 電子發燒友App
電子發燒友App


自從AlexNet一舉奪得ILSVRC 2012 ImageNet圖像分類競賽的冠軍后,卷積神經網絡(CNN)的熱潮便席卷了整個計算機視覺領域。CNN模型火速替代了傳統人工設計(hand-crafted)特征和分類器,不僅提供了一種端到端的處理方法,還大幅度地刷新了各個圖像競賽任務的精度,更甚者超越了人眼的精度(LFW人臉識別任務)。CNN模型在不斷逼近計算機視覺任務的精度極限的同時,其深度和尺寸也在成倍增長。
?
表1 幾種經典模型的尺寸,計算量和參數數量對比
Model Model Size(MB) Million
Mult-Adds Million
Parameters
AlexNet[1]?>200?720?60?
VGG16[2]?>500?15300?138?
GoogleNet[3]?~50?1550?6.8?
Inception-v3[4]?90-100?5000?23.2
隨之而來的是一個很尷尬的場景:如此巨大的模型只能在有限的平臺下使用,根本無法移植到移動端和嵌入式芯片當中。就算想通過網絡傳輸,但較高的帶寬占用也讓很多用戶望而生畏。另一方面,大尺寸的模型也對設備功耗和運行速度帶來了巨大的挑戰。因此這樣的模型距離實用還有一段距離。
在這樣的情形下,模型小型化與加速成了亟待解決的問題。其實早期就有學者提出了一系列CNN模型壓縮方法,包括權值剪值(prunning)和矩陣SVD分解等,但壓縮率和效率還遠不能令人滿意。
近年來,關于模型小型化的算法從壓縮角度上可以大致分為兩類:從模型權重數值角度壓縮和從網絡架構角度壓縮。另一方面,從兼顧計算速度方面,又可以劃分為:僅壓縮尺寸和壓縮尺寸的同時提升速度。
本文主要討論如下幾篇代表性的文章和方法,包括SqueezeNet[5]、Deep Compression[6]、XNorNet[7]、Distilling[8]、MobileNet[9]和ShuffleNet[10],也可按照上述方法進行大致分類:
表2 幾種經典壓縮方法及對比
Method Compression Approach Speed Consideration
SqueezeNet?architecture?No?
Deep Compression?weights?No?
XNorNet?weights?Yes?
Distilling?architecture?No?
MobileNet?architecture?Yes?
ShuffleNet?architecture?Yes
一、SqueezeNet
1.1 設計思想
SqueezeNet是F. N. Iandola,S.Han等人于2016年的論文《SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size》中提出的一個小型化的網絡模型結構,該網絡能在保證不損失精度的同時,將原始AlexNet壓縮至原來的510倍左右(< 0.5MB)。
SqueezeNet的核心指導思想是——在保證精度的同時使用最少的參數。
而這也是所有模型壓縮方法的一個終極目標。
基于這個思想,SqueezeNet提出了3點網絡結構設計策略:
策略 1.將3x3卷積核替換為1x1卷積核。
這一策略很好理解,因為1個1x1卷積核的參數是3x3卷積核參數的1/9,這一改動理論上可以將模型尺寸壓縮9倍。
策略 2.減小輸入到3x3卷積核的輸入通道數。
