 電子發燒友App
電子發燒友App


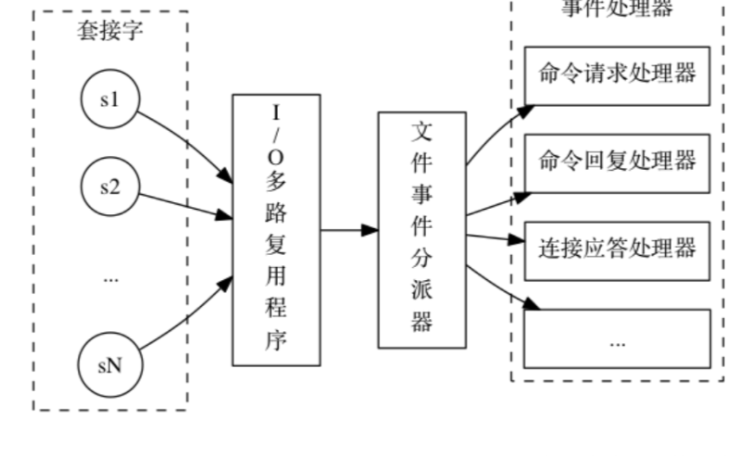
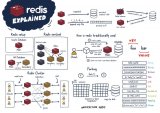
Redis對象類型簡介
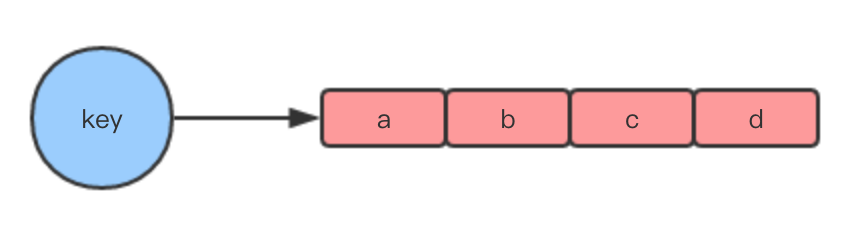
Redis是一種key/value型數據庫,其中,每個key和value都是使用對象表示的。比如,我們執行以下代碼:
[plain]
redis>SET?message?“hello?redis” ?
redis>SET message "hello redis"
其中的key是message,是一個包含了字符串”message”的對象。而value是一個包含了”hello redis”的對象。
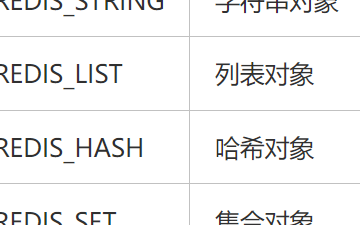
Redis共有五種對象的類型,分別是:
類型常量 對象的名稱
REDIS_STRING?字符串對象?
REDIS_LIST?列表對象?
REDIS_HASH?哈希對象?
REDIS_SET?集合對象?
REDIS_ZSET?有序集合對象?
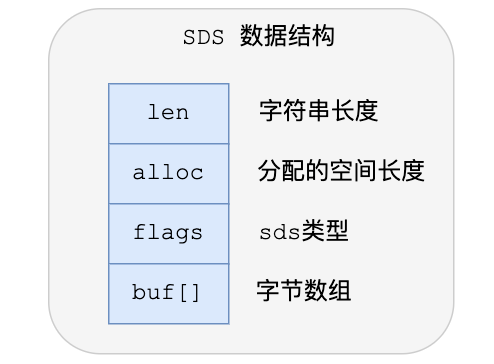
Redis中的一個對象的結構體表示如下:
[cpp]
/*?
*?Redis?對象?
*/??
typedef?struct?redisObject?{ ?
//?類型??
unsigned?type:4; ? ? ? ? ?
//?不使用(對齊位)??
unsigned?notused:2; ?
//?編碼方式??
unsigned?encoding:4; ?
//?LRU?時間(相對于?server.lruclock)??
unsigned?lru:22; ?
//?引用計數??
int?refcount; ?
//?指向對象的值??
void?*ptr; ?
}?robj; ?
