 電子發燒友App
電子發燒友App


以市場觀點來看,許多人只會重視FPGA的大量型應用,例如用FPGA取代ASIC。
但就技術角度來看,FPGA的應用拓展就更為多樣且具意義,這包括用FPGA加速高效運算、用FPGA加速電路設計驗證、用FPGA取代大量性的DSP運算。
由于掩膜成本的指數性攀升,許多中等用量規模(約50萬顆以下)的芯片無法如過去般以ASIC方式投產,且不得不改以FPGA投產,如此使近年來FPGA的市場不斷增長。
FPGA侵蝕原有ASIC市場的用量極為可觀的,此也成為近年來眾人關注FPGA的首要焦點,不過也因為過于聚焦在高用量、大市場的觀察,使FPGA的其它新應用發展被人所忽略,但這些應用卻也極具意義。所以,以下本文將針對FPGA的新應用進行更多的了解與說明。
高效運算(High Performance Computing;HPC)
高效運算所指的即是軍方、政府機關、學術研究單位所用的超級計算機(Supercomputer),另外部分企業內的工程、科技運算也含括在內,這類型的計算機擁有極高的運算效能,然近年來為了進一步提升系統效能,因此開始將FPGA運用于系統中。
首先是Cray Research,該公司的超級計算機:XD1就有用上FPGA,XD1用的是Xilinx(賽靈思)公司的VIRTEX系列FPGA。XD1機內有所謂的FPGA應用程序加速模塊(FPGA Application Acceleration Module),模塊等于是機內的一個小型輔助運算系統,VIRTEX是模塊內的主控芯片,等于是一個協同處理器(Co-Processor),只不過這個協同處理器與ASIC型式的協同處理器不同,FPGA具有可程序化的功效,因此VIRTEX是一顆可程序化的協同處理器。
運算模塊內除了有FPGA的協同處理器外,處理器也必須搭配內存才能行使運算,所以FPGA會再連接4顆QDR II SRAM(極高速性的內存),然后模塊一方面用HyperTransport與XD1的主處理器相連,另一方面也連往XD1的特有高速I/O界面:RapidArray。
接著,由于高效運算多是執行大量重復性的運算,例如氣象預測、風洞測試等,所以可以將執行的應用程序轉化成FPGA內的組態(Configuration,中國內地方面稱為:配置)程序,以硬件線路方式來執行運算,如此將比過往用純軟件方式執行快上數倍至數十倍的效能,甚至在特定的應用運算上能達一百倍以上的效能。
更仔細而言,其實是將整個應用程序中重復性最高、且最經常呼用(Call,呼叫使用,中國內地方面稱為:調用)的函式庫(Library,中國內地方面稱為:庫)進行轉化,改以FPGA的硬件線路執行,如此就能夠以最小的轉化心力獲得最大的加速效果。
Cray如此,與Cray同為高效運算市場的另一家業者:SGI(視算科技)也實行相同的作法,SGI提出所謂的RASC(Reconfigurable Application Specific Computing;RASC),中文可稱為:可組態化應用程序性運算,RASC也是以模塊方式讓原有的超級計算機能獲得加速效果。
SGI的作法與Cray有部分相同也有部分不同,Cray是將模塊設置在原有超級計算機的機內,而SGI則是運用既有超級計算機機箱的上部來加搭加速模塊,不過就功效機制而言兩者異曲同工,此外兩者都使用Xilinx的VIRTEX系列FPGA,但是內存與I/O部分兩家也實行不同的設計,Cray是使用QDR II SRAM,SGI則是可實行QDR SRAM,或者也可用DDR2 SDRAM,前者容量少(80MB)但速度快,后者容量大(20GB)而速度慢,提供兩種選擇的原因是可依據不同的應用程序特性來選用。
另外,高效運算業者通常有獨門的機內通訊傳輸技術,RapidArray即是Cray的獨家技術,而SGI自身也有獨家的傳輸技術,即NUMAlink 4(已是第四代技術),所以SGI的RASC不是使用RapidArray,而是使用NUMAlink 4。
