 一個學習何時做分類決策的強化學習模型:Jumper
一個學習何時做分類決策的強化學習模型:Jumper

文本理解是自然語言處理領域的一個核心目標,最近取得了一系列的進展,包括機器翻譯、問答等。不過之前的工作大多數是關心最終的效果,而人們對于模型何時做出決定(或做決定的原因)卻知之甚少,這是一個對于理論研究和實際應用都非常重要的課題。深度好奇(DeeplyCurious.AI) 最近在IJCAI-2018上展示了一個學習何時做分類決策的強化學習模型:Jumper, 該論文將文本分類問題建模成離散的決策過程,并通過強化學習來優化,符號化表征模型的決策過程具有很好的可解釋性,同時分類效果也達到最高水平。
本文提供了一種新的框架,將文本理解建模為一個離散的決策過程。通常在閱讀過程中,人們尋找線索、進行推理,并從文本中獲取信息;受到人類認知過程的啟發,我們通過將句子逐個地遞送到神經網絡來模仿這個過程。在每個句子中,網絡基于輸入做出決策(也稱為動作),并且在該過程結束時,該決策序列可以視為是對文本有了一些“理解”。
特別一提的是,我們專注于幾個預定義子任務的文本分類問題。當我們的神經網絡讀取一個段落時,每個子任務在開始時具有默認值“無”(None)。 在每個決策步驟中,段落的句子按順序被遞送到神經網絡;之后,網絡來決定是否有足夠的信心“跳轉”到非默認值作為特定時間的預測。我們施加約束,即每次跳轉都是最終決定,它不可以在后面的閱讀中被更改。如圖1所示,給定一段話,有多個預先定義好的問題等待回答;模型按句子閱讀,在閱讀過程中,問題的答案陸續被找到。模型從默認決策到非默認決策都是一個“跳轉”的過程,正因此我們稱模型為Jumper。在人類閱讀的過程中,人們通常會獲得一致的閱讀理解的結果,但是閱讀理解過程中的很多環節卻經常是微妙和難以捉摸的。同樣,我們也假設我們的訓練標簽僅包含最終結果,并且沒有給出關于模型應該做出決定的步驟的監督信號。也就是說,我們通過強化學習在弱監督信號情況下訓練Jumper模型。
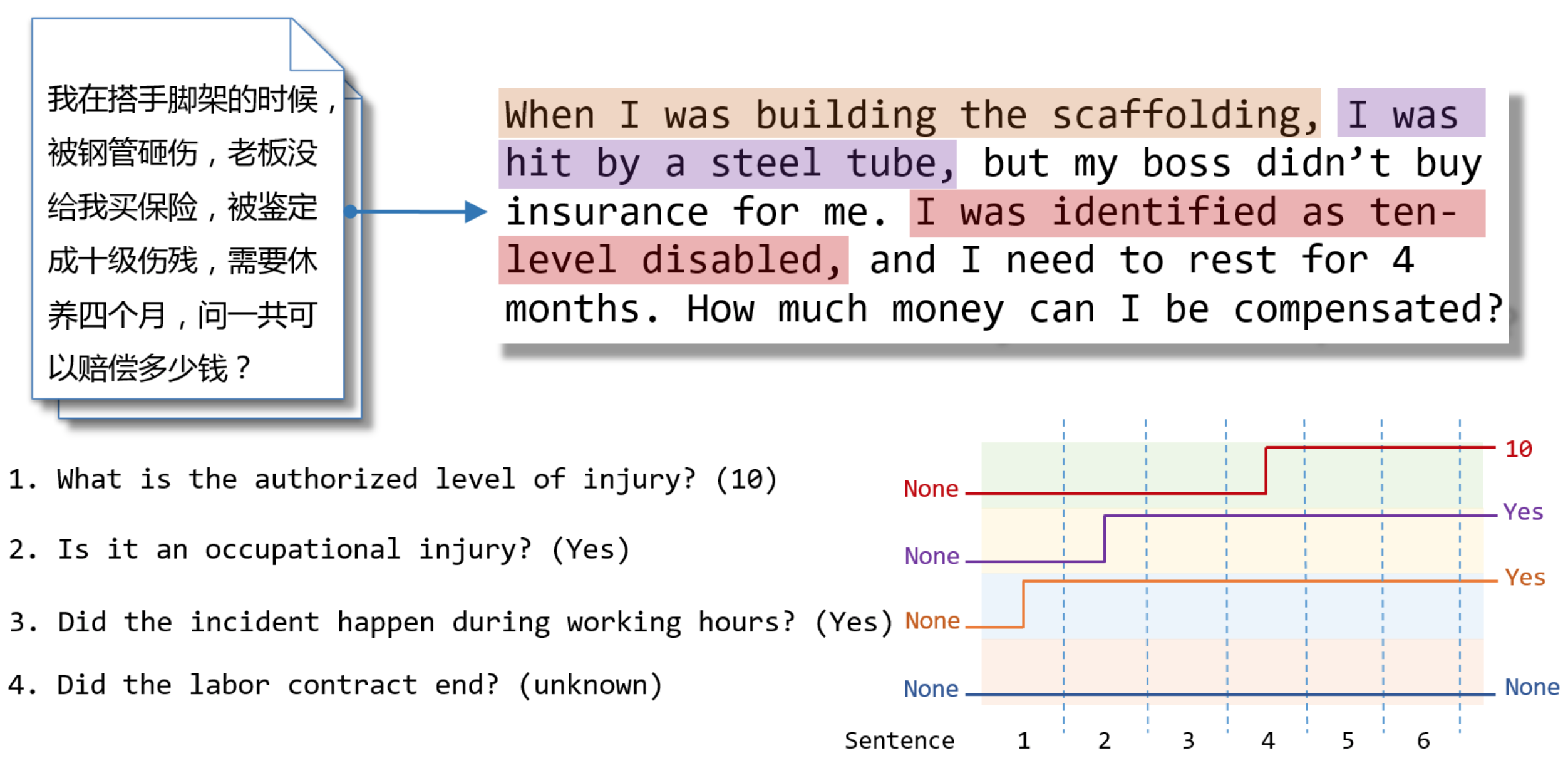
圖1 Jumper模型在閱讀段落的決策過程
Jumper模型主要由編碼層、控制器、符號輸出層構成。編碼層將句子編碼成定長的向量,控制器根據歷史和當前輸入產生當前的決定,符號輸出層使模型的輸出滿足跳轉約束,即每個決策過程最多只能有一次跳轉。

