 電子發(fā)燒友App
電子發(fā)燒友App


前言
借助移動(dòng)互聯(lián)網(wǎng)技術(shù)、機(jī)器學(xué)習(xí)領(lǐng)域深度學(xué)習(xí)技術(shù)的發(fā)展,以及大數(shù)據(jù)語(yǔ)料的積累,自然語(yǔ)言處理技術(shù)發(fā)生了突飛猛進(jìn)的變化。越來(lái)越多的科技巨頭開(kāi)始看到了這塊潛在的“大蛋糕”中蘊(yùn)藏的價(jià)值,通過(guò)招兵買馬、合作、并購(gòu)的方式、拓展自己在自然語(yǔ)言處理研究領(lǐng)域的業(yè)務(wù)范圍,進(jìn)一步提升自然語(yǔ)言處理在整個(gè)公司中的主導(dǎo)地位。與此同時(shí),也不斷有新興的科技公司涌現(xiàn),提出自己的在智能交互、語(yǔ)音識(shí)別、機(jī)器翻譯等方面的解決方案,試圖在自然語(yǔ)言處理這片廣闊的藍(lán)海上劃分自己的領(lǐng)土、樹(shù)立自己的標(biāo)桿。
人工智能已經(jīng)是大部分普通人都耳熟能詳?shù)脑~匯,而人們對(duì)自然語(yǔ)言處理技術(shù)的了解程度卻大部分還停留在表面階段。本文通過(guò)回顧自然語(yǔ)言處理的發(fā)展歷史,解讀2015年整個(gè)自然語(yǔ)言處理行業(yè)的重大變化,進(jìn)而提出新的時(shí)代下自然語(yǔ)言處理技術(shù)的發(fā)展瓶頸、以及對(duì)于自然語(yǔ)言處理所提出的挑戰(zhàn)、自然語(yǔ)言處理未來(lái)的發(fā)展方向。
一、追本溯源——自然語(yǔ)言處理技術(shù)發(fā)展歷程
自人工智能在1956年達(dá)特茅斯會(huì)議上首次提出,讓機(jī)器完成更多的智力工作成為科學(xué)家努力的方向。其中一個(gè)重要的目標(biāo)就是希望機(jī)器能夠與人類進(jìn)行更加自然高效的交流,希望機(jī)器讀懂人類深?yuàn)W的語(yǔ)言,同時(shí)以一種我們習(xí)慣的方式進(jìn)行交互,而解決這個(gè)問(wèn)題的關(guān)鍵技術(shù)就是自然語(yǔ)言處理。
尤其是近20年來(lái),隨著互聯(lián)網(wǎng)的發(fā)展引發(fā)了對(duì)這一技術(shù)的強(qiáng)勁需求,這一技術(shù)在得到長(zhǎng)足發(fā)展的同時(shí),也在有力地促進(jìn)互聯(lián)網(wǎng)核心能力的增強(qiáng)。比如,目前互聯(lián)網(wǎng)提供的一個(gè)基礎(chǔ)性能力是信息檢索。人們?cè)谒?a target="_blank">索引擎中輸入關(guān)鍵詞,就可以獲得相關(guān)信息。在20年前,互聯(lián)網(wǎng)剛開(kāi)始發(fā)展的初期,給搜索引擎輸入“和服”,返回的結(jié)果中很可能包含不少生產(chǎn)、銷售“鞋子和服裝”的公司的信息。現(xiàn)在這種錯(cuò)誤已經(jīng)比較少了,而促進(jìn)其質(zhì)量不斷提升的一個(gè)核心就是采用了不斷改進(jìn)的自然語(yǔ)言理解技術(shù)。“互聯(lián)網(wǎng)”自然語(yǔ)言理解已經(jīng)成為互聯(lián)網(wǎng)發(fā)展的一個(gè)共識(shí),并在不斷深化。
