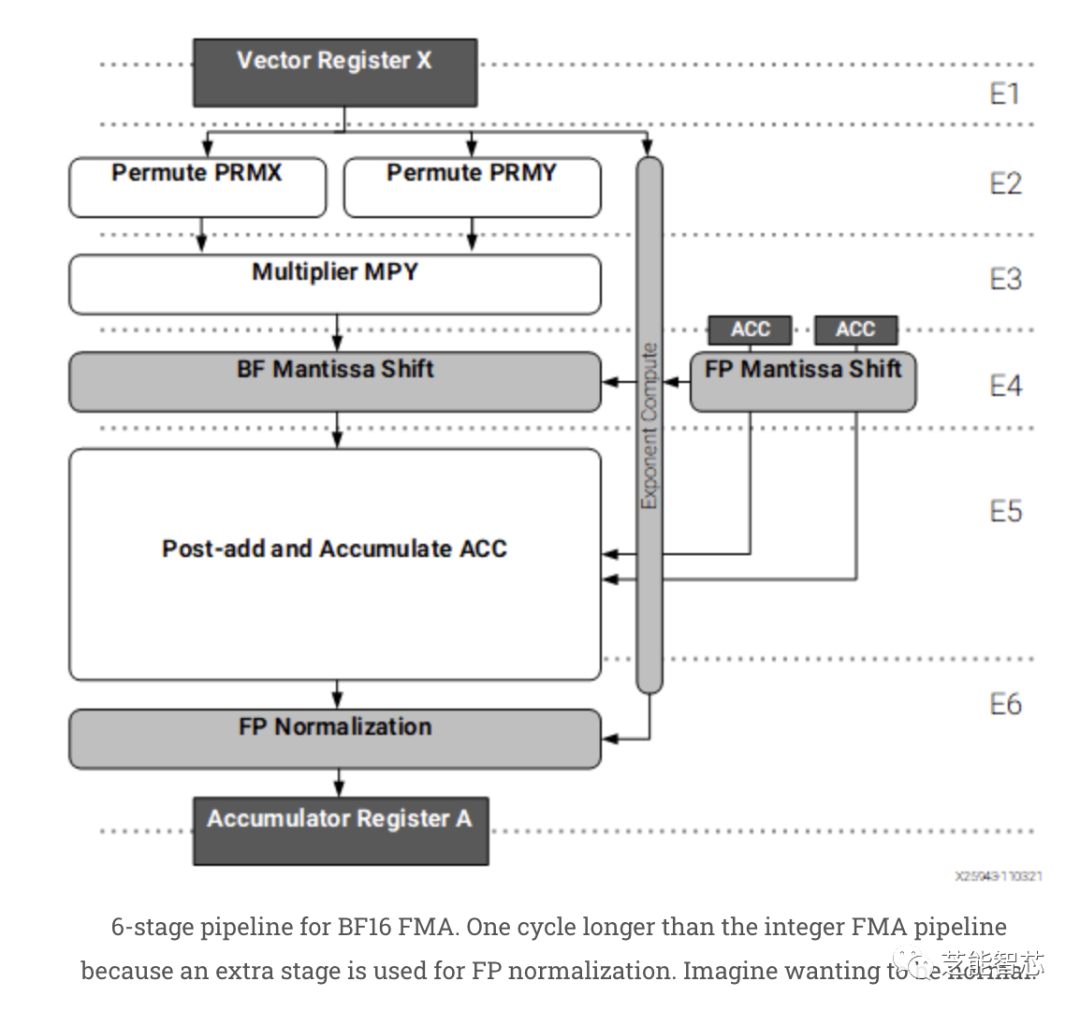
一個6KB的寄存器文件集提供乘法器輸入。單獨的8KB寄存器文件保存累加器值,并在乘加流水線的較后階段訪問。兩個寄存器文件可以以1024位、512位或256位的模式尋址,連續的256位寄存器形成512位或1024位的寄存器。
BF16 FMA的6級流水線。比整數FMA流水線多一個周期,因為多了一個階段用于FP規范化。乘加操作似乎具有5-6個周期的延遲,具體取決于是否需要FP規范化。對于以大約1 GHz運行的東西來說,這有點長,但XDNA會在其中提供排列。較簡單的512位加法和洗牌享有更快的3個周期延遲。
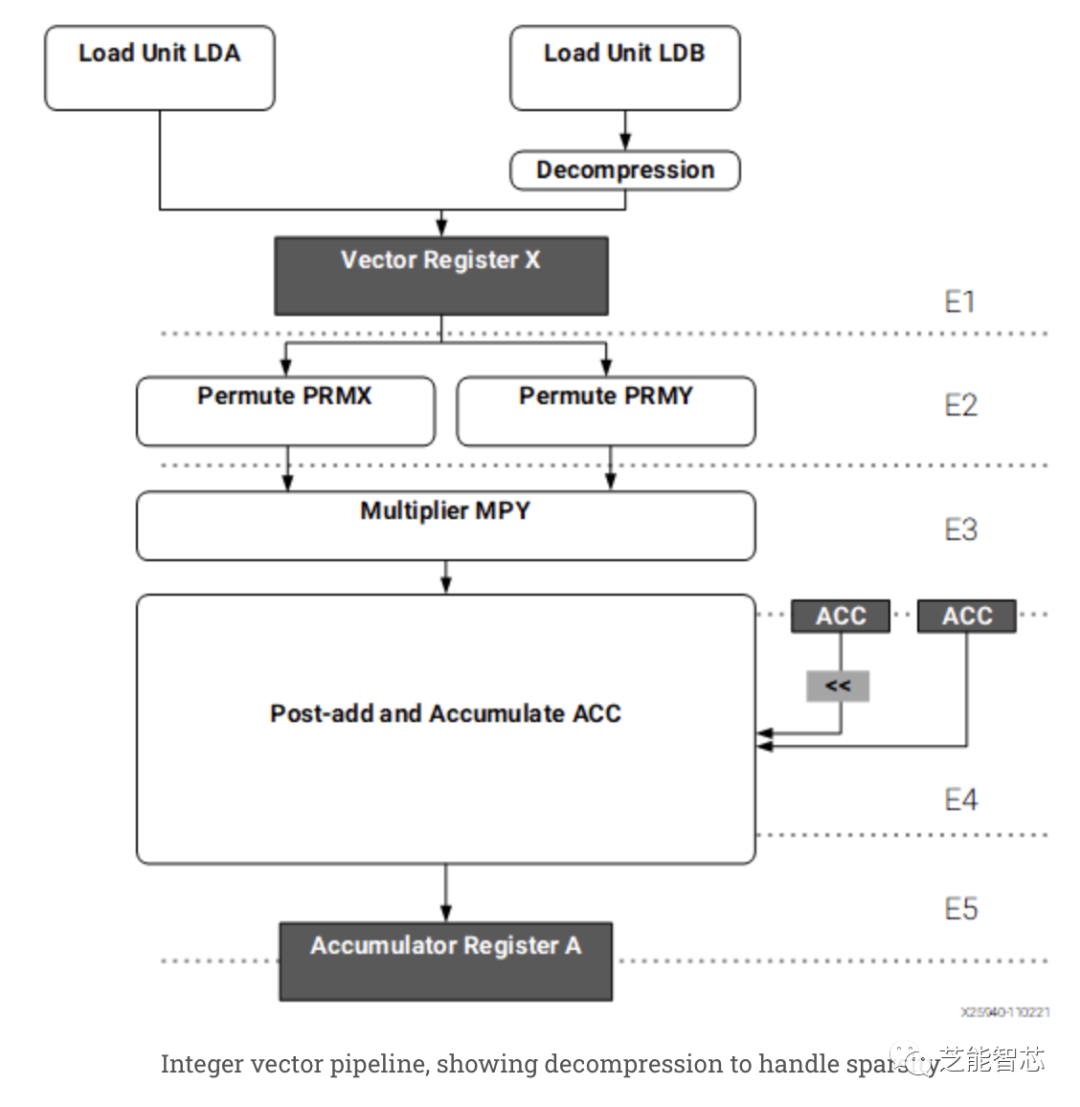
每個XDNA瓦片使用64 KB的直接尋址數據存儲器為其龐大的矢量單元提供數據存儲器。數據存儲器不是高速緩存,因此無需標簽檢查,可以節省功率。使用20位尋址進一步節省了電源,這對任何人來說都應該足夠。地址由三個AGU生成,它們在20位指針和修飾符寄存器上運行。在地址上使用單獨的寄存器并不是什么新鮮事(6502具有兩個索引寄存器),并且避免了主要標量寄存器文件上的六個額外端口。
