 電子發(fā)燒友App
電子發(fā)燒友App


SLUB和SLAB的區(qū)別
首先為什么要說slub分配器,內(nèi)核里小內(nèi)存分配一共有三種,SLAB/SLUB/SLOB,slub分配器是slab分配器的進化版,而slob是一種精簡的小內(nèi)存分配算法,主要用于嵌入式系統(tǒng)。慢慢的slab分配器或許會被slub取代,所以對slub的了解是十分有必要的。
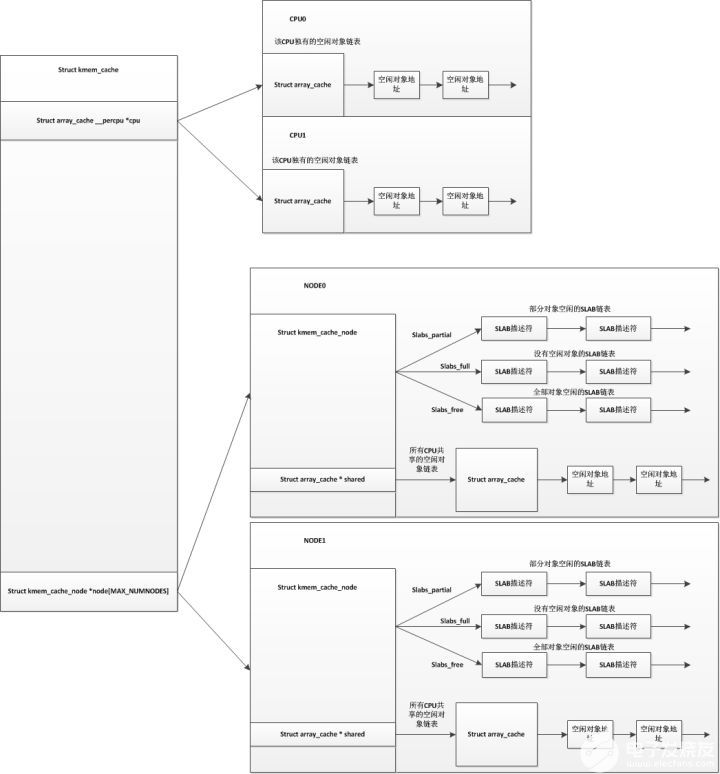
我們先說說slab分配器的弊端,我們知道slab分配器中每個node結(jié)點有三個鏈表,分別是空閑slab鏈表,部分空slab鏈表,已滿slab鏈表,這三個鏈表中維護著對應(yīng)的slab緩沖區(qū)。我們也知道slab緩沖區(qū)的內(nèi)存是從伙伴系統(tǒng)中申請過來的,我們設(shè)想一個情景,如果沒有內(nèi)存回收機制的情況下,只要申請的slab緩沖區(qū)就會存入這三個鏈表中,并不會返回到伙伴系統(tǒng)里,如果這個類型的SLAB迎來了一個分配高峰期,將會從伙伴系統(tǒng)中獲取很多頁面去生成許多slab緩沖區(qū),之后這些slab緩沖區(qū)并不會自動返回到伙伴系統(tǒng)中,而是會添加到node結(jié)點的這三個slab鏈表中去,這樣就會有很多slab緩沖區(qū)是很少用到的。
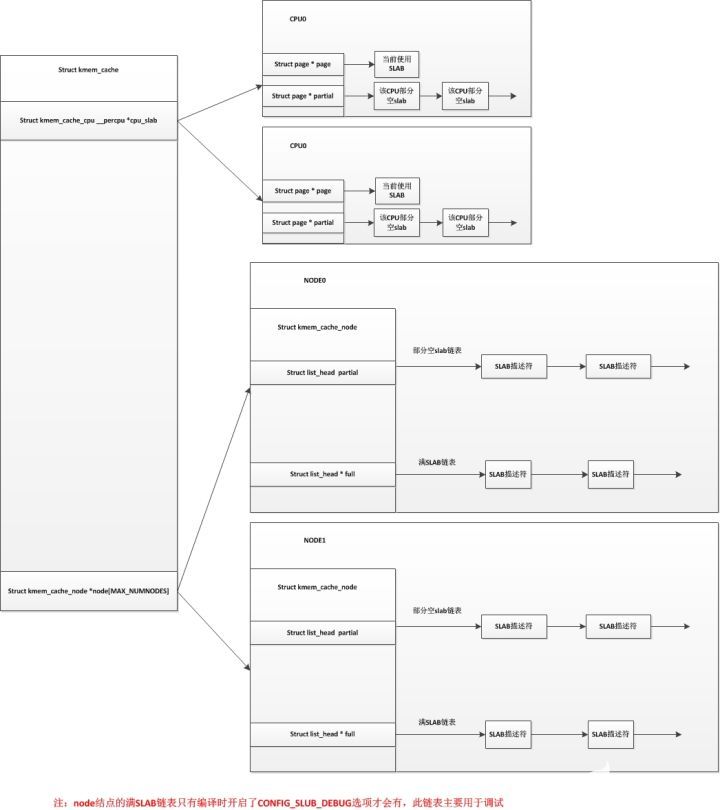
而slub分配器把node結(jié)點的這三個鏈表精簡為了一個鏈表,只保留了部分空slab鏈表,而SLUB中對于每個CPU來說已經(jīng)不使用空閑對象鏈表,而是直接使用單個slab,并且每個CPU都維護有自己的一個部分空鏈表。在slub分配器中,對于每個node結(jié)點,也沒有了所有CPU共享的空閑對象鏈表。我們用以下圖來表示以下slab分配器和slub分配器的區(qū)別(上圖為SLAB,下圖為SLUB):
單個SLAB分配器結(jié)構(gòu)
?
