 關于華為AI芯片的性能分析和介紹
關于華為AI芯片的性能分析和介紹
日前,華為公布了其最新的AI芯片戰略,并正式推出了基于達芬奇架構設計的的云端和邊緣端的AI芯片。作為國內ICT產業、集成電路領域的一個重要角色,華為的這次公布,讓行業內的人沸騰了。甚至出現了華為將在云端AI芯片領域干掉英偉達、谷歌,在邊緣端會對這個領域的AI芯片初創者或者老玩家帶來滅頂之災。但華為真的有那么強大的影響力嗎?我們來看一下本文作者對華為戰略和整個市場影響力的分析。
近日,華為在聯接大會2018發布了其全棧全場景AI解決方案,涵蓋了從終端到云端,從AI芯片到深度學習訓練部署框架的多層解決方案,其在AI領域投入的決心可謂巨大。然而,如果仔細分析其具體落地,我們會發現華為的戰略特別實用主義,并沒有去刻意追求技術上的精致,而是快速做了一個能滿足需求的框架,以求先占領市場再做迭代。本文將著重對華為的AI芯片戰略做一分析,并加入一些華為AI芯片對整個產業影響的個人觀點。
多戰場全覆蓋:華為的雄心壯志
華為在本次大會上公布了其AI戰略,涉及的產品無論是深度還是廣度都是非常驚人的。首先,從深度來說,其AI相關產品生態包含了從應用接口ModelArt(用于客戶的應用直接接入AI功能),中層深度學習軟件框架MindSpore,軟硬件接口層CANN,直到專用硬件Ascend系列,最終可以為終端和云端的應用賦能。
華為的AI戰線之深可謂是全球一流,僅有Google、百度等技術導向明顯的互聯網公司可以與之匹敵(Google擁有最流行的深度學習框架TensorFlow和芯片TPU,百度則擁有深度學習框架PaddlePaddle和芯片XPU),而諸如微軟、亞馬遜、騰訊等其他云服務領域廠商的戰線深度,尤其是在硬件領域的投入決心,都遠遠不及華為。

華為的戰線如此之深,究其原因無外乎是“有縱深才能有壁壘”。
對于華為這樣的巨頭公司而言,只有把握住了生態鏈上的每一個環節,把開發者和用戶的整個使用循環全部保留在自己的生態圈內,才能形成真正的壁壘,否則只要在任何環節存在空白或者弱項,就有被競爭對手或者新興公司單點突破的機會。而這樣的壁壘一旦形成,不僅僅可以完成對于競爭對手的防御,更可以在整體生態上獲得極高的利潤——由于完整技術棧的不可替代性,從而可以收獲大量利潤。Nvidia就是把自己凡是能接觸到的生態環節都打通并做到極致的公司,從而產生了極高的壁壘:硬件上有GPU,深度學習框架和軟硬件接口層有CuDNN和TensorRT,因此在這幾年深度學習人工智能高速發展中,Nvidia幾乎占據了不可替代的地位。
然而,Nvidia人工智能生態中的底層硬件GPU卻存在破綻,由于GPU對于人工智能算法的支持并非完美,因此造成了計算效率不高,也引得群雄逐鹿,眾多公司紛紛進入人工智能芯片的戰場。從這個角度來看華為正在做挑戰Nvidia的事情,借著Nvidia GPU做人工智能效率低的弱點,希望構建自主的技術生態來取而代之。
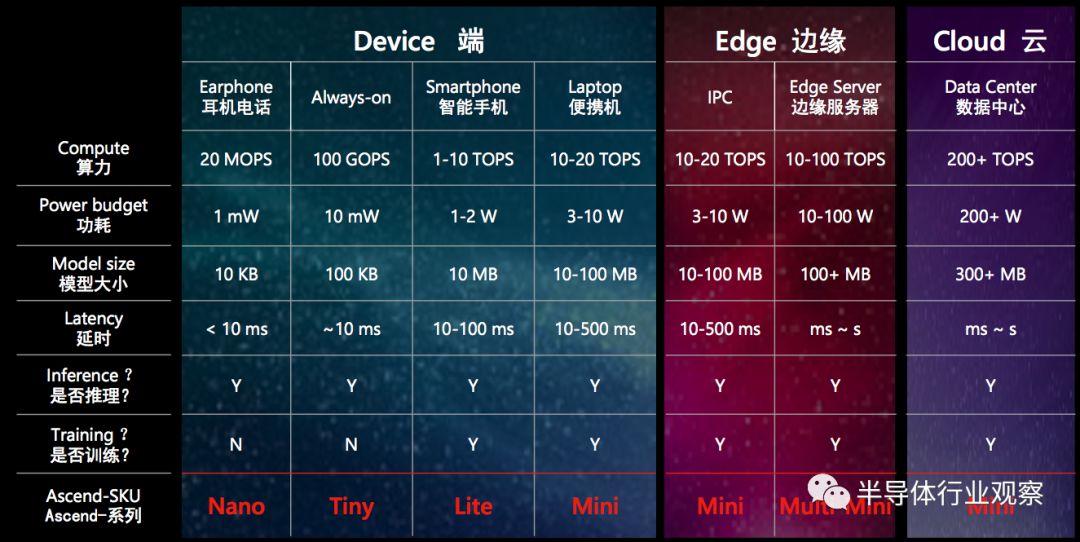
