 電子發燒友App
電子發燒友App


設計人員使用賽靈思級高層次綜合工具,能以類似軟件的方式用高級編程結構描述包處理系統,而使用RTL則難以實現。
不同層面的協議處理常見于各種新型通信系統,因為任何信息交流都需要使用某種通信協議。通信協議一般包含數據包。數據包由發送方創建,由接收方重新組合,這些操作都要遵循協議規范。這樣協議處理無處不在,需要FPGA設計人員特別關注。因此高效地實現協議處理功能對FPGA有非常重要的意義。
設計人員在視頻處理和信號處理領域運用高層次綜合(HLS)功能已取得巨大成功。使用HLS,用戶可使用高級編程語言來表達硬件功能。為測試這種技術用于包處理的效果,我們用賽靈思Vivado HLS工具構建了一個完整的原型系統,其結果確實令人振奮。Vivado HLS不僅讓我們將開發時間縮減了一半,而且還減少了資源使用并降低了時延。我們的原型系統是一個簡單的ARP/ICMP服務器,能對ping和地址解析協議(ARP)請求做出響應并解析IP地址查詢。
?
下面我們深入了解一下Vivado HLS是如何幫助設計人員解決在協議處理過程中遇到的主要問題。為了解這項技術的優勢,應首先詳細了解Vivado HLS,掌握其工作方式。
提高抽象層次
Vivado HLS能提高系統設計的抽象層次,為設計人員帶來切實的幫助。Vivado HLS通過下面兩種方法提高抽象層次:
? 使用C/C++作為編程語言,充分利用該語言中提供的高級結構;
? 提供更多數據原語,便于設計人員使用基礎硬件構建塊(位向量、隊列等)。
與使用RTL相比,這兩大特性有助于設計人員使用Vivado HLS更輕松地解決常見的協議系統設計難題。最終簡化系統匯編,簡化FIFO和存儲器訪問,實現控制流程的抽象。HLS的另一大優勢是便于架構研究和仿真。
Vivado HLS把C++函數視為模塊,函數定義等效于模塊的RTL描述,函數調用等效于模塊實例化。這種方法能減少需要用戶編寫的代碼量,進而顯著簡化用于系統描述的結構代碼,最終加速系統匯編進程。
在Vivado HLS中,存儲器或FIFO可通過兩種方法訪問。一種是通過合適的對象(比如對流對象的讀寫)。另一種是直接訪問綜合工具隨后將實現為Block RAM或分布式RAM的標準C陣列。綜合工具會根據需要處理額外的信令、同步或尋址問題。
從控制流的角度,Vivado HLS從簡單的FIFO接口到完整的AXI4-Stream均可提供整套流控制感知接口。使用這些接口,設計人員可直接訪問數據,無需檢查背壓或數據可用性。Vivado HLS會適當地調度執行,應對一切緊急情況,同時確保正確完成執行。
設計人員還會感激Vivado HLS提供的另一項功能,即簡便的架構研究功能。用戶只需在代碼中插入程序指令(如使用GUI或批處理模式時的Tcl命令),就可以把設計所需特性傳遞給綜合工具。這樣用戶可以在不修改設計代碼本身的情況下研究大量備選架構方案。研究的范圍可以是模塊流水線化等根本性問題,也可以是FIFO隊列深度等較常見的問題。
最后,C和RTL仿真是Vivado HLS另一個大放異彩的地方。設計一般采用兩步流程驗證:第一步是C語言仿真。這個步驟中C/C++的編譯和執行與常見的C/C++程序相同;第二步是C/RTL協仿真。在這步驟中,Vivado HLS會根據C/C++測試平臺自動生成RTL測試平臺,然后設置并執行RTL仿真,檢查實現方案吧的正確性。
如能充分發揮這些優勢,這將對于用戶的系統設計大有裨益。這不僅體現在開發時間和生產力上,還由于Vivado HLS代碼更加緊湊的特點,體現在代碼可維護性和可讀性上。此外通過高層次綜合,用戶仍能有效控制架構及其特性。正確理解和使用Vivado HLS程序對實現這一控制起著根本作用。
高層次綜合在賽靈思提供的包處理解決方案的層級結構中起著承上啟下、承前啟后的作用。而Vivado SDNet(見《賽靈思雜志》第87期的封面專題報道)和RTL則對其起到補充作用。Vivado SDnet使用特定領域語言,提供一種大為簡便但相當受限的協議處理系統表達方法。RTL則可以用于Vivado HLS無法表達的大量系統的實現工作(例如使用DCM或差分信號并需要詳細時鐘管理的各類系統)。雖然有種種局限,Vivado HLS仍然是在保證結果質量或設計人員靈活性的前提下設計大部分協議處理解決方案的有效途徑。
