 電子發燒友App
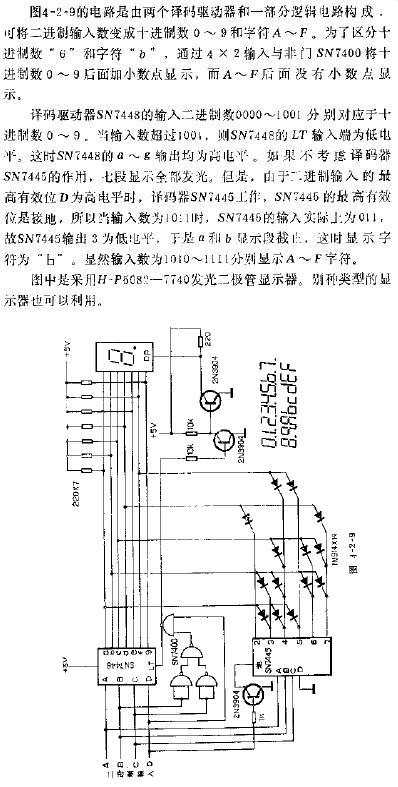
電子發燒友App


摘 要: 采用易于FPGA實現的歸一化最小和算法,通過選取合適的歸一化因子,將乘法轉化成移位和加法運算。在高斯白噪聲信道下,仿真該譯碼算法得出最佳的譯碼迭代次數,并結合Xilinx XC7VX485T資源確定量化位數。然后基于該算法和這3個參數設計了一種全新的、高速部分并行的DSC譯碼器。該譯碼器最大限度地實現了譯碼效率、譯碼復雜度、FPGA資源利用率之間的平衡,并在Xilinx XC7VX485T芯片上實現了該譯碼器,其吞吐率可達197 Mb/s。
?
0 引言
分布式信源編(DSC)解碼較傳統信道編解碼而言,因其編碼簡單、譯碼復雜成為近年來通信領域的研究熱點。DSC編碼端各信源獨立編碼,譯碼端根據信源的相關性聯合譯碼,從而降低了編碼的復雜度,而把整個系統的復雜度轉移到譯碼端,所以本文重點研究DSC譯碼器的設計。
Turbo碼和LDPC碼是實現DSC譯碼器的兩種主要編碼。在DSC譯碼過程中,Turbo碼譯碼算法復雜、譯碼延時長且存在一定的不可檢測錯誤,而LDPC碼具有較大的靈活性、較低的差錯平底特性、譯碼速度快、具有高效的譯碼迭代算法[1],因此LDPC碼更適合于實現DSC譯碼器。
LDPC碼分為規則LDPC碼和非規則LDPC碼,非規則LDPC碼的譯碼性能優于規則LDPC碼,是目前己知的最接近Shannon限的碼[2],所以本文采用非規則LDPC碼實現DSC譯碼器。
本文設計的DSC譯碼器具有反饋信道,根據當前聯合譯碼的結果把譯碼判決信息反饋到編碼端,但這種方法對實時性要求很高[3],這是限制DSC譯碼器工程應用的一個重要因素。FPGA由于其強大的數據并行處理能力,能夠做到數據處理的實時性、高效性。所以,FPGA能夠解決DSC譯碼器反饋信道實時性的問題。
Log-BP算法、BP-Based算法、歸一化最小和(NMS)算法是3種常用的DSC譯碼算法,這3種算法把一部分乘法用求和運算代替極大地減少了運算量。Log-BP算法修正了碼長較長時概率 BP 譯碼算法計算不穩定的問題,但是仍然存在乘法運算不利于 FPGA實現。BP-Based算法雖然降低了運算量,但BP-Based 算法相對于Log-BP算法收斂速度慢,譯碼性能也不如前者[4]。NMS算法和BP-Based算法的復雜度幾乎相同,若選取合適的歸一化因子η,能將乘法用加法和移位操作代替,并且其譯碼性能與概率BP算法幾乎一致[5]。因此,NMS算法在FPGA實現時被大量采用。
基于非規則LDPC碼、FPGA、NMS譯碼算法3方面的優點,本文的主要工作是采用非規則LDPC碼、運用NMS譯碼算法設計了一種全新的、實時高速的DSC譯碼器并在Xilinx XC7VX485T上實現了該譯碼器。該譯碼器的吞吐率可達197 Mb/s,具有較好的工程應用價值。
1 DSC譯碼器實現的理論基礎
1.1 DSC的基本原理
假設Xi(i=1,2…N)是來自同一個系統的N個信源,這N個信源之間的相關性稱為邊信息,現對這N個信源進行獨立編碼,將編碼后的N路信息傳輸到同一個譯碼節點,并結合邊信息進行聯合譯碼。因此,DSC系統的編碼端極為簡單,其復雜度主要體現在譯碼端。
1.2 基于非規則LDPC碼的DSC系統
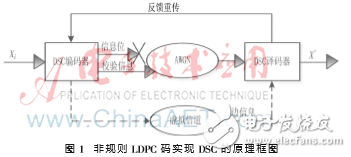
圖1是非規則LDPC碼實現DSC系統的框圖,其中Xi(i=1,2…N)表示來自同一個系統的N個信源,DSC編碼器和譯碼器根據非規則LDPC碼的校驗矩陣(H矩陣)而設計。
從圖1中可知,非規則LDPC碼實現DSC編解碼系統的基本原理:信源Xi經過DSC編碼器后輸出信息位和校驗信息,與傳統譯碼相比,DSC編解碼系統丟棄信息位并且經高斯白噪聲(AWGN)信道每次只傳輸少量的校驗位到DSC譯碼器,如此可以實現碼率自適應并提高壓縮效率。同時邊信息經過虛擬信道傳輸到DSC譯碼器進行聯合譯碼,如果此時能夠正確譯碼就輸出譯碼信息X’,否則進行反饋重傳校驗位繼續譯碼,直至正確譯碼輸出。