?
?
單個SLUB分配器結(jié)構(gòu)
?
?
?
SLUB分配器
發(fā)明SLUB分配器的主要目的就是減少slab緩沖區(qū)的個數(shù),讓更多的空閑內(nèi)存得到使用。首先,SLUB和SLAB一樣,都分為多種,同時也分為專用SLUB和普通SLUB。如TCP,UDP,dquot這些,它們都是專用SLAB,專屬于它們自己的模塊。而后面這張圖,如kmalloc-8,kmalloc-16...還有dma-kmalloc-96,dma-kmalloc-192...在這方面與SLAB是一樣的,同樣地,也是使用一個struct kmem_cache結(jié)構(gòu)來描述一個SLUB(與SLAB一樣)。并且這個struct kmem_cache與SLAB的struct kmem_cache幾乎是同一個,而且對于SLAB和SLUB,向外提供的接口是統(tǒng)一的(函數(shù)名、參數(shù)以及返回值一模一樣),這樣也就讓驅(qū)動和其他模塊在編寫代碼時無需操心系統(tǒng)使用的是SLAB還是SLUB。這是為了同一個內(nèi)核可以通過編譯選項使用SLAB或者SLUB。
SLUB分配器中的slab緩沖區(qū)結(jié)構(gòu)與SLAB分配器中的slab緩沖區(qū)的結(jié)構(gòu)也有了明顯的不同,對于SLAB分配器的slab緩沖區(qū),其結(jié)構(gòu)如下:

?
?
而在SLUB分配器的slab緩沖區(qū)結(jié)構(gòu)中,已經(jīng)沒有了對象描述符數(shù)組,而freelist也拆分成了每個對象有一個指向下一個對象的指針,如下:

?
?
雖然這兩個slab緩沖區(qū)的結(jié)構(gòu)上有所不同,但其實際原理還是一樣,每次分配或釋放都會設(shè)置對象的下個空閑對象指針,讓其指向正確的位置。有疑問的同學(xué)可以看看我之前寫的linux內(nèi)存源碼分析 - SLAB分配器概述。在初始化一個slab緩沖區(qū)時,默認第一個空閑對象是對象0,然后對象0后面跟著的下一個空閑對象指針指向?qū)ο?,對象1的空閑對象指針指向?qū)ο?,以此類推。
我們看看SLUB分配器的描述符,struct kmem_cache結(jié)構(gòu):
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* 標志 */
unsigned long flags;
/* 每個node結(jié)點中部分空slab緩沖區(qū)數(shù)量不能低于這個值 */
unsigned long min_partial;
/* 分配給對象的內(nèi)存大小(大于對象的實際大小,大小包括對象后邊的下個空閑對象指針) */
int size;
/* 對象的實際大小 */
int object_size;
/* 存放空閑對象指針的偏移量 */
int offset;
/* cpu的可用objects數(shù)量范圍最大值 */
int cpu_partial;
/* 保存slab緩沖區(qū)需要的頁框數(shù)量的order值和objects數(shù)量的值,通過這個值可以計算出需要多少頁框,這個是默認值,初始化時會根據(jù)經(jīng)驗計算這個值 */
struct kmem_cache_order_objects oo;
/* 保存slab緩沖區(qū)需要的頁框數(shù)量的order值和objects數(shù)量的值,這個是最大值 */
struct kmem_cache_order_objects max;
/* 保存slab緩沖區(qū)需要的頁框數(shù)量的order值和objects數(shù)量的值,這個是最小值,當默認值oo分配失敗時,會嘗試用最小值去分配連續(xù)頁框 */
struct kmem_cache_order_objects min;
/* 每一次分配時所使用的標志 */
gfp_t allocflags;
/* 重用計數(shù)器,當用戶請求創(chuàng)建新的SLUB種類時,SLUB 分配器重用已創(chuàng)建的相似大小的SLUB,從而減少SLUB種類的個數(shù)。 */
int refcount;
/* 創(chuàng)建slab時的構(gòu)造函數(shù) */
void (*ctor)(void *);
/* 元數(shù)據(jù)的偏移量 */
int inuse;
/* 對齊 */
int align;
int reserved;
/* 高速緩存名字 */
const char *name;
/* 所有的 kmem_cache 結(jié)構(gòu)都會鏈入這個鏈表,鏈表頭是 slab_caches */
struct list_head list;
#ifdef CONFIG_SYSFS
/* 用于sysfs文件系統(tǒng),在/sys中會有個slub的專用目錄 */
struct kobject kobj;
#endif