出了縱向深度之外,華為的戰線橫向也鋪得很開。一旦有了一個設計完善的縱向框架,那么把這個框架在不同算力需求尺度上推廣上將是非常容易的,對于華為這樣以執行力強著稱的公司來說這樣的平推戰術更是得心應手。一旦戰略的深度和廣度上都得到良好的執行,其最終的收益將是乘數效應(即收益正比于深度x廣度),從而帶來驚人的回報。從華為的戰略廣度來看,既包含終端(低功耗,中低算力),也包含邊緣(中等功耗,中等算力)和云(高功耗,高算力)。在之前,華為的業務領域早已包含了從端(華為/榮耀手機以及智能家電)到云(華為云),因此在之前的業務上再部署推廣人工智能可謂是水到渠成。
唯快不破:“達芬奇”架構
華為同時注重深度和廣度的人工智能戰略是以技術為基石的,而其技術棧中最具有挑戰性,同時也是最具有區分度的就是底層芯片。為了滿足華為戰略上的需求,其芯片技術需要滿足以下需求:
性能好,否則難以撼動Nvidia的位置,這毫無疑問是戰略深度中最重要的一個要素;
設計可伸縮性好,同一架構可以通過修改設計規模快速部署到不同算力尺度的應用,從而實現戰略廣度快速鋪開的需求;
通用性好,能兼容盡可能多的操作;
上市速度要快。
以上四點要同時滿足是非常困難的,尤其是一些非常癡迷于技術的公司,往往會選擇去探索新的芯片架構以把前三個需求做到極致,這也就意味著放棄了第四個能快速上市的需求,因為新架構往往意味著較長的研發周期和較大的風險,難以做到快速上市。而華為的選擇則是在傳統架構上做足夠的工程優化,并不追求極致性能,但求能滿足用戶需求并快速落地。與之對應的是華為使用在Ascend系列芯片中的達芬奇架構。
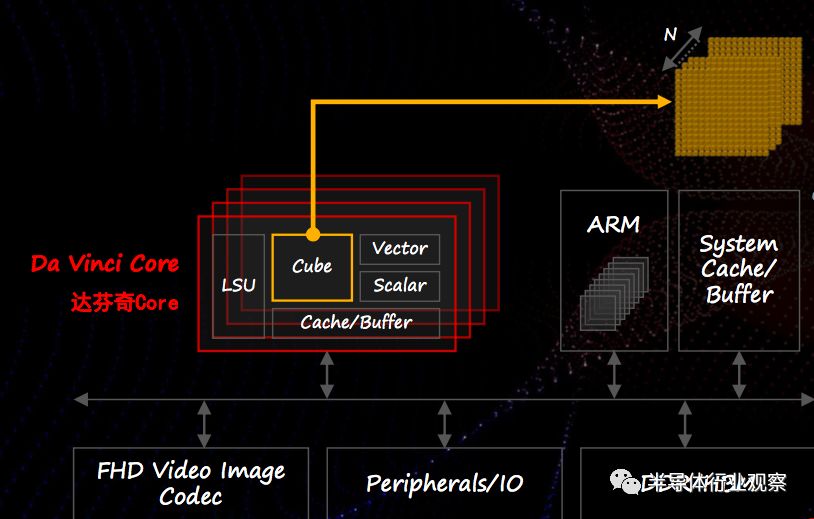
從Ascend芯片的架構來看,其實就是傳統的ARM核+AI加速器的模式,而其AI加速器就是達芬奇核心。達芬奇核心從架構上看起來也并沒有使用炫技式的前沿技術,而是簡單直接地把計算用的乘加器(MAC)按照不同的計算組織成不同的方式,并搭配標準的數據緩存。當要做人工智能相關的計算時,可以使用按cube(“三維立方”) 模式組織的MAC群,從而支持相關計算。當需要其他常規計算時,則可以使用矢量或標量計算MAC。對于不同規模的芯片,可以通過放置不同數量的達芬奇核心來滿足需求,因此同一個達芬奇核心的設計可以靈活地滿足華為戰略橫向上不同應用的需求。
這次的大會上,華為發布了Ascend 910和Ascend 310,其中Ascend 910針對云端應用,使用7nm工藝在350W的功耗上實現了256 TOPS半精度浮點數算力或512 TOPS 8位整數算力,并且集成了128通道全高清視頻解碼器;而Ascend 310針對邊緣應用,使用12nm工藝在7W的功耗上實現了8 TOPS半精度浮點數算力或16 TOPS 8位整數算力,并且集成了單通道全高清視頻解碼器。從中,我們可以看到華為的戰略橫向野心很大,但是第一個落地的市場看來還是機器視覺市場。
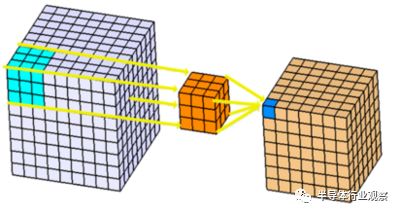