我們知道,對于一個采用3x3卷積核的卷積層,該層所有卷積參數的數量(不考慮偏置)為:
式中,N是卷積核的數量,也即輸出通道數,C是輸入通道數。
因此,為了保證減小網絡參數,不僅僅需要減少3x3卷積核的數量,還需減少輸入到3x3卷積核的輸入通道數量,即式中C的數量。
策略 3.盡可能的將降采樣放在網絡后面的層中。
在卷積神經網絡中,每層輸出的特征圖(feature map)是否下采樣是由卷積層的步長或者池化層決定的。而一個重要的觀點是:分辨率越大的特征圖(延遲降采樣)可以帶來更高的分類精度,而這一觀點從直覺上也可以很好理解,因為分辨率越大的輸入能夠提供的信息就越多。
上述三個策略中,前兩個策略都是針對如何降低參數數量而設計的,最后一個旨在最大化網絡精度。
1.2 網絡架構
基于以上三個策略,作者提出了一個類似inception的網絡單元結構,取名為fire module。一個fire module 包含一個squeeze 卷積層(只包含1x1卷積核)和一個expand卷積層(包含1x1和3x3卷積核)。其中,squeeze層借鑒了inception的思想,利用1x1卷積核來降低輸入到expand層中3x3卷積核的輸入通道數。如圖1所示。
圖1 Fire module結構示意圖
其中,定義squeeze層中1x1卷積核的數量是s1x1,類似的,expand層中1x1卷積核的數量是e1x1, 3x3卷積核的數量是e3x3。令s1x1 < e1x1+ e3x3從而保證輸入到3x3的輸入通道數減小。SqueezeNet的網絡結構由若干個 fire module 組成,另外文章還給出了一些架構設計上的細節:
為了保證1x1卷積核和3x3卷積核具有相同大小的輸出,3x3卷積核采用1像素的zero-padding和步長
squeeze層和expand層均采用RELU作為激活函數
在fire9后采用50%的dropout
由于全連接層的參數數量巨大,因此借鑒NIN[11]的思想,去除了全連接層而改用global average pooling。
1.3 實驗結果
表3 不同壓縮方法在ImageNet上的對比實驗結果[5]
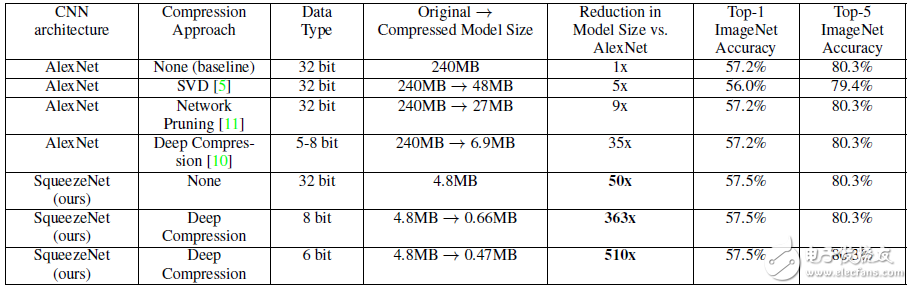
上表顯示,相比傳統的壓縮方法,SqueezeNet能在保證精度不損(甚至略有提升)的情況下,達到最大的壓縮率,將原始AlexNet從240MB壓縮至4.8MB,而結合Deep Compression后更能達到0.47MB,完全滿足了移動端的部署和低帶寬網絡的傳輸。
此外,作者還借鑒ResNet思想,對原始網絡結構做了修改,增加了旁路分支,將分類精度提升了約3%。
1.4 速度考量
盡管文章主要以壓縮模型尺寸為目標,但毋庸置疑的一點是,SqueezeNet在網絡結構中大量采用1x1和3x3卷積核是有利于速度的提升的,對于類似caffe這樣的深度學習框架,在卷積層的前向計算中,采用1x1卷積核可避免額外的im2col操作,而直接利用gemm進行矩陣加速運算,因此對速度的優化是有一定的作用的。然而,這種提速的作用仍然是有限的,另外,SqueezeNet采用了9個fire module和兩個卷積層,因此仍需要進行大量常規卷積操作,這也是影響速度進一步提升的瓶頸。
二、Deep Compression
