 電子發燒友App
電子發燒友App


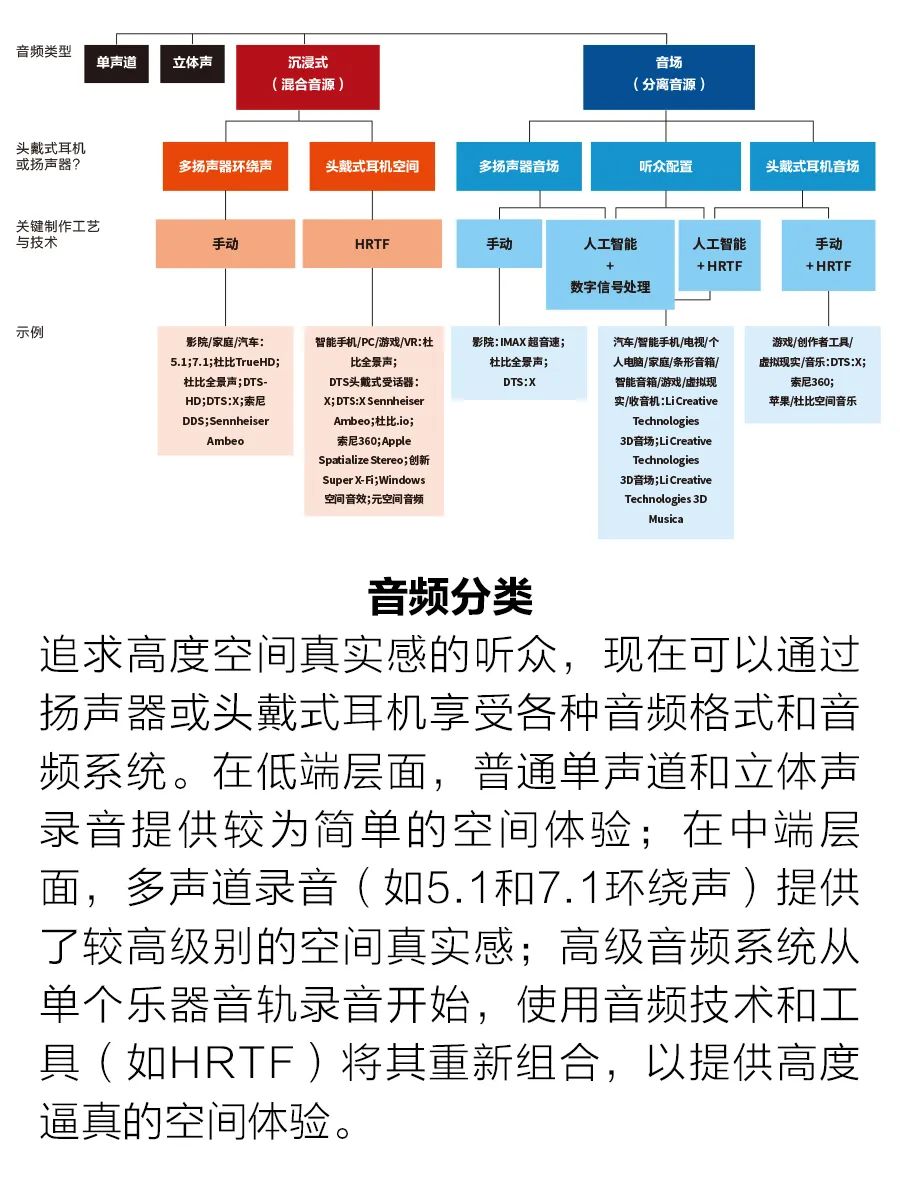
如今到處都可以聽到錄制的聲音,我們幾乎不會刻意想到它們。這些聲音從智能手機、智能音箱、電視、收音機、光盤播放機和汽車音響系統傾瀉而出,持久而愉快地出現在我們的生活中。2017年,尼爾森市場調研公司的一項調查顯示,約90%的美國人經常聽音樂,每周平均聽32個小時。?在這自由流暢的愉悅背后,龐大的產業推動技術實現長遠的目標:最大可能真實地再現聲音。從19世紀80年代愛迪生的留聲機和喇叭揚聲器開始,一代又一代工程師追求這一理想,發明和開發了無數項技術:真空三極管、電動式揚聲器、盒式磁帶留聲機、數十種不同拓撲結構的固態放大器電路、靜電揚聲器、光盤、立體聲音響和環繞立體聲音響。在過去的50年里,音頻壓縮和流媒體等數字技術改變了音樂產業。

? 然而,即使是現在,經過150年的發展,我們從高端音頻系統中聽到的聲音,也遠遠不及音樂表演現場聽到的聲音。在這樣的演出現場,我們處于一個自然的聲場中,可以很容易地感覺到來自不同位置、不同樂器的聲音,即使聲場有多種樂器的混合聲音交織在一起。人們支付大價錢去現場聽音樂是有原因的:現場音樂更令人愉悅、更令人興奮,并且可以產生更大的情緒感染力。?如今,研究人員、公司和企業家,包括我們公司,終于接近實現真實重建聲場進而記錄音頻的目標了。其中包括蘋果和索尼這樣的大公司,以及Creative這樣的小公司。奈飛最近披露了與Sennheiser的合作,在網絡中開始使用一種新系統,即Ambeo 2-Channel Spatial Audio,提高《怪奇物語》和《巫師》等電視劇的聲音真實感。 目前,至少有6種不同的方法可以制作高逼真的音頻(見插圖“音頻分類”)。我們使用術語“音場”(soundstage)來區別我們的成果與其他音頻格式,例如空間音頻或沉浸式音頻。