 電子發燒友App
電子發燒友App


2023 年 10 月 27 日,蟄伏了 3 年之久的極越 01 正式上市,相比于已經曝光到幾乎明牌的整車,我更對極越 01 所搭載的這套輔助駕駛系統更感興趣。 主要有兩個點:
Apollo 高階自動駕駛能力全面賦能
單挑特斯拉,中國唯一的量產純視覺方案
這兩個點提取一個關鍵詞最終都落在了「純視覺」上,如果長期研究輔助駕駛技術的對純視覺輔助駕駛方案都不陌生,這是目前僅有特斯拉一家量產應用上車的智駕方案。
在 2023 年新能源汽車行業如此內卷的態勢下,極越 01 作為一個新選手要用什么姿態來奪得大眾的目光?
顯然智駕是一個比較好的選擇,不管是華為、蔚來、理想、小鵬都明確了自家要在智能化這條道上比拼到底,而這中間最核心的部分當屬智駕。
智駕比拼是一個確定性的答案,可是在國內沒有一家說要完全切換到純視覺,當然除了極越。
這是一個很有趣的現象,一方面是國內各家不敢切換還是不想切換;另一方面純視覺究竟有什么魔力,讓特斯拉和其他廠商分歧如此之大。
對于中國路況,其他主機廠給出的答案是要用激光雷達解決多復雜場景,實現安全容易,而極越的選擇是用「純視覺」挑戰技術極限。
01
先了解整車
極越 01 目前推出兩個版本:
極越 01 MAX
CLTC 續航 550km
后驅電機最大功率 200 kW
標配高通 8295、2 顆 Orin X?等支持城市輔助駕駛的智駕硬件
售價 24.99 萬元(1.9 萬上市權益包后 23.09 萬)
選裝 100 度電池包,續航可達?720km
極越 01 MAX Performance
標配 100 度電池包,CLTC 續航 660km
四驅雙電機?200kW + 200kW
標配高通 8295、2 顆 Orin X?等支持城市輔助駕駛的智駕硬件
標配可升降尾翼
售價 33.99 萬元(1.9 萬元上市權益包后 32.09 萬元)
從實際體驗來看,作為一個新品牌,新產品極越 01 的完成度是不錯的,以智能化為整體差異化的方式雖然很難,但路徑選擇道也合理,整車設計并沒有出現過于嘩眾取寵的點。
可是極越 01 最大的難點在于,一上市就遇到了汽車行業史無前例的價格戰,特別是整車的優惠權益讓很多潛在用戶看不懂的情況下,24.99 萬的起售價顯得并不是很有沖擊力。
但真的如此嗎?
先說一個現象:「極越 01 整體優惠后的價格其實非常有誠意,但是極越對于權益的策略制定卻非常混亂,這個混亂導致很多真實的潛在用戶根本看不懂。」
一個一個說:
一,現金優惠
這個優惠是實打實的現金權益,是直接抵扣在車價里面的,這里面包含兩個部分:
1.9 萬元上市權益金:9000 元盲訂膨脹金 + 5000 元大定立減金 + 5000 元邀請獎勵(4000 元京東卡加上 10000 積分);
1.5 萬元選裝基金:如果選擇收費選裝項目可以立減 1.5 萬元。
也就是,1.9 萬元和 1.5 萬元疊加使用后,可綜合優惠 3.4 萬元。
二,整車權益
在 11 月 30 日之前的定購的用戶,均可享受三個非常劃算的權益:
終身整車及三電質保、道路救援:價值 8000 元
直流家充樁或 2 年免費充電:價值 7500 元
ROBO Drive MAX 6 個月免費訂閱:價值 5880 元
也就是說,購買極越 01 MAX 550km 版疊加完權益后只需要 23.59 萬元,同時還能免費拿一套舒享套裝。