/* * Redis 對象 */ typedef struct redisObject { // 類型 unsigned type:4; // 不使用(對齊位) unsigned notused:2; // 編碼方式 unsigned encoding:4; // LRU 時間(相對于 server.lruclock) unsigned lru:22; // 引用計數 int refcount; // 指向對象的值 void *ptr; } robj;
type表示了該對象的對象類型,即上面五個中的一個。但為了提高存儲效率與程序執行效率,每種對象的底層數據結構實現都可能不止一種。encoding就表示了對象底層所使用的編碼。下面先介紹每種底層數據結構的實現,再介紹每種對象類型都用了什么底層結構并分析他們之間的關系。
Redis對象底層數據結構
底層數據結構共有八種,如下表所示:
編碼常量 編碼所對應的底層數據結構
REDIS_ENCODING_INT?long類型的整數?
REDIS_ENCODING_EMBSTR?embstr編碼的簡單動態字符串?
REDIS_ENCODING_RAW?簡單動態字符串?
REDIS_ENCODING_HT?字典?
REDIS_ENCODING_LINKEDLIST?雙端鏈表?
REDIS_ENCODING_ZIPLIST?壓縮列表?
REDIS_ENCODING_INTSET?整數集合?
REDIS_ENCODING_SKIPLIST?跳躍表和字典?
字符串對象
字符串對象的編碼可以是int、raw或者embstr。
如果一個字符串的內容可以轉換為long,那么該字符串就會被轉換成為long類型,對象的ptr就會指向該long,并且對象類型也用int類型表示。
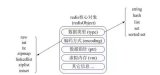
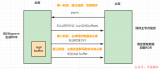
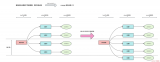
普通的字符串有兩種,embstr和raw。embstr應該是Redis 3.0新增的數據結構,在2.8中是沒有的。如果字符串對象的長度小于39字節,就用embstr對象。否則用傳統的raw對象。可以從下面這段代碼看出:
[cpp]
#define?REDIS_ENCODING_EMBSTR_SIZE_LIMIT?39??
robj?*createStringObject(char?*ptr,?size_t?len)?{??
if?(len?<=?REDIS_ENCODING_EMBSTR_SIZE_LIMIT)??
return?createEmbeddedStringObject(ptr,len);??
else??
return?createRawStringObject(ptr,len);??
} ?
#define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39 robj *createStringObject(char *ptr, size_t len) { if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT) return createEmbeddedStringObject(ptr,len); else return createRawStringObject(ptr,len); }embstr的好處有如下幾點:
embstr的創建只需分配一次內存,而raw為兩次(一次為sds分配對象,另一次為objet分配對象,embstr省去了第一次)。
相對地,釋放內存的次數也由兩次變為一次。
embstr的objet和sds放在一起,更好地利用緩存帶來的優勢。
需要注意的是,redis并未提供任何修改embstr的方式,即embstr是只讀的形式。對embstr的修改實際上是先轉換為raw再進行修改。
?
raw和embstr的區別可以用下面兩幅圖所示:
列表對象
列表對象的編碼可以是ziplist或者linkedlist。
ziplist是一種壓縮鏈表,它的好處是更能節省內存空間,因為它所存儲的內容都是在連續的內存區域當中的。當列表對象元素不大,每個元素也不大的時候,就采用ziplist存儲。但當數據量過大時就ziplist就不是那么好用了。因為為了保證他存儲內容在內存中的連續性,插入的復雜度是O(N),即每次插入都會重新進行realloc。如下圖所示,對象結構中ptr所指向的就是一個ziplist。整個ziplist只需要malloc一次,它們在內存中是一塊連續的區域。
linkedlist是一種雙向鏈表。它的結構比較簡單,節點中存放pre和next兩個指針,還有節點相關的信息。當每增加一個node的時候,就需要重新malloc一塊內存。
哈希對象
哈希對象的底層實現可以是ziplist或者hashtable。
ziplist中的哈希對象是按照key1,value1,key2,value2這樣的順序存放來存儲的。當對象數目不多且內容不大時,這種方式效率是很高的。
hashtable的是由dict這個結構來實現的
[cpp]
typedef?struct?dict?{??
dictType?*type;??
void?*privdata;??
dictht?ht[2];??
long?rehashidx;?/*?rehashing?not?in?progress?if?rehashidx?==?-1?*/??
int?iterators;?/*?number?of?iterators?currently?running?*/??
}?dict; ?
typedef struct dict { ??? dictType *type; ??? void *privdata; ??? dictht ht[2]; ??? long rehashidx; /* rehashing not in progress if rehashidx == -1 */ ??? int iterators; /* number of iterators currently running */ } dict;dict是一個字典,其中的指針dicht ht[2] 指向了兩個哈希表
[cpp]
typedef?struct?dictht?{??
dictEntry?**table;??
unsigned?long?size;??
unsigned?long?sizemask;??
unsigned?long?used;??