Deep Compression出自S.Han 2016 ICLR的一篇論文《Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding》。該文章獲得了ICLR 2016的最佳論文獎,同時也具有里程碑式的意義,引領了CNN模型小型化與加速研究方向的新狂潮,使得這一領域近兩年來涌現出了大量的優秀工作與文章。
2.1 算法流程
與前面的“架構壓縮派”的SqueezeNet不同,Deep Compression是屬于“權值壓縮派”的。而兩篇文章均出自S.Han團隊,因此兩種方法結合,雙劍合璧,更是能達到登峰造極的壓縮效果。這一實驗結果也在上表中得到驗證。
Deep Compression的算法流程包含三步,如圖2所示:
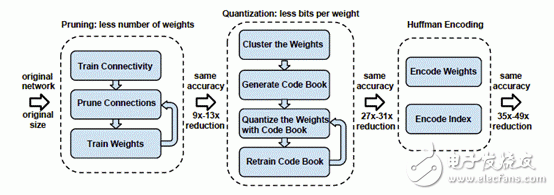
圖2 Deep Compression Pipeline
1、Pruning(權值剪枝)
剪枝的思想其實早已在早期論文中可以窺見,LeCun等人曾經就利用剪枝來稀疏網絡,減小過擬合的風險,提升網絡泛化性。
圖3是MNIST上訓練得到的LeNet conv1卷積層中的參數分布,可以看出,大部分權值集中在0處附近,對網絡的貢獻較小,在剪值中,將0值附近的較小的權值置0,使這些權值不被激活,從而著重訓練剩下的非零權值,最終在保證網絡精度不變的情況下達到壓縮尺寸的目的。
實驗發現模型對剪枝更敏感,因此在剪值時建議逐層迭代修剪,另外每層的剪枝比例如何自動選取仍然是一個值得深入研究的課題。
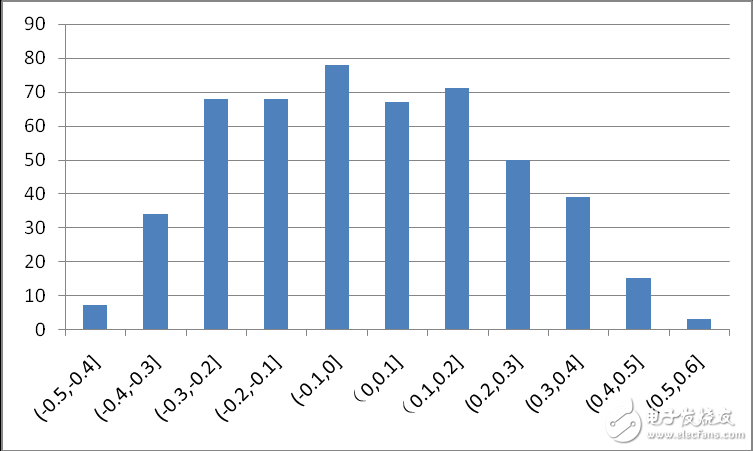
圖3 LeNet conv1層權值分布圖
2、Quantization (權值量化)
此處的權值量化基于權值聚類,將連續分布的權值離散化,從而減小需要存儲的權值數量。
初始化聚類中心,實驗證明線性初始化效果最好;
利用k-means算法進行聚類,將權值劃分到不同的cluster中;
在前向計算時,每個權值由其聚類中心表示;
在后向計算時,統計每個cluster中的梯度和將其反傳。
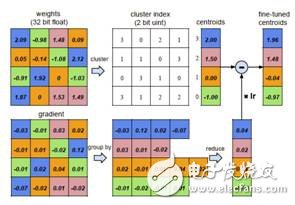
圖4 權值量化前向和后向計算過程
3、Huffman encoding(霍夫曼編碼)
霍夫曼編碼采用變長編碼將平均編碼長度減小,進一步壓縮模型尺寸。
2.2 模型存儲
前述的剪枝和量化都是為了實現模型的更緊致的壓縮,以實現減小模型尺寸的目的。
對于剪枝后的模型,由于每層大量參數為0,后續只需將非零值及其下標進行存儲,文章中采用CSR(Compressed Sparse Row)來進行存儲,這一步可以實現9x~13x的壓縮率。
對于量化后的模型,每個權值都由其聚類中心表示(對于卷積層,聚類中心設為256個,對于全連接層,聚類中心設為32個),因此可以構造對應的碼書和下標,大大減少了需要存儲的數據量,此步能實現約3x的壓縮率。
最后對上述壓縮后的模型進一步采用變長霍夫曼編碼,實現約1x的壓縮率。
2.3 實驗結果
表4 不同網絡采用Deep Compression后的壓縮率
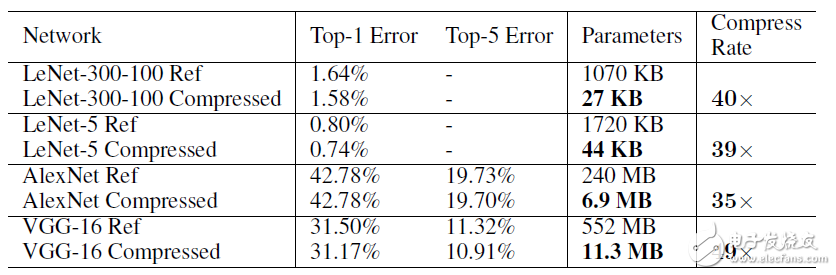
通過SqueezeNet+Deep Compression,可以將原始240M的AlexNet壓縮至0.47M,實現約510x的壓縮率。
2.4 速度考量
可以看出,Deep Compression的主要設計是針對網絡存儲尺寸的壓縮,但在前向時,如果將存儲模型讀入展開后,并沒有帶來更大的速度提升。因此Song H.等人專門針對壓縮后的模型設計了一套基于FPGA的硬件前向加速框架EIE[12],有興趣的可以研究一下。
