 電子發(fā)燒友App
電子發(fā)燒友App


阿里云視頻云直播轉(zhuǎn)碼每天都會處理大量的不同場景、不同編碼格式的直播流。為了保證高畫質(zhì),團(tuán)隊借助VMAF標(biāo)準(zhǔn)來對每路轉(zhuǎn)碼的效果做質(zhì)量評估,然后進(jìn)行反饋、調(diào)優(yōu)、迭代。這么做的原因在于,像動作片、紀(jì)錄片、動畫片、體育賽事這些場景,影響畫質(zhì)的因素各不相同,基于VMAF的視頻質(zhì)量反饋機(jī)制,可以在保證畫質(zhì)的前提下,對不同的場景做針對性優(yōu)化,達(dá)到畫質(zhì)最優(yōu)、成本最低的效果。本文由阿里云視頻云高級開發(fā)工程師楊洋撰寫,旨在分享VMAF的核心模塊與技術(shù)實踐。
背景
圖像質(zhì)量的衡量是個老問題,對此人們提出過很多簡單可行的解決方案。例如均方誤差(Mean-squared-error,MSE)、峰值信噪比(Peak-signal-to-noise-ratio,PSNR)以及結(jié)構(gòu)相似性指數(shù)(Structural Similarity Index,SSIM),這些指標(biāo)最初都是被用于衡量圖像質(zhì)量的,隨后被擴(kuò)展到視頻領(lǐng)域。這些指標(biāo)通常會用在編碼器(“循環(huán)”)內(nèi)部,可用于對編碼決策進(jìn)行優(yōu)化并估算最終編碼后視頻的質(zhì)量。但是由于這些算法衡量標(biāo)準(zhǔn)單一,缺乏對畫面前后序列的總體評估,導(dǎo)致計算的結(jié)果很多情況下與主觀感受并不相符。
VMAF 介紹
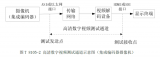
VMAF(Video Multimethod Assessment Fusion)由Netflix開發(fā)并開源在Github上,基本想法在于,面對不同特征的源內(nèi)容、失真類型,以及扭曲程度,每個基本指標(biāo)各有優(yōu)劣。通過使用機(jī)器學(xué)習(xí)算法(SVM)將基本指標(biāo)“融合”為一個最終指標(biāo),可以為每個基本指標(biāo)分配一定的權(quán)重,這樣最終得到的指標(biāo)就可以保留每個基本指標(biāo)的所有優(yōu)勢,借此可得出更精確的最終分?jǐn)?shù)。Netfix使用主觀實驗中獲得的意見分?jǐn)?shù)對這個機(jī)器學(xué)習(xí)模型進(jìn)行訓(xùn)練和測試。VMAF主要使用了3種指標(biāo):visual quality fidelity(VIF)、detail loss measure(DLM)、temporal information(TI)。其中VIF和DLM是空間域的也即一幀畫面之內(nèi)的特征,TI是時間域的也即多幀畫面之間相關(guān)性的特征。這些特性之間融合計算總分的過程使用了訓(xùn)練好的SVM來預(yù)測。工作流程如圖:

