 電子發燒友App
電子發燒友App


在處理小型數據集和簡單算法時,傳統的機器學習模型可以存儲在獨立機器或本地硬盤驅動器上。然而,隨著深度學習的發展,團隊在處理更大的數據集和更復雜的算法時越來越多地遇到存儲瓶頸。
這凸顯了分布式存儲在人工智能(AI)領域的重要性。JuiceFS 是一個開源、高性能的分布式文件系統,為這個問題提供了解決方案。
在本文中,我們將討論 AI 團隊面臨的挑戰,JuiceFS 如何加速模型訓練,以及加速模型訓練的常見策略。
AI 團隊經常遇到以下挑戰:
大型數據集:隨著數據和模型大小的增長,獨立存儲無法滿足應用程序需求。因此,分布式存儲解決方案成為解決這些問題的必要條件。
完整存檔歷史數據集:在某些情況下,每天都會生成大量新數據集,并且必須作為歷史數據存檔。這在自動駕駛領域尤其重要,因為道路測試車輛收集的數據(如雷達和攝像頭數據)是公司的寶貴資產。在這些情況下,獨立存儲被證明是不夠的,因此分布式存儲成為必要的考慮因素。
小文件和非結構化數據過多:傳統的分布式文件系統難以管理大量小文件,導致元數據存儲負擔沉重。這對于視覺模型尤其成問題。為了解決這個問題,我們需要一個針對存儲小文件進行優化的分布式存儲系統。這確保了高效的上層訓練任務和大量小文件的輕松管理。
用于培訓框架的 POSIX 接口:在模型開發的初始階段,算法科學家通常依靠本地資源進行研究和數據訪問。但是,當擴展到分布式存儲以滿足更大的訓練需求時,原始代碼通常需要最少的修改。因此,分布式存儲系統應支持 POSIX 接口,以最大程度地兼容在本地環境中開發的代碼。
共享公共數據集和數據隔離:在某些領域,例如計算機視覺,權威的公共數據集需要在公司內的不同團隊之間共享。為了促進團隊之間的數據共享,這些數據集通常集成并存儲在共享存儲解決方案中,以避免不必要的數據重復和冗余。
基于云的訓練中的數據 I/O 效率低:基于云的模型訓練通常使用對象存儲作為存儲-計算分離架構的基礎存儲。但是,對象存儲的讀寫性能不佳可能會導致訓練期間出現重大瓶頸。
JuiceFS 如何幫助提高模型訓練效率
什么是果汁FS?
JuiceFS 是一個開源、云原生的分布式文件系統,兼容 POSIX、HDFS 和 S3 API。JuiceFS 采用解耦架構,將元數據存儲在元數據引擎中,并將文件數據上傳到對象存儲,提供高性價比、高彈性的存儲解決方案。
JuiceFS 的用戶遍布 20 多個國家,包括人工智能、互聯網、汽車、電信、金融科技等行業的龍頭企業。
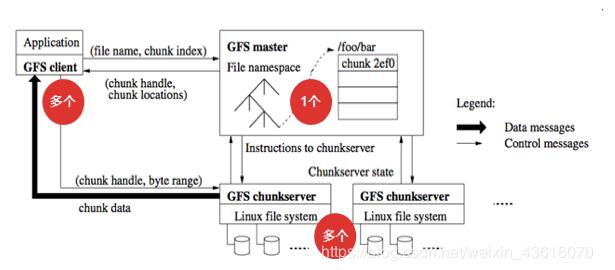
模型訓練場景中 JuiceFS 的架構。
JuiceFS 在模型訓練場景中的架構由三個組件組成:
元數據引擎:任何數據庫,如 Redis 或 MySQL,都可以用作元數據引擎。用戶可以根據自己的需求做出選擇。
對象存儲:您可以使用公有云或自托管提供的任何受支持的對象存儲服務。
果汁FS客戶端:要像訪問本地硬盤一樣訪問 JuiceFS 文件系統,用戶需要將其掛載在每個 GPU 和計算節點上。