與普通立體聲相比,這些音頻可以呈現出更多的空間效果,但它們通常不包含再現真正令人信服的聲場所需的詳細音源位置提示。 我們相信,音場是音樂錄制和再現的未來。但在這場大規模革命發生之前,我們必須克服一個巨大的障礙:如何方便、廉價地轉換現有不計其數的錄音,無論它們是單聲道、立體聲還是多通路環繞聲(5.1、7.1等)。沒有人確切地知道錄制了多少首歌曲,但根據Gracenote的娛樂元數據,目前地球上有超過2億首錄制歌曲。考慮到一首歌曲的平均時長約為3分鐘,這相當于音樂時長約為1100年。 音樂的數量是龐大的。任何推廣一種新音頻格式(無論它是多么有前途)的嘗試都注定要失敗,除非它包含一種技術,使我們能夠輕松、方便地收聽所有這些現有音頻,就像我們現在在家里、海灘上、火車上或汽車內聽立體聲音樂一樣。?
我們已經開發了這樣一種技術,稱為3D音場。該系統可在智能手機、普通或智能音箱、頭戴式耳機、耳塞、筆記本電腦、電視、條形音箱和車內播放音場音樂。它不僅可以將單聲道和立體聲錄音轉換為音場,還允許未經特殊訓練的聽眾根據自己的喜好,使用圖形用戶界面重新配置聲場(sound field)。例如,聽眾可以指定每個樂器和聲樂源的位置,并調整各自的音量,改變相對音量,例如伴奏樂器與人聲樂的對比。該系統在這里應用了人工智能(AI)、虛擬現實和數字信號處理(稍后將詳細介紹)。
?
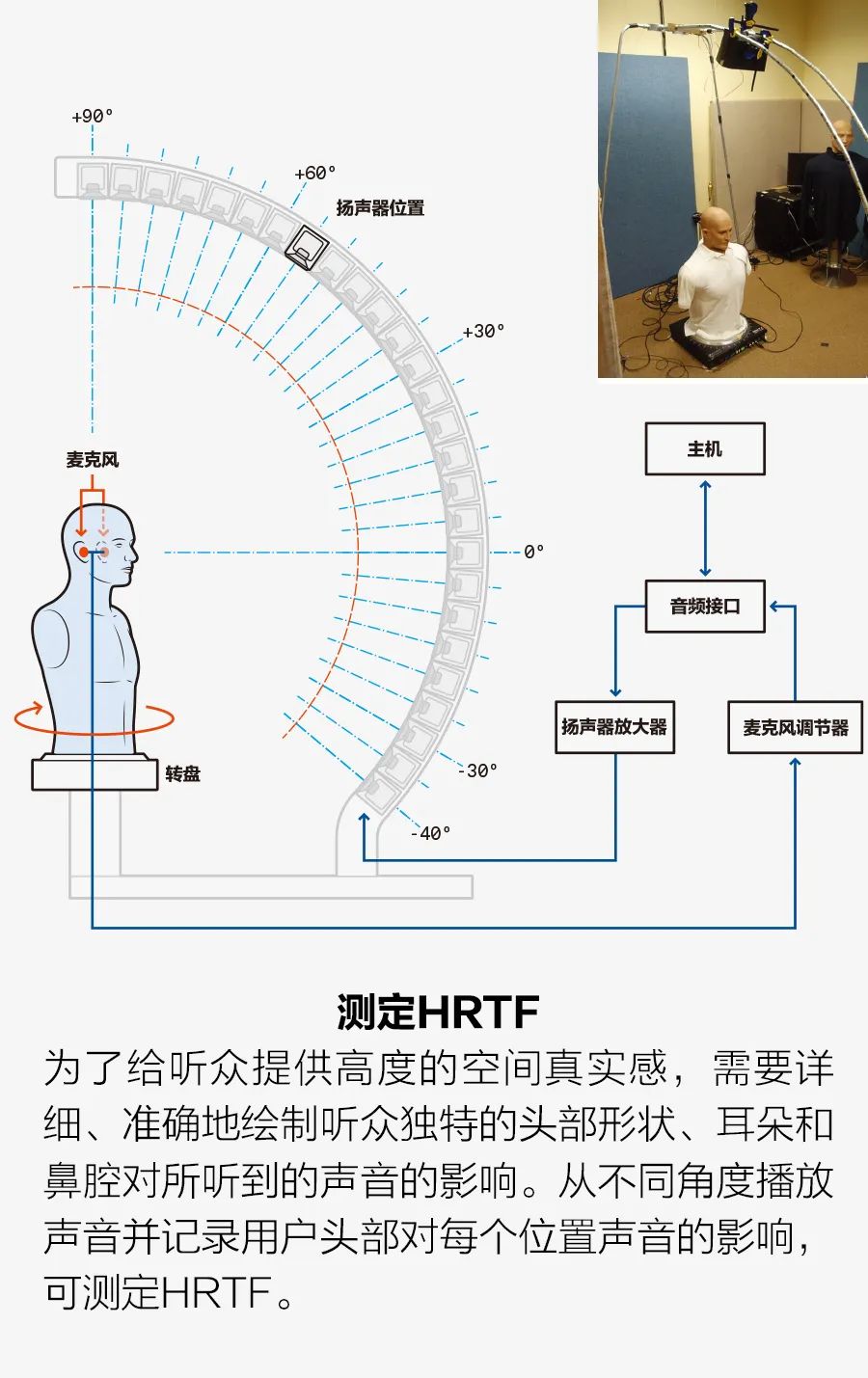
要用兩個小揚聲器(比如一副頭戴式耳機)令人信服地再現弦樂四重奏等聲音,需要大量的技術技巧。要了解這是如何做到的,還要從感知聲音的方式說起。 當聲音傳到耳朵時,你頭部的特征,包括物理形狀、外耳和內耳的形狀,甚至是鼻腔的形狀等,都會改變原始聲音的音頻頻譜。此外,一個聲源傳送到兩只耳朵的時間也有非常細微的差別。通過這種頻譜變化和時間差,大腦可以感知聲源的位置。頻譜變化和時間差可以根據頭部相關傳遞函數(HRTF)進行數學建模。