VMAF 核心模塊
VMAF基于SVM的nuSvr算法,在運行的過程中,根據(jù)事先訓(xùn)練好的model,賦予每種視頻特征以不同的權(quán)重。對每一幀畫面都生成一個評分,最終以均值算法進(jìn)行歸總(也可以使用其他的歸總算法),算出該視頻的最終評分。其中主要的幾個核心模塊如下:
VMAF分別用python和C++實現(xiàn)了兩套接口,同時提供了C版本的lib庫,最新版本的ffmpeg已經(jīng)將vmaf作為一個filter集成進(jìn)去。下面我們分析下各個模塊的作用:
? Asset
一個Asset單元,包含了一個正在執(zhí)行的任務(wù)信息。比如目標(biāo)視頻與原始視頻的幀范圍,低分辨率視頻幀上采樣信息等(VMAF會在特征提取前通過上采樣的方式保證兩個視頻分辨率相同)。
? Executor
Executor會取走并計算Asset鏈表中每一個Asset單元,將執(zhí)行結(jié)果返回到一個Results鏈表中。Executor類是FeatureExtractor與QualityRunner的基類。它提供了一些基函數(shù),包括Results的操作函數(shù)、FIFO管道函數(shù)、clean函數(shù)等。
? Result
Result是以key-value形式,將Executor執(zhí)行的結(jié)果存儲起來。key存儲的是“FrameNum”或者質(zhì)量分?jǐn)?shù)的類型(VMAF_feature_vif_scale0_score或VMAF_feature_vif_scale1_score等),value存儲的是一系列分值組成的鏈表。
Result類也提供了一個匯總工具,將每個單元的質(zhì)量分?jǐn)?shù)匯總成一個值。默認(rèn)的匯總算法是“均值算法”,但是Result.set_score_aggregate_method()方法允許定制其他的算法。
? ResultStore
ResultStore類提供了Result數(shù)據(jù)集的存儲、加載的能力。
? FeatureExtractor
FeatureExtractor是Extractor子類,專門用于從Asset集合中提取特征,作為基本的特征提取類。任何具體的特征提取接口,都繼承自FeatureExtractor,例如VmafFeatureExtractor/PsnrFeatureExtractor/SsimFeatureExtractor等。
? FeatureAssembler
FeatureAssembler是一個聚合類,通過在構(gòu)造函數(shù)傳入feature_dict參數(shù),指定具體的特征提取標(biāo)準(zhǔn),將該標(biāo)準(zhǔn)提取出的特征結(jié)果聚合,輸出到一個BasicResult對象中。FeatureAssembler被QualityRunner調(diào)用,用來將提取后的特征數(shù)組傳給TrainTestModel使用。
? TrainTestModel
TrainTestModel是任何具體的回歸因子接口的基類,回歸因子必須提供一個train()方法去訓(xùn)練數(shù)據(jù)集,predict()方法去預(yù)測數(shù)據(jù)集,以及to_file(),frome_file()方法去保存、加載訓(xùn)練好的模型。
回歸方程的超參數(shù)必須通過TrainTestModel的構(gòu)造函數(shù)傳入。TrainTestModel類提供了一些基礎(chǔ)方法,例如歸一化、反歸一化、評估預(yù)測性能。
? CrossValidation
CrossValidation提供了一組靜態(tài)方法來促進(jìn)TrainTestModel訓(xùn)練結(jié)果的驗證。因此,它還提供了搜索TrainTestModel最優(yōu)超參的方法。
? QualityRunner
QualityRunner是Executor子類,用來評估Asset任務(wù)集合的畫質(zhì)分?jǐn)?shù)。任何用于生成最終質(zhì)量評分的接口都應(yīng)該繼承QualityRunner。例如跑vmaf標(biāo)準(zhǔn)的VmafQualityRunner,跑psnr標(biāo)準(zhǔn)的PsnrQualityRunner都是QualityRunner的子類。
自定義VMAF
最新版本的vmaf提供了1080p、4k、mobilephone三種場景下的model文件。Netflix號稱使用了海量的、多分辨率、多碼率視頻素材(高噪聲視頻、CG動漫、電視劇)作為數(shù)據(jù)集,得到的這三組model。在日常使用中,這三組model基本滿足需求了。不過,VMAF提供了model訓(xùn)練工具,可以用于訓(xùn)練私有model。
創(chuàng)建新的數(shù)據(jù)集
首先,按照dataset格式,定義數(shù)據(jù)集文件,比如定義一個
example_dataset.py:?
dataset_name = 'example_dataset'?
yuv_fmt = 'yuv420p'?
width = 1920?
height = 1080?
ref_videos = [?
{'content_id': 0,?
'content_name': 'BigBuckBunny',?
'path': ref_dir + '/BigBuckBunny_25fps.yuv'}?
...?
]?
dis_videos = [{'asset_id': 0,?
'content_id': 0,?
'dmos': 100.0,?
'path': ref_dir + '/BigBuckBunny_25fps.yuv',?
}?
...?
]
ref_video是比對視頻集,dis_video是訓(xùn)練集。每個訓(xùn)練集樣本視頻都有一個主觀評分DMOS,進(jìn)行主觀訓(xùn)練。SVM會根據(jù)DMOS做有監(jiān)督學(xué)習(xí),所以DMOS直接關(guān)系到訓(xùn)練后model的準(zhǔn)確性。
PS: 將所有觀察者針對每個樣本視頻的分?jǐn)?shù)匯總在一起計算出微分平均意見分?jǐn)?shù)(Differential Mean Opinion Score)即DMOS,并換算成0-100的標(biāo)準(zhǔn)分,分?jǐn)?shù)越高表示主觀感受越好。
驗證數(shù)據(jù)集
./run_testing quality_type test_dataset_file [--vmaf-model optional_VMAF_model_path] [--cache-result] [--parallelize]
數(shù)據(jù)集創(chuàng)建后,用現(xiàn)有的VMAF或其他指標(biāo)(PSNR,SSIM)驗證數(shù)據(jù)集是否正確,驗證無誤后才能訓(xùn)練。
訓(xùn)練新的模型
驗證完數(shù)據(jù)集沒問題后,便可以基于數(shù)據(jù)集,訓(xùn)練一個新的質(zhì)量評估模型。
./run_vmaf_training train_dataset_filepath feature_param_file model_param_file output_model_file [--cache-result] [--parallelize]?
例如,?
./run_vmaf_training example_dataset.py resource/feature_param/vmaf_feature_v2.py resource/model_param/libsvmnusvr_v2.py workspace/model/test_model.pkl --cache-result --parallelize?
feature_param_file 定義了使用那些VMAF特征屬性。例如,?
feature_dict = {'VMAF_feature':'all', } 或 feature_dict = {'VMAF_feature':['vif', 'adm'], }
model_param_file 定義了回歸量的類型和使用的參數(shù)集。當(dāng)前版本的VMAF支持nuSVR和隨機(jī)森林兩種機(jī)器算法,默認(rèn)使用的nuSVR。
output_model_file 是新生成的model文件。
交叉驗證
vmaf提供了run_vmaf_cross_validation.py工具用于對新生成的model文件做交叉驗證。
自定義特征和回歸因子
vmaf具有很好的可擴(kuò)展性,不僅可以訓(xùn)練私有的model,也可以定制化或插入第三方的特征屬性、SVM回歸因子。
通過feature_param_file類型文件,支持自定義或插入第三方特征,需要注意的是所有的新特征必須要是FeatureExtractor子類。類似的,也可以通過param_model_file類型文件,自定義或插入一個第三方的回歸因子。同樣需要注意的是,所有創(chuàng)建的新因子,必須是TrainTestModel子類。
由于Netflix沒有開放用于訓(xùn)練的數(shù)據(jù)集,個人覺得,受制于數(shù)據(jù)集DMOS準(zhǔn)確性、數(shù)據(jù)集樣本的量級等因素,通過自建數(shù)據(jù)集訓(xùn)練出普適的model還是挺不容易滴~
最后,附上VMAF Github地址:https://github.com/Netflix/vmaf


































 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論