最近幾年,眾多科技巨頭正在這方面進(jìn)行布局。2013年谷歌以超過(guò)3000萬(wàn)美元收購(gòu)了新聞閱讀應(yīng)用開(kāi)發(fā)商Wavii。Wavii擅長(zhǎng)自然語(yǔ)言處理技術(shù),可以通過(guò)掃描互聯(lián)網(wǎng)發(fā)現(xiàn)新聞,并給出一句話摘要;微軟將自然語(yǔ)言處理技術(shù)應(yīng)用在了智能助手小冰、Cortana上,取得了不錯(cuò)的效果,通過(guò)機(jī)器翻譯使Skype具備了實(shí)時(shí)翻譯功能;自然語(yǔ)言處理技術(shù)是Facebook智能助手M背后的核心技術(shù)之一,其產(chǎn)品負(fù)責(zé)人稱“我們對(duì)M做的事情可以讓我們更好地理解自然語(yǔ)言處理。”國(guó)內(nèi)的科大訊飛在去年年底發(fā)布了自然語(yǔ)言處理云平臺(tái),很早推出語(yǔ)音合成產(chǎn)品,在中文領(lǐng)域的自然語(yǔ)言處理和語(yǔ)音合成方面有著深厚積累。可見(jiàn),早在前幾年,眾多科技巨頭和國(guó)內(nèi)IT廠商就已對(duì)自然語(yǔ)言處理這篇潛在的廣闊市場(chǎng)覬覦已久,紛紛開(kāi)始摩拳擦掌,準(zhǔn)備將自然語(yǔ)言處理技術(shù)向公司的核心業(yè)務(wù)方向進(jìn)行轉(zhuǎn)移,針對(duì)業(yè)務(wù)線轉(zhuǎn)型、新產(chǎn)品提出來(lái)醞釀更大的動(dòng)作。
?
二、自然語(yǔ)言處理技術(shù)發(fā)展歷程——持續(xù)探索 穩(wěn)中前行
2015年是自然語(yǔ)言處理技術(shù)進(jìn)一步發(fā)展的一年。由于自然語(yǔ)言處理的主流技術(shù)主要是以統(tǒng)計(jì)機(jī)器學(xué)習(xí)為基礎(chǔ)的,因此這些技術(shù)的性能就依賴兩個(gè)因素:一是針對(duì)不同任務(wù)的統(tǒng)計(jì)模型和優(yōu)化算法,二是相應(yīng)的大規(guī)模語(yǔ)料庫(kù)。2015年得益于深度學(xué)習(xí)算法的快速進(jìn)展和大規(guī)模社交文本數(shù)據(jù)以及語(yǔ)料數(shù)據(jù)的不斷積累,自然語(yǔ)言處理技術(shù)有了飛躍式的發(fā)展。在這一年,各大廠商致力于解決語(yǔ)音識(shí)別、語(yǔ)義理解、智能交互、搜索優(yōu)化等領(lǐng)域更加復(fù)雜、困難的問(wèn)題,持續(xù)不斷地對(duì)原有產(chǎn)品的算法、模型進(jìn)行優(yōu)化與革新。
在新產(chǎn)品方面,2015年帶給了我們太多的驚喜。高考期間,百度推出了小度機(jī)器人,無(wú)獨(dú)有偶,十月底,Rokid團(tuán)隊(duì)推出的Rokid機(jī)器人也與公眾見(jiàn)面。這些實(shí)體機(jī)器人不僅能用擬人的思維識(shí)別語(yǔ)義,嘗試與用戶建立起更深層、連續(xù)的溝通,還能模仿人的“思考”,先從海量互聯(lián)網(wǎng)內(nèi)容中提取信息,然后按人的思維邏輯對(duì)信息進(jìn)行推理分析和篩選,再得到答案。不僅如此,優(yōu)秀的實(shí)體機(jī)器人還能與智能家居設(shè)備深度融合,并接入音樂(lè)、新聞等內(nèi)容,還能給予攝像頭進(jìn)行手勢(shì)喚醒與遠(yuǎn)場(chǎng)識(shí)別。
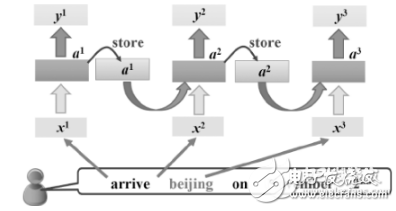