整數矢量流水線,顯示處理稀疏性的解碼器步驟,64KB數據存儲器,指針寄存器,大數據運算單元Ryzen 7 7840HS以65W TDP運行,不過Phoenix設計的TDP范圍可能從35W到60W不等。默認配置下,Phoenix的XDNA瓦片可以實現4 TFLOPS的吞吐量,功耗僅為13W。如果整個芯片被配置為65W,則XDNA可以實現10 TFLOPS的吞吐量。
通過減小核心計數并提高XDNA時鐘,TDP可以進一步減少到35W。這將限制XDNA到2 TFLOPS,但在大多數筆記本中,可能不會發生這種情況。
Phoenix還有多個標量ALU,每個瓦片的流水線中有兩個整數算術單元,以及單個浮點乘法器和浮點加法器。流水線提供多達256位的寬度,并且為低延遲而優化。盡管AMD沒有詳細介紹流水線的結構,但它們似乎包括大量的特化邏輯,以加速整數算術。例如,一個6級流水線的int->int復制將會非常快。XDNA流水線還支持超標量整數操作,可以在多個流水線中同時執行。
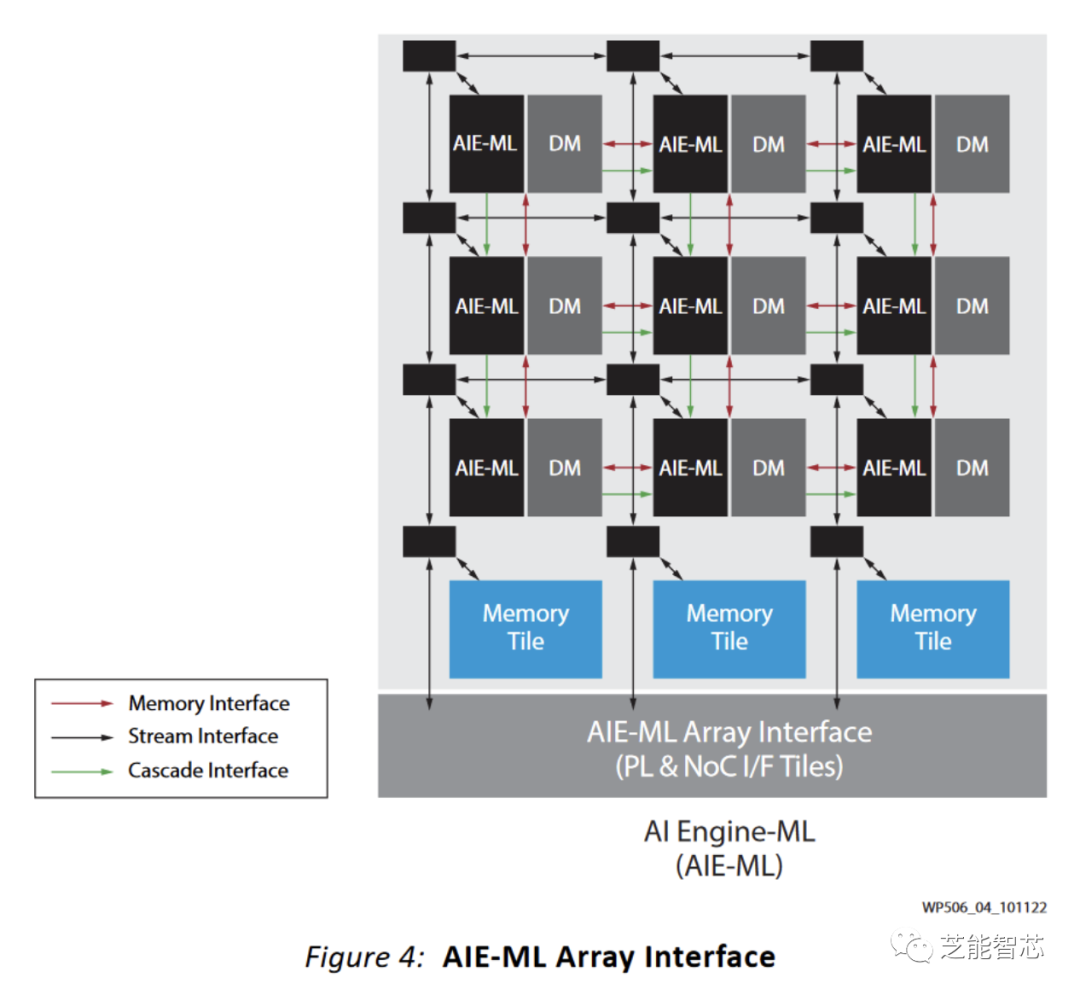
除了標量整數,XDNA流水線還可以執行標量邏輯和標量訪存。整數指令和邏輯指令可以同時執行,從而實現更高的吞吐量。 Phoenix的XDNA實現似乎沒有指令級并行性問題,可以以每個周期4條指令的吞吐量運行。這是因為乘加和邏輯單元是相互獨立的。

XDNA可以從LPDDR5內存訪問數據,與GPU一樣,它可以從完全不同的內存訪問。但是,GPU和XDNA之間的內存訪問共享是不太可能的,因為它們使用不同的地址空間。必須通過主機來傳輸數據。但是,由于LPDDR5具有足夠的帶寬,可以將數據傳輸到XDNA或GPU,而不必禁用著色器或ALU。 Phoenix的內存子系統可以實現與Van Gogh相同的DRAM帶寬,同時仍然具有內存訪問(可能會增加DRAM的帶寬要求)。
音頻
Phoenix的音頻控制器在一定程度上類似于AMD的CPU核心,它具有8個SIMD單元,可以通過VLIW進行調度。

