 電子發燒友App
電子發燒友App


最近幾年存儲介質得到了高速發展,單位存儲介質的性能越來越高,從原來的機械硬盤不足 100 IOPS 到現在的 NVMe SSD 一塊就能達到 50W IOPS,但與之形成反差的是 CPU 的速度提升并沒有那么多,根據 Red Hat 的相關數據統計,存儲介質由原來的單盤幾十 IOPS 到現在的單盤 50 萬 IOPS,但是 CPU 的主頻增長的速度相對并沒有那么快,而不同的存儲介質每個 IO 需要的 CPU 時鐘周期也各不相同,如在 HDD 中一個 IO 需要 2000 萬時鐘周期,在 NMVE 設備中只需要 6000 時鐘周期。

▲圖表及數據均來源于Red Hat
With a cpu clocked at 3ghz you can afford:
HDD: ~20 million cycles/IO
SSD: 300,000 cycles/IO
NVMe: 6000 cycles/IO
在這樣的背景下,對于存儲軟件來說能否發揮出存儲介質的高性能,其關鍵是如何高效利用 CPU,其中,單核 CPU 能夠提供的 IOPS,是存儲系統的一個關鍵指標。
而分布式存儲作為當前存儲系統的一個重要分支,其軟件定義的特征,能夠更好更快地適配新硬件的發展,成為了存儲領域的熱點。
我們先簡單地聊聊分布式存儲中開源領域在適配新硬件的進展,而說到開源的分布式存儲,我們一定會想到明星開源項目 Ceph,它在國內外都被廣泛使用,其良好的擴展性和穩定性也獲得大家一致認可。
在 Ceph 的迭代發展中,其本地存儲引擎 ObjectStore 也經過了兩代的發展,由最初的 FileStore,到現在廣泛使用的 BlueStore,但是這些存儲引擎對于高性能的存儲介質(如 NVMe SSD 等)都存在一定的不足。
所以 Ceph 社區也在 2018 年提出了新一代本地存儲引擎 SeaStore,對細節感興趣的讀者可以訪問 https://docs.ceph.com/docs/master/dev/seastore/。
下面筆者根據個人的理解對 SeaStore 的設計做一個簡單解讀。
SeaStore 的設計目標
面向NVMe 設計,不考慮 PEME 和 HDD。
使用SPDK 實現用戶態 IO。
使用Seastar 框架進行基于 future&promise 的編程方式實現 run-to-completion。
結合Seastar 的網絡消息層實現讀寫路徑上的零(最小)拷貝。
對于目標 1、2,面向 NVMe 的設計,筆者認為主要是指當前的 NVMe 設備是可以使用用戶態驅動的,即可以不通過系統內核,使用 Polling 模型能夠明顯降低 IO 延時。
同時對于 NVMe 設備來說,由于其 erase-before-write 特性帶來的 GC 問題需要被高效解決,理論上通過 discard 作為一種 hint 機制可以讓上層軟件啟發底層閃存去安排 GC,但實際上大部分閃存設備的 discard 實現的并不理想,因此需要上層軟件的介入。
對于目標 3、4,是從如何降低 CPU 的角度去考慮底層存儲設計的,如上文中也提到對于高性能的分布式存儲,CPU 會成為系統瓶頸,如何提高 CPU 的有效使用率是一個重點考慮的問題。
目標 3 中采用 run-to-completion 的方式能夠避免線程切換和鎖的開銷,從而有效提高 CPU 的使用率,Intel 曾經發布報告說明,在 Block Size 為 4KB 的情況下,單線程利用 SPDK 能夠提供高達 1039 萬 IOPS,充分說明了使用單線程異步編程的方式能夠有效提升 CPU 的使用率。