2015年,遠(yuǎn)場(chǎng)語(yǔ)音識(shí)別技術(shù)突破了5米的瓶頸,大幅度改進(jìn)了語(yǔ)音交互的自由度,再次刷新業(yè)界期待。利用麥克風(fēng)陣列、回聲消除等技術(shù)將目標(biāo)說(shuō)話人的聲音增強(qiáng),并抑制/消除噪聲和回聲,由此進(jìn)行語(yǔ)音前端處理;在語(yǔ)音識(shí)別引擎,則針對(duì)麥克風(fēng)陣列處理后的數(shù)據(jù)進(jìn)行收集、訓(xùn)練,以使遠(yuǎn)場(chǎng)效果最優(yōu)化。目前國(guó)內(nèi)集成全新的4麥克風(fēng)陣列方案,利用麥克風(fēng)陣列的空域?yàn)V波特性——在目標(biāo)說(shuō)話人方向形成拾音波束(BeamForming),抑制波束之外的噪聲;結(jié)合獨(dú)特的去混響算法,最大程度的吸收反射聲,達(dá)到去除混響的目的。其中,漢語(yǔ)語(yǔ)音識(shí)別技術(shù)也取得了重大突破:識(shí)別相對(duì)錯(cuò)誤率比現(xiàn)有技術(shù)降低15%以上,使?jié)h語(yǔ)安靜環(huán)境普通話語(yǔ)音識(shí)別的識(shí)別率接近97%。通過(guò)基于多層單向LSTM的漢語(yǔ)聲韻母整體建模技術(shù),成功地把連接時(shí)序分類(CTC)訓(xùn)練技術(shù)嵌入到傳統(tǒng)的語(yǔ)音識(shí)別建模框架中,再結(jié)合語(yǔ)音識(shí)別領(lǐng)域的決策樹(shù)聚類、跨詞解碼和區(qū)分度訓(xùn)練等技術(shù),大幅度提升線上語(yǔ)音識(shí)別產(chǎn)品性能,是一次框架式的創(chuàng)新。2015年,“字根嵌入”的提出,將“字根作為中文語(yǔ)言處置懲罰的最小單位進(jìn)行研究”,機(jī)器在處置懲罰中文分詞、短文本分類及網(wǎng)頁(yè)排序方面的效果大幅提升,可以有效促進(jìn)機(jī)器對(duì)用戶中文表意進(jìn)行深度學(xué)習(xí),讓搜索引擎更加智慧、更“懂“用戶。隨著大數(shù)據(jù)技術(shù)和深度學(xué)習(xí)算法的不斷發(fā)展,2015年,基于數(shù)據(jù)驅(qū)動(dòng)的自然語(yǔ)言對(duì)話系統(tǒng)也為我們打開(kāi)了新的思路:通過(guò)提出Deep Match CNN和Deep Match Tree兩種匹配模型以及Neural Responding Machine(NRM)對(duì)話生成模型,并深入挖掘大規(guī)模對(duì)話數(shù)據(jù),很容易地構(gòu)建一個(gè)自動(dòng)生成對(duì)話系統(tǒng),其準(zhǔn)確率相比傳統(tǒng)的機(jī)器翻譯模型由26%提高到76%,而且對(duì)話十分自然流暢。
2015年,許多廠商也紛紛開(kāi)源了自己用于自然語(yǔ)言處理、機(jī)器學(xué)習(xí)的工具包和技術(shù)專利。Facebook人工智能研究院(FAIR)宣布開(kāi)源了一組深度學(xué)習(xí)工具,這些工具主要是針對(duì)Torch機(jī)器學(xué)習(xí)框架的插件,包括iTorch、fbcunn、fbnn、fbcuda和fblualib。這些插件能夠在很大程度上提升深度學(xué)習(xí)的速度,并可用于計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理等場(chǎng)景。Torch已被Google、Twitter、Intel、AMD、NVIDIA等公司采用。Google、Microsoft和IBM分別發(fā)布并開(kāi)源了自己的機(jī)器學(xué)習(xí)工具包TensorFlow、DMTK和SystemML。Google已將TensorFlow用于GMail(SmartReply)、搜索(RankBrain)、圖片(生成圖像分類模型--Inception Image Classification Model)、翻譯器(字符識(shí)別)等產(chǎn)品。