設置簡單系統
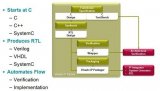
開始新設計時需要完成的最基本工作首先是確定設計的結構,然后將其實現在Vivado HLS中。Vivado HLS中的基本系統構建塊是C/C++函數。構建一個由模塊和子模塊組成的系統意味著需要用一個頂層函數來調用底層函數。圖1所示的是一個極為簡單的三級流水線,我們以此為例來介紹Vivado HLS中系統構建的基本思路。一般采用流水線化設計執行協議處理,由每一級負責解決處理的特定部分。
?
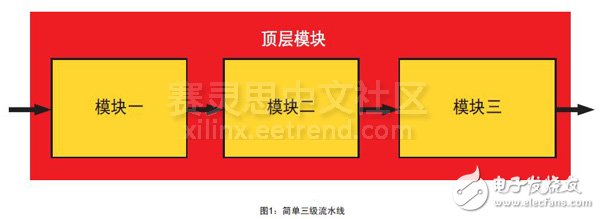
?
構建一個由模塊和子模塊組成的系統意味著需要用一個頂層函數來調用底層函數。
例1:在Vivado HLS中創建簡單系統
1 void topLevelModule(stream&inData,
stream&outData) {
2 #pragma HLS dataflow interval=1
3
4 #pragma INTERFACE axis port=inData
5 #pragma INTERFACE axis port=outData
6
7 static stream> modOne2modTwo;
8 static stream> modTwo2modThree;
9
10 moduleOne(inData, modOne2modTwo);
11 moduleTwo(modOne2modTwo, modTwo2modThree);
12 moduleThree(modTwo2modThree, outData);
13 }
例1中的代碼用于創建頂層模塊函數,供調用所有其它子函數使用。頂層模塊函數使用兩個參數,均屬于“流”(stream)類(Vivado HLS庫中提供的模塊類之一)。流是一種HLS建模架構,代表準備以流方式交換的數據通過的接口。流可以實現為FIFO隊列或內存,也可以是一種能夠配合任何C++架構使用的模板類。在本例中,我們定義了一種稱為axiWord的數據結構(Struct),如例2所示。
例2:定義流接口使用的C++ 結構
structaxiWord {
ap_uint<64> data;
ap_uint<8>strb;
ap_uint<1> last;
};
該struct用于定義AXI4-Stream接口的部分字段。Vivado HLS能自動支持此類接口,使用編譯指令(pragma)語句即可完成設定。編譯指令是對高層次綜合工具的指令,用于指導工具實現要求的結果。例1中第4行和第5行的編譯指令用于告知Vivado HLS這兩個指令(具體是頂層模塊的輸入和輸出端口)將使用AXI4-Stream接口。AXI4-Stream I/F包含兩個必備信號,分別是有效信號和就緒信號,但它們沒有包含在聲明的數據結構中。這是由于Vivado HLS AX4 I/F會在內部處理這些信號,也就是說它們對用戶邏輯而言是透明的。如前文所述,在使用AXI4-Stream I/F時,從用戶處抽象流控制完全由Vivado HLS完成。
當然未必一定使用AXI4-Stream接口。Vivado HLS提供有豐富的總線接口。這里選擇AXI4-Stream作為常見標準接口的示例,供用戶進行包處理。
實現我們的設計的下一項工作是確保我們的三個模塊彼此互聯。這項工作也通過流完成,不過這次它們是位于頂層模塊的內部。第7行和第8行用于聲明實現這一目標的兩個流。這兩個流使用了另一種Vivado HLS結構ap_uint。這是一種無符號一維位陣列,隨后將按此對其操作。同時這也是又一種模板類,因此必須設定這個陣列的寬度。在本例中使用64位,與頂層模塊輸入輸出I/F的數據成員寬帶匹配。還有一點需要詳細說明的是這些流全部聲明為靜態變量。靜態變量是指其值不隨函數調用變化的一種變量。由于在作為順序C/C++程序執行時頂層模塊(以及全部的子模塊)每個時鐘周期會被調用一次,所以任何需要保持其值不隨時鐘周期變化的變量都需要聲明為靜態變量。