但智駕權益里面有一個小細節,按照目前的權益策略是買斷 1.99 萬元、訂閱 980 元/月,但如果你用選裝基金買斷智駕系統的話只需要 4900 元買斷。
但你需要注意一個細節,如果你用 1.5 萬元選裝基金去抵扣智駕買斷,那么你也會失去舒享套裝。
總結則是,舒享套裝和智駕系統你只能白嫖一個。
講完整車,下面智駕才是極越 01 的核心。
02
智駕最終要回歸到硬件的合理性上
硬件堆疊并不能保證最終的體驗
在講極越 01 的純視覺方案之前,先說一個背景:
我們都知道市面上將智駕分為「純視覺」和「激光雷達融合」方案兩種,可是對于這兩種方案區別性的解釋,往往只歸結在有無激光雷達硬件這一個維度上。
顯然,這么理解對于輔助駕駛的解釋即不明確也不立體。
我們先理解輔助駕駛系統包含的核心兩個能力,很好理解:一個是硬件,包含計算平臺、感知傳感器、定位等;另一個則是算法,一個系統運行的基本神經網絡系統。
純視覺和激光雷達方案,除了字面意思理解到的感知傳感器的區別,還有就是算法對于攝像頭和激光雷達數據處理的方式。
簡單說就是,即使使用了激光雷達,但激光雷達數據的融合方式也決定了系統整個能力的表現,有些廠商的方案是視覺數據和激光雷達數據是分別處理的,融合過程在各自輸出結果的層面上完成,也就是自動駕駛領域常說的?「后融合」。
這樣做可以盡可能地保證兩個系統之間的獨立性,并為彼此提供安全冗余。
但后融合也導致神經網絡,無法充分利用兩個異構傳感器之間數據的互補性,來學習最有價值的特征。
這也是異構感知傳感器系統,為什么大部分都存在「時間上的感知不連續、空間上的感知碎片化」的問題。」
我回想起 2021 年,車企爭相宣布擺脫供應商方案,選擇自動駕駛「全棧自研」,彼時輔助駕駛賽道還是 Mobileye 的天下,大部分車企的輔助駕駛方案都來自于 MobilEye 的能力,乃至于國內第一個高速導航輔助駕駛量產方案蔚來 NOP 也是基于 MobilEye 視覺方案進行的二次開發。
從供應商切換到自研意味著一切從零開始,但是要很快追平原有方案的體驗。
但是新產品的上市,只留給了車企們兩年的時間,而 Mobileye 成立于 1999 年,2008 年就提供了 Eye Q1 芯片,目前出貨量已經超過一億片。
到了 2020 年 Eye Q4 已經是全球出貨量最大的智駕芯片,Mobileye 的 L2 方案幾乎拿下來國內外大部分頂級廠商,蔚來、理想、寶馬等等。
這種競爭并不公平。
好在我們有一條清晰的捷徑?「激光雷達」,它可以提供珍貴的距離真值,給出了相對直接的世界描述,給開發提供了極大便利。
也正因如此,一切就顯得水到渠成,眾多車企開始比拼激光雷達的數目。鋪天蓋地的宣傳下「硬件性能不等于最終體驗」這件事卻被有意忽略了。
硬件只是基礎,算法的能力決定了系統的上限。
到 2023 年,消費者開始發現,即使攝像頭和激光雷達遍布全車,更高階的輔助駕駛功能并沒有如期而至。
車企的算法能力沒有因為硬件的堆疊而得到質的飛躍,而特斯拉依然靠著幾乎普通的感知硬件,用純視覺始終保持在輔助駕駛第一陣營。
純視覺通往高階輔助駕駛的最優解?
人靠視覺就能開車,那么視覺就能完成輔助駕駛。這是馬斯克的第一性原理,特斯拉死磕純視覺的理由。
那么技術上是怎么實現的?
我們在路上看到一輛車能夠知道,這可能是一個障礙物,同時我們也可以大概估計這輛車離我們有多遠。
純視覺算法也是如此。
本質上是通過對圖像信息的特征進行廣泛的訓練,讓神經網絡獲得視覺估計距離的能力。?
