 TensorFlow2.0中創建了一個Transformer模型包,可用于重新構建GPT-2、 BERT和XLNet
TensorFlow2.0中創建了一個Transformer模型包,可用于重新構建GPT-2、 BERT和XLNet

今日Reddit最熱帖。博主在TensorFlow2.0中創建了一個Transformer模型包,可用于重新構建GPT-2、 BERT和XLNet。這個項目的目標是創建Transformer模型的所有核心部分,這樣就可以重用它們來創建更新的、更多的SOTA模型,比如BERT和XLNet。
Transformer是谷歌在2017年提出的一個革新性的NLP框架,相信大家對那篇經典論文吸睛的標題仍印象深刻:Attention Is All You Need。
自那以來,業內人士表示,在機器翻譯領域,Transformer 已經幾乎全面取代 RNN。總之 Transformer 確實是一個非常有效且應用廣泛的結構,應該可以算是自 seq2seq 之后又一次 “革命”。
如今,谷歌手上握有兩個強大的AI戰力:TensorFlow 2.0和Transformer。如果能將兩大戰力合體,就能制造出更強大的AI武器。
想到不如做到。于是Zachary Bloss(就是下圖這位帶著淡淡憂傷的背影),一位美國最大的非銀行貸款機構之一Quicken Loans的數據分析師,花了一點時間,在TF2中構建一個可擴展的transformer模型。
該項目的目標是創建"Attention is all you need"論文中所討論的transformer模型的所有核心部分,以便可以重復使用它們來創建更前衛、更多像BERT和XLNet一樣的SOTA模型,
Zachary已經將做好的模型打包放在了GitHub上,而且這個包抽象度很高,只要是相關的類都可以隨意使用。
只要你野心夠大,完全可以用這個包來折騰Encoder和Decoder類去創建其他模型,比如BERT,Transformer-XL,GPT,GPT-2甚至XLNet都沒問題,你只需要調整masking類即可。
那么我們看看具體應該如何安裝和使用。
如何安裝
前期準備
進行安裝
強烈建議為項目創建一個新的虛擬環境!因為此軟件包需要Tensorflow 2.0,你懂的。
接下來通過安裝Tensorflow 2.0的gpu版本來使用GPU:
如何使用
Repo里有一個(example.py)文件。這是一個示例文件,可以用來了解此模型的工作原理。該模型以其最基本的形式,以numpy數組作為輸入,并返回一個numpy數組作為輸出。
此模型的常見用例是語言翻譯。一般來說,訓練這個模型的時候,功能列是原始語言,目標列是要翻譯的語言。
生成輸入/輸出
這里提供了一些輔助函數,但基本上需要生成兩個Tensorflow標記生成器以及一個帶有功能和目標列的pandas DataFrame
可以利用DataProcess類中的輔助函數從DataFrame生成TensorDatasets,以及執行train_test_split
學習率/優化器
當設置在具有急劇傾斜然后指數衰減的自定義學習速率時,transformer模型表現優異
這項工作已在CustomSchedule()類中實現。隨意玩熱身步驟,以完成日程安排!
定義transformer模型
創建HPARAMS,定義模型的大小。
訓練
定義Trainer類后,只需要在訓練器對象上調用train()方法。
這將返回訓練的準確性和損失
Attention is all you need
從實踐中學習,才能對理論理解的更加透徹。在通過上述方式實操后,我們回過頭再看Transformer的論文,可能就會覺得更加清晰了。
早在2年前,谷歌大腦、谷歌研究院和多倫多大學學者合作的一項新研究稱,使用一種完全基于注意力機制(Attention)的簡單網絡架構 Transformer 用于機器翻譯,效果超越了當下所有公開發表的機器翻譯模型,包括集成模型。
值得一提的是,該研究沒有使用任何循環或卷積神經網絡,全部依賴注意力機制。正如文章的標題所說:“注意力機制是你需要的全部(Attention Is All You Need)。
一直以來,在序列建模和序列轉導問題中,比如涉及語言建模和機器翻譯的任務,循環神經網絡(RNN),尤其是長短時記憶(LSTM)及門循環網絡,都被視為最先進的方法。研究人員也想方設法拓展循環語言建模和編碼器-解碼器架構。
其中,注意力機制自提出以來便成為序列建模和轉導模型不可或缺的一部分,因為注意力機制能夠在不關注輸入輸出序列之間距離的情況下,對依存(dependence)建模。只有在極少數的案例中,作者將注意力機制與一個循環網絡作為整個網絡中相等的結構,并行放置。
在谷歌大腦最新公開的一項研究中,研究人員提出了一個全新的架構 Transformer,完全依賴注意力機制從輸入和輸出中提取全局依賴,不使用任何循環網絡。
谷歌大腦的研究人員表示,Transformer 能夠顯著提高并行效率,僅在 8 顆 P100 GPU 上訓練 12 小時就能達到當前最高性能。
論文作者以 Extended Neural GPU、ByteNet 和 ConvS2S 為例,這些結構都使用卷積神經網絡(CNN)作為基本的模塊,并行計算所有輸入和輸出位置的隱藏表征,從而減少序列計算的計算量。在這些模型中,將來自兩個任意輸入或輸出位置的信號相關聯的運算次數會根據位置之間的距離增加而增加,對于 ConvS2S 這種增加是線性的,而對于 ByteNet 則是呈對數增長的。
這讓學習距離較遠的位置之間的依賴難度增大。在 Transformer 當中,學習位置之間的依賴被減少了,所需的運算次數數量是固定的。
這需要使用自注意力(Self-attention),或內部注意力(intra-attention),這是一種與單個序列中不同位置有關的注意力機制,可以計算出序列的表征。
以往研究表明,自注意力已被成功用于閱讀理解、抽象概括等多種任務。
不過,谷歌大腦的研究人員表示,據他們所知,Transformer 是第一個完全依賴自注意力的轉導模型,不使用 RNN 或 CNN 計算輸入和輸出的表征。

