 摩爾定律正在放緩 大型芯片公司方向或發生重大轉變
摩爾定律正在放緩 大型芯片公司方向或發生重大轉變
為什么Intel,AMD,Arm和IBM專注于架構,微體系結構和功能變化。
大型芯片制造商正在轉向芯片組等架構改進,片上和片外更快的吞吐量,以及每個操作或周期集中更多工作,以提高處理速度和效率。
總的來說,這代表了主要芯片公司方向的重大轉變。他們所有人都在努力應對處理需求的大幅增加以及傳統方法無法提供足夠的改進能力,性能和面積。自28nm以來,縮放的好處一直在減少,在某些情況下還要好。與此同時,從新設備,新應用程序和各地傳感器的大量增加中收集的數據越來越多,需要使用相同或更低的功率更快地處理。
對于芯片制造商來說,這相當于一場完美的風暴,過去他們利用投機執行等方法來增加擴展的好處。但是,投機性執行已被證明會產生安全漏洞,只是縮小的功能不再能使功率和性能提高30%到50%。今天的數字接近20%,甚至需要新的材料和結構。
與此同時,大型芯片制造商看到谷歌,亞馬遜和Facebook等公司紛紛跨界其主要市場——巨型數據中心。此外,它們正在人工智能 / 機器學習市場中受到挑戰,并且在一些初創公司開發專門的加速器方面受到挑戰,這些加速器通過架構變化有望實現數量級的改進。
最大的芯片制造商開始接受它,而不是試圖對抗這種趨勢。例如,AMD推出了Zen 2架構,它依賴于由它們和其他人制造的芯片組合——高速芯片到芯片互連和可以調整的優先級方案,以便數據可以更快地移動到一個方向或其他。
