 關于馭勢通往深度學習之路的分析和介紹
關于馭勢通往深度學習之路的分析和介紹

AI天團出道已久,成員都是集顏值和才華于一身的男紙,之前我們已經見過其中三位了,壓軸出場的到底是誰?
更為重要的是,他會帶給我們關于人工智能的什么新鮮東東呢?
王宇航,博士畢業于中國科學院自動化研究所,現階段主要研究方向包括:深度學習、圖像語義分割、目標檢測、網絡模型壓縮與加速等。
宇航告訴我們,深度神經網絡也可以是一個“Transformer”,它可以在使用時根據輸入數據動態地調整自己的結構。至于為什么要設計這樣的網絡結構,宇航用“殺雞焉用牛刀”來形容它。
隨著近年來深度學習的快速發展,我們已經能夠獲得越來越精確的模型實現對圖像目標的識別,而相應地,模型的體積也在成倍地增長,這給模型的部署和應用帶來了很大的麻煩。因此,很多學者一直致力于給深度神經網絡模型“減重”,從而實現效果和速度的平衡。
其中的主要方法包括對模型和知識進行蒸餾,對模型進行剪枝,以及對模型參數進行分解和量化等等。這些方法都能夠提高模型中“有效計算”的密度,從而使模型變得更加高效。如果說這些方法是獲得了更加高效的“靜態”模型的話,另一類方法則采用“動態”的模型來提高應用端的計算效率,它們針對不同的輸入數據動態地調整網絡的前向過程,去除不必要的計算,從而達到加速的目的。
首先,我們可以分析一下深度神經網絡模型在訓練和預測過程中的不同:在訓練的過程中,我們要求模型對來自不同場景不同類別的目標都進行學習和辨別,以豐富其“知識儲備”,并因此不得不引入更多的神經元和網絡連接。
而在預測階段,我們的需求往往集中于個體圖像的識別,而應對這樣相對單一的場景和目標,往往不需要我們使出全部的“看家本領”,只需要使用一部分相關知識針對性地去解決就可以了。
對于深度神經網絡模型,參數,或者說神經元之間的連接,就是它的“知識”,而針對不同的數據對網絡連接進行選擇, 就可以動態地調整網絡的計算過程,對于比較容易辨認的圖像進行較少的編碼和計算,而對于比較難以辨認的圖像進行較多的編碼和計算,從而提高網絡預測的整體效率。
本文介紹的這兩篇文章都是基于這樣的出發點,而它們的關注點又各自不同。
“Runtime” 一文主要關注于減少網絡中卷積層的channel數量,如下圖所示:
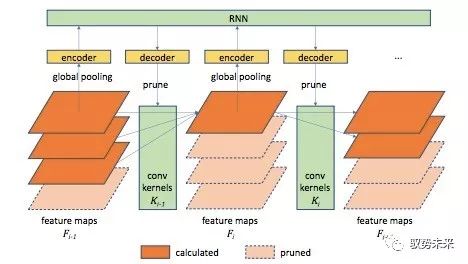
為了簡化模型,他們將網絡中每一個卷積層的卷積核分為k組,根據網絡各前層的輸出特征決定在本層中使用的卷積核數量m(1≤m≤k),并僅使用前m組卷積核參與運算,從而通過減小m來削減層與層之間的連接,達到channel pruning的效果。
而 “SkipNet”一文則主要關注網絡中layer的數量,其主要思想如下圖所示:
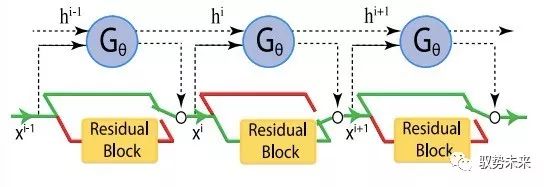
他們為網絡中的每一個層(或每一組層)學習一個“門”,并基于網絡各前層的輸出特征進行判斷,是將前一層輸出的特征圖輸入本層進行計算還是直接越過本層將其送入后續網絡,從而通過“skip”掉盡可能多的層來實現加速的目的。
從直觀上來講,這兩篇文章分別從動態削減模型的“寬度”和“深度”的角度,實現了對預測過程中網絡計算的約減。
那么如何實現對網絡連接方式的動態調整呢?
在網絡由淺至深的過程中,對于網絡中每一層連接方式的選擇(對于“Runtime” 一文是選擇該層使用的卷積核數量,而對于 “SkipNet”一文是選擇該層參與計算與否)可以看作一個序列決策過程,因此,這兩篇文章均選擇了強化學習的方式建模這一過程。將原始的主體CNN網絡作為“Environment”,學習一個額外的輕量的CNN或RNN網絡作為“Agent”來產生決策序列。其中,對于原CNN網絡每一層的決策,作為一個“Action”都將帶來相應的“Reward”。
為了在最大限度地壓縮網絡計算的同時最大化網絡的分類精度,在構建“Reward”函數的過程中,需要同時考慮兩個部分:1.對“Action”約減計算量的獎勵,即prune掉的channel越多或skip掉的layer越多,獲得獎勵越大;2.網絡最終的分類預測損失,即最終分類預測的log損失越小,獲得獎勵越大。由于這兩部分的梯度計算方式不同,因此在對模型目標函數進行優化的過程中,會構成一個“強化學習+監督學習”的混合學習框架。
在具體的算法實現中,這兩篇文章對于“Reward”函數的設計和優化策略的選擇各有不同。“Runtime”一文采取了交替更新的方式,而“SkipNet”一文則采用了混合優化的方式,具體的細節我們就不在這里詳述了。
對于方法的效果,這兩篇文章都給出了嚴謹的數據對比和可視化結果分析,大家可以根據興趣進行更深入的閱讀和研究。而動態網絡結構的意義,可能也不止于單純的約減計算。網絡連接的改變實際上影響著整個特征編碼的過程,以“SkipNet”為例,對n個網絡層的選擇可能會帶來2^n種不同的特征編碼方式,而在訓練這種動態選擇策略的過程中,可能也會一定程度地解耦層與層之間的依賴關系,這也會為我們日后設計更具“自適應性”的網絡結構和研究網絡中信息的傳遞及融合方式帶來更多的啟發。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103441 -
可視化
+關注
關注
1文章
1259瀏覽量
21813 -
深度學習
+關注
關注
73文章
5560瀏覽量
122750
發布評論請先 登錄
騰勢首款概念跑車亮相2025上海車展

軍事應用中深度學習的挑戰與機遇
BP神經網絡與深度學習的關系
NPU在深度學習中的應用
更準、更深度、更貼近業務 數勢科技智能分析助手SwiftAgent報告功能全面升級







 工商網監
工商網監
評論