摘要
當前主流的序列轉導(transduction)模型都是基于編碼器-解碼器配置中復雜的循環或卷積神經網絡。性能最好的模型還通過注意力機制將編碼器和解碼器連接起來。
提出了一種簡單的網絡架構——Transformer,完全基于注意力機制,沒有使用任何循環或卷積神經網絡。兩項機器翻譯任務實驗表明,這些模型質量更好、可并行化程度更高,并且能大大減少訓練時間。
該模型在 WMT 2014 英德翻譯任務上實現了 28.4 的 BLEU 得分,在現有最佳成績上取得了提高,其中使用集成方法,超過了現有最佳成績 2 個 BLEU 得分。
在 WMT 2014 英法翻譯任務中,該模型在單一模型 BLEU 得分上創下了當前最高分 41.0,而訓練時間是在 8 顆 GPU 上訓練 3.5 天,相比現有文獻中的最佳模型,只是其訓練成本的很小一部分。
研究還發現,Transformer 泛化性能很好,能夠成功應用于其他任務,比如在擁有大規模和有限訓練數據的情況下,解析英語成分句法解析(English constituency parsing)。
模型架構
大多數性能較好的神經序列轉導模型都使用了編碼器-解碼器的結構。Transformer 也借鑒了這一點,并且在編碼器-解碼器上使用了全連接層。
編碼器:由 6 個完全相同的層堆疊而成,每個層有 2 個子層。在每個子層后面會跟一個殘差連接和層正則化(layer normalization)。第一部分由一個多頭(multi-head)自注意力機制,第二部分則是一個位置敏感的全連接前饋網絡。
解碼器:解碼器也由 6 個完全相同的層堆疊而成,不同的是這里每層有 3 個子層,第 3 個子層負責處理編碼器輸出的多頭注意力機制。解碼器的子層后面也跟了殘差連接和層正則化。解碼器的自注意力子層也做了相應修改。
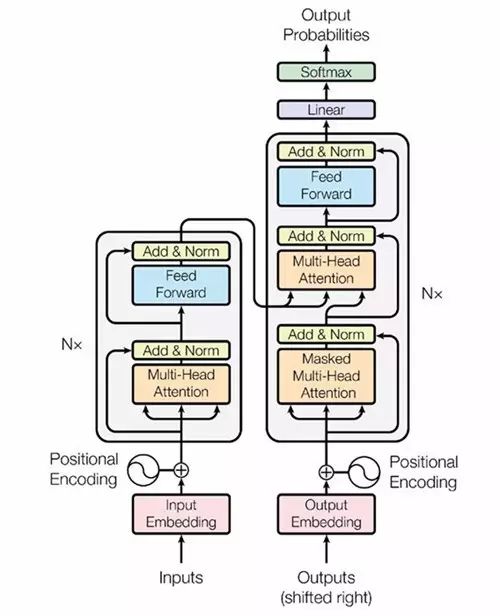
(圖1)Transformer的架構示意圖
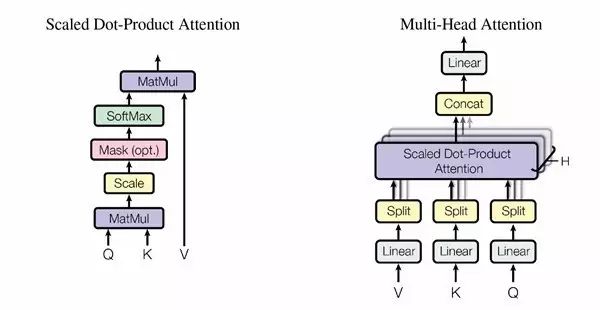
(圖2)具體采用的注意力機制。左邊是 Scaled Dot-Roduct Attention,右邊是多頭注意力(Multi-Head Attention),由幾個并行的層組成。
在編碼器-解碼器層當中,query 來自上一個解碼層,編碼器輸出值(value)及 memory key。這樣,解碼器中所有位置都能照顧到輸入序列中的所有位置。
編碼器含有自注意力層。在自注意力層中,所有的 key、value 和 query 都來自同一個地方,那就是編碼器的上一層輸出。編碼器中的每一個位置都能照顧到編碼器上一層中所有的位置。
同樣,解碼器中的自注意力層讓解碼器中所有位置都能被注意到,包括那個位置本身。
創造了BLEU的最高分28.4