在頭部周圍三維空間的每個點都有一對HRTF,一個用于左耳,另一個用于右耳(見插圖“測定HRTF”)。 因此,使用一對HRTF來處理一段給定的音頻,一個用于右耳,另一個用于左耳。為了重現最初的體驗,我們需要考慮聲源相對于錄制麥克風的位置。然后播放處理過的音頻,例如通過一副頭戴式耳機,聽眾將聽到音頻中帶有原始提示,感覺到聲音來自最初錄制的方向。 如果沒有原始位置信息,我們可以簡單地指定每個音源的位置,并獲得基本相同的體驗。聽眾不太可能注意到表演者位置的細微變化,事實上,他們可能更喜歡自己的配置。 許多商業化的應用程序都使用HRTF為使用頭戴式耳機和耳塞的聽眾創建空間音響。蘋果公司的Spa-tialize Stereo就是一個例子。這項技術將HRTF應用于播放音頻,令人感受到空間音效,即比普通立體聲更逼真的更深層次的聲場。蘋果公司還提供了一個頭部追蹤器版本,使用iPhone和AirPods上的傳感器跟蹤頭部(AirPods)和iPhone之間的相對方向。然后,使用與iPhone方向相關聯的HRTF生成空間音頻,使人感覺是自己聽到的是來自iPhone的聲音。這不是我們所說的音場音頻,因為樂器的聲音仍然混合在一起。例如,你感覺不到小提琴手在中提琴手左邊。

? 不過蘋果公司確實有一款產品試圖提供音場音頻:蘋果Spatial Audio。我們認為,與普通立體聲相比,這是一個顯著的改進,但仍然有一些問題需要解決。首先,它結合了杜比全景聲,這是杜比實驗室開發的一種環繞聲技術。Spatial Audio使用一組HRTF為頭戴式耳機及耳塞創建空間音頻。但是,采用杜比全景聲意味著,要使用這項技術,所有現有立體聲音樂必須重新灌錄,而重新灌錄數百萬單聲道和立體聲歌曲幾乎是不可能的。Spatial Audio的另一個問題是,它只支持頭戴式耳機或耳塞,而不支持揚聲器。因此,那些喜歡在家里和車里聽音樂的人無法獲益。 ?