AMD首席架構師Dan Bouvier在半導體芯片大會上表示,小型芯片可以提高產量。但他指出,通過使用通用互連并將所有這些組件放在基板上,小芯片也可用于將芯片尺寸增加到1000平方毫米,這大于光罩尺寸。該互連還可用于連接在不同工藝節點上開發的芯片,具體取決于對特定功能最有意義的內容。
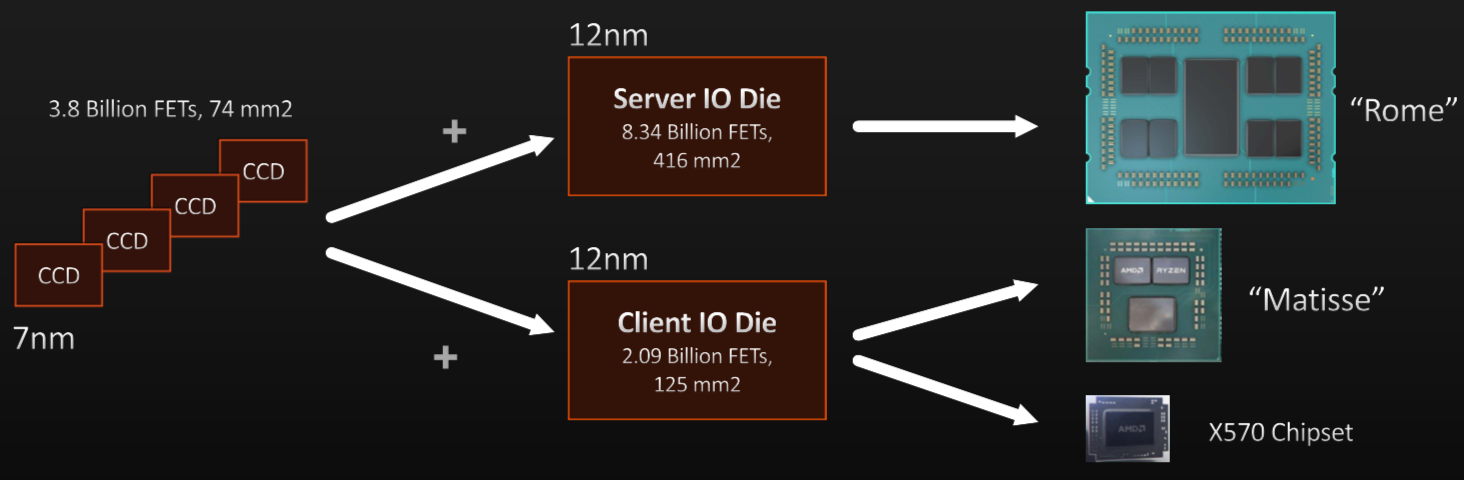
圖1:AMD的芯片架構。資料來源:AMD
英特爾的戰略也很大程度上依賴于芯片,它通過各種方法連接,包括內部開發的芯片到芯片橋(嵌入式多芯片互連橋或EMIB)。但該公司也一直在研究內存訪問和存儲問題。該解決方案的一部分涉及持久存儲器,這有助于彌合DRAM和固態驅動器之間的差距。
一段時間以來,英特爾一直在發布一種稱為3D XPoint的持久存儲器類型。基于相變存儲器技術,英特爾在其自己的SSD和DIMM中集成了3D XPoint設備,從而加速了這些系統中的操作。
英特爾高級首席工程師Lily Looi說:“最大的挑戰之一就是你已經獲得了所有需要處理的數據,但你的空間有限。” “在過去的幾年里,數據爆炸式增長,有兩件事情發生了變化。首先,納秒很重要,因此您需要更多容量。第二件事是您需要一個持久性功能,以便在關閉電源時數據仍然存在。但是您不必保存所有數據。您可能只需要保存一個塊甚至幾千字節的數據,這樣效率會更高。”
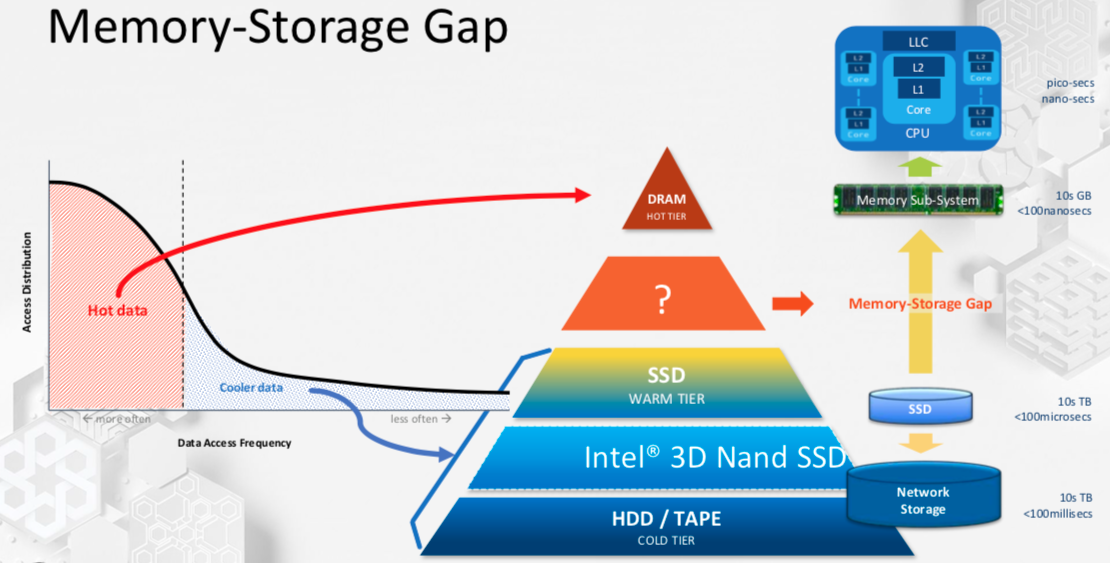
圖2:存儲指數級數據的位置。資料來源:Intel
更智能的權衡
更大的芯片和更快的互連并不是實現更好性能的唯一途徑。
例如,Arm推出了它的Neoverse N1架構,它顯著提高了分支預測的準確性——基本上相當于搜索中的預取。Arm還繼續推動以更低的功耗做更多事情,通過連貫的網狀網絡將IP磁貼連接在一起,允許根據特定應用的需要調整處理器的大小。