三、XNorNet
二值網絡一直是模型壓縮和加速領域經久不衰的研究課題之一。將原始32位浮點型的權值壓縮到1比特,如何最大程度地減小性能損失就成為了研究的關鍵。
此篇論文主要有以下幾個貢獻:
提出了一個BWN(Binary-Weight-Network)和XNOR-Network,前者只對網絡參數做二值化,帶來約32x的存儲壓縮和2x的速度提升,而后者對網絡輸入和參數都做了二值化,在實現32x存儲壓縮的同時帶了58x的速度提升;
提出了一個新型二值化權值的算法;
第一個在大規模數據集如ImageNet上提交二值化網絡結果的工作;
無需預訓練,可實現training from scratch。
3.1 BWN

即最優的二值化濾波器張量B即為原始參數的符號函數,最優的尺度因子為每個濾波器權值的絕對值的均值。
訓練算法如圖5所示,值得注意的是,只有在前向計算和后向傳播時使用二值化后的權值,在更新參數時依然使用原始參數,這是因為如果使用二值化后的參數會導致很小的梯度下降,從而使得訓練無法收斂。
3.2 XNOR-Net
在XNOR網絡中,優化的目標是將兩個實數向量的點乘近似到兩個二值向量的點乘,即

在卷積計算中,輸入和權值均量化成了二值,因此傳統的乘法計算變成了異或操作,而非二值化數據的計算只占了很小一部分。
XNOR-Net中一個典型的卷積單元如圖6所示,與傳統單元不同,各模塊的順序有了調整。為了減少二值化帶來的精度損失,對輸入數據首先進行BN歸一化處理,BinActiv層用于對輸入做二值化,接著進行二值化的卷積操作,最后進行pooling。

圖5 BWN訓練過程
圖6 傳統卷積單元與XNOR-Net卷積單元對比
3.3 實驗結果
表5 ImageNet上二值網絡與AlexNet結果對比
與ALexNet相比,BWN網絡能夠達到精度基本不變甚至略好,XNOR-Net由于對輸入也做了二值化,性能稍降。
四、Distilling
Distilling算法是Hinton等人在論文Distilling the Knowledge in a Neural Network中提出的一種類似網絡遷移的學習算法。
4.1 基本思想
Distilling直譯過來即蒸餾,其基本思想是通過一個性能好的大網絡來教小網絡學習,從而使得小網絡能夠具備跟大網絡一樣的性能,但蒸餾后的小網絡參數規模遠遠小于原始大網絡,從而達到壓縮網絡的目的。
其中,訓練小模型(distilled model)的目標函數由兩部分組成
1) 與大模型(cumbersome model)的softmax輸出的交叉熵(cross entropy),稱為軟目標(soft target)。其中,softmax的計算加入了超參數溫度T,用以控制輸出,計算公式變為
溫度T越大,輸出的分布越緩和,概率zi/T越小,熵越大,但若T過大,會導致較大熵引起的不確定性增加,增加了不可區分性。
至于為何要以soft target來計算損失,作者認為,在分類問題中,真值(groundtruth)是一個確定性的,即one-hot vector。以手寫數字分類來說,對于一個數字3,它的label是3的概率是1,而是其他數值的概率是0,而對于soft target,它能表征label是3的概率,假如這個數字寫的像5,還可以給出label是5的一定概率,從而提供更多信息,如
數字 0 1 2 3 4 5 6 7 8 9
真值?0?0?0?1?0?0?0?0?0?0?