#ifdef CONFIG_MEMCG_KMEM
/* 這兩個主要用于memory cgroup的,先不管 */
struct memcg_cache_params *memcg_params;
int max_attr_size;
#ifdef CONFIG_SYSFS
struct kset *memcg_kset;
#endif
#endif
#ifdef CONFIG_NUMA
/* 用于NUMA架構(gòu),該值越小,越傾向于在本結(jié)點分配對象 */
int remote_node_defrag_ratio;
#endif
/* 此高速緩存的SLAB鏈表,每個NUMA結(jié)點有一個,有可能該高速緩存有些SLAB處于其他結(jié)點上 */
struct kmem_cache_node *node[MAX_NUMNODES];
};
掃一下整個kmem_cache結(jié)構(gòu),知識點最重要的有4個:每CPU對應(yīng)的cpu_slab結(jié)構(gòu),每個node結(jié)點對應(yīng)的kmem_cache_node結(jié)構(gòu),slub重用以及struct kmem_cache_order_objects結(jié)構(gòu)對應(yīng)的oo,max,min這三個值。
除去以上4個知識點,我們先簡單說說kmem_cache中的一些成員變量:
size:size = 對象大小 + 對象后面緊跟的下個空閑對象指針。
object_size:對象大小。
offset:對象首地址 + offset = 下個空閑對象指針地址
min_partial:node結(jié)點中部分空slab緩沖區(qū)數(shù)量不能小于這個值,如果小于這個值,空閑slab緩沖區(qū)則不能夠進行釋放,而是將空閑slab加入到node結(jié)點的部分空slab鏈表中。
cpu_partial:同min_partial類似,只是這個值表示的是空閑對象數(shù)量,而不是部分空slab數(shù)量,即CPU的空閑對象數(shù)量不能小于這個值,小于的情況下要去對應(yīng)node結(jié)點的部分空鏈表中獲取若干個部分空slab。
name:該kmem_cache的名字。
我們再來看看struct kmem_cache_cpu __percpu *cpu_slab,對于同一種kmem_cache來說,每個CPU對應(yīng)有自己的struct kmem_cache_cpu結(jié)構(gòu),這個結(jié)構(gòu)如下:
struct kmem_cache_cpu { ? ?/* 指向下一個空閑對象,用于快速找到對象 */ ? ?void **freelist; ? ?/* 用于保證cmpxchg_double計算發(fā)生在正確的CPU上,并且可作為一個鎖保證不會同時申請這個kmem_cache_cpu的對象 */ ? ?unsigned long tid; ? ? ? ?/* CPU當前所使用的slab緩沖區(qū)描述符,freelist會指向此slab的下一個空閑對象 */ ? ?struct page *page; ? ? ? ?/* CPU的部分空slab鏈表,放到CPU的部分空slab鏈表中的slab會被凍結(jié),而放入node中的部分空slab鏈表則解凍,凍結(jié)標志在slab緩沖區(qū)描述符中 */ ? ?struct page *partial; #ifdef CONFIG_SLUB_STATS ? ?unsigned stat[NR_SLUB_STAT_ITEMS]; #endif };
在此結(jié)構(gòu)中主要注意有個partial部分空slab鏈表以及page指針,page指針指向當前使用的slab緩沖區(qū)描述符,內(nèi)核中slab緩沖區(qū)描述符與頁描述符共用一個struct page結(jié)構(gòu)。SLUB分配器與SLAB分配器有一部分不同就在此,SLAB分配器的每CPU結(jié)構(gòu)中保存的是空閑對象鏈表,而SLUB分配器的每CPU結(jié)構(gòu)中保存的是一個slab緩沖區(qū)。而對于tid,它主要用于檢查是否有并發(fā),對于一些操作,操作前讀取其值,操作結(jié)束后再檢查其值是否與之前讀取的一致,非一致則要進行一些相應(yīng)的處理,這個tid一般是遞增狀態(tài),每分配一次對象加1。這個結(jié)構(gòu)說明了一個問題,就是每個CPU有自己當前使用的slab緩沖區(qū),CPU0不能夠使用CPU1所在使用的slab緩存,CPU1也不能夠使用CPU0正在使用的slab緩存。而CPU從node獲取slab緩沖區(qū)時,一般傾向于從該CPU所在的node結(jié)點上分配,如果該node結(jié)點沒有空閑的內(nèi)存,則根據(jù)memcg以及node結(jié)點的zonelist從其他node獲取slab緩沖區(qū)。這些具體可以在代碼中見到。
?