底層存儲依賴于對象存儲中的原始數據,每個計算節點都有一些本地緩存,包括元數據和數據緩存。
JuiceFS 設計允許在每個計算節點上多級本地緩存:
第一級:基于內存的緩存
第二級:基于磁盤的緩存
對象存儲僅在緩存滲透時訪問。
對于獨立模型,在第一輪訓練中,訓練集或數據集通常不會命中緩存。但是,從第二輪開始,有了足夠的緩存資源,幾乎不需要訪問對象存儲。這可以加速數據 I/O。
JuiceFS 中的讀寫緩存流程
我們之前比較了使用或不使用緩存來訓練訪問對象存儲時的效率。結果表明,JuiceFS 的元數據緩存和數據緩存,與對象存儲相比,平均性能提升了 4 倍以上,性能提升了近 7 倍。
下圖顯示了在 JuiceFS 中讀寫緩存的過程:
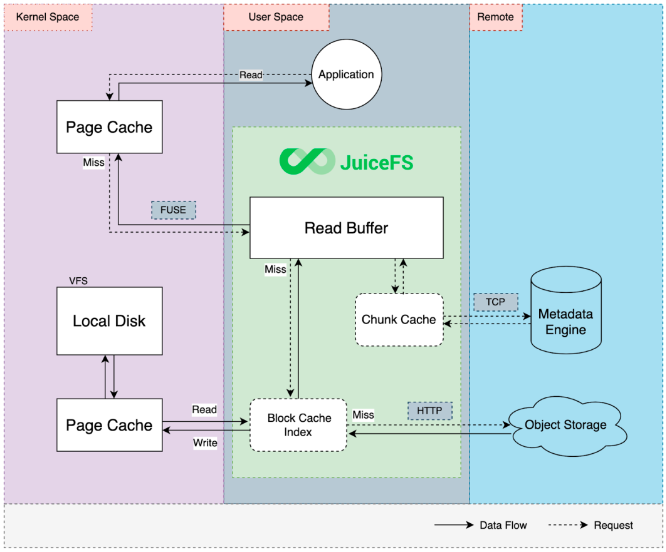
JuiceFS 的讀寫緩存流程
對于上圖中的“塊緩存”,塊是 JuiceFS 中的一個邏輯概念。每個文件分為多個 64 MB 的塊,以提高大文件的讀取性能。這些信息緩存在 JuiceFS 進程的內存中,以加速元數據訪問效率。
JuiceFS 中的讀緩存流程:
1. 應用程序(可以是 AI 模型訓練應用程序,也可以是任何啟動讀取請求的應用程序)發送請求。
2. 請求進入左側的內核空間。內核檢查請求的數據在內核頁面緩存中是否可用。如果沒有,請求會回到用戶空間中的 JuiceFS 進程,該進程處理所有讀寫請求。
默認情況下,JuiceFS 在內存中維護一個讀取緩沖區。當請求無法從緩沖區檢索數據時,JuiceFS 會訪問塊緩存索引,這是一個基于本地磁盤的緩存目錄。JuiceFS 將文件劃分為 4 MB 塊進行存儲,因此緩存粒度也是 4 MB。
例如,當客戶端訪問文件的一部分時,它僅將與該部分數據對應的 4 MB 塊緩存到本地緩存目錄,而不是整個文件。這是 JuiceFS 與其他文件系統或緩存系統的顯著區別。
3. 塊緩存索引在本地緩存目錄中快速定位文件塊。如果找到文件塊,JuiceFS 會從本地磁盤讀取,進入內核空間,并將數據返回給 JuiceFS 進程,再將數據返回給應用。
4. 讀取本地磁盤數據后,也會緩存在內核頁面緩存中。這是因為如果不使用直接 I/O,Linux 系統會默認將數據存儲在內核頁面緩存中。內核頁面緩存可加快緩存訪問速度。如果第一個請求命中并返回數據,則請求不會通過用戶空間 (FUSE) 層中的文件系統進入用戶空間進程。如果沒有,JuiceFS 客戶端會通過緩存目錄來獲取這些數據。如果在本地找不到,則會將網絡請求發送到對象存儲,然后提取數據并將其返回到應用程序。
5. 當 JuiceFS 從對象存儲下載數據時,數據會異步寫入本地緩存目錄。這可確保下次訪問同一塊時,可以在本地緩存中命中該塊,而無需再次從對象存儲中檢索它。
與數據緩存不同,元數據緩存時間更短。為了確保強一致性,默認情況下不緩存 Open 操作。考慮到元數據流量較低,其對整體 I/O 性能的影響很小。但是,在小文件密集型場景中,元數據的開銷也占據了一定的比例。
為什么AI模型訓練太慢?