Arm的戰略關鍵是更大的2級緩存和上下文切換,Arm的高級首席工程師Andrea Pellegrini 說,它比以前的方法快2.5倍。“我們也看到分支誤差預測減少了7倍,”他說。Arm還專注于通過降低緩存未命中率來減少其指令占用率,Pellegrini表示已降低1.4倍。與此同時,L2訪問量下降了2.25倍。
這是查看處理器效率和每瓦性能的另一種方式。雖然大多數處理器公司從在相同功率預算下做得更多的角度來處理它,但其他公司正在考慮用更少的功率做更多的事情,這在帶電池的設備中很重要。這包括智能手機,但它也包括為電動汽車和機器人開發的芯片。
Arm還將使用其網狀網絡方法添加為特定數據類型定制的第三方加速器。
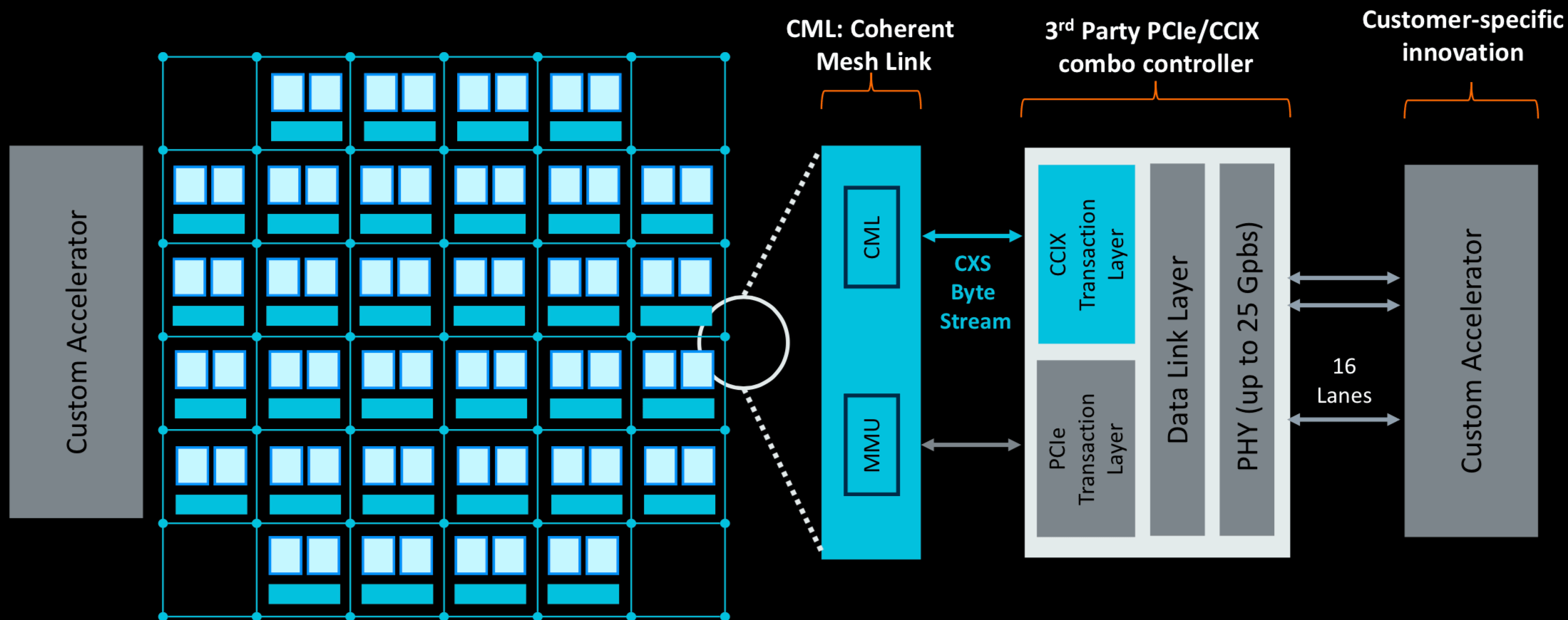
圖3:Arm的可定制Neoverse架構。資料來源:Arm
與此同時,IBM推出了一種既簡單又非常不同的架構。IBM的目標之一是假設數據包何時到達,這實質上將預取概念提升到更高的抽象級別。它理解如何使這些假設變得如此困難,因為它有效地將使用模型應用于架構中。
IBM的方法是使用最可能的芯片配置,預先進行權衡并設置限制。根據IBM的 Power系統硬件架構師Jeff Stuecheli的說法,這可以鞏固物理層的數量,通過PCIe Gen 4運行一些數據,其余的通過25G SerDes運行。“這更具功率和面積效率,”Stuecheli說。該公司還做了一些事情,如走向不對稱的架構,這意味著一個加速器的狀態不會影響另一個加速器的運行。“我們希望隱藏加速器的狀態表。”