從公布的芯片性能上來看,這次Ascend 910以及Ascend 310特意提到了視頻解碼器,顯然是與視頻應用有關;此外,達芬奇架構中的cube式MAC陣列估計也是為了同時兼顧云端訓練應用和機器視覺推理應用而做的選擇。從技術上看,cube式MAC陣列非常適合卷積神經網絡。卷積神經網絡是目前機器視覺應用最流行的模型,而機器視覺應用則可以說是這一波人工智能應用中落地幅度最大的。在卷積神經網絡中,卷積計算的形式(如下圖)可以被達芬奇的cube式MAC陣列高效支持,而決策樹、貝葉斯等其他常見機器學習算法在cube式MAC陣列上運行卻不見得有什么優勢,因此可以猜測達芬奇的架構設計首要目的是為了支持卷積神經網絡推理,而優化卷積神經網絡推理就意味著主打機器視覺。
換句話說,達芬奇架構是在通用性上有意識地做了折衷以換取較合理的開發時間和成本。另一方面,做云端訓練的時候由于數據往往是批量到來,因此使用cube式MAC陣列也能一次處理一個批次中的不同并行數據,從而也能較好地支持訓練。然而,如果從從架構上做比較,cube式的MAC陣列的效率相比Nvidia GPU的SIMD架構未必會有本質上的提升,因此從訓練的角度來看達芬奇架構可以說是Nvidia GPU的替代者,但很難說是超越者。
我們不妨將達芬奇架構與目前最熱門的兩種商用人工智能芯片架構做比較,即Nvidia的GPU和Google的TPU。Nvidia的GPU架構源自經典的GPU多核并行架構,為了優化人工智能計算,加入了對于矩陣運算的優化支持(Tensor Core)。但是GPU并非天生為人工智能而生,因此在卷積神經網絡推理等主流應用上,GPU架構的效率并不高,因此華為達芬奇為卷積神經網絡優化過的架構相比GPU的計算效率要強不少。與Google的TPU相比,達芬奇架構則顯得更加簡單直接。
TPU上使用了優美的脈動陣列(systolic array)架構,該架構雖然很久之前就被人們提出,但是遲遲沒有找到合適的應用,因此TPU采用脈動陣列從某種意義上可以說是重新發明了脈動陣列,給了脈動陣列以新生。脈動陣列的優勢是對于內存帶寬的需求大大減少,但是問題在于難以做小,一旦做小了效率就會大大下降——在TPU等級的云端高算力應用脈動陣列是合適的,但是在終端低算力低功耗應用中脈動陣列的效率就不高。因此達芬奇架構相比TPU的脈動陣列來說更靈活,能滿足不同算力需求,也即滿足了華為AI戰略中的橫向部分。

最終比拼的還是生態
從之前的分析中,我們的結論是華為的達芬奇架構是一個出色的架構,與Nvidia的GPU和Google的TPU相比性能并不落下風,但是其可伸縮性卻遠好于GPU和TPU,能快速部署到多個不同算力等級的應用中。為了能充分發揮可伸縮性強的優勢,華為的AI芯片必須能盡快進入多個不同的應用領域,因此最終比拼的還是綜合生態而非一兩個特定應用上的性能對比,正如兩軍交戰最終看的是能否實現戰略意圖而并不比糾結于一兩座城市的得失。那么,在與Google和Nvidia等生態玩家的比拼中,華為有哪些優勢和挑戰呢?