1.3 LDPC譯碼算法
NMS譯碼算法具體闡述如下:
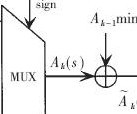
設α2為AWGN信道的方差,yi表示接收到的信息,L(ci)為信道初始化信息,L(qij)為變量節點接收來自校驗節點的信息,L(rji)為校驗節點接收來自變量節點的信息,L(Qi)是變量節點接收到的全部信息,C(i)表示連接變量節點i的所有校驗節點,C(i)j表示連接變量節點i中除j外的全部校驗節點,C(j)i表示連接校驗節點j中除i外的全部變量節點,η表示歸一化因子。
從式(2)中可以看出NMS算法仍然存在少量的乘法運算,若選取合理的η,則能在不損失譯碼性能的情況下,將乘法用加法和移位操作代替[5],使譯碼的計算量最少、譯碼的復雜度最小、FPGA消耗的資源最少。
η是一個小于1的正常數,通常在FPGA上實現LDPC譯碼算法時選取η為0.75,此時的NMS算法譯碼性能最佳[6]。
2 DSC譯碼器設計
文獻[7]對非規則(2 048,1 024)、碼率1/2的H矩陣的研究表明該H矩陣在譯碼過程中能夠實現相當低的誤碼率。因此本文選用此類型度分布為(λ(x),ρ(x)),碼率為1/2的非規則H矩陣,其中λ(x)=0.285 6x+0.257 5x2+0.456 7 x7,ρ(x)=0.003 4x5+0.996 6x6。
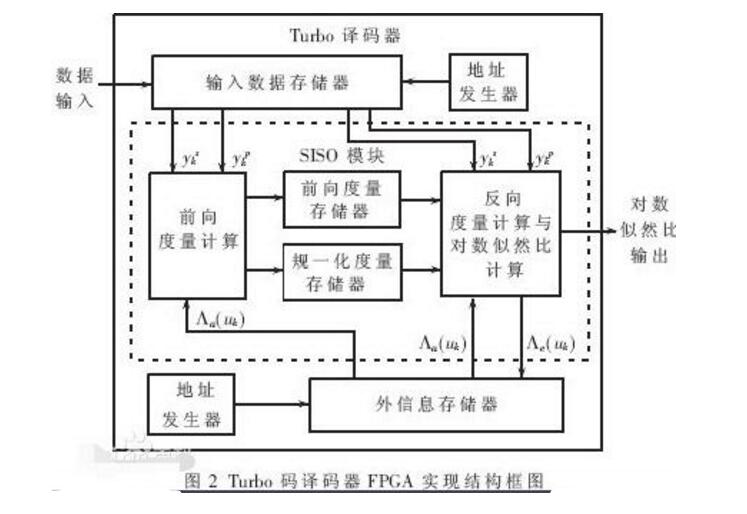
本文設計的DSC譯碼器分為輸入模塊、緩沖模塊、節點信息更新模塊、判決模塊、控制模塊、反饋模塊、輸出模塊。圖2是DSC譯碼器的邏輯結構圖,該譯碼器主要模塊的功能如下:
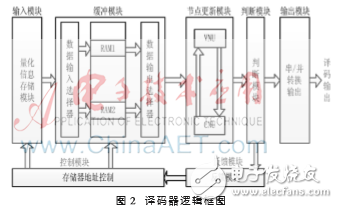
(1)將量化好的邊信息、校驗位信息存入FPGA Block RAM模塊中。
(2)緩沖模塊中兩個完全相同的RAM塊用于乒乓操作,周期性地切換數據選擇器可以提高數據傳輸的速率、效率,亦能使緩沖模塊與節點更新模塊的速率相匹配。
(3)控制模塊用于控制量化信息存儲器和緩沖模塊的工作時序,保證這兩個模塊有序工作,保證數據連續。
(4)節點信息更新模塊控制變量和校驗兩類節點的信息更新,并將判決信息輸出給判決模塊。
(5)反饋模塊把判決結果實時反饋到數據輸出選擇器端,通知輸出選擇器繼續發送校驗信息。
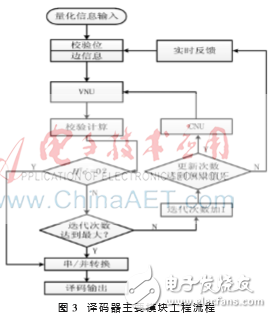
該譯碼器的設計重點體現在節點更新模塊、判決模塊和反饋模塊。圖3是這3個模塊的工作流程。
2.1 量化位數及迭代次數設計
量化必然會損失信息,所以量化位數的設計對信息重建至關重要。量化位數越多,則信息損失越少,譯碼正確性越高,但計算量會增加、消耗的FPGA資源也越多;若量化位數太少,丟失的信息過多,雖然計算量減少、消耗FPGA資源減少,但可能造成譯碼錯誤。
文獻[8-9]中提出(q,f)均勻量化方案,其中量化位數q=8,因量化精度對譯碼性能影響很小,故取f=2足矣。鑒于Xilinx XC7VX485T的邏輯資源相對豐富,本文設計了(8,2)、(9,2)、(10,2)、(11,2)4種量化方案,這4種量化方案經ISE布局布線后消耗FPGA中一種重要資源指標Slice Registers的情況如表1所示。