我們再看看kmem_cache_node結(jié)構(gòu):
struct kmem_cache_node {
/* 鎖 */
spinlock_t list_lock;
/* SLAB使用 */
#ifdef CONFIG_SLAB
/* 只使用了部分對象的SLAB描述符的雙向循環(huán)鏈表 */
struct list_head slabs_partial; /* partial list first, better asm code */
/* 不包含空閑對象的SLAB描述符的雙向循環(huán)鏈表 */
struct list_head slabs_full;
/* 只包含空閑對象的SLAB描述符的雙向循環(huán)鏈表 */
struct list_head slabs_free;
/* 高速緩存中空閑對象個數(shù)(包括slabs_partial鏈表中和slabs_free鏈表中所有的空閑對象) */
unsigned long free_objects;
/* 高速緩存中空閑對象的上限 */
unsigned int free_limit;
/* 下一個被分配的SLAB使用的顏色 */
unsigned int colour_next; /* Per-node cache coloring */
/* 指向這個結(jié)點上所有CPU共享的一個本地高速緩存 */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
/* 兩次緩存收縮時的間隔,降低次數(shù),提高性能 */
unsigned long next_reap;
/* 0:收縮 1:獲取一個對象 */
int free_touched; /* updated without locking */
#endif
/* SLUB使用 */
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
/* 該node中此kmem_cache的所有slab的數(shù)量 */
atomic_long_t nr_slabs;
/* 該node中此kmem_cache中所有對象的數(shù)量 */
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
這個結(jié)構(gòu)中我們只需要看#ifdef CONFIG_SLUB部分,這個結(jié)構(gòu)里正常情況下只有一個node結(jié)點部分空slab鏈表partial,如果在編譯內(nèi)核時選擇了CONFIG_SLUB_DEBUG選項,則會有個node結(jié)點滿slab鏈表。對于SLAB分配器,SLUB分配器在這個結(jié)構(gòu)也做出了相應(yīng)的變化,去除了滿slab緩沖區(qū)鏈表和空閑slab緩沖區(qū)鏈表,只使用了一個部分空slab緩沖區(qū)鏈表。對于所有的CPU來說,它們可以使用這個node結(jié)點里面部分空鏈表中保存的那些slab緩沖區(qū),當它們需要使用時,要先將緩沖區(qū)拿到CPU對應(yīng)自己的鏈表或者當前使用中,也就是說node結(jié)點上部分空slab緩沖區(qū)同一個時間只能讓一個CPU使用。
而關(guān)于slub重用,這里只做一個簡單的解釋,其作用是為了減少slub的種類,比如我有個kmalloc-8類型的slub,里面每個對象大小是8,而我某個驅(qū)動想申請自己所屬的slub,其對象大小是6,這時候系統(tǒng)會給驅(qū)動一個假象,讓驅(qū)動申請了自己專屬的slub,但系統(tǒng)實際把kmalloc-8這個類型的slub返回給了驅(qū)動,之后驅(qū)動中分配對象時實際上就是從kmalloc-8中分配對象,這就是slub重用,將相近大小的slub共用一個slub類型,雖然會造成一些內(nèi)碎片,但是大大減少了slub種類過多以及減少使用了跟多的內(nèi)存。
最后說說struct kmem_cache_order_objects結(jié)構(gòu)對應(yīng)的oo,max,min這三個值,struct kmem_cache_order_objects結(jié)構(gòu)實際上就是一個unsigned long,這個結(jié)構(gòu)有兩個作用,保存一個slab緩沖區(qū)占用頁框的order值和一個slab緩沖區(qū)對象數(shù)量的值。當kmem_cache需要創(chuàng)建一個新的slab緩沖區(qū)時,會使用它們當中保存的oder值去申請2的order次方個數(shù)的頁框。oo是一個默認值,在大多數(shù)情況下創(chuàng)建一個新的slab緩沖區(qū)時會用oo中的值來申請頁框,而min是在oo申請失敗的情況下使用,它是一個比oo更小的值,當伙伴系統(tǒng)拿不出oo中指定的數(shù)量的頁框,會嘗試向伙伴系統(tǒng)申請min中指定的頁框數(shù)量(這個slab緩沖區(qū)連續(xù)頁框數(shù)量少,對象數(shù)量也會少)。而max的值是在做slab緩沖區(qū)壓縮時使用,其作用更多的是作為一個安全值,在這個kmem_cache中所有slab緩沖區(qū)的objects數(shù)量都不會大于max中的值。所有情況都是max >= oo > min。
?