軟目標?0?0?0?0.95?0?0.048?0.002?0?0?0
2)與真值(groundtruth)的交叉熵(T=1)
訓練的損失為上述兩項損失的加權和,通常第二項要小很多。
4.2 實驗結果
作者給出了在語音識別上的實驗結果對比,如下表
表6 蒸餾模型與原始模型精度對比[8]
上表顯示,蒸餾后的模型的精確度和單字錯誤率和用于產生軟目標的10個模型的性能相當,小模型成功地學到了大模型的識別能力。
4.3 速度考量
Distilling的提出原先并非針對網絡加速,而最終計算的效率仍然取決于蒸餾模型的計算規模,但理論上蒸餾后的小模型相對原始大模型的計算速度在一定程度上會有提升,但速度提升的比例和性能維持的權衡是一個值得研究的方向。
五、MobileNet
MobileNet是由Google提出的針對移動端部署的輕量級網絡架構。考慮到移動端計算資源受限以及速度要求嚴苛,MobileNet引入了傳統網絡中原先采用的group思想,即限制濾波器的卷積計算只針對特定的group中的輸入,從而大大降低了卷積計算量,提升了移動端前向計算的速度。
5.1 卷積分解
MobileNet借鑒factorized convolution的思想,將普通卷積操作分成兩部分:
Depthwise Convolution
每個卷積核濾波器只針對特定的輸入通道進行卷積操作,如下圖所示,其中M是輸入通道數,DK是卷積核尺寸:
圖7 Depthwise Convolution
Depthwise convolution的計算復雜度為 DKDKMDFDF,其中DF是卷積層輸出的特征圖的大小。
Pointwise Convolution
采用1x1大小的卷積核將depthwise convolution層的多通道輸出進行結合,如下圖,其中N是輸出通道數:
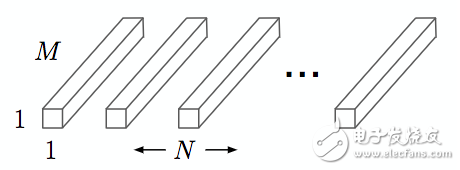
圖8 Pointwise Convolution[
Pointwise Convolution的計算復雜度為 MNDFDF
上面兩步合稱depthwise separable convolution
標準卷積操作的計算復雜度為DKDKMNDFDF
因此,通過將標準卷積分解成兩層卷積操作,可以計算出理論上的計算效率提升比例:
對于3x3尺寸的卷積核來說,depthwise separable convolution在理論上能帶來約8~9倍的效率提升。
5.2 模型架構
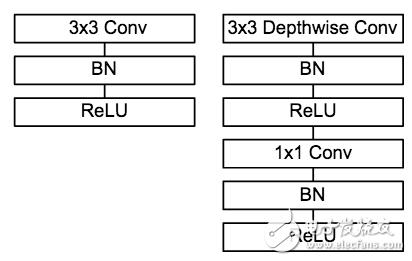
圖9 普通卷積單元與MobileNet 卷積單元對比