在WMT2014 英語到德語的翻譯任務中,大型transformer在性能上優于此前在有記錄的所有模型(包括集成的模型),并且創造了BLEU的最高分28.4。
模型的配置詳情見表3下的清單。訓練過程為3.5天,在8顆P100 GPU上運行。即便是最基礎的模型,也超越了此前所有發布的和集成的模型,但是訓練的成本卻只是此前最好的一批模型中的一小部分。
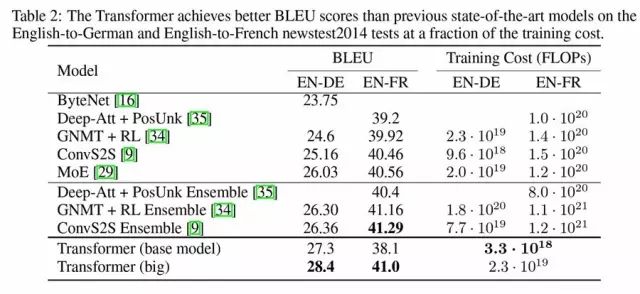
表2:Transformer 在英語到德語和英語到法語新聞測試2014數據集上,比此前最好的模型獲得的BLEU分數都要高。
表2 總結了結果,并與其他模型在翻譯質量和訓練成本上進行對比,評估了被用于訓練模型的浮點操作數量,用來乘以訓練時間,使用的GPU的數量,并評估了每一顆GPU中,可持續的單精度浮點承載量。
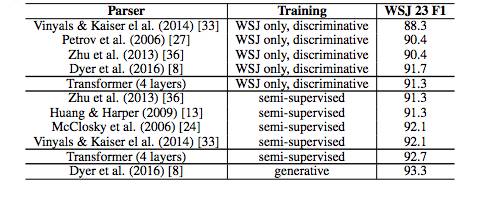
表4 Transformer 在英語成分句法解析任務上也取得了較好的效果。(基于WSJ Section 23 數據庫)
為了測試Transformer能否用于完成其他任務,研究人員做了一個在英語成分句法解析上的實驗。這一任務的難度在于:輸出受到結構限制的強烈支配,并且比輸入要長得多得多。另外,RNN序列到序列的模型還沒能在小數據領域獲得最好的結果。
-
機器翻譯
+關注
關注
0文章
140瀏覽量
15191 -
tensorflow
+關注
關注
13文章
330瀏覽量
61170
原文標題:通吃BERT、GPT-2,用TF 2.0實現谷歌破世界紀錄的機器翻譯模型Transformer
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用OpenVINO? 2020.4.582將自定義TensorFlow 2模型轉換為中間表示 (IR)收到錯誤怎么解決?
將YOLOv4模型轉換為IR的說明,無法將模型轉換為TensorFlow2格式怎么解決?
使用Python API在OpenVINO?中創建了用于異步推理的自定義代碼,輸出張量的打印結果會重復,為什么?
無法轉換TF OD API掩碼RPGA模型怎么辦?
創建了用于OpenVINO?推理的自定義C++和Python代碼,從C++代碼中獲得的結果與Python代碼不同是為什么?
用PaddleNLP在4060單卡上實踐大模型預訓練技術

OpenAI即將推出GPT-5模型
如何使用MATLAB構建Transformer模型

transformer專用ASIC芯片Sohu說明

【「大模型啟示錄」閱讀體驗】如何在客服領域應用大模型
如何使用Python構建LSTM神經網絡模型
自動駕駛中一直說的BEV+Transformer到底是個啥?







 工商網監
工商網監
評論