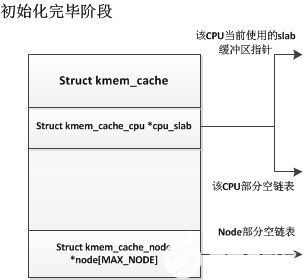
現(xiàn)在,我們描述一下SLUB分配器是如何運作的,kmem_cache初始化后其是沒有slab緩沖區(qū)的,當其他模塊需要從此kmem_cache中申請一個對象時,kmem_cache會從伙伴系統(tǒng)獲取連續(xù)的頁框作為一個slab緩沖區(qū),然后通過kmem_cache中的cotr函數(shù)指針指向的構(gòu)造函數(shù)構(gòu)造初始化這個slab緩沖區(qū)后,將其設(shè)置為該cpu的當前使用slab緩沖區(qū),當此slab緩沖區(qū)使用完后,外部模塊在申請對象時,會把這個滿的slab緩沖區(qū)移除,再從伙伴系統(tǒng)獲取一段連續(xù)頁框作為一個新的空閑slab緩沖區(qū),也是設(shè)置為該CPU當前使用的slab緩沖區(qū)。而那些滿slab緩沖區(qū)中有對象釋放時,SLUB分配器優(yōu)先把這些緩沖區(qū)放入該CPU對應(yīng)的部分空slab鏈表。而當一個部分空slab通過釋放對象成為了一個空閑slab緩沖區(qū)時,SLUB分配器會視情況而定將此空閑slab釋放還是加入到node結(jié)點的部分空slab鏈表中。
我們先看看一個slub初始化結(jié)束的情況:
?
?
?
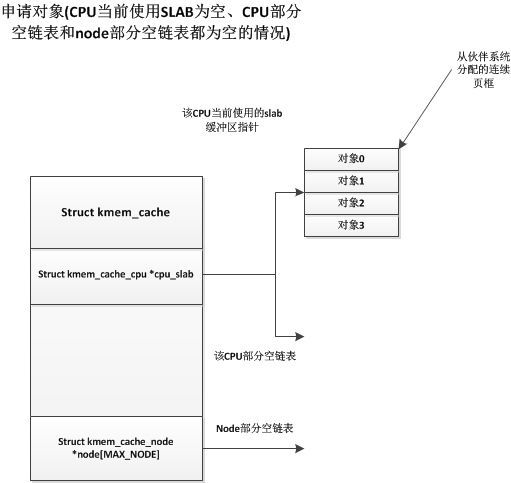
初始化完成后,slub中并沒有一個slab緩沖區(qū),只有在第一次申請時,才會從伙伴系統(tǒng)中獲取一段連續(xù)頁框作為一個slab緩沖區(qū),如下:
?
?
?
這時候當前CPU獲得了一個空閑slab緩沖區(qū),并將其中的一個空閑對象分配出去,而下次申請對象時也會從該slab緩沖區(qū)中獲取對象,直到此緩沖區(qū)中對象用完為止。
?
上面描述的是初始化完成后第一次申請對象的情況,現(xiàn)在我們描述一下運行時申請對象的情況,一種情況是當前CPU使用的slab緩沖區(qū)有多余的空閑對象,這樣直接從這些多余的空閑對象中分配一個出去即可,這種情況很簡單。我們著重說明CPU使用的slab緩沖區(qū)沒有多余的空閑對象的情況,這種情況又分為CPU的部分空slab鏈表是否為空的情況,如果CPU部分空slab鏈表不為空,則CPU會將當前使用的滿slab移除,并從CPU的部分空slab鏈表中獲取一個部分空的slab緩沖區(qū),并設(shè)置為CPU當前使用的slab緩沖區(qū),如下圖:
?
