 模擬內存計算迎來挑戰 解決邊緣AI推理迫在眉睫
模擬內存計算迎來挑戰 解決邊緣AI推理迫在眉睫
機器學習和深度學習已經成為我們生活中不可或缺的一部分。通過自然語言處理(NLP)、圖像分類和對象檢測的人工智能(AI)應用已經深入到我們許多設備中。大多數人工智能應用程序都是通過基于云的引擎提供服務,這些引擎可以很好地為它們的用途提供基礎支持,比如在Gmail中輸入電子郵件回復時獲得單詞預測。
盡管我們很享受這些人工智能應用所帶來的好處,但這種方法也帶來了隱私、功耗、延遲和成本方面的挑戰。如果在數據起源處有一個本地處理引擎能夠執行部分或全部計算(推理),則可以解決這些挑戰。這在傳統的數字神經網絡實現中是很難做到的,在這種情況下,內存成為了耗電的瓶頸。這個問題可以通過多層內存和使用模擬內存計算方法來解決,這些計算方法可讓處理引擎能夠滿足在網絡邊緣執行人工智能推斷所需的更低的毫瓦到微瓦的功率要求。
云計算的挑戰
當人工智能應用程序通過基于云的引擎提供服務時,用戶必須上傳一些數據到云中,由計算引擎處理數據,提供預測,并將預測發送到下游,供用戶使用。
在這一進程中也有一些困難:
1.隱私和安全問題:對于始終在線的、感知的設備,人們擔心個人數據在上傳期間或在數據中心的存儲期間被濫用。
2.不必要的功耗:如果每個數據位都被云計算占用,那么它就會消耗來自硬件、無線電、傳輸和云計算的能量。
3.小批量推理的延遲:如果數據來自邊緣,則從基于云的系統獲得響應可能需要一秒或更長的時間。對于人類的感官來說,任何超過100毫秒的延遲都是顯而易見的。
4.數據經濟:傳感器無處不在,而且它們非常便宜;然而,他們產生了大量的數據。將所有數據上傳到云端并進行處理似乎毫無經濟可言。
通過使用本地處理引擎來解決這些挑戰,執行推理操作的神經網絡模型,首先要針對所需用例使用給定的數據集進行培訓。通常,這需要高計算資源和浮點算術運算。因此,機器學習解決方案的訓練部分仍然需要在公共或私有云(或本地GPU、CPU、FPGA場)上使用數據集完成,以生成最優的神經網絡模型。一旦神經網絡模型準備就緒,神經網絡模型就不需要反向傳播進行推理操作,因此該模型可以進一步針對具有小型計算引擎的本地硬件進行優化。一個推理引擎通常需要大量的多重累加(MAC)單元,然后是一個激活層,如整流線性單元(ReLU)、sigmoid或tanh,這取決于神經網絡模型的復雜性和層之間的池化層。
大多數神經網絡模型需要大量的MAC操作。例如,即使一個相對較小的“1.0 MobileNet-224”模型也有420萬個參數(權重),需要5.69億個MAC操作來執行推斷。由于大多數模型由MAC操作主導,這里的重點將放在機器學習計算的這一部分,并探索創建更好的解決方案的機會。圖2顯示了簡單的、完全連通的兩層網絡。
輸入神經元(數據)使用第一層權值進行處理。第一層的輸出神經元然后與第二層的權重進行處理,并提供預測(比如,該模型是否能夠在給定的圖像中找到一張貓臉)。這些神經網絡模型使用“點積”來計算每一層的每一個神經元,如下式所示(為了簡化,在方程中省略“偏差”項):
數字計算的內存瓶頸
在數字神經網絡實現中,權值和輸入的數據存儲在DRAM/SRAM中。權重和輸入數據需要移動到MAC引擎進行推理。如下圖所示,這種方法在獲取模型參數和將數據輸入到實際MAC操作發生的算術邏輯單元(ALU)時消耗了大部分能量。
從能量的角度來看——一個典型的MAC操作使用數字邏輯門消耗大約250飛托焦耳(fJ,或10 - 15焦耳)的能量,但在數據傳輸過程中消耗的能量比計算本身要多兩個數量級,大概在50皮焦耳(pJ,或10 - 12焦耳)到100pJ之間。
公平地說,有許多設計技術從內存到ALU的數據傳輸可以最小化;然而,整個數字方案仍然受到馮·諾依曼架構的限制——因此這為減少能源浪費提供了巨大的機會。如果執行MAC操作的能量可以從~100pJ降低到pJ的一個分數會是什么結果?