經過大量數據訓練的算法,能夠得到前方障礙物的類型,同時得到一個位置估計,提供給下游規劃控制算法。
當然,這里最重要的是:「精確的真值標注」和「大量的數據」。
這不是一件簡單的事情。
需要用數據壓榨算法的能力,在弱硬件上得到足夠好的性能,逐漸逼近算法的上限。
03
純視覺算法的上限在哪?
純視覺估計距離具備足夠的數學理論基礎
這里舉一個例子,雙目測距,假設我們有一個點 P,但是我們用不同的攝像頭去拍攝這個點,那么這個點會分別在左邊和右邊的圖片上分別形成一個點。
如果我們對這兩個點的位置尋找得足夠準確的話,根據圖片上這兩個點 p_l,p_r 的位置差別,我們可以按照相似三角形的原理,計算出 P 點在世界中的位置。
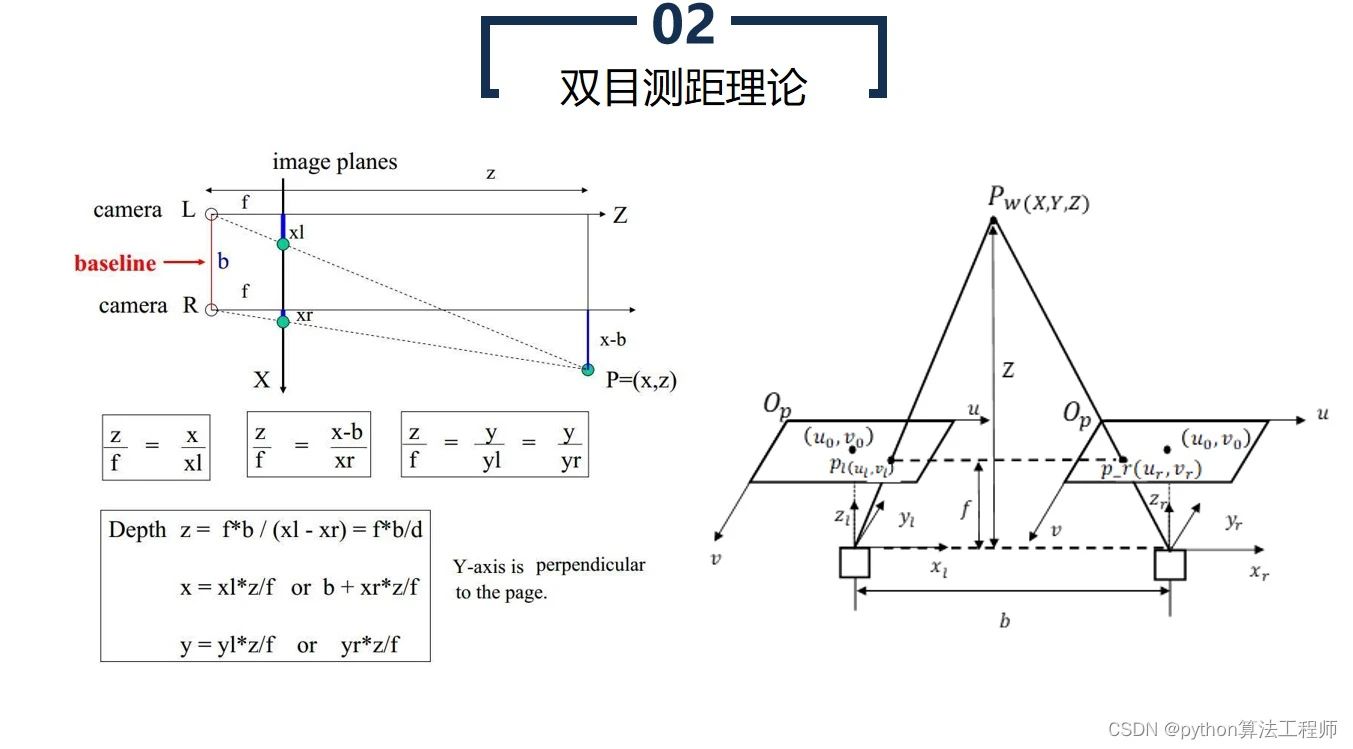
當然,這里有許多局限,在圖片上的點進行搜索時,我們并不總能如愿找到精確兩個點對,所以傳統雙目測距會有一定的局限性。
但是,這種數學原理也告訴我們,視覺算法的上限是足夠高的。
本質原理即:多個攝像頭之間的視覺特征互相驗證,能夠獲得相對精確的距離信息。
實際上目前主流的 BEV 的網絡,某種程度上也可以看作將視覺特征投影到 BEV 俯視圖下,各視角的特征進行互相自動驗證,最終得到一個相對精確的結果的。
但即使業界認為視覺的上限很高,但執行量產的動作卻是一個地獄級別的難度,那么純視覺難度在何處?