DMTK其功能特點(diǎn)以及定位更傾向于自然語(yǔ)言處理方面,例如文本分類與聚類、話題識(shí)別以及情感分析等。SystemML則是IBM研發(fā)了超過(guò)十年的機(jī)器學(xué)習(xí)技術(shù),沃森(Watson)在幾年前的大型活動(dòng)里就整合了很多SystemML的機(jī)器學(xué)習(xí)功能。語(yǔ)音識(shí)別知名廠商SoundHound.inc年底也開(kāi)放了自己的“Houndify”平臺(tái),通過(guò)與各大傳統(tǒng)行業(yè)廠商深入合作,集成各個(gè)方面的行業(yè)數(shù)據(jù):如與Expedia.com合作,集成酒店、航班方面的語(yǔ)料數(shù)據(jù);與Xignite合作,集成金融市場(chǎng)語(yǔ)料數(shù)據(jù),意在通過(guò)語(yǔ)音“識(shí)別一切”,構(gòu)建更廣闊的識(shí)別平臺(tái)。?
#e#
三、當(dāng)前國(guó)內(nèi)外在自然語(yǔ)言處理領(lǐng)域的研究熱點(diǎn)和難點(diǎn)
自然語(yǔ)言處理的難點(diǎn)
單詞的邊界界定
在口語(yǔ)中,詞與詞之間通常是連貫的,而界定字詞邊界通常使用的辦法是取用能讓給定的上下文最為通順且在文法上無(wú)誤的一種最佳組合。在書(shū)寫(xiě)上,漢語(yǔ)也沒(méi)有詞與詞之間的邊界。
詞義的消歧
許多字詞不單只有一個(gè)意思,因而我們必須選出使句意最為通順的解釋。
句法的模糊性
自然語(yǔ)言的文法通常是模棱兩可的,針對(duì)一個(gè)句子通常可能會(huì)剖析(Parse)出多棵剖析樹(shù)(Parse Tree),而我們必須要仰賴語(yǔ)意及前后文的資訊才能在其中選擇一棵最為適合的剖析樹(shù)。
有瑕疵的或不規(guī)范的輸入
例如語(yǔ)音處理時(shí)遇到外國(guó)口音或地方口音,或者在文本的處理中處理拼寫(xiě),語(yǔ)法或者光學(xué)字符識(shí)別(OCR)的錯(cuò)誤。
語(yǔ)言行為與計(jì)劃
句子常常并不只是字面上的意思;例如,“你能把鹽遞過(guò)來(lái)嗎”,一個(gè)好的回答應(yīng)當(dāng)是把鹽遞過(guò)去;在大多數(shù)上下文環(huán)境中,“能”將是糟糕的回答,雖說(shuō)回答“不”或者“太遠(yuǎn)了我拿不到”也是可以接受的。再者,如果一門(mén)課程去年沒(méi)開(kāi)設(shè),對(duì)于提問(wèn)“這門(mén)課程去年有多少學(xué)生沒(méi)通過(guò)?”回答“去年沒(méi)開(kāi)這門(mén)課”要比回答“沒(méi)人沒(méi)通過(guò)”好。
關(guān)于如何解決語(yǔ)境的問(wèn)題:
同時(shí),由于強(qiáng)調(diào)了“大規(guī)模”,強(qiáng)調(diào)了“真實(shí)文本”,下面兩方面的基礎(chǔ)性工作也得到了重視和加強(qiáng)。
(1)大規(guī)模真實(shí)語(yǔ)料庫(kù)的研制。大規(guī)模的經(jīng)過(guò)不同深度加工的真實(shí)文本的語(yǔ)料庫(kù),是研究自然語(yǔ)言統(tǒng)計(jì)性質(zhì)的基礎(chǔ)。沒(méi)有它們,統(tǒng)計(jì)方法只能是無(wú)源之水。
(2)大規(guī)模、信息豐富的詞典的編制工作。規(guī)模為幾萬(wàn),十幾萬(wàn),甚至幾十萬(wàn)詞,含有豐富的信息(如包含詞的搭配信息)的計(jì)算機(jī)可用詞典對(duì)自然語(yǔ)言處理的重要性是很明顯的。
?