根據面積換“速度”的思想,提高FPGA資源利用率的同時增加譯碼的準確性。因此,根據表1可知(10,2)均勻量化方案最適合本文DSC譯碼量化要求。
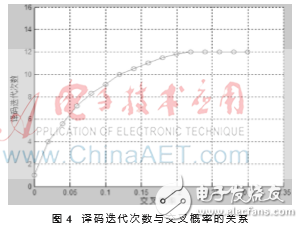
另一個重要的參數是譯碼迭代次數。通常碼長、碼率相同時,不同交叉概率對應的譯碼迭代次數不同。通過仿真AWGN信道下碼長2 048、碼率1/2、量化位數10 bits的信號,得出交叉概率與譯碼迭代次數之間的關系,如圖4所示。
圖4表明,交叉概率變大時,譯碼迭代次數隨之增加。當交叉概率超過0.2后,譯碼迭代次數不再改變。所以本文設計譯碼迭代次數的最大值為12。
2.2 變量更新單元設計
從式(3)和式(4)可知,變量節點的更新主要是加法運算。初始信息與校驗信息送入VNU更新變量節點并計算出各碼位判決控制信息。其原理框圖如圖5所示,由于H矩陣非規則,所以設計了兩種校驗信息組合方式。
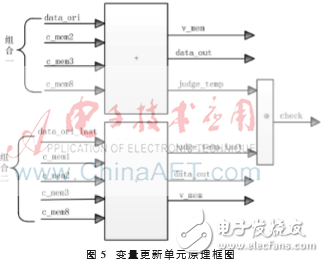
其中,data_ori、data_ori_last表示兩種組合狀態的初始信息,c_mem1、c_mem2、c_mem3、c_mem8表示分別與度為1、2、3、8的變量節點相連的校驗節點信息,v_mem表示更新后的變量節點信息,judge_temp、judge_temp_last表示兩種組合狀態的中間判決信息,check表示輸入判決模塊的最終判決信息。
VNU計算完成后,將judge_temp、judge_temp_last進行異或運算得到判決結果check,如果判斷結果是0,則表示譯碼正確,將譯碼結果送至串/并轉換模塊輸出,否則表示譯碼錯誤。
2.3 校驗更新單元設計
根據式(2)可知,更新校驗節點信息需要求絕對值、求符號、排序找出最小值、移位和加運算這4個步驟。在式(2)中,雖然選擇合適的η可以將乘法全部轉化成移位和加法運算,但是大量的移位操作會占用過多的時鐘周期,因此在CNU模塊的移位/加運算中采用“流水移位/加運算”的方式,這樣不但提高了時鐘利用率、運算效率,也降低了FPGA資源的消耗。
CNU的原理框圖如圖6所示,由于H矩陣非規則,所以設計了兩種變量信息組合方式。
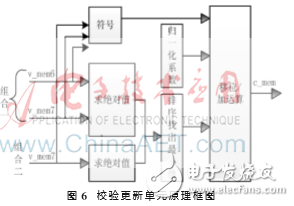
其中,v_mem6、v_mem7分別表示與度為6、7的校驗節點相連的變量節點信息, c_mem表示更新后的校驗節點信息。
3 DSC譯碼器設計結果分析
3.1 DSC譯碼器結構分析
通常情況下,串行譯碼的譯碼效率最低,全并行譯碼器的譯碼效率最高,但是FPGA有限的邏輯資源限制了這種方法的實用性。為了平衡FPGA資源的利用率和譯碼器的譯碼效率,本文采用部分并行的思想設計譯碼器。
由于本文的H矩陣是非規則的,不同度的節點組合在一起消耗的FPGA資源不一樣。綜合考慮運算量、FPGA資源、占用時鐘周期等因素,設計VNU中組合一、組合二的結構如表2、表3所示。