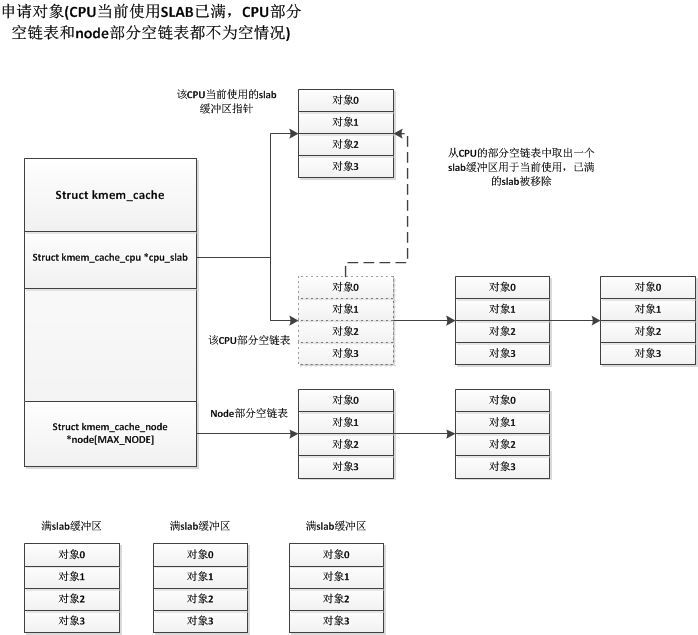
?
?
如果node的部分空鏈表和CPU的部分空鏈表都為空的情況,那就與我們第一次申請對象的情況一樣,直接從伙伴系統(tǒng)中獲取連續(xù)頁框用于一個slab緩沖區(qū)。
?
現(xiàn)在我們再說說CPU當前使用的slab已滿,CPU的部分空slab鏈表為空的情況,這種情況下,會從node結(jié)點的部分空slab鏈表獲取若干個部分空slab緩沖區(qū),將它們放入CPU的部分空slab鏈表中,獲取的slab緩沖區(qū)個數(shù)根據(jù)一個規(guī)則就是:cpu空閑的對象數(shù)量必須要大于kmem_cache中的cpu_partial的值的一半。具體如下:
?
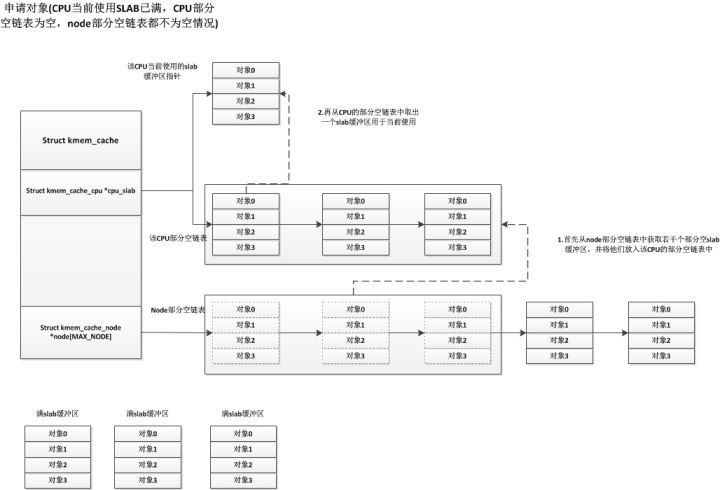
?
?
各種情況的申請對象都已經(jīng)說明了,接下來我們說說釋放對象的情況,釋放對象也分很多種,我們先說說最簡單的一種釋放情況,就是部分空的slab釋放其中一個使用著的對象,釋放后這個部分空slab還是部分空slab(有些部分空slab只使用了一個對象,釋放這個對象后就變?yōu)榭臻eslab),這些部分空slab可能處于CPU當前使用slab,CPU部分空鏈表,node部分空鏈表中,但是它們的處理都是一樣的,直接釋放掉該對象即可,如下:
?