可以高效地運行不同的聲音效果,并具有低時延。AMD還為Phoenix的音頻引擎提供了一個編程接口,使它能夠輕松支持不同的音頻引擎。這使得它可以與不同的操作系統和音頻處理軟件一起工作,而不必為不同的音頻引擎重新編寫代碼。
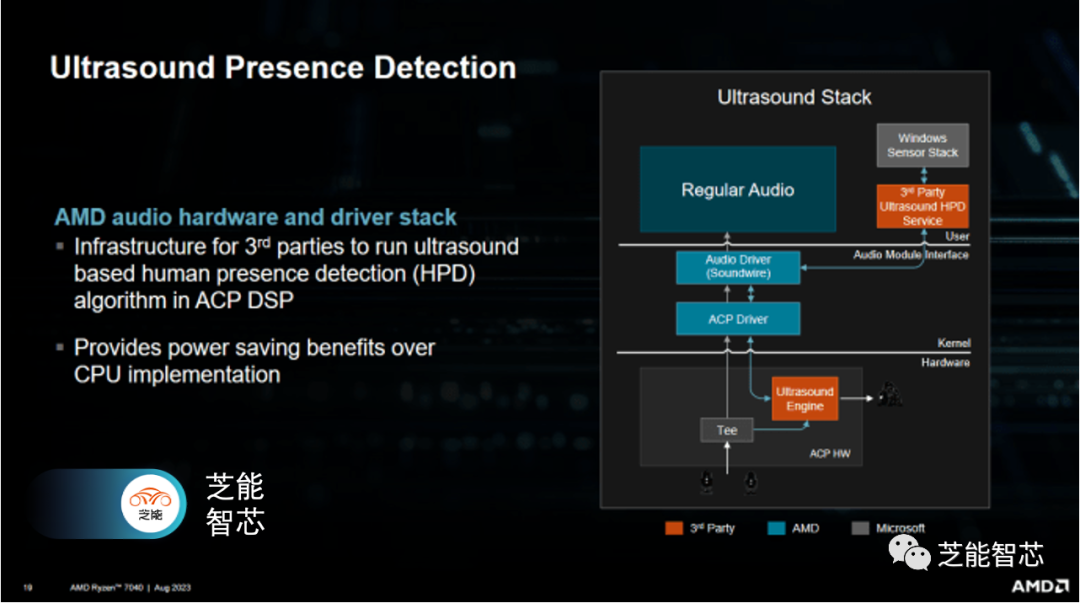
音頻引擎還支持高質量的音頻解碼,包括解碼壓縮的音頻格式,如MP3和AAC,還可以支持音頻編碼,允許用戶創建高質量的音頻內容。
總結
AMD的Phoenix SoC是一款非常令人印象深刻的移動芯片,將Zen 4 CPU核心和RDNA 3 GPU整合到一個緊湊的封裝中,還具有一系列加速器,包括XDNA AI引擎、視頻引擎和音頻控制器,為多種應用程序提供了高效的處理能力。Phoenix的CPU性能在移動領域應該是一流的,而GPU性能也足以運行現代游戲和圖形密集型應用程序。Phoenix的LPDDR5內存支持和高速緩存配置應該進一步提高系統的整體性能。

編輯:黃飛
?










 工商網監
工商網監
評論