自然語(yǔ)言處理技術(shù)發(fā)展瓶頸
目前自然語(yǔ)言處理技術(shù)的兩大瓶頸就是大規(guī)模語(yǔ)料數(shù)據(jù)的建設(shè),以及語(yǔ)義分析的進(jìn)一步完善。
主流的自然語(yǔ)言處理技術(shù)是以統(tǒng)計(jì)機(jī)器學(xué)習(xí)為基礎(chǔ)的,這就需要大規(guī)模的語(yǔ)料庫(kù)。在很多任務(wù)中,這些語(yǔ)料庫(kù)是需要人工構(gòu)建的,這是非常費(fèi)力的工作。因此,數(shù)據(jù)共享是一個(gè)可以促進(jìn)研究發(fā)展的必不可少的因素。可以說(shuō),自然語(yǔ)言處理的快速發(fā)展離不開(kāi)一些開(kāi)源的語(yǔ)料庫(kù),比如WordNet、PennTreebank等。第二,任何語(yǔ)料庫(kù)無(wú)論大小類型,都難以囊括某個(gè)領(lǐng)域的全部案例;而且,語(yǔ)料庫(kù)的標(biāo)注體系往往難以把握,類別劃分過(guò)粗,則無(wú)法全面、細(xì)致地描述語(yǔ)言,類別劃分過(guò)細(xì),則標(biāo)注信息過(guò)于龐大、降低標(biāo)注效率,統(tǒng)計(jì)數(shù)據(jù)的稀疏問(wèn)題嚴(yán)重,訓(xùn)練出來(lái)的模型健壯性差。第三,因?yàn)槿斯?biāo)注的語(yǔ)料庫(kù)畢竟是費(fèi)時(shí)費(fèi)力的工作,因此還需要從模型和算法方面去研究如何利用大量的無(wú)人工標(biāo)注或部分標(biāo)注的數(shù)據(jù),也就是半監(jiān)督學(xué)習(xí),但這方面的研究還不是特別成熟。
自然語(yǔ)言處理技術(shù)的另一大瓶頸就是如何精確地表現(xiàn)自然語(yǔ)言的語(yǔ)義,比如在人機(jī)交互過(guò)程中,首先就要理解用戶的意圖,而這里“用戶的意圖”就是語(yǔ)義。目前業(yè)界常用的方法有兩種:基于知識(shí)或語(yǔ)義學(xué)規(guī)則的語(yǔ)義分析方法和基于統(tǒng)計(jì)學(xué)的語(yǔ)義分析方法。盡管兩類方法都能在一定程度上進(jìn)行自然語(yǔ)言語(yǔ)義的推導(dǎo)以及信息之間關(guān)聯(lián)的判別,但是基于知識(shí)與語(yǔ)義學(xué)規(guī)則的方法無(wú)法覆蓋全部語(yǔ)言現(xiàn)象、推理過(guò)程復(fù)雜,無(wú)法處理不確定性事件,規(guī)則間的相容性和適用層次范圍存在缺陷和限制,知識(shí)和語(yǔ)義規(guī)則的建立是瓶頸問(wèn)題;而基于統(tǒng)計(jì)學(xué)的方法則過(guò)多地依賴于大規(guī)模語(yǔ)料庫(kù)的支持,性能依賴語(yǔ)料庫(kù)的優(yōu)劣,易受數(shù)據(jù)稀疏和數(shù)據(jù)噪聲的干擾,正如之前提到,大規(guī)模語(yǔ)料庫(kù)的建立和語(yǔ)料質(zhì)量的保證仍是瓶頸問(wèn)題。