使用內存中的模擬計算消除內存瓶頸
當內存本身可以用來減少計算所需的功耗時,在邊緣執行推理操作就變得非常省電。使用內存中的計算方法可以將必須移動的數據量最小化。這反過來又消除了數據傳輸過程中所浪費的能量。采用超低有功功率耗散、待機狀態下幾乎無能量耗散的閃速電池,也會進一步降低了系統的能量耗散。
這種方法的一個案例是來自Microchip公司的Silicon Storage Technology (SST) ——memBrain?技術。基于SST的SuperFlash?內存技術,解決方案包括一個內存計算架構,可以在存儲推理模型的權重的地方進行計算。這消除了MAC計算中的內存瓶頸,因為權重沒有數據移動——只有輸入數據需要從輸入傳感器(如攝像頭或麥克風)移動到內存陣列。
這個內存的概念基于兩個因素:(a)模擬電流響應從一個晶體管是基于其閾值電壓(Vt)和輸入數據,和(b)基爾霍夫電流定律,即導體網絡中在一點相接的電流的代數和為零。
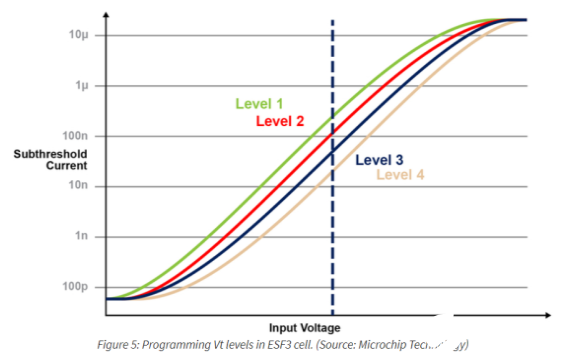
理解基本的非易失性內存(NVM)位元組(bitcell)同等很重要,它被用在這種多層內存架構中。下圖(圖4)是兩個ESF3(嵌入式SuperFlash第三代)位元的橫截面,它們具有共享擦除門(EG)和源線(SL)。每個位元有五個終端:控制門(CG)、工作線(WL)、擦除門(EG)、源線(SL)和位線(BL)。擦除操作是通過在EG上施加高壓來完成的。對WL、CG、BL、SL施加高/低電壓偏置信號進行編程操作,對WL、CG、BL、SL施加低電壓偏置信號進行讀操作。
使用這種內存架構,用戶可以通過細粒度的編程操作在不同的Vt級別上對內存位單元進行編程。該存儲技術利用一種智能算法來調整存儲單元的浮動門(FG) Vt,以實現輸入電壓的一定電流響應。根據最終應用的需要,我們可以在線性或閾下工作區域對單元進行編程。
下圖演示了在內存單元上存儲和讀取多個級別的功能。假設我們試圖在內存單元中存儲一個2位整數值。對于這個場景,我們需要用2位整數值(00、01、10、11)的四個可能值中的一個對內存數組中的每個單元進行編程。下面的四條曲線是四種可能狀態的IV曲線,電池的電流響應取決于施加在CG上的電壓。
使用內存計算的乘法累加操作
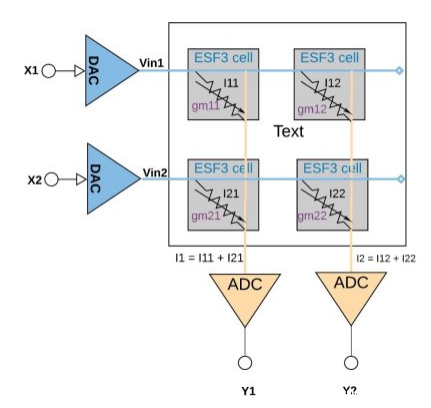
每個ESF3單元都可以建模為可變電導(gm)。電導的ESF3細胞取決于浮動柵Vt的編程細胞。將訓練模型的權值編程為記憶單元的浮動門Vt,因此,單元的gm表示訓練模型的權值。當輸入電壓(Vin)作用于ESF3電池時,輸出電流(Iout)由公式Iout = gm * Vin給出,它是輸入電壓與儲存在ESF3電池上的重量之間的乘法運算。
圖6演示了一個小數組配置(2×2數組)中的乘法累加概念,其中累加操作是通過添加連接到同一列(例如I1 = I11 + I21)的輸出電流來執行的。激活功能可以在ADC塊內執行,也可以在內存塊外的數字實現中執行,具體取決于應用程序。
我們在更高的層次上進一步闡明這一概念——來自訓練模型的單個權值被編程為內存單元的浮動門Vt,因此來自訓練模型的每一層(假設是一個全連接層)的所有權值都可以在一個物理上看起來像權值矩陣的內存陣列上編程。