「純視覺」企業工程師的噩夢
從傳統雙目視覺的角度看,我們無法如愿找到精確的兩個點對,而從深度學習的角度看,我們無法保證神經網絡內部的多個攝像頭的視覺互相驗證時正確的。
算法一直都在不斷演進,例如 BEV 視角去進行自動駕駛感知,Transformer 結構也獲得了很多關注。
但是在特斯拉驗證可行之前,沒有人這么做量產。
因為需要大量的數據進行神經網絡的訓練,來逐步提升距離估計的精確。
特斯拉用強大的工程能力完成數據閉環,示范這件事情可行。回想起 2021 年看特斯拉 AI Day 那個夜晚,行業驚呼特斯拉的工程能力之強,也驚呼純視覺的上限竟然如此高。
那么需要怎么做?
為了保證輔助駕駛的可靠性,工程師需要一個對周圍障礙物估計的網絡,這樣就車輛能夠看到周圍交通參與者,并且能夠對它們進行及時的反應。
這就是 BEV 動態網絡,本質上俯視圖,將所有的攝像頭信息都投影到這個俯視圖上,由于每個攝像頭之間有互相的信息補齊,這樣對遮擋的物體也能夠較好的識別,并且當引入時序信息。
也就是說,將這一個時間段前面的信息也融合進來也能夠多一些信息進行推理,這樣會給 PNC 帶來更好的障礙物軌跡預測結果,進而帶來更安全且順滑的體驗。
視頻截圖是基于極越 01 前段時間在上海市區,基于 BEV Transformer 的純視覺架構跑出來的效果,展現出的足夠高的精度和足夠遠的感知距離,可以證明極越的純視覺方案已經有比較高的完成度。
但是這還不夠。
除了障礙物,系統還需要車道線和道路拓撲結構的識別,同樣的,將周圍的攝像頭轉換到BEV 空間下,將周圍的地圖繪制出來,這就是常說的實時繪制地圖。
這些部分完成之后,最難的部分來了。
這些本質上到目前所感知到的障礙物還是白名單物體,并且還是物體級的識別。當在城市中駕駛時,很多物體需要被更精確的描述,而且很多物體在并不在常見的白名單中。
這里出現了一個新的詞:白名單。
其實你就簡單理解成,這個時候系統所感知到的障礙物都是通過標準完成的,工程師將感知到的數據進行數據標準,形成一個可用數據包然后通過云端和實時感知進行數據比對,這樣系統在駕駛開啟時所感知到的物體都是經過標注后的。
但這有個問題,即使今天自動標注也已經逐步量產,但在真實物理世界里所出現的障礙物也不能被窮盡,同時數據標注的精度不夠高,也不能描述具體物體的 3D 信息。
一句話總結則是:白名單里的物體都是工程師標注后系統已知的物體。
那系統不知道的物體呢?