圖4:IBM強調數據吞吐量。資料來源:IBM
連接各個部分
從所有這些角度來看,所有主要的芯片制造商都在解決目標市場中的類似問題。它們通過通用處理器和自定義加速器的組合提高了每瓦性能,并且在許多情況下,它們使得從一個市場到下一個市場更容易,更快地替換模塊成為可能,并且隨著算法的更新。它們還提高了片上數據,片外到存儲器的吞吐量,并優先考慮不同類型數據的移動。
其中許多方法并非新思路,但過去并不存在使這一切成為現實的一些技術。
“創建通用PHY以啟用加速器是發生的關鍵事情之一,” Cadence的高級設計工程架構師Stuart Fiske說。“你還看到的是,處理器并沒有變得更簡單。很多這些公司都在嘗試為加速器創建接口。這并不能解決復雜性問題。它仍然是一個幾年的設計周期,并沒有辦法解決這個問題。但是你可以讓加速器適應最新的神經網絡。”
關鍵是平衡所有這些組件的集成,并具有足夠的靈活性來進行更改。實際上,所有這些芯片制造商都在設計多芯片平臺,可針對特定市場和用例進行定制,同時優化每瓦性能并提高數據吞吐量。
Silexica產品和技術營銷負責人Loren Hobbs說:“時鐘速度方面的設計正在嶄露頭角。” “前進的方向是使每個時鐘周期盡可能高效。隨著多核異構多處理器的增加,這加速了這些芯片的復雜性。您可以將所有這些小芯片組合在一起以提高處理能力,但您需要使用工具來幫助分發和分析它們。您必須映射代碼庫,這是無限復雜的。它需要靜態,動態和上下文分析。”
這里的共同點是不斷增長的數據量,無論是在邊緣還是在云端。處理數據的位置以及移動的速度是架構的關鍵部分。
“每個人都在與CCIX抗爭,” Arteris IP總裁兼首席執行官K. Charles Janac說。“如果你有一個加速器和兩個連貫的模具,那么有太多的情況可以讓它輕松工作。但現在您可以使用3D互連將平面CPU和平面I / O連接在一起。因此,這看起來像是軟件的一個系統,并且您在芯片上的網絡和不同的芯片之間存在芯片間鏈接。這樣,您可以支持跨兩個芯片的非連貫和一致的讀/寫。它使互連更有價值,但也使它變得更加復雜。”
實際上,這就是為什么這些架構已經在工作一段時間的原因之一。讓所有部分一起工作已經證明比任何人最初想象的要困難得多。
“內存控制器和NoC將必須更緊密地集成,”Janac說。“問題在于,沒有人理解整個芯片的QoS,也沒有任何獨立的內存控制器公司。但是內存流量必須更好地集成才能實現這一目標。”
為了讓小型車市場真正起飛,還需要有開放標準。
“沒有標準用于連接芯片,” Achronix營銷副總裁Steve Mensor說。“問題是你必須能夠與他們交談。所以你應該能夠為套接字開發一個芯片,并有一個鏈接和一個協議棧來支持它。有AMD和英特爾的專有解決方案。還有正在開發的標準解決方案。如果我構建ASIC并購買小芯片,我需要一個標準的解決方案,以便我可以獨立構建該芯片。這是這個模型的基本要求。”
盡管如此,它確實為構建在不同ISA上的加速器打開了大門,例如RISC-V。