其實Cray系統內所用的FPGA模塊是與DRC Computer公司技術合作而成,因此DRC Computer自身也有提供相近方案,DRC的RPU(Reconfigurable Processor Units)同樣也是用FPGA來加速,一樣是用Xilinx VIRTEX FPGA,但與主系統間的連接接口改成AMD Opteron處理器的接座接口,如此一般使用AMD Opteron處理器的x86服務器也可以加裝RPU來提升高效運算的效能。
芯片開發時的邏輯功效驗證
FPGA的另一個新應用是芯片開發時的邏輯功效驗證。過去數字芯片在設計開發時,每開發至一個階段就必須對已經完成的電路進行邏輯上、機制上的功效驗證,以了解設計是否有誤,關于此多是用計算機軟件程序來進行邏輯推演(Simulation),不過用計算機程序來進行驗證,其推演速度相當慢,所以每一項驗證都要經過漫長等待才能知道結果。
對此或許有人會說:可以使用更快速的計算機來加快驗證,但這其實是雞與蛋的問題,計算機效能提升其實是因為芯片效能愈來愈高,芯片效能愈來愈高原因可用摩爾定律來解釋,在摩爾定律下,芯片開發速度變快、同時也讓芯片更復雜,所以「計算機的更快速」與「芯片的更復雜」是連動的,使用了更快速的計算機,也意味著要推演、驗證更復雜設計的芯片,最根本的問題并還沒有真正解決。
不過,由于FPGA的電路密度、運作效能在近年來大幅提升,所以開始有人提議用FPGA來取代純計算機執行的驗證軟件,如此推演速度就可以獲得大幅提升。舉例來說,IBM、Sony、Toshiba三家業者所共同合作開發的Cell芯片,當芯片還在開發階段時就已經使用FPGA來推演驗證,以加速了解設計上的正確性。更具體來說,就是將新芯片的邏輯電路加載到FPGA,讓FPGA充當新芯片來執行。
改采FPGA方式來驗證,其優點不僅是加速驗證程序,也可以節省驗證成本,過去為了加速驗證,必須動用大量的計算機,讓眾多的計算機同時都執行驗證程序,才能讓驗證速度提升,有時其計算機的用量甚至要用及整個運算機房內的計算機,而今改成FPGA方式驗證后,計算機用量就可大幅減少。
要注意的是,由于芯片的電路愈來愈復雜,即便使用高階、大容量(邏輯閘)的FPGA,都很難單獨用一顆FPGA就仿真出整個新芯片,所以通常是同時用上多顆FPGA芯片,每顆FPGA芯片仿真部份的新芯片電路,然后再將多個FPGA芯片進行串連,用多個芯片來同時仿真一顆新芯片。
另外,FPGA雖可以進行芯片設計的功效驗證,但并不代表整個芯片的設計開發流程都可以加速,芯片電路設計的部份依舊需要工程師人工設計,只有功效驗證上可以獲得加速。再者,功效驗證完全正確后并不代表芯片就此設計完成(除非該芯片確定直接以FPGA方式出貨),后續在正式投產之前,還要經過頻率收斂、電路化簡等其它實體電路特性的調修,這方面FPGA也無從給予幫助。
數字信號處理器(DSP)
FPGA另一個新應用是取代DSP,由于FPGA適合規劃成可同時大量平行運算組態,如此可加速數字信號運算。
所謂的「取代」,其實牽涉到價格效能比(Price Performance Rate,中國內地方面稱為:性價比,性能價格比)問題,相同的數字信號運算工作可以用FPGA運算,也可以用DSP運算,重點在于芯片成本,一般而言FPGA的芯片價格貴過DSP,但FPGA同時間可平行執行的數字信號運算量比DSP大,當數字信號運算的需求量夠大時,FPGA在價格效能比上就會超越DSP。
若更具體說明,一顆高效能的DSP約要30至200美元,而一顆高階的FPGA則約200美元,高效能的DSP同時間可以處理4個信道的數字信號,而高階的FPGA則可因應20至40個信道以上的信號運算,如此簡單將信道數與價格相除,可明顯看出在同時多組運算時FPGA的成本低于DSP。