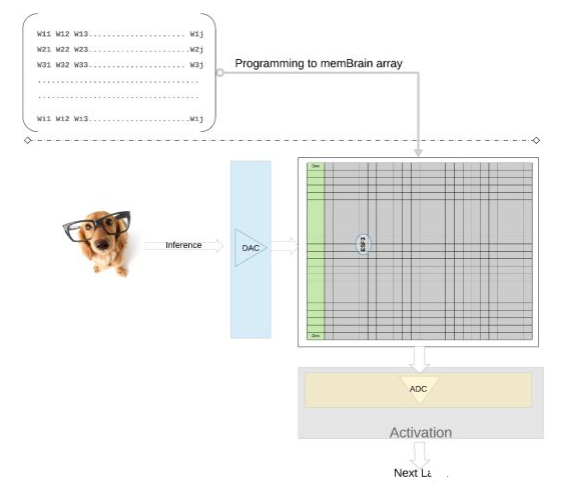
對于推理操作,我們首先使用數模轉換器(DAC)將數字輸入(比如圖像像素)轉換為模擬信號,并應用于內存陣列。然后,該陣列對給定的輸入向量并行執行數千次MAC操作,并產生可進入相應神經元激活階段的輸出,然后使用模數轉換器(ADC)將其轉換回數字信號。數字信號在進入下一層之前被處理成池。
這種類型的內存架構非常模塊化和靈活。許多memBrain塊可以被拼接在一起,用混合權重矩陣和神經元構建各種大型模型,如下圖所示。在本例中,一個3×4的拼接配置是與各個拼接之間的模擬和數字結構縫合在一起的,數據可以通過共享總線從一個tile移動到另一個tile。
到目前為止,我們主要討論了該體系結構的硅實現過程。軟件開發工具包(SDK)的可用性(圖9)有助于解決方案的部署。除了硅之外,SDK還促進了推理引擎的部署。
SDK與培訓框架無關。用戶可以在任何可用的框架(如TensorFlow、PyTorch或其他框架)中使用浮點計算創建神經網絡模型。一旦創建,SDK幫助量化訓練過的神經網絡模型,并將其映射到內存數組中,在內存數組中,向量-矩陣乘法可以用來自傳感器或計算機的輸入向量進行。
結論
這種具有內存計算能力的多級內存方法的優點:
1.超低功耗:該技術專為低功耗應用而設計。
第一級的功耗優勢來自于內存計算,因此在計算期間不會在數據和從SRAM/DRAM傳輸的權值中浪費能量。
第二個能量優勢來自于閃存單元在亞閾值模式下運行,電流值非常低,所以有源功耗非常低。
第三個優點,由于非易失性存儲單元不需要任何能量來保存數據,所以在待機模式下幾乎沒有能量消耗。該方法也非常適合于利用權值和輸入數據的稀疏性。如果輸入數據或權值為零,則不會激活內存位單元。
2.更低的封裝引腳
該技術使用分裂門(1.5T)單元架構,而數字實現中的SRAM單元基于6T架構。此外,與6T SRAM單元相比,該單元要小得多。另外,一個電池可以存儲4位整數值,而SRAM電池需要4*6 = 24個晶體管才能存儲整數值。這提供了更小的芯片占用空間。
3.更低的開發成本
由于內存性能瓶頸和馮諾依曼架構的限制,許多專用設備(如Nvidia的Jetsen或谷歌的TPU)傾向于使用更小的幾何圖形來獲得每瓦的性能,這是解決邊緣AI計算挑戰的一種昂貴方式。隨著多級存儲器方法使用模擬存儲器上的計算方法,計算在閃存芯片上完成,因此可以使用更大的幾何圖形,并減少掩模成本和前置時間。
由此可看,邊緣計算應用程序顯示了巨大的潛力。然而,在邊緣計算能夠騰飛之前,還有一些功率和成本方面的挑戰需要解決。通過使用在閃存單元中執行芯片上計算的內存方法,可以消除其中的主要障礙。這種方法利用了經過生產驗證的、事實上標準類型的多級內存技術解決方案,該解決方案針對機器學習應用程序進行了優化。
Vipin Tiwari
延伸閱讀——Microchip-SST神經形態存儲解決方案memBrain
Microchip公司通過其硅存儲技術(SST)子公司,通過其模擬存儲器技術memBrain神經形態存儲器解決方案降低功耗,從而應對這一挑戰。