}?dictht;??
?
typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht;dicht[0] 是用于真正存放數據,dicht[1]一般在哈希表元素過多進行rehash的時候用于中轉數據。
dictht中的table用語真正存放元素了,每個key/value對用一個dictEntry表示,放在dictEntry數組中。
?
集合對象
集合對象的編碼可以是intset或者hashtable。
intset是一個整數集合,里面存的為某種同一類型的整數,支持如下三種長度的整數:
[cpp]
#define?INTSET_ENC_INT16?(sizeof(int16_t))??
#define?INTSET_ENC_INT32?(sizeof(int32_t))??
#define?INTSET_ENC_INT64?(sizeof(int64_t)) ?
#define INTSET_ENC_INT16 (sizeof(int16_t))
有序集合對象
有序集合的編碼可能兩種,一種是ziplist,另一種是skiplist與dict的結合。
ziplist作為集合和作為哈希對象是一樣的,member和score順序存放。按照score從小到大順序排列。它的結構不再復述。
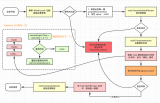
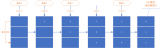
skiplist是一種跳躍表,它實現了有序集合中的快速查找,在大多數情況下它的速度都可以和平衡樹差不多。但它的實現比較簡單,可以作為平衡樹的替代品。它的結構比較特殊。下面分別是跳躍表skiplist和它內部的節點skiplistNode的結構體:
[cpp]
/*?
*?跳躍表?
*/??
typedef?struct?zskiplist?{??
//?頭節點,尾節點??
struct?zskiplistNode?*header,?*tail;??
//?節點數量??
unsigned?long?length;??
//?目前表內節點的最大層數??
int?level;??
}?zskiplist;??
/*?ZSETs?use?a?specialized?version?of?Skiplists?*/??
/*?
*?跳躍表節點?
*/??
typedef?struct?zskiplistNode?{??
//?member?對象??
robj?*obj;??
//?分值??
double?score;??
//?后退指針??
struct?zskiplistNode?*backward;??
//?層??
struct?zskiplistLevel?{??
//?前進指針??
struct?zskiplistNode?*forward;??
//?這個層跨越的節點數量??
unsigned?int?span;??
}?level[];??
}?zskiplistNode; ?
/* * 跳躍表 */ typedef struct zskiplist { // 頭節點,尾節點 struct zskiplistNode *header, *tail; // 節點數量 unsigned long length; // 目前表內節點的最大層數 int level; } zskiplist; /* ZSETs use a specialized version of Skiplists */ /* * 跳躍表節點 */ typedef struct zskiplistNode { // member 對象 robj *obj; // 分值 double score; // 后退指針 struct zskiplistNode *backward; // 層 struct zskiplistLevel { // 前進指針 struct zskiplistNode *forward; // 這個層跨越的節點數量 unsigned int span; } level[]; } zskiplistNode;head和tail分別指向頭節點和尾節點,然后每個skiplistNode里面的結構又是分層的(即level數組)
用圖表示,大概是下面這個樣子:
每一列都代表一個節點,保存了member和score,按score從小到大排序。每個節點有不同的層數,這個層數是在生成節點的時候隨機生成的數值。每一層都是一個指向后面某個節點的指針。這種結構使得跳躍表可以跨越很多節點來快速訪問。
前面說到了,有序集合ZSET是有跳躍表和hashtable共同形成的。
[cpp]
typedef?struct?zset?{??
//?字典??
dict?*dict;??
//?跳躍表??
zskiplist?*zsl;??
}?zset; ?
typedef struct zset { // 字典 dict *dict; // 跳躍表 zskiplist *zsl; } zset;為什么要用這種結構呢。試想如果單一用hashtable,那可以快速查找、添加和刪除元素,但沒法保持集合的有序性。如果單一用skiplist,有序性可以得到保障,但查找的速度太慢O(logN)。結尾
簡單介紹了Redis的五種對象類型和它們的底層實現。事實上,Redis的高效性和靈活性正是得益于對于同一個對象類型采取不同的底層結構,并在必要的時候對二者進行轉換;以及各種底層結構對內存的合理利用。
















 工商網監
工商網監
評論