當然,先決條件是應用需求上需要同時間的多組運算,并非所有的應用都需要大量的數字信號運算,不過無線基地臺方面確實有此種需求,但無線基地臺前端的用戶裝置則沒有這類的需求,事實上現在確實有諸多的無線基地臺,已從過去完全只用DSP方式來進行信號收發解析處理,改成部份使用DSP、部份使用FPGA。
但是這也并非絕對,原因有二,一是FPGA仍在積極降價中,未來的價格性能比會持續提升,目前只有大量的數字信號運算是屬于FPGA較合算,但日后也會逐漸往中階、初階發展,接下來可能小規模性的基地臺(如Pico Cell、Femto Cell等)也會使用。
另一是前端用戶的數字信號運算量也在增加,特別是MIMO技術已經進入到末端用戶產品上(如IEEE 802.11n標準),同時2個、3個天線的收發將使數字信號的運算量增加,加上愈來愈多無線技術是使用OFDM調變,而OFDM的調變為高度平行化的運算,使用FPGA將可獲得不錯的效益。
雖然許多人看好FPGA取代DSP的后續發展,但是FPGA也并非全然無威脅,目前許多芯片業者正積極發展多核心處理器,例如Tilera公司的Tile64處理器擁有64個執行核心,一樣可以提供大量平行的運算,而不需要使用FPGA或DSP。
如冰山般「厚實、緩慢」的推進
上述三種FPGA的新應用,筆者個人認為往后只會更擴展、更深入地運用,而不可能回退,高效運算系統未來只會愈來愈常使用FPGA,芯片設計上的邏輯功效驗證也會愈來愈常用使用FPGA,并減少使用推演軟件(或稱:仿真軟件),基地臺等應用也是如此。
所以FPGA是厚實地擁有了這三項新應用,未來用量與運用程度只會增加,但會慢慢地增加,因為FPGA的電路密度(或稱:晶體管數量)只會愈來愈密、運作效能只會愈來愈快,同時價格也將愈來愈低。如同冰山一樣:緩慢擴展,但每一英寸擴展卻都相當地堅厚而難以回退。
△圖說:Cray XD1超級計算機內的應用程序加速模塊是用FPGA做協處理器,接著透過RapidArray接口連接至RapidArray的接口處理器(簡稱:RAP),RAP另一端再以HyperTransport(簡稱:HT)接口與超級計算機的主處理器連接。(www.Cray.com)
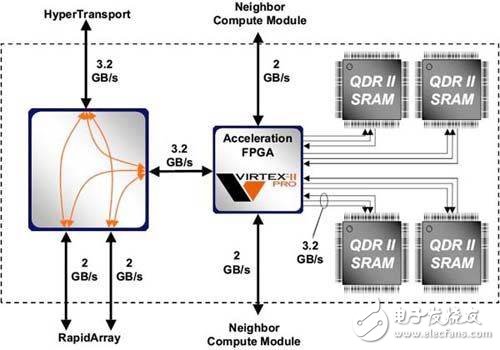
△圖說:Cray XD1超級計算機應用程序加速模塊部分的更仔細線路圖,其中Xilinx VIRTEX FPGA與4顆QDR II SRAM相連,同時自身也能與其它相鄰運算模塊溝通傳輸,另外也與RAP相連。(www.Cray.com)
△圖說:SGI的RASC應用程序加速模塊,可直接加裝在SGI超級計算機機箱的上端,并透過NUMAlink 4接口與超級計算機相連,以加速原有超級計算機的應用程序運算。
△圖說:SGI RASC加速模塊的內部圖,中間部位的銅質散熱片下方即是FPGA芯片,設置于周旁的則是內存模塊,后端的黑色連接器即是NUMAlink 4接口,2組連接器表示RASC具有2組NUMAlink 4接口。
△圖說:另一款SGI RASC:RASC RC100 Blade,圖中可見大量的DDR2 SDRAM內存模塊,容量最高可至20GB,適合在大數據量的高效運算。
△圖說:Cell寬帶引擎芯片還在電路的開發設計階段時,是先運用數顆FPGA芯片組兜出Cell的仿真電路,然后推演、驗證其功效邏輯及機制是否正確無誤,圖為Cell芯片的裸晶與一般文具圖釘的體積比較。
△圖說:無線收發基地臺端有著同時多組數字信號的運算需求,此時就價格效能比而言使用FPGA將比使用多顆DSP合算,圖中為WiMAX基地臺端的模塊化運算機箱(東訊TECOM公司的WM5070),機箱內負責無線傳輸的收發信號解析與演算,若WiMAX基地臺使用方位性天線,則同時間內所需要運算的信號組數也會增加。



















 工商網監
工商網監
評論