而目標 4 則需要充分結合網絡模型,一致性協議等,實現零拷貝,來降低在模塊中內存拷貝次數。
基于 SeaStore 的設計目標,具體的設計方案中主要考慮了通過 segment 的數據布局來實現的 NMVE 設備的 GC 優化,以及上層如果控制 GC 時的相關處理,同時在文檔中也提到了用 B-tree 的方式實現元數據的存儲,而沒有采用類似 bluestore 中使用 RocksDB 來存儲元數據的方式。
但是筆者認為,這個設計對于實現的難度可能比較高,當前的 rados 不僅僅是存儲數據還有大量的元數據存儲的功能。如 OMAP 和 XATTR,這些小的 KV 信息實際如果采用新寫一個 B-tree 的方式進行存儲,那相當于需要實現一個專有的小型 KV 數據庫,這個功能實現難度會非常大,而類似直接使用簡單的 B-tree 存儲元數據就會落入類型 XFS 等文件系統存儲元數據的困境,不能存儲大量 xattr 的問題。
上文中只是簡單的描述的 Ceph 對下一代存儲引擎的設計構思,如果想等到具體的開源來實現估計還需要個 3 到 5 年的開發周期。
而我們對高性能分布式存儲的需求又非常熱切,所以深信服存儲團隊就獨立設計了一個全新的存儲引擎來滿足高性能分布式存儲的需求。
下面我們簡單介紹深信服企業級分布式存儲 EDS 團隊在高性能本地存儲的實踐之路。
PFStore 設計與實現
PFStore(Phoenix Fast Store)是 EDS 團隊自研的基于 SPDK 的用戶態本地存儲引擎,它的核心架構如下圖所示。
在系統中主要有數據管理和元數據管理兩大核心模塊,下面介紹一下兩大核心模塊的職責和技術特點:
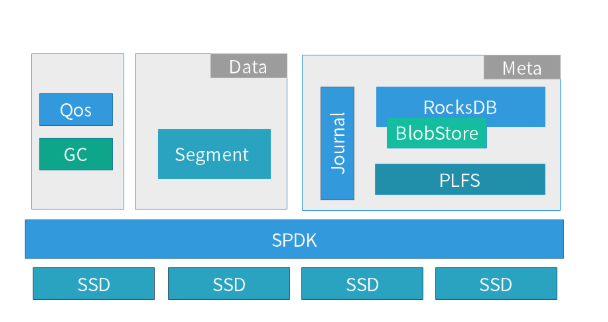
數據管理模塊職責:
它是一個 segment 空間管理的基礎單元,所有的數據都是以追加寫入的,即底層的 SSD 都是順序寫入的,這樣能夠盡可能發揮每塊 SSD 的性能,降低 SSD 本身 GC 帶來的開銷。
同時整個 store 的系統都是基于 SPDK 的中 spdk_thread 編程模型實現的,整個 IO 過程全部在一個獨立線程中完成,所以不會有線程切換和鎖的開銷。
當然全異步的編程方式會導致開發的難度比較高,所以我們研發內部也提煉了一套基于狀態機的異步編程方式,在各個子系統都采用一個子狀態機,這樣既保證了系統的高性能,也保證了系統的可維護性和可擴展性。
元數據管理模塊職責:
對于元數據的存儲,我們借鑒了 Ceph 中 BlueStore 的 Rocksdb 方式,也是采用一個簡化的用戶態文件系統 PLFS 來對接 Rocksdb。
而采用這樣的方式,也是因為我們重點考查了 LSM 和 B-tree 的存儲結構的不同及能夠帶來的收益,對于存儲引擎中頻繁的數據寫入,相對簡潔的元數據管理(本地存儲引擎提供的對象存儲接口,元數據層次是平鋪的),采用 LSM 有利于提升系統寫性能。
下面分別介紹一下本地存儲引擎的技術特點。
元數據引擎技術特點:
使用自研 Journal,替換 RocksDB 的 WAL,這樣元數據的修改都是增量地寫入到 Journal 中,在后期定時刷盤時才寫入到 RocksDB 中。 這個改進是基于下面幾點方面的原因: a) PLStore 是全異步的編程模型,而 RocksDB 的接口是同步的,會阻塞整個 IO 路徑,性能比較差。 b) Journal 的數據是增量更新的,這樣能夠實現聚合的方式寫入,降低元數據寫入次數。 c) Journal 不僅僅記錄了 Object 的元數據更新,還承載了分布式一致性協議中的 LOG 功能(類似 Ceph 中的 PGLOG),而多個功能融合能夠減少數據的寫入次數。