該公司的模擬閃存解決方案基于其Superflash技術并針對神經網絡進行了優化以執行矢量矩陣乘法(VMM),通過模擬內存計算方法改善了VMM的系統架構實現,增強了邊緣的AI推理。
由于當前的神經網絡模型可能需要50M或更多的突觸(權重)進行處理,因此為片外DRAM提供足夠的帶寬變得具有挑戰性,從而造成神經網絡計算的瓶頸和整體計算能力的提高。相比之下,memBrain解決方案將突觸權重存儲在片上浮動門中,從而顯著改善系統延遲。與傳統的基于數字DSP和SRAM / DRAM的方法相比,它可以降低10到20倍的功耗并降低整體BOM。
“ 隨著汽車,工業和消費者市場的技術提供商繼續為神經網絡實施VMM,我們的架構可幫助這些前向解決方案實現功耗,成本和延遲優勢, ”SST許可部門副總裁Mark Reiten表示。“ Microchip將繼續為AI應用提供高度可靠和多功能的Superflash內存解決方案。“
今天的公司正在采用memBrain解決方案來提高邊緣設備的ML容量。由于具有降低功耗的能力,這種模擬內存計算解決方案非常適合任何AI應用。
“ Microchip的memBrain解決方案為我們即將推出的模擬神經網絡處理器提供超低功耗的內存計算, ” Syntiant公司首席執行官Kurt Busch 說道。 “ 我們與Microchip的合作繼續為Syntiant提供許多關鍵優勢,因為我們支持普遍的ML邊緣設備中語音,圖像和其他傳感器模式的永遠在線應用。“
SST展示了這種模擬存儲器解決方案,并在FMS上展示了Microchip的基于memBrain產品區塊陣列的架構。
池化層理解
池化層夾在連續的卷積層中間, 用于壓縮數據和參數的量,減小過擬合。簡而言之,如果輸入是圖像的話,那么池化層的最主要作用就是壓縮圖像。
池化層的作用:
1. invariance(不變性),這種不變性包括translation(平移),rotation(旋轉),scale(尺度)
2. 保留主要的特征同時減少參數(降維,效果類似PCA)和計算量,防止過擬合,提高模型泛化能力
-
內存
+關注
關注
8文章
3074瀏覽量
74467 -
AI
+關注
關注
87文章
32023瀏覽量
270915 -
機器學習
+關注
關注
66文章
8458瀏覽量
133229
發布評論請先 登錄
相關推薦
AI賦能邊緣網關:開啟智能時代的新藍海
【新品體驗】幸狐Omni3576邊緣計算套件免費試用
研華科技邊緣AI平臺榮獲2024年IoT邊緣計算卓越獎
羅克韋爾自動化助您向可持續性生產目標邁進
NVIDIA IGX平臺加速實時邊緣AI應用

平衡創新與倫理:AI時代的隱私保護和算法公平
邊緣AI需求爆發,邊緣計算網關亟待革新
邊緣AI網關,將具備更強大的計算和學習能力
如何基于OrangePi?AIpro開發AI推理應用

ai邊緣盒子有哪些用途?ai視頻分析邊緣計算盒子詳解

邊緣側AI芯片提供商超星未來完成數億元 Pre-B輪融資
三星電子瞄準邊緣計算市場,計劃2025年推出AI加速器芯片Mach-1
英特爾發布全新邊緣計算平臺,解決AI邊緣落地難題






 工商網監
工商網監
評論