?
那么我們的系統是如何實現逼真的音場音頻的呢?我們首先使用機器學習軟件將音頻分解成多個單獨的音軌,每個音軌代表一種或一組樂器/歌手。這種分離過程稱為混音(upmixing)。一個制作人,甚至是未經特殊訓練的聽眾都可以將多個音軌重新組合,重建和個性化所需的聲場。
? 假設要處理的是一首四重奏,音樂由吉他、貝司、鼓和人聲組成,聽眾可以根據個人喜好決定表演者的位置并調整音量;可以使用觸摸屏安排聲源和聽眾在聲場的虛擬位置,實現滿意的配置效果。圖形用戶界面顯示一個舞臺的形狀,上面覆蓋著指示音源的圖標,包括人聲、鼓、貝司、吉他等。中間有一個頭部圖標,表示聽眾的位置。聽眾可以根據自己的喜好,觸摸并拖動頭部圖標來更改聲場。 將頭部圖標靠近鼓時,鼓聲會更突出。如果聽眾將頭部圖標移動到表示一個樂器或一位歌手的圖標,聽眾將聽到表演者的獨奏(唱)。重點是允許聽眾重新配置聲場,3D音場為音樂欣賞增加了新維度(如有不當,請多包涵)。 如果你想通過頭戴式耳機或普通的左右聲道系統收聽音頻,轉換后的音場音頻可以有兩個聲道;如果你想在多揚聲器系統上播放,它還可以是多聲道的。在后一種情況下,可以由2個、4個或更多揚聲器創建音場。重建聲場中不同音源的數量甚至可能大于揚聲器的數量。 這種多聲道方法與普通的5.1和7.1環繞聲道不同。5.1和7.1環繞聲道通常有5或7個單獨的頻道,每個頻道都有一個揚聲器,外加一個低音炮(即數字5和7后的“.1”)。多揚聲器創建的聲場比標準的雙揚聲器立體聲設備更具沉浸感,但它們仍達不到真正的音場錄制所能帶來的真實感。當通過此多聲道設備播放時,我們的3D音場錄音會繞過5.1、7.1或任何其他特殊音頻格式,包括多音軌音頻壓縮標準格式。
? 簡單介紹一下這些標準格式。為了更好地處理數據,改進環繞聲和沉浸式音頻應用,最近一系列新標準推出,包括沉浸式空間音頻的空間音頻對象編碼(SAOC)和MPEG-H 3D音頻標準。這些新標準繼承了幾十年前開發的各種多聲道音頻格式及其相應的編碼算法,如杜比數碼環繞聲AC-3和DTS。 在開發新標準格式時,專家必須考慮到人們的各種要求和期望的功能。人們想要與音樂互動,例如改變不同樂器組合的相對音量。他們想要不同的多媒體流、不同的網絡、不同的揚聲器配置。空間音頻對象編碼的設計考慮了這些功能,允許高效存儲和傳輸音頻文件,同時保留了聽眾根據個人喜好調整混音的可能性。 但是,要實現這一點,要依賴于各種標準化編碼技術。空間音頻對象編碼需要通過編碼器來創建文件。編碼器的輸入是一批包含音軌的數據文件;每個音軌文件表示一個或多個樂器。編碼器基本上使用標準化技術來壓縮數據文件。在播放過程中,音頻系統中的解碼器對文件進行解碼,然后通過數模轉換器將這些文件轉換成多聲道模擬聲音信號。 我們的3D音場技術繞過了這一點,使用單聲道、立體聲或多聲道音頻數據文件作為輸入。我們將這些文件或數據流劃分為多個分立音源的音軌,然后根據聽眾偏好的配置,將這些音軌轉換為雙聲道或多聲道輸出,驅動多個揚聲器或頭戴式耳機。我們使用人工智能技術避免多聲道重錄、編碼和解碼。

?