“這是小型輕量級硬件加速器的新機遇,” Codasip營銷副總裁Chris Jones說。“初創公司構建芯片的開放接口可能會為半導體提供另一個繁榮周期,而這種情況將一直發生在全封裝上。關于這一點仍然存在一些問題,例如誰最終負責測試整個界面,以及如何在簽署界面時使用它。我們還需要看看它們的芯片接口是什么樣的,它們是標準化還是保持專有。但它肯定為更多驗證IP,仿真和模擬增添了新的機會。”
更換組件
目前尚不清楚的是這些架構還有哪些變化。目前推出的大多數是平面的,但也可以選擇將其中一些設計推入Z軸。
例如,SerDes增加了設計的延遲,但使用先進的封裝技術可以實現同樣的延遲。臺積電的CoWoS(基板上芯片上芯片)和InFO MS(基板上帶有存儲器的集成扇出)是兩種選擇。eSilicon的業務和企業發展副總裁Patrick Soheili表示,該公司剛剛使用聯華電子的插入器開發了一種CoWoS類型的方法。
“你可以將它拆開并將其帶到不同的抽象層次,”Soheili說。“如果你看一下這些架構中的一些,如果你有大量的數據流,那么擁有大量的小型SRAM是很低效的,當你做大量的內存時效率很高。這可能聽起來違反直覺,但我們發現更大的內存更有效,特別是對于AI類型的應用程序。”
如何邁出下一步?
所有這些方法的市場才剛剛開始。現在的關鍵是找出在這些不同架構中構建可重復性和可靠性的方法,以便它們可以用于汽車或工業等安全關鍵應用,以及當今各種各樣的終端市場。
這些新架構如此引人注目的原因在于能夠針對特定應用程序對其進行自定義,并利用架構作為此類自定義的基礎。所有處理器供應商都采用這些類型的架構,從FPGA供應商到像Nvidia這樣的公司,后者在創紀錄的六個月內推出了新的芯片架構。但很明顯,未來,隨著設備的修改和更新,行業將需要更多的工具,更多的數據分析以及對潛在交互的更好理解。
這只是一個轉變的開始,最終將涉及整個半導體供應鏈。雖然擴展將繼續,但在處理器領域,它只是一個額外的開關,可以在一個長列表中轉換,現在包括架構,封裝,材料和工作負載優化。設計師現在是變革的驅動力,他們中的大多數人預計隨著摩爾定律的減速,設計的變化將會加速。
新聞源:semiengineering
-
芯片
+關注
關注
459文章
52252瀏覽量
436914 -
半導體
+關注
關注
335文章
28666瀏覽量
233292 -
加速器
+關注
關注
2文章
824瀏覽量
38949
發布評論請先 登錄
跨越摩爾定律,新思科技掩膜方案憑何改寫3nm以下芯片游戲規則
電力電子中的“摩爾定律”(1)

瑞沃微先進封裝:突破摩爾定律枷鎖,助力半導體新飛躍

Chiplet:芯片良率與可靠性的新保障!

混合鍵合中的銅連接:或成摩爾定律救星

石墨烯互連技術:延續摩爾定律的新希望
摩爾定律是什么 影響了我們哪些方面

Chiplet或改變半導體設計和制造

后摩爾定律時代,提升集成芯片系統化能力的有效途徑有哪些?
觀點評論 | 芯片行業,神奇的一年

高算力AI芯片主張“超越摩爾”,Chiplet與先進封裝技術迎百家爭鳴時代






 工商網監
工商網監
評論