從公司基因來看,Google是一家技術驅動的互聯網公司,Nvidia是芯片硬件公司,而華為則是設備提供商。Google一切業務的源頭都是互聯網,因此也希望把一切新擴展的業務規劃到互聯網的范疇中。Google屬于第一批看到人工智能潛力的公司,在自己的業務中早早就用上了人工智能,并開發了全球最流行的深度學習框架TensorFlow。
當人工智能得到更多認可后, Google Cloud上開放了深度學習應用接口給用戶使用,并且在發現人工智能計算需要新一代芯片后著手研發了TPU。對于Google來說,最關鍵的生態環節在于人工智能入口即TensorFlow,一旦TensorFlow成為人工智能的絕對主流框架,那么Google就將成為制訂下一代人工智能標準化實施方案的主導者,這可以說與當年Google把握了互聯網搜索入口如出一轍。另一方面TPU其實只是其生態中并不怎么重要的一環,事實上TPU最早是給Google內部自己使用以節省云計算功耗并加速訓練模型用的,Google并沒有強烈的讓所有用戶都用上TPU的決心。
Nvidia則是底層芯片硬件公司,最關注的是GPU是否能賣得足夠好,CuDNN和TensroRT可以認為是GPU在人工智能時代的驅動程序,但卻不是Nvidia的主要盈利點,而Nvidia更不會嘗試去做人工智能時代入口之類的嘗試,而是會更傾向于把自己定義為“人工智能計算的賦能者”。
相比Google和Nvidia,華為事實上在一個更中間的位置,因為華為是一個解決方案提供商,最終是為了解決客戶的需求,因此其解決方案中既要包含硬件又要包含軟件。華為在底層硬件和上層軟件接口上都有與Nvidia和Google重合競爭的部分,但是其解決方案提供者的地位則是與Nvidia以及Google都沒有任何競爭。
舉例來說,如果中國某零售巨頭要做智能零售解決方案,需要高速邊緣服務器,這樣的公司將會是華為的目標客戶,卻并非Google或Nvidia的目標客戶,因為這三家公司中只有華為有意愿給這樣的客戶提供服務器軟硬件以及云端接入的完整解決方案。而此次發布的Ascend芯片則很明顯是瞄準了安防、智能零售等新興機器視覺解決方案市場,在這些市場Nvidia和Google的基因決定了它們都不會涉足。
雖然目前華為和Google以及Nvidia在邊緣計算解決方案領域并沒有直接競爭,但是隨著華為在云端布局加深,與Nvidia和Google將會有正面競爭。如前所述,Google的TensorFlow是手中的一張王牌,憑著TensorFlow的開放性以及社區建設,目前TensorFlow已經能完美支持多種不同的硬件平臺,另一方面華為的MindSpore配合CANN則更像是面對自家芯片做的定制化解決方案,性能卓越但是開放性卻可能會成為一個挑戰。另一方面,在硬件層面,達芬奇如果想徹底戰勝Nvidia的GPU或許還需要在芯片架構上更進一步,如果無法對GPU有數量級的性能優勢,最終恐怕還是會陷入苦戰。
對AI芯片行業的影響