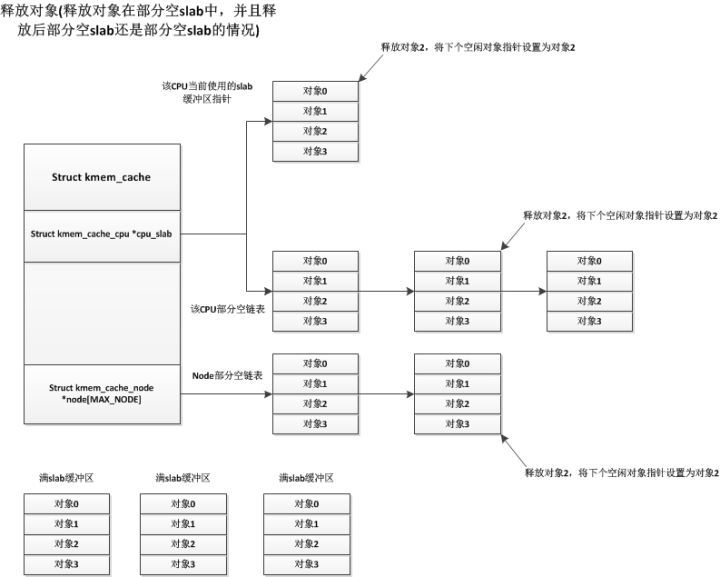
?
?
另一種情況是滿slab緩沖區(qū)釋放對象后變?yōu)榱瞬糠挚誷lab緩沖區(qū),這種情況下系統(tǒng)會將此部分空slab緩沖區(qū)放入CPU的部分空鏈表中,如下:
?
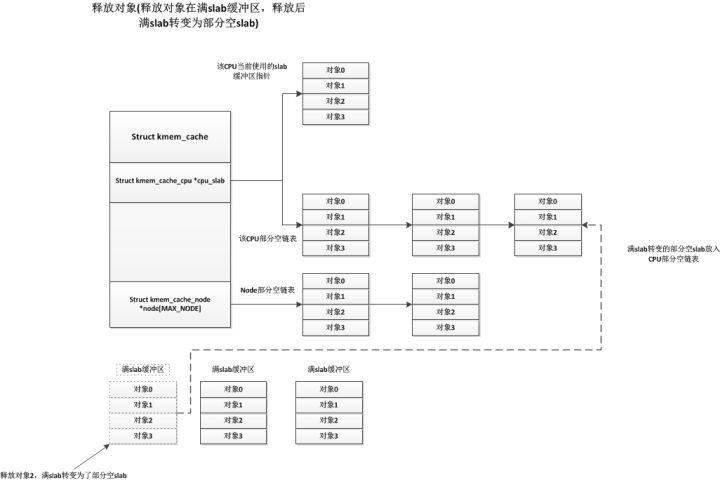
?
最后一種釋放情況就是部分空slab釋放一個對象后轉(zhuǎn)變成了空閑slab緩沖區(qū),而對于這個空閑slab緩沖區(qū)的處理,系統(tǒng)首先會檢查node部分空鏈表中slab緩沖區(qū)的個數(shù),如果node部分空鏈表中slab緩沖區(qū)數(shù)量小于kmem_cache中的min_partial,則將這個空閑slab緩沖區(qū)放入node部分空鏈表中。否則釋放此空閑slab,將其占用頁框返回伙伴系統(tǒng)中。我們知道部分空slab有可能存在于3個地方,CPU當前使用的slab緩沖區(qū),CPU部分空鏈表,node部分空鏈表,這三個地方對于這種情況下的處理都是一樣的,如下:
?
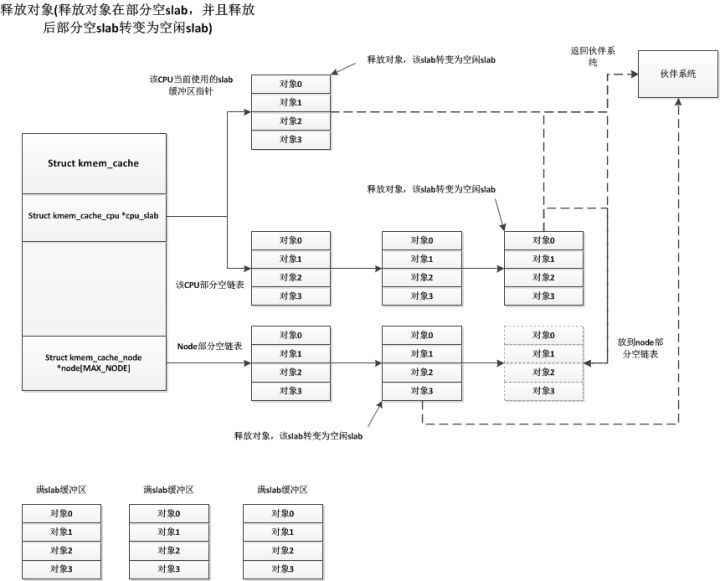
?
?