可喜的是,如火如荼的云計(jì)算為復(fù)雜模型計(jì)算以及大規(guī)模語(yǔ)料庫(kù)的收集與建立提供了基礎(chǔ)設(shè)施上的支撐。例如,借助Microsoft Azure,用戶可以在幾分鐘內(nèi)完成NLP on Azure站點(diǎn)的部署,并立即開(kāi)始對(duì)NLP開(kāi)源工具的使用,或者以REST API的形式調(diào)用開(kāi)源工具的語(yǔ)言分析功能,而無(wú)需關(guān)注基礎(chǔ)結(jié)構(gòu),只需專注于應(yīng)用程序的業(yè)務(wù)邏輯。PaaS(平臺(tái)即服務(wù))的特性隱藏了基礎(chǔ)設(shè)施的細(xì)節(jié),讓用戶無(wú)須關(guān)心操作系統(tǒng)、運(yùn)行環(huán)境、安全補(bǔ)丁、錯(cuò)誤恢復(fù)等問(wèn)題,這使得用戶進(jìn)行NLP語(yǔ)料庫(kù)建設(shè)以及應(yīng)用程序使用的門(mén)檻大大降低。
#e#
四、自然語(yǔ)言處理技術(shù)——面臨的挑戰(zhàn)
隨著智能硬件技術(shù)與移動(dòng)技術(shù)的蓬勃爆發(fā),自然語(yǔ)言處理技術(shù)的應(yīng)用趨勢(shì)也發(fā)生了變化。一方面用戶要求自然語(yǔ)言處理技術(shù)可以精準(zhǔn)地理解自己的需求,而且直接給出最匹配的答案,而非簡(jiǎn)單地給出Url讓用戶自己去找答案(起碼目前代表業(yè)內(nèi)較高水平的小度機(jī)器人還是這樣做的)。另一方面是需要自然語(yǔ)言處理技術(shù)可以與用戶進(jìn)行對(duì)話式搜索與智能交互,例如針對(duì)“我到哪里可以買到漂亮衣服?”互聯(lián)網(wǎng)針對(duì)衣服款式的定位、價(jià)錢的定位等條件與用戶進(jìn)行對(duì)話與交互,通過(guò)基于自然語(yǔ)言處理技術(shù)的搜索引擎來(lái)步步引導(dǎo)用戶,幫助用戶逐漸發(fā)現(xiàn)自己的真實(shí)需求,進(jìn)而給出最優(yōu)答案。第三方面,需要自然語(yǔ)言處理技術(shù)對(duì)用戶進(jìn)行“畫(huà)像”,提供“主動(dòng)推薦、不問(wèn)即得”的個(gè)性化推薦服務(wù)。由于每個(gè)人各個(gè)方面的生活需求(尤其是娛樂(lè)方面的需求)不盡相同,自然語(yǔ)言處理技術(shù)可以根據(jù)用戶的瀏覽歷史來(lái)挖掘用戶的喜好,進(jìn)而針對(duì)用戶的喜好進(jìn)行精準(zhǔn)式推薦。
在這樣的需求下面,對(duì)于自然語(yǔ)言處理技術(shù)的未來(lái)發(fā)展提出了很大的挑戰(zhàn)。它要求未來(lái)的自然語(yǔ)言處理技術(shù)能夠做到:
· 1、需求識(shí)別。通過(guò)用戶提出了多種多樣的、復(fù)雜的、基于情感式的、語(yǔ)意模糊的需求進(jìn)行深刻分析,精確地理解用戶的需求。
· 2、知識(shí)挖掘。經(jīng)過(guò)海量的網(wǎng)絡(luò)數(shù)據(jù)與知識(shí)的挖掘分析,將各種結(jié)構(gòu)化、非結(jié)構(gòu)化、半結(jié)構(gòu)化的知識(shí)進(jìn)行組織與梳理,最終以結(jié)構(gòu)化、清晰化的知識(shí)形式完整地呈現(xiàn)給用戶。
· 3、用戶引導(dǎo)。這與對(duì)話式智能交互相關(guān),不僅根據(jù)用戶的需求來(lái)提供“建議”,還能“猜測(cè)”用戶可能會(huì)有什么未想到、未提出的需求,從而“先人一步”為用戶提供相關(guān)的擴(kuò)展信息。
· 4、結(jié)果組織和展現(xiàn)。由于用戶更加青睞直接的答案,答案的形式可以是唯一答案、聚合答案、圖片、多媒體的形式,這就要求自然語(yǔ)言處理技術(shù)能夠?qū)⑼诰虺龅男畔⑦M(jìn)行有效地組織與整理,以條理化、簡(jiǎn)潔化、直接化的形式呈現(xiàn)給用戶。?