這次華為大舉進軍AI芯片,是AI芯片領域的一個重要事件。天下之勢,分久必合,合久必分,最初的系統廠商如IBM,SUN等的系統都是包含了自研芯片,直到以Intel為代表的標準化處理器芯片崛起以及計算市場利潤變薄后這些系統公司才逐漸放棄自研芯片而轉而采用Intel的標準化處理器芯片;而AI市場目前看來潛力巨大,不同場景差異化大而且對于芯片效率有很高的需求,這也就為系統廠商重新開始自研芯片提供了足夠的動力。 我們認為華為這次自研AI芯片是系統廠商自研芯片趨勢的延續。
在華為之前,已經有Google、Facebook、亞馬遜、阿里巴巴、百度等諸多互聯網系統廠商開始了AI芯片研發,而華為作為中國芯片研發能力最強的系統廠商,進入AI芯片領域可謂是理所當然,因為對于系統廠商來說擁有了自研芯片才能擁有真正的核心競爭力。華為這次進軍AI芯片預計將會引發更多系統廠商進入AI芯片領域,估計海康、大華、曠視、商湯、依圖等都有自研芯片(或者與其他芯片公司合作研發自己專屬的定制化芯片)的商業動力,我們在不久的將來預計會看到更多系統廠商發布自己的芯片,反之缺乏自研芯片能力的系統廠商的生存空間將會受到擠壓,要么逐漸消失,要么找到新的商業模式。
另一方面,對于AI芯片初創公司來說,華為的AI芯片目前并沒有對外銷售的打算,因此華為并非直接競爭對手。此外,由于AI芯片細分市場多,差異化大,華為的AI芯片更有可能發揮鯰魚效應,激勵這些AI芯片初創公司去尋找華為無暇顧及的細分市場,例如功耗小于1W的超低功耗市場等等。
此外,華為的Ascend系列AI芯片也并非不可戰勝,其架構如前所述并非屬于常人無法想象的黑科技,而更像是一款經過仔細工程優化的AI加速器。因此AI芯片公司如果擁有下一代技術,即使與華為在云端正面競爭也有勝算。
最后,我們必須看到不少AI芯片初創公司實際上也是系統廠商,其AI芯片也是主要供自己的系統使用,如Rokid等。對于這類自研AI芯片的初創系統廠商來說,華為施加的競爭壓力會更大,因為華為實際上走了和這些廠商一樣的道路,本來這些初創公司系統中的亮點是自研芯片,但是現在相對于同樣擁有自研芯片的華為來說這個就不再成為亮點了。對于這些廠商,如何找到屬于自己的差異化市場避開華為的鋒芒就成了目前亟待解決的問題。
-
芯片
+關注
關注
458文章
51435瀏覽量
428874 -
機器視覺
+關注
關注
162文章
4423瀏覽量
120958 -
人工智能
+關注
關注
1799文章
47967瀏覽量
241313
發布評論請先 登錄
相關推薦
AI芯大PK:三星首款AI芯片NPU,性能或超華為蘋果

從華為mete10發布,看國產芯片崛起之路
年底入手全球首款AI手機華為Mate 10 Pro還是值得的
中國企業的崛起!全球AI芯片Top24榜單7家中國公司上榜
AI智能芯片火熱,全芯片產業鏈都積極奔著人工智能去
【免費直播】讓AI芯片擁有最強大腦—AI芯片的操作系統設計介紹.
【HarmonyOS HiSpark AI Camera】開箱介紹
華為芯片性能第一!華為海思麒麟970超越高通驍龍845
華為在AI芯片大戰中有什么優勢?
關于AI芯片格局性能介紹和應用





 工商網監
工商網監
評論