MobileNet的卷積單元如上圖所示,每個卷積操作后都接著一個BN操作和ReLU操作。在MobileNet中,由于3x3卷積核只應用在depthwise convolution中,因此95%的計算量都集中在pointwise convolution 中的1x1卷積中。而對于caffe等采用矩陣運算GEMM實現卷積的深度學習框架,1x1卷積無需進行im2col操作,因此可以直接利用矩陣運算加速庫進行快速計算,從而提升了計算效率。
5.3 實驗結果
表7 MobileNet與主流大模型在ImageNet上精度對比
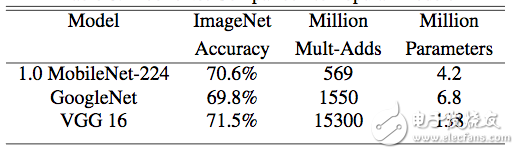
上表顯示,MobileNet在保證精度不變的同時,能夠有效地減少計算操作次數和參數量,使得在移動端實時前向計算成為可能。
六、ShuffleNet
ShuffleNet是Face++今年提出了一篇用于移動端前向部署的網絡架構。ShuffleNet基于MobileNet的group思想,將卷積操作限制到特定的輸入通道。而與之不同的是,ShuffleNet將輸入的group進行打散,從而保證每個卷積核的感受野能夠分散到不同group的輸入中,增加了模型的學習能力。
6.1 設計思想
我們知道,卷積中的group操作能夠大大減少卷積操作的計算次數,而這一改動帶來了速度增益和性能維持在MobileNet等文章中也得到了驗證。然而group操作所帶來的另一個問題是:特定的濾波器僅對特定通道的輸入進行作用,這就阻礙了通道之間的信息流傳遞,group數量越多,可以編碼的信息就越豐富,但每個group的輸入通道數量減少,因此可能造成單個卷積濾波器的退化,在一定程度上削弱了網絡了表達能力。
6.2 網絡架構
在此篇工作中,網絡架構的設計主要有以下幾個創新點:
提出了一個類似于ResNet的BottleNeck單元
借鑒ResNet的旁路分支思想,ShuffleNet也引入了類似的網絡單元。不同的是,在stride=2的單元中,用concat操作代替了add操作,用average pooling代替了1x1stride=2的卷積操作,有效地減少了計算量和參數。單元結構如圖10所示。
提出將1x1卷積采用group操作會得到更好的分類性能
在MobileNet中提過,1x1卷積的操作占據了約95%的計算量,所以作者將1x1也更改為group卷積,使得相比MobileNet的計算量大大減少。
提出了核心的shuffle操作將不同group中的通道進行打散,從而保證不同輸入通道之間的信息傳遞。
ShuffleNet的shuffle操作如圖11所示。
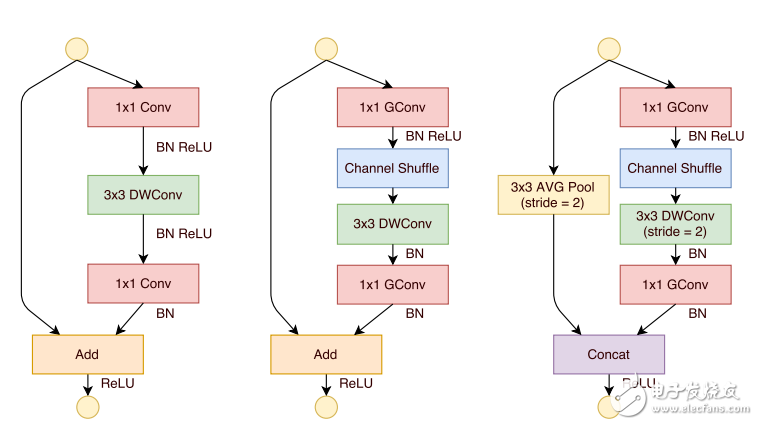
圖10 ShuffleNet網絡單元
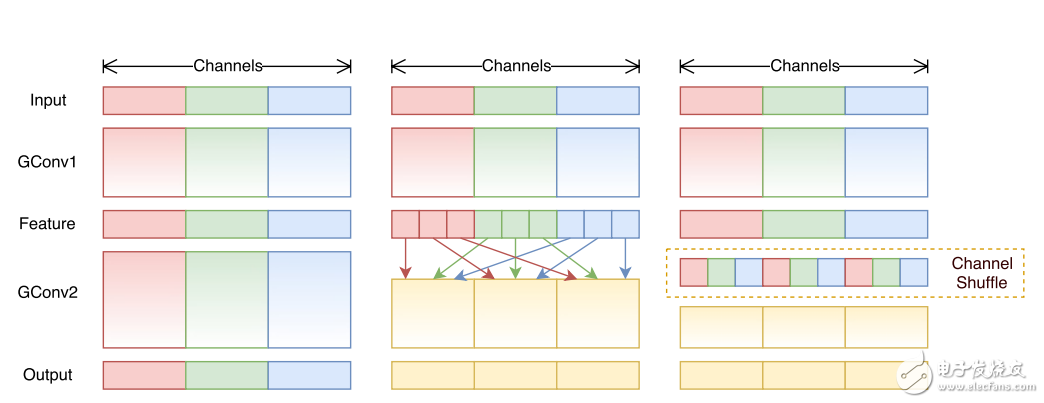