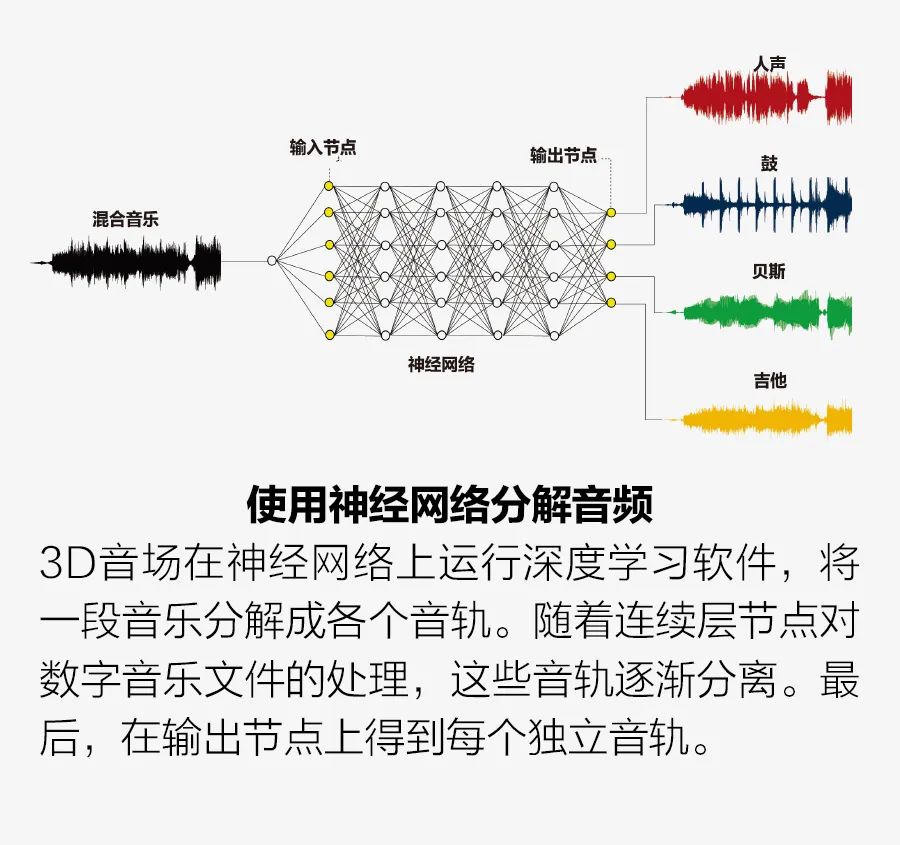
事實上,我們在開發3D音場系統時面臨的最大的技術挑戰是編寫機器學習軟件,將傳統的單聲道、立體聲或多聲道錄音實時分離(或混合)成多個獨立的音軌。該軟件在神經網絡上運行。我們于2012年開發了這種音樂分離方法,并在2022年和2015年獲得的專利(美國專利號:11240621 B2和9131305 B2)中進行了描述。 典型的過程包括兩個部分:訓練和混合。在訓練過程中,大量的混音歌曲及其獨立的樂器和聲樂音軌,分別用作神經網絡的輸入和目標輸出。訓練過程中使用機器學習來優化神經網絡參數,使神經網絡的輸出(樂器和聲樂的單個音軌數據的集合)與目標輸出相匹配。 神經網絡是非常松散的人腦模型。它有一個輸入節點層,代表生物神經元,接著是許多中間層,稱為“隱藏層”。最后是一個顯示最終結果的輸出層。在我們的系統中,輸入節點的數據為混合音軌的數據。當這些數據通過隱藏層節點進行處理時,每個節點計算生成加權值的總和(見插圖“使用神經網絡分解音頻”)。然后對總和進行非線性數學運算。此計算確定是否以及如何將來自此節點的音頻數據傳遞到下一層的節點。 這樣的層有幾十個。隨著音頻數據從一層傳輸到另一層,各個樂器逐漸相互分離。最后,在輸出層中,每個獨立的音軌被輸出到輸出層中的一個節點。 不過,在訓練神經網絡時,輸出可能會偏離目標。例如,它可能不是一個獨立樂器的音軌,或它可能包含兩種樂器的音頻成分。在這種情況下,將調整權重方案中的單個權重,確定數據如何從隱藏節點傳輸到隱藏節點,然后再次運行訓練。這種迭代訓練和持續調整會一直繼續,直到輸出與目標輸出接近完美地匹配為止。 與機器學習的任何訓練數據集一樣,可用的訓練樣本越多,最終的訓練效果越好。我們需要數萬首歌曲及其單獨樂器音軌來進行訓練,總訓練音樂數據集為數千小時。 在神經網絡經過訓練后,輸入一首混音歌曲,經過訓練建立的系統神經網絡運行,輸出多個獨立的音軌。
?