創建流水線設計
將要討論的最后也是最重要的一個是編譯指令。第2行中的數據流編譯指令指示Vivado HLS盡量以并行方式安排執行該函數的所有子函數。“internal”參數用于設置該模塊的初始化間隔(II)。初始化間隔(II)告知Vivado HLS該模塊必須具備的處理新輸入數據字的頻次,故決定了設計的吞吐量。不過這并不妨礙模塊內部的流水線化和擁有>1的時延。當II=2時,該模塊將用兩個周期完成數據字的處理,然后再讀入新的數據字。以這種方式Vivado HLS可以簡化模塊最終的RTL。也就是說,在一個典型的協議處理應用中,設計必須具備每個時鐘周期處理一個數據字的能力,故從現在起我們令II=1。
初始化間隔(II)告知Vivado HLS該模塊必須具備的處理新輸入數據字的頻次,故決定了設計的吞吐量。
最后要解決的問題是函數調用本身。在Vivado HLS中,這個過程對應的是模塊的實例化。傳遞給每個模塊的參數實質上定義了模塊的通信端口。在本例中,通過將輸入連接到第一個模塊,然后用 modOne2modTwo流把第一個模塊連接到第二個模塊,依次類推,將三個模塊鏈接起來。
設置簡單系統
協議處理一般情況下屬于狀態事務。必須先順序讀取在多個時鐘周期內進入總線的數據包字,然后根據數據包的某些字段決定進一步操作。通常應對這種處理的方法是使用狀態機,對數據包進行迭代運算,完成必要的處理。例3是一種簡單的狀態機,用于根據上一級的輸入丟棄或轉發數據包。該函數接收三個參數:一個是通過“inData”流接收到的輸入分組數據;一個是通過“validBuffer”流顯示數據包是否有效的1位旗標;第三個是稱為“outData”的輸出分組數據流。注意Vivado HLS函數中的參數是按引用傳遞的。這在使用較為復雜的Vivado HLS流的時候是必要的。ap_uint等較為簡單的數據類型則可按值傳遞。
第2行中的流水線編譯指令指示Vivado HLS將該函數流水線化,讓初始化間隔為1(II=1),即每個時鐘周期處理一個新的輸入數據字。Vivado HLS負責核驗設計,并確定需要在設計中引入多少個流水線級來滿足調度限制要求。
例3:使用Vivado HLS的有限狀態機
1 void dropper(stream&inData,
stream>&validBuffer,
stream&outData) {
2 #pragma HLS pipeline II=1 enable_flush
3
4 static enumdState {D_IDLE = 0, D_STREAM, D_
DROP} dropState;
5 axiWordcurrWord = {0, 0, 0, 0};
6
7 switch(dropState) {
8 case D_IDLE:
9 if (!validBuffer.empty() && !inData.empty()) {
10 ap_uint<1> valid = validBuffer.read();
11 inData.read(currWord);
12 if (valid) {
13 outData.write(currWord);
14 dropState = D_STREAM;
15 }
16 }
17 else
18 dropState = D_DROP;
19 break;
20 case D_STREAM:
21 if (!inData.empty()) {
22 inData.read(currWord);
23 outData.write(currWord);
24 if (currWord.last)
25 dropState = D_IDLE;
26 }
27 break;
28 case D_DROP:
29 if (!inData.empty()) {
30 inData.read(currWord);
31 if (currWord.last)
32 dropState = D_IDLE;
33 }
34 break;
35 }
36 }