當你使用 JuiceFS 進行模型訓練時,性能是你應該考慮的關鍵因素,因為它直接影響訓練過程的速度。有幾個因素可能會影響 JuiceFS 的培訓效率:
元數據引擎
元數據引擎(如 Redis、TiKV 或 MySQL)的選擇會在處理小文件時顯著影響性能。一般來說,Redis 比其他數據庫快 3-5 倍。如果元數據請求速度較慢,請嘗試使用更快的數據庫作為元數據引擎。
對象存儲
對象存儲會影響數據存儲訪問的性能和吞吐量。公有云對象存儲服務提供穩定的性能。如果您使用自建對象存儲(例如 Ceph 或 MinIO),則可以優化組件以提高性能和吞吐量。
本地磁盤
緩存目錄存儲的位置對整體讀取性能有重大影響。在高緩存命中率的情況下,緩存磁盤的 I/O 效率會影響整體 I/O 效率。因此,您必須考慮存儲類型、存儲介質、磁盤容量和數據集大小等因素。
網絡帶寬
第一輪訓練后,如果數據集不足以在本地完全緩存,網絡帶寬或資源消耗會影響數據訪問效率。在云中,不同的機器型號具有不同的網卡帶寬。這也會影響數據訪問速度和效率。
內存大小
內存大小會影響內核頁緩存的大小。當有足夠的內存時,剩余的可用內存可以作為 JuiceFS 的數據緩存。這可以進一步加快數據訪問速度。
但是,當可用內存很少時,您需要通過本地磁盤獲取數據訪問權限。這會導致訪問開銷增加。此外,在內核模式和用戶模式之間切換會影響性能,例如系統調用的上下文切換開銷。
如何排查 JuiceFS 中的問題
JuiceFS 提供了許多工具來優化性能和診斷問題。
工具#1:命令juicefs profile
您可以運行該命令來分析訪問日志以進行性能優化。掛載每個文件系統后,都會生成訪問日志。但是,訪問日志不會實時保存,僅在查看時顯示。juicefs profile
與查看原始訪問日志相比,該命令聚合信息并執行滑動窗口數據統計信息,按響應時間從高到低對請求進行排序。這有助于您專注于響應時間較慢的請求,進一步分析請求與元數據引擎或對象存儲之間的關系。juicefs profile
工具#2:命令juicefs stats
該命令從宏觀角度收集監視數據并實時顯示。它監控當前掛載點的 CPU 使用率、內存使用率、內存中的緩沖區使用率、FUSE 讀/寫請求、元數據請求和對象存儲延遲。通過這些詳細的監控指標,可以輕松查看和分析模型訓練期間的潛在瓶頸或性能問題。juicefs stats
其他工具
JuiceFS 還提供了 CPU 和堆分析的性能分析工具:
CPU 分析工具分析了 JuiceFS 進程執行速度的瓶頸,適合熟悉源代碼的用戶。
堆分析工具會分析內存使用情況,尤其是在 JuiceFS 進程占用大量內存時。有必要使用堆分析工具來確定哪些函數或數據結構消耗了大量內存。
加速AI模型訓練的常用方法
元數據緩存優化
您可以通過兩種方式優化元數據緩存,如下所示。
調整內核元數據緩存的超時
參數 、 和對應于不同類型的元數據:--attr-cache--entry-cache--dir-entry-cache
attr表示文件屬性,例如大小、修改時間和訪問時間。
entry表示 Linux 中的文件和相關屬性。
dir-entry表示目錄及其包含的文件。
這些參數分別控制元數據緩存的超時。
為了保證數據的一致性,這些參數的默認超時值僅為1秒。在模型訓練場景中,不會修改原始數據。因此,可以將這些參數的超時時間延長到幾天甚至一周。請注意,元數據緩存無法主動失效,只能在超時期限到期后刷新。
優化 JuiceFS 客戶端的用戶級元數據緩存
打開文件時,元數據引擎通常會檢索最新的文件屬性以確保強一致性。但是,由于通常不會修改模型訓練數據,因此可以啟用該參數,并且可以設置超時以避免每次打開同一文件時重復訪問元數據引擎。
此外,該參數控制緩存文件的最大數量。默認值為 10,000,這意味著最近打開的 10,000 個文件的元數據最多將緩存在內存中。可以根據數據集中的文件數調整此值。
數據緩存優化
JuiceFS 數據緩存包括內核頁面緩存和本地數據緩存:
內核頁面緩存不能通過參數調整。因此,在計算節點上預留足夠的空閑內存,以便 JuiceFS 能夠充分利用它。如果計算節點上的資源緊張,JuiceFS 不會在內核中緩存數據。
本地數據緩存可由用戶控制,緩存參數可根據具體場景進行調整。
調整緩存大小,默認值為 100 GB,這足以滿足大多數方案的需求。但是,對于占用特別大的存儲空間的數據集,需要適當調整緩存大小。否則 100 GB 的緩存空間可能會很快被填滿,使得 JuiceFS 無法緩存更多數據。
另一個可以與之一起使用的參數是 。它確定緩存磁盤上的可用空間量。默認值為 0.1,它允許將最多 90% 的磁盤空間用于緩存數據。
JuiceFS 也支持同時使用多個緩存盤。建議盡可能使用所有可用磁盤。數據將通過輪詢均勻分布到多個磁盤,實現負載均衡,最大化多個磁盤的存儲優勢。
緩存預熱
為了提高訓練效率,您可以使用緩存預熱來加速訓練任務。JuiceFS 支持在客戶端預熱元數據緩存和本地數據緩存。該命令會提前構建緩存,以便在訓練任務開始時緩存可用,從而提高效率。
增加緩沖區大小
緩沖區大小也會影響讀取性能。默認情況下,緩沖區大小為 300 MB。但在高通量訓練場景中,這可能還不夠。您可以根據訓練節點的內存資源調整緩沖區大小。
一般來說,緩沖區大小越大,讀取性能越好。但不要將值設置得太大,尤其是在最大內存有限的容器環境中。有必要根據實際工作負載設置緩沖區大小,并找到一個相對合理的值。可以使用本文前面介紹的命令實時監視緩沖區使用情況。
審核編輯:郭婷
























 工商網監
工商網監
評論