這里就需要一個「占用網絡」。
簡單來說就是,純視覺將世界感知分為無數個網格體,每個網格體里面代表被占據的概率。
在極越 01 上市之前,極越官方釋放了一個基于 OCC 占用網絡的視頻 demo,可以看到視頻里包含的感知內容:一個常規的周圍環境實時顯示;另一個通用占用網絡。
這便是極越的輔助駕駛方案:動態 BEV + 靜態 BEV + 占用網絡。
這條路與特斯拉基本一致,不同的是極越的攝像頭是 800 萬像素,而特斯拉的攝像頭是 200 萬。對于相對較遠的物體,極越這套硬件可以分配到更多的像素理論上限會更高。
BEV 動態識別網絡 + BEV 靜態網絡做地圖構建,這是相對常規的內容,頭部的幾家也基本上完成了 BEV 的量產。
為什么占用網絡上車才能證明純視覺最終能走通?
占用網絡將世界感知為相對比較小的占用空間,每個空間里面有被占據的概率。相較于常規的畫一個 3D 或者 2D 框來描述某一個具體的物體,占用網格的描述更加細膩。
例如一個兩節的大公交車,常規的描述是一個 3D 長寬高, 但是當這輛公交正在進行轉向的時候描述就顯得不夠精確了。
如果將這輛公交車分割成很多塊,這樣即使運動起來,描述也足夠精準。
極越這里也展現了不是畫一個 2D 框,顯示這個是一輛車,而是顯示這是一些被占據的空間。
這樣更加精細地描述了感知世界之后,邏輯就可以變成:
如果道路上沒有被占據就是可行駛空間,這就完全跳脫出原來識別是一個具體物體(人,車,錐桶等),然后再考慮能不能開的邏輯,而是有障礙物影響就需要做繞行或者新的路徑規劃。
這就規避了窮舉道路上所有目標的問題。
為什么純視覺占用網絡不像 BEV 一樣,提出之后被大量跟進,到目前國內也只有極越宣布今年 12 月上車?
因為二者的技術迭代路線已經出現了顯著的分歧,大部分高度重視激光雷達的算法方案,都在研究如何將激光雷達的真值更好地使用。
激光雷達可以相對天然得到一個占用網格結果,尤其是在前視部分。
比如華為提出的 GOD,從某種意義就是 Lidar 點云作為基礎,得出的占用網絡結果,通過 3D 點獲得 3D 占用網絡,再通過視覺進行一定的融合表現也很好。
相較于 Lidar 直接獲得真值,純視覺這條路要靠多攝像頭直接推導出距離信息,這中間的難度極大。
但是純視覺這條路得出占用網絡(Occupancy Grid 3D)并不是終局。
之后還會有:
「Occupancy Flow 」:就是對占用網絡運動狀態相關的估計,這個格子的自身運動狀態是什么。例如視頻里第二張圖中的紅色圈出的部分,估計出非剛體的不同部分的運動狀態,藍色運動,紅色靜止;
Occupancy prediction:對占據網格預測相關的估計,這個格子下一步怎么走
也就是說,以前目標級別的任務,在更細粒度上的占用網格上都可以做一遍,占據網絡對周圍世界的理解,不是目標級別的感知可以比擬的。
寫在最后
極越選了一條非常難并且不一樣的路,在選擇的過程中一定會伴隨著質疑,但是極越還是勇敢地站出來。
當視覺能力足夠強時,足夠完成城區高階輔助駕駛。
若無必要,勿增實體,這是互聯網產品圈非常流行的一句話。
極越方案里的純視覺選擇就是這么出現的,不看硬件,只關注體驗。
純視覺的核心是:
構建以視覺為中心的輔助駕駛系統,不被其他的傳感器分掉研發精力,并且構建出一個非常精簡的數據閉環系統,在之后的方案迭代中能夠保證數據的高度可復用性。
也期待極越使用純視覺完成端到端的方案構建。
這條路很難,但是選擇最難的這條路,或許是通向未來的最正確的一條路。
編輯:黃飛
?










 工商網監
工商網監
評論