五、自然語(yǔ)言處理技術(shù)——展望未來(lái)
在電影《Her》里,語(yǔ)音交互成為普遍的交互方式:孤獨(dú)的作家西奧多,有語(yǔ)音操控的隨身計(jì)算設(shè)備,用語(yǔ)音撰寫(xiě)感人的書(shū)信安撫受傷人,還找到了“機(jī)器人女友”莎曼薩。我想,擁有一個(gè)貼心的“莎曼薩”,能做到“知我心、懂我意”,仿佛看到第二個(gè)自己,應(yīng)該是很多人都會(huì)憧憬的事情。
展望2018年,自然語(yǔ)言處理技術(shù)還將沿著致力于實(shí)現(xiàn)智能化、人性化的搜索推薦、語(yǔ)音交互、語(yǔ)義理解的道路繼續(xù)前行。相信不僅會(huì)有更多技術(shù)難題被攻克,也會(huì)有越來(lái)越多類似于“莎曼薩”的產(chǎn)品問(wèn)世。
隨著大數(shù)據(jù)技術(shù)的不斷發(fā)展,大規(guī)模語(yǔ)料樣本數(shù)據(jù)以驚人的數(shù)量不斷積累以及自然語(yǔ)言處理在深度學(xué)習(xí)方面的不斷深耕,目前業(yè)界已經(jīng)開(kāi)始使用上萬(wàn)小時(shí)的樣本進(jìn)行模型訓(xùn)練。不難預(yù)測(cè),不久,自然語(yǔ)言處理技術(shù)發(fā)展將很快進(jìn)入10萬(wàn)小時(shí)數(shù)據(jù)樣本訓(xùn)練階段,只有這樣,才能覆蓋千差萬(wàn)別的用戶口音差異、多領(lǐng)域歧義語(yǔ)料數(shù)據(jù)以及復(fù)雜的語(yǔ)法規(guī)則。再考慮環(huán)境變化的影響,未來(lái)訓(xùn)練語(yǔ)料量可能會(huì)突破100萬(wàn)小時(shí)。未來(lái),基于統(tǒng)計(jì)學(xué)的語(yǔ)義分析方法研究將會(huì)繼續(xù)深化,會(huì)隨著大規(guī)模語(yǔ)料樣本數(shù)據(jù)的不斷積累以及大數(shù)據(jù)挖掘技術(shù)、深度模型算法的不斷發(fā)展呈現(xiàn)質(zhì)的飛躍。
隨著訓(xùn)練數(shù)據(jù)量的迅速增加,如何實(shí)現(xiàn)大規(guī)模LSTM(長(zhǎng)短時(shí)記憶模型)建模和CTC(連接時(shí)序分類)的有效訓(xùn)練,會(huì)成為一個(gè)核心的技術(shù)難題。未來(lái)語(yǔ)音識(shí)別領(lǐng)域的深度學(xué)習(xí)將進(jìn)入數(shù)百GPU并行訓(xùn)練的狀態(tài),理論創(chuàng)新和算法技術(shù)創(chuàng)新都將圍繞大數(shù)據(jù)展開(kāi)。語(yǔ)音識(shí)別技術(shù)的研發(fā)方法,相對(duì)于現(xiàn)在必將發(fā)生深刻的變革。此外,CTC建模技術(shù)進(jìn)一步降低了語(yǔ)音識(shí)別應(yīng)用的解碼成本,隨著適合深度模型計(jì)算的專業(yè)硬件的大量涌現(xiàn),語(yǔ)音識(shí)別云服務(wù)的成本將大量降低,從而推動(dòng)語(yǔ)言處理與語(yǔ)音交互技術(shù)的更大范圍的普及。
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論