OpenStack數(shù)據(jù)庫服務(wù)與Trove的介紹
大小:0.4 MB 人氣: 2017-10-11 需要積分:1
對比Amazon AWS中各種關(guān)于數(shù)據(jù)的服務(wù),其中最著名的是RDS(SQL-base)和DynamoDB(NoSQL),除了實現(xiàn)了基本的數(shù)據(jù)管理能力,還具備良好的伸縮能力、容災(zāi)能力和不同規(guī)格的性能表現(xiàn)。因此,對于最炙手可熱的開源云計算平臺Openstack來說,也從Icehouse版加入了DBaaS服務(wù),代號Trove。直到去年底發(fā)布的Openstack Liberty版本,Trove已經(jīng)經(jīng)過了4個版本的迭代發(fā)布,目前已經(jīng)成為Openstack官方可選的核心服務(wù)之一。本文將深入介紹Trove的原理、架構(gòu)與功能,并通過實踐來展示Trove的應(yīng)用。
Trove的設(shè)計目標
“Trove is Database as a Service for OpenStack. It’s designed to run entirely on OpenStack, with the goal of allowing users to quickly and easily utilize the features of a relational or non-relational database without the burden of handling complex administrative tasks. ”這是Trove在官方首頁上對這個項目的說明,有兩個關(guān)鍵點。一個是從產(chǎn)品設(shè)計上說,它定位不僅僅是關(guān)系型數(shù)據(jù)庫,而且還涵蓋非關(guān)系數(shù)據(jù)庫的服務(wù)。另一個是從產(chǎn)品實現(xiàn)上說,它是完全基于Openstack的。
從第一點可以看出Trove解決問題的高度已經(jīng)超越了同類產(chǎn)品。因為我們從其他云計算平臺對比去看,關(guān)系型和非關(guān)系型數(shù)據(jù)庫都是由不同的服務(wù)去提供(比如AWS的RDS和DynamoDB),而且實現(xiàn)上也往往互相獨立的系統(tǒng),不僅UI不同,API也不一樣。而Trove的目標是抽象盡可能多的東西,對外提供統(tǒng)一的UI和API,盡量減少冗余實現(xiàn),提升平臺內(nèi)聚。只要具備了實例、數(shù)據(jù)庫、用戶、配置、備份、集群、主從復(fù)制這些概念,不管是關(guān)系型還是非關(guān)系型數(shù)據(jù)庫,都能統(tǒng)一管理起來。從最新的Liberty版本發(fā)布的情況下,目前開源的主流關(guān)系型和非關(guān)系型數(shù)據(jù)庫也得到了支持,比如Mysql(包括Percona和MariaDB分支)、Postgresql、Redis、MongoDB、CouchDB、Cassandra等等。不過根據(jù)官方的介紹,目前只有Mysql是得到了充分的生產(chǎn)性測試,其他的還處于實驗性階段。
而第二點完全基于Openstack的,可以說是一個較大的創(chuàng)新。試想,假設(shè)你是一個云計算服務(wù)商,如果現(xiàn)在要提供數(shù)據(jù)庫服務(wù),只需要在原有平臺軟件上升級與配置一下就行,其他什么都不需要,不需要采購數(shù)據(jù)庫服務(wù)器硬件,不需要規(guī)劃網(wǎng)絡(luò),不需要規(guī)劃IDC,這是一種什么樣的感覺?Trove完全構(gòu)建于Openstack原有的幾大基礎(chǔ)服務(wù)之上。打個比喻類似于Google著名的Bigtable服務(wù)是構(gòu)建于GFS、Borg、Chubby等幾個基礎(chǔ)服務(wù)之上。所以,Trove實際上擁有了云平臺的一些基礎(chǔ)特性,比如容災(zāi)隔離、動態(tài)調(diào)度、快速響應(yīng)等能力,而且從研發(fā)的角度看,也大大減少了重復(fù)造輪子的現(xiàn)象。
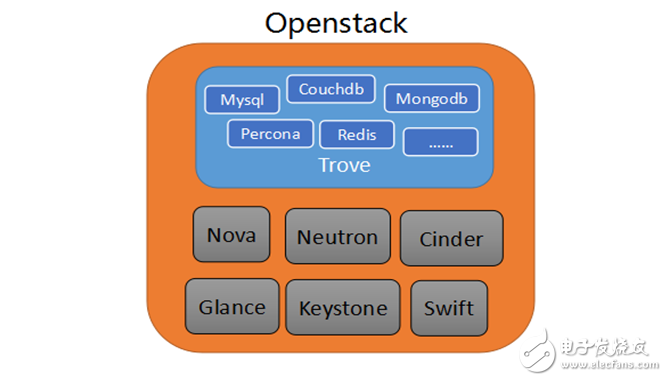
Trove的架構(gòu)介紹