圖11 不同group間的shuffle操作
6.3 實驗結果
表8 ShuffleNet與MobileNet在ImageNet上精度對比
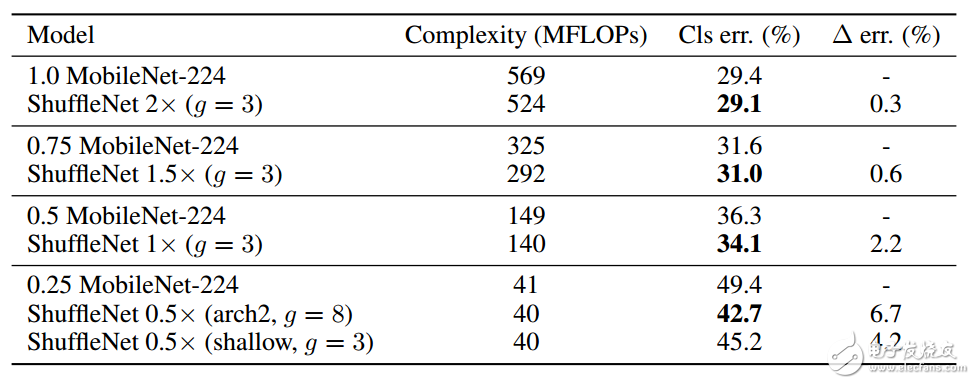
上表顯示,相對于MobileNet,ShuffleNet的前向計算量不僅有效地得到了減少,而且分類錯誤率也有明顯提升,驗證了網絡的可行性。
6.4 速度考量
作者在ARM平臺上對網絡效率進行了驗證,鑒于內存讀取和線程調度等因素,作者發現理論上4x的速度提升對應實際部署中約2.6x。作者給出了與原始AlexNet的速度對比,如下表。
表9 ShuffleNet與AlexNet在ARM平臺上速度對比 [10]

結束語
近幾年來,除了學術界涌現的諸多CNN模型加速工作,工業界各大公司也推出了自己的移動端前向計算框架,如Google的Tensorflow、Facebook的caffe2以及蘋果今年剛推出的CoreML。相信結合不斷迭代優化的網絡架構和不斷發展的硬件計算加速技術,未來深度學習在移動端的部署將不會是一個難題。
參考文獻
[1] ImageNet Classification with Deep Convolutional Neural Networks
[2] Very Deep Convolutional Networks for Large-Scale Image Recognition
[3] Going Deeper with Convolutions
[4] Rethinking the Inception Architecture for Computer Vision
[5] SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size
[6] Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
[7] Distilling the Knowledge in a Neural Network
[8] XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
[9] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
[10] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
[11] Network in Network
[12] EIE: Efficient Inference Engine on Compressed Deep Neural Network













 工商網監
工商網監
評論