改進 RocksDB 的 compact 處理,在數據聚合時在內存中建立一個基于 B-tree 的位置索引,這樣在 RocksDB 的數據讀取時,可以直接通過索引獲得數據的位置信息,然后利用位置信息直接通過異步的數據讀取口。 這樣就將原有的 RocksDB 同步讀接口改造成了異步,能夠明顯地提升單線程下的讀取能力,通過實測有 5-8 倍的提升。
數據存儲引擎技術特點:
對于數據使用追加寫的方式,更加有利于發揮每塊 SSD 性能,能夠實現更加豐富的數據邏輯空間管理,為存儲的一些高級特性,如快照、克隆、壓縮重刪的實現提供基礎。
與此同時,使得我們需要在 store 層實現空間回收(GC),而空間回收的設計對提升追加寫的存儲系統性能和穩定性至關重要。
在 PLStore 中我們使用數據分層管理的方式來減少在進行空間回收時對底層 SSD 對性能和壽命的影響。
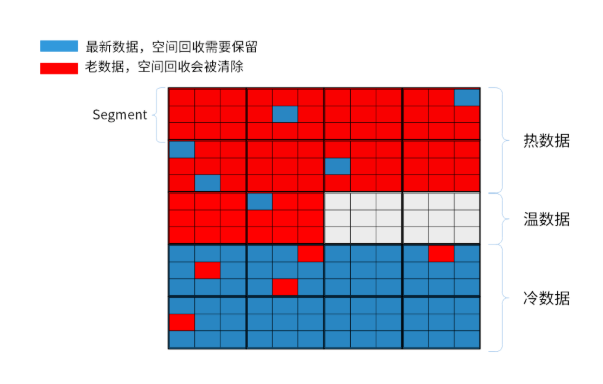
如上圖所示,我們將數據分為 3 個層次:
熱數據 ,經常被更新的數據,并且被集中存放在 SSD zone1 的數據區中
溫數據 ,被更新次數較少的數據,被集中存放在 SSD zone2 的數據區中
冷數據 ,最少被更新的數據,被集中存放在 SSD zone3 的數據區中
其中 zone 由多個 segment 構成,通過數據的分層管理,能夠實現在空間回收時將需要被回收的數據集中存放,這樣在執行空間回收的過程搬動的數據量較少,在空間回收時對正常業務的性能影響較小。同時在執行空間回收的過程中需要回寫的數據量較少,能夠有效的較低空間回收對 SSD 壽命的影響。
在進行數據分區管理后,空間回收是以 segment 為執行單位,可以通過靈活的空間回收的策略選擇代價較小(需要搬動數據較少)的 segment 進行空間回收,這種空間回收過程對上層業務的性能影響較小,而且配合 SSD 中 discard 指令,還能夠降低對 SSD 的壽命的影響。
在空間回收的處理時,PFStore 同時會配合其 Qos 模塊,選擇合適的時機進行空間回收,從各個方向降低對正常業務的影響,避免分布式系統中出現性能抖動和“毛刺”。
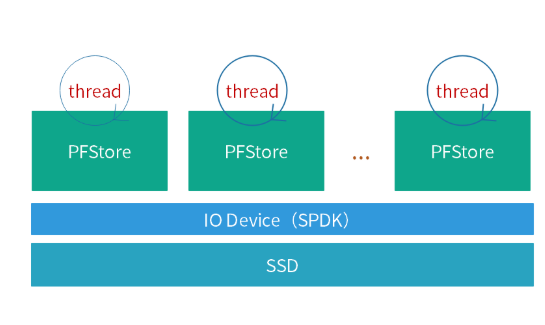
PFStore 只在一個線程中運行,采用 run-to-completion 的編程模型,這樣既簡化了系統,也消除了系統的性能抖動。但在實際中一個 CPU 的 core 并不能完全發揮出一塊 NVMe SSD 的全部性能,所以我們在一個進程中啟動多個獨立線程,每個獨立線程綁定一個 PFStore,而不同的 PFStore 分別管理不同的 SSD 的物理空間,如下圖所示。
總結
對于一個分布式系統而言,本地存儲引擎只是一個基礎組件,需要與其他模塊,如一致性協議,網絡傳輸等模塊相互配合才能發揮其價值。Ceph 社區在 2018 年提出 Seastore 草案后,在 2019 年又重新提出了新的 OSD(Crimson)來滿足高性能應用場景的需求。感興趣的同學可以閱讀 Crimson:A New Ceph OSD for the Age of Persistent Memory and Fast NVMe Storage 的相關內容。
最近幾年存儲領域有著非常大的進展,硬件領域中非易失性內存、SCM 等技術的逐步成熟與落地,NVMe-OF 等協議逐漸被各個操作系統所支持,同時學術界也出現很多好的 Idea,這些都促進了分布式存儲的軟件革新和高速發展。
深信服 EDS 團隊未來的重點也將放在改進軟件架構來更好適配硬件,從而提升系統整體的性價比。



























 工商網監
工商網監
評論