實際上Trove的架構(gòu)(最新版本)與Openstack Nova項目的架構(gòu)是如出一轍,可以說是Nova的一個簡化版。也是典型的Openstack項目架構(gòu)風格。Trove所管理的各個數(shù)據(jù)庫引擎的差異性主要體現(xiàn)在trove-guestagent的具體manager和strategies代碼實現(xiàn)上。架構(gòu)如圖所示:
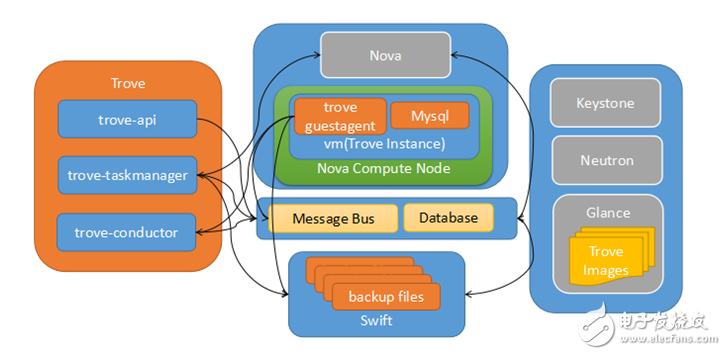
trove-api是接入層,輕量級請求通過在接入層直接處理或者通過直接訪問guestagent處理,比如獲取實例列表、獲取實例規(guī)格列表等;而比較重的請求則通過message bus(Openstack默認實現(xiàn)是Rabbitmq)中轉(zhuǎn)給trove-taskmanager進行調(diào)度處理。trove-taskmanager是調(diào)度處理層,主要是處理較重的請求,比如創(chuàng)建實例、實例resize等。
taskmanager會通過Nova、Swift的API訪問Openstack基礎(chǔ)的服務(wù),而且是有狀態(tài)的,是整個系統(tǒng)的核心。trove-conductor是guestagent訪問數(shù)據(jù)庫的代理層,主要是為了屏蔽掉guestagent直接對數(shù)據(jù)庫的訪問。
在Trove目前的實現(xiàn)中,一個數(shù)據(jù)庫實例一一對映到一個vm,而guestagent也是運行在vm里面。vm鏡像包含了經(jīng)過裁剪的操作系統(tǒng)、數(shù)據(jù)庫引擎和guestagent(鏡像具體實現(xiàn)沒有標準,數(shù)據(jù)庫引擎和guestagent也都可以在vm啟動時通過網(wǎng)絡(luò)動態(tài)裝載)。而實例所在分區(qū)的硬盤是通過Cinder提供的云硬盤。每個vm都會關(guān)聯(lián)一個安全組防火墻,只允許數(shù)據(jù)庫服務(wù)的端口通過(比如Mysql,默認是TCP 3306端口)。從這里可以看出,Trove創(chuàng)建數(shù)據(jù)庫實例是非常靈活的,后期的調(diào)度也非常方便,這些都得益于Nova和Cinder。
Trove功能介紹
正如前面說的,實際上Trove是在主流的關(guān)系和非關(guān)系型數(shù)據(jù)庫的一些核心概念基礎(chǔ)上抽象出的一個系統(tǒng)框架,所以其實現(xiàn)的功能也是圍繞著這些核心概念的。Trove的概念關(guān)系圖:
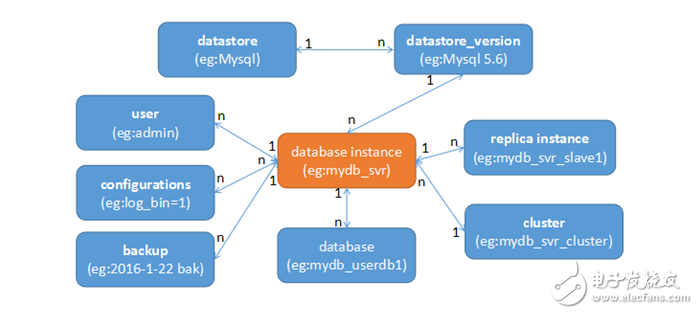
因此Trove的主要功能也是圍繞這幾個概念實現(xiàn)的。datastore管理,Instance管理,configuration管理,database管理,user管理,replication管理,backup管理,cluster管理等等。
從最新的Liberty版本看,目前Trove的功能還是比較多的,而且擴展性很強。可惜的是實例統(tǒng)計監(jiān)控功能卻沒有看到,而統(tǒng)計監(jiān)控功能的缺失,應(yīng)該也是導(dǎo)致了實例容災(zāi)的自動切換還沒有實現(xiàn),相信這些都會在不久的新版本中逐漸完善。不過從另外一個角度看,由于數(shù)據(jù)庫對用戶來說是非常關(guān)鍵的服務(wù),涉及到核心數(shù)據(jù)的數(shù)據(jù)一致性問題,目前交由用戶上層去確認和切換實例也不失一個明智的選擇。下面以Mysql數(shù)據(jù)庫作為例子,對Trove的一些重要功能進行分析。
非常好我支持^.^
(0) 0%
不好我反對
(0) 0%
下載地址
OpenStack數(shù)據(jù)庫服務(wù)與Trove的介紹下載
相關(guān)電子資料下載
- JetBrains發(fā)布獨立Rust IDE:RustRover 399
- Openstack網(wǎng)絡(luò)模型場景及代碼解析 161
- 2023年了,OpenStack仍是第三大開源項目 849
- 圖數(shù)據(jù)庫驅(qū)動的基礎(chǔ)設(shè)施運維代碼編程案例 83
- openEuler資源利用率提升之道:虛擬機混部OpenStack調(diào)度 398
- 使用Ansible的OpenStack自動化 501
- 中國OpenStack往事回望 449
- openEuler社區(qū)鄧一諾:實踐是探索和提升的最佳捷徑 663
- 后OpenStack時代的Kubernetes 398
- NestOS實例創(chuàng)建與配置 517