將一段錄音分解成音軌成分之后,下一步是將它們重新混合成一段音場錄音。這是由音場信號處理器完成的。音場處理器執行復雜的計算功能,生成驅動揚聲器的輸出信號,產生音場音頻。發生器的輸入包括獨立音軌、揚聲器的物理位置以及重建聲場中的聽眾和音源的期望位置。音場處理器的輸出是一個多音軌信號,每個聲道一個,用于驅動多個揚聲器。 如果聲場是由揚聲器產生的,它可以位于物理空間中;如果聲場是由頭戴式耳機或耳塞產生的,它也可以位于虛擬空間中。音場處理器的功能基于計算聲學和心理聲學實現,考慮了在期望聲場中聲波的傳播和干擾,以及聽眾的HRTF和期望聲場。 例如,如果聽眾想要使用耳機,生成器將根據期望音源位置的配置選擇一組HRTF,然后使用所選的HRTF過濾獨立的音源音軌。最后,音場處理器組合所有的HRTF輸出,為耳機生成左右音軌。如果聽眾想在揚聲器上播放音樂,至少需要使用兩個揚聲器,揚聲器越多,聲場越好。重建聲場中的音源數量可以多于或少于揚聲器的數量。
? 我們于2020年推出了第一個支持iPhone的音場應用程序3D Musica。它允許聽眾實時配置、收聽和保存音樂,處理過程不會造成可感覺的時間延遲。3D Musica可以將聽眾個人音樂庫、云端甚至流媒體音樂中的立體聲音樂實時轉換為音場音樂。(對于卡拉OK錄音,該應用程序可以刪除人聲或輸出任一單獨樂器。) 2022年早些時候,我們開設了門戶網站3dsoundstage.com,提供云端3D Musica應用程序的所有功能,以及應用程序編程接口(API),因此流媒體音樂提供商,甚至任何流行網頁瀏覽器的用戶都可以使用這些功能。現在,基本上任何人都可用任何設備聽音場音頻的音樂。 我們還為車輛和家庭音頻系統和設備開發了不同版本的3D音場軟件,可用2個、4個或更多揚聲器重建3D聲場。除了音樂播放,我們希望視頻會議中也能應用這項技術。我們許多人都體驗過參加視頻會議的疲憊。參加視頻會議時,我們很難清楚地聽到其他與會者的聲音,還可能搞不清是誰在講話。而應用音場,你可以配置音頻,聽到每個人的聲音來自虛擬房間的不同位置,“位置”指派可簡單地按照參會者在Zoom和其他視頻會議應用程序中的網格位置。這樣一來,至少對一些人來說,視頻會議不會太累,講話也更容易聽清楚。
?
正如音頻從單聲道到立體聲,從立體聲到環繞聲和空間音頻一樣,它現在也開始走向音場。在早期,發燒友評估音響系統的保真度根據的是帶寬、諧波失真、數據分辨率、響應時間、無損或有損數據壓縮,以及其他與信號相關的參數。現在,音場可以看成是聲音保真度的另一個維度,我們甚至敢說,這是最基本的維度。對于人耳而言,相比不斷改善諧波失真,有空間提示、具備扣人心弦的即時性的音樂所帶來的影響更為顯著。這是錄制音頻第一次在與保真度相關外,還考慮到了心理聲學和更廣泛的大腦活動。這個非凡特性提供的體驗甚至超過了許多財力雄厚的音響發燒友的體驗。 技術推動了音頻產業的前幾次革命,現在它正在掀起另一場革命。人工智能、虛擬現實和數字信號處理正在利用心理聲學為音頻愛好者提供前所未有的體驗。同時,這些技術為唱片公司和藝術家提供了新的工具,為舊唱片注入了新的活力,并開辟了創作的新途徑。令人信服地重現音樂廳音響的百年目標終于實現。?
作者:Qi “Peter” Li、Yin Ding、Jorel Olan
編輯:黃飛













 工商網監
工商網監
評論