從表2、表3中可以看出組合一的并行度是77,組合二的并行度是46。所以VNU組合一經過26個狀態以及VNU組合二經過1個狀態可以完全更新變量節點。
設計CNU中組合一、組合二的結構如表4、表5所示。從表4、表5中可以看出組合一的并行度是36,組合二的并行度是38,所以CNU組合一經過1個狀態以及CNU組合二經過26個狀態可以完全更新校驗節點。

3.2 DSC譯碼器時序圖
為了驗證該DSC譯碼器設計的可行性,在MATLAB中隨機產生一段二進制信息序列,先進行LDPC編碼,再進行AWGN信道加噪和BPSK調制,得到初始化信息,然后作10 bits均勻量化,將量化結果存入Block RAM中作為譯碼器輸入。
該譯碼器正確譯碼一次的主要信號時序圖如圖7所示(為了清晰地顯示信號,故將圖中的信號名重寫)。信號的含義如下:clk表示譯碼器的全局時鐘,rst表示譯碼器的全局復位,out_flag表示譯碼輸出標志,out_en表示譯碼輸出使能,iter_counter表示譯碼迭代次數,check表示譯碼判決信號,data_out表示譯碼輸出。圖7(b)、圖7(c)是圖7(a)中a、b局部放大后的圖。

從圖7(b)可以看出該譯碼器經過10次循環迭代后,判決信息輸出為0,說明譯碼器譯碼正確。對比MATLAB產生的二進制信息序列,表明譯碼輸出結果與產生的二進制信息序列完全一致,至此證明了該譯碼器設計是正確的。
3.3 DSC系統壓縮性能
一般而言,信源的交叉概率越大,正確譯碼所需的校驗位個數越多。為驗證本文設計的DSC系統的壓縮性能,通過改變信源的交叉概率測試正確譯碼需要的校驗位個數,并與MATLAB中設計的DSC系統對比。本文設計的DSC系統與MATLAB中設計的DSC系統壓縮性能對比如圖8所示。
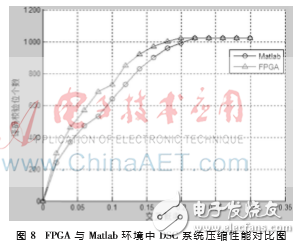
從圖8中可知,在FPGA和MATLAB實現的DSC系統中,正確譯碼所需的校驗位個數都隨交叉概率增加而增加。當交叉概率相同時,本文設計實現的DSC系統比MATLAB仿真的DSC系統需要更多的校驗位才能正確譯碼,主要原因是受FPGA資源限制導致量化位數不夠并且FPGA在布局布線時有延遲。
該DSC高速譯碼器在Xilinx XC7VX485T上實現,ISE完成布局布線消耗的FPGA資源如表6所示。
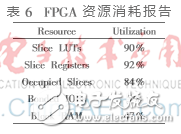
經過時序約束,譯碼器最大工作頻率f可達195.048 MHz,譯出一個碼字需要169個時鐘。根據吞吐率計算公式N×f/(k×T),其中N是碼長,f是時鐘工作頻率,k是最大譯碼迭代次數,T是譯出一個碼字的周期,則譯碼吞吐率可達197 Mb/s。
4 結束語
本文針對當前DSC譯碼器譯碼實時性差、譯碼效率低等因素設計了一種全新的、高速部分并行的DSC譯碼器,并在Xilinx XC7VX485T芯片上實現,在設計時最大限度平衡了FPGA資源、譯碼復雜度和譯碼效率。該DSC譯碼器的設計具有一般性、便于移植等特點,其高達197 Mb/s的吞吐率,使該DSC譯碼器具有較強的工程實用性。













 工商網監
工商網監
評論