第4行用于聲明一個靜態枚舉變量,用于表達該FSM中的狀態。使用枚舉與否可以選擇,不過能讓代碼更容易閱讀,因為可以給狀態適當地命名。不過使用任何整數或ap_unit變量也能得到與之類似的結果。第5行用于聲明一個“axiWord”類型的變量,用于存儲準備從輸入中讀取的分組數據。
第7行中的開關語句用于表達實際的狀態機。建議使用開關,但非強制要求。使用if-else決策樹也能執行同樣的功能。開關語句能夠讓Vivado HLS工具更高效地枚舉所有狀態,并優化得到的狀態機RTL代碼。
執行從D_IDLE狀態開始,此時FSM從第10行和第11行的兩個輸入流讀取。這兩行分別代表兩種流對象讀取方法。這兩種方法均從設定的流讀取,然后將結果存儲到給定變量中。這種方法采取阻塞式讀取,意味著如果該方法調用無法順序執行,就會暫停執行該函數調用中的其余代碼。在試圖讀取空流的時候會發生這種情況。
流分割和合并
在協議處理中,根據協議棧特定字段轉發數據包給不同模塊,然后在發送前將不同的流重新組合,是一項關鍵功能。Vivado HLS允許使用高級架構來推動這一轉發過程,具體如例4中所示的流合并。
例4:簡單的流合并情況
1 void merge(streaminData[NUM_MERGE_
STREAMS], stream&outData) {
2 #pragma HLS INLINE off
3 #pragma HLS pipeline II=1 enable_flush
4
5 static enummState{M_IDLE = 0, M_STREAM}
mergeState;
6 static ap_uint
rrCtr = 0;
7 static ap_uint
streamSource = 0;
8 axiWordinputWord = {0, 0, 0, 0};
9
10 switch(mergeState) {
11 case M_IDLE:
12 boolstreamEmpty[NUM_MERGE_STREAMS];
13 #pragma HLS ARRAY_PARTITION variable=stream-
Empty complete
14 for (uint8_t i=0;i
searchAddress);
9 };
這個類也包括四種在這個表上運算方法(其中一個是構造器)。其中的一個,即比較法,用于實現真正的查找功能。本例通過提供IP地址來返回相應的MAC地址。處理的方法是使用“for”循環查找表中的每一條記錄,搜索有相同IP地址的有效記錄。然后完整地返回這條記錄。如果沒有找到,就返回無效記錄。為讓設計實現II=1的目標,必須完全展開這個循環。
例8:用于CAM類的比較法
1 arpTableEntry cam::compare(ap_uint<32>searchAddress)
{
2 for (uint8_t i=0;ifilterEntries[i].valid == 1 &&
searchAddress == this->filterEntries[i].ipAddress)
4 return this->filterEntries[i];
5 }
6 arpTableEntry temp = {0, 0, 0};
7 return temp;
8 }
上述經驗和示例明確說明,用戶可以使用Vivado HLS充分發揮高級編程結構的作用,用類似軟件的方法描述包處理系統。采用RTL是難以實現的。
10GBps速率下的協議處理
與傳統RTL相比,Vivado HLS可使用C/C++在FPGA上迅速方便地實現協議處理設計,充分發揮高級語言帶來的效率提升優勢。另外還具有下列優點:使用C函數輕松完成系統構建;數據通過流交換,提供類似FIFO的標準化接口;靈活的流控制和HLS編譯指令,便于使用該工具實現需要的架構。借助這些功能,用戶無需重寫源代碼就能夠迅速判研多種不同設計方案的利弊。
出于解釋這類設計的基本概念的目的,上文討論了一種能夠應答ping和ARP請求,解析IP地址查詢的簡單ARP服務器。結果證明用Vivado HLS設計的模塊能夠以10Gbp乃至更高的線速完成協議處理。














 工商網監
工商網監
評論