這樣看來只有空閑的slab緩沖區(qū)會被放入node結(jié)點的部分空鏈表中,這只是從釋放對象的角度看是這樣的,當刷新kmem_cache時,會將kmem_cache中所有的slab緩沖區(qū)放回到node結(jié)點的部分空鏈表(也包括當前CPU使用的slab緩沖區(qū)),這種情況node結(jié)點的部分空鏈表就會有部分空slab緩沖區(qū)了。而還有一種情況就是編譯時禁用了CPU的部分空鏈表,即CPU只有一個當前使用的slab緩沖區(qū),這樣其他的部分空緩沖區(qū)都會保存在node結(jié)點的部分空鏈表上,更多詳細細節(jié)請看內(nèi)核源碼中的mm/slub.c文件。
slab緩沖區(qū)壓縮技術(shù)
說是壓縮技術(shù),其實就是把kmem_cache中所有的slab緩沖區(qū)放回到node結(jié)點的部分空鏈表中(包括所有CPU當前正在使用的slab),然后node結(jié)點的部分空鏈表中的空閑的slab緩沖區(qū)釋放掉,然后將node結(jié)點中的其他部分空slab緩沖區(qū)按照空閑對象數(shù)量進行重新排列,把空閑數(shù)量少的放在前面,空閑數(shù)量多的放在后面,這樣空閑數(shù)量少的更容易被移去cpu的部分空鏈表。其實思想就是讓那些更容易成為滿slab的部分空slab優(yōu)先被使用。總結(jié)出來就是釋放空閑slab和對部分空slab排序。
我們知道,在node結(jié)點的部分空鏈表中,slab緩沖區(qū)數(shù)量少于kmem_cache中的min_partial的值時,即使空閑slab緩沖區(qū)也不會被釋放,而是放入node結(jié)點部分空鏈表中,這樣一來之后會有一些空閑slab緩沖區(qū)無法自動釋放回伙伴系統(tǒng),壓縮技術(shù)就是在系統(tǒng)內(nèi)存緊急時會去釋放這些空閑的伙伴系統(tǒng),然后對其他部分空的slab緩沖區(qū)重新排列。代碼如下:
int __kmem_cache_shrink(struct kmem_cache *s)
{
int node;
int i;
struct kmem_cache_node *n;
struct page *page;
struct page *t;
/* 所有slab緩沖區(qū)的最大對象數(shù)量 */
int objects = oo_objects(s->max);
/* 申請objects個鏈表頭,每個inuse相同的slab緩沖區(qū)會放入對應(yīng)的鏈表中 */
struct list_head *slabs_by_inuse =
kmalloc(sizeof(struct list_head) * objects, GFP_KERNEL);
unsigned long flags;
if (!slabs_by_inuse)
return -ENOMEM;
/* 刷新這個kmem_cache中所有的slab,這個操作會將所有CPU中的slab放回到node結(jié)點的部分空鏈表中 */
flush_all(s);
/* 變量kmem_cache中的每個node結(jié)點 */
for_each_kmem_cache_node(s, node, n) {
/* node結(jié)點部分空鏈表為空則直接下一個結(jié)點 */
if (!n->nr_partial)
continue;
/* node結(jié)點部分空鏈表不為空,初始化slabs_by_inuse鏈表中每個鏈表頭結(jié)點 */
for (i = 0; i < objects; i++)
INIT_LIST_HEAD(slabs_by_inuse + i);
/* kmem_cache_node上鎖 */
spin_lock_irqsave(&n->list_lock, flags);
/* 遍歷node結(jié)點部分空鏈表中所有的部分空slab緩沖區(qū) */
list_for_each_entry_safe(page, t, &n->partial, lru) {
/* 將node結(jié)點中所有的部分空slab緩沖區(qū)移到slabs_by_inuse中inuse鏈表中,也就是所有inuse=1的slab放入同一個鏈表,inuse=2的放入同一個鏈表 */
list_move(&page->lru, slabs_by_inuse + page->inuse);
/* 如果inuse == 0,則node結(jié)點的部分空slab數(shù)量-- */
if (!page->inuse)
n->nr_partial--;
}
/* 重建node結(jié)點的部分空鏈表,將slabs_by_inuse中inuse高的放在前面,inuse低的放在后面,讓inuse高的更容易得到分配機會,也就是讓inuse高的更快用完 */
for (i = objects - 1; i > 0; i--)
list_splice(slabs_by_inuse + i, n->partial.prev);
spin_unlock_irqrestore(&n->list_lock, flags);
/* 如果有空的slab緩沖區(qū),空的slab緩沖區(qū)保存在slabs_by_inuse + 0的鏈表位置,釋放他們 */
list_for_each_entry_safe(page, t, slabs_by_inuse, lru)
discard_slab(s, page);
}
/* 釋放objects個鏈表頭 */
kfree(slabs_by_inuse);
return 0;
}
?
?
??
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論