圖2 Jumper模型的基本框架
跳轉約束的作用在于使模型更加慎重地決定何時跳轉。因此,Jumper模型的優化目標有兩個,第一個是盡可能早地“跳轉”,第二個是盡可能預測準。假設t* 是最佳的跳轉時間,那么如果模型在t* 時刻之前跳轉,則模型還沒有看到真正的pattern,那么得到的答案等同于隨機猜;如果模型在t* 時刻之后跳轉,而t* +1句話可能不存在,因此沒有機會跳轉從而預測錯誤。
通過上述建模,論文把文本分類問題轉化為離散的決策過程,訓練好的Jumper輸出的離散決策過程就可以表達模型對文本的理解過程;而決策過程本身并沒有標簽,因此我們用policy gradient強化學習算法來訓練,如果最終的決定和分類標簽一致,就獎勵整個決策動作,如果不一致,則懲罰。
我們對三個任務評估了Jumper,包括兩個基準數據集和一個實際工業應用。我們首先分析了Jumper的分類準確性,并與幾個基線進行了比較。表1顯示Jumper在所有這些任務上實現了相當或更好的性能,這表明將文本分類建模為順序決策過程不僅不會損害、甚至提高了分類準確性。

表1 在電影評論數據集(MR)、新聞數據集(AG)和工傷數據集(OI)的測試集上的準確率
我們想指出,“準確性”并不是我們關注的唯一表現。更重要的是,提出的模型能夠減少閱讀過程,或者找到文本分類的關鍵支撐句。只要在閱讀過程中基于“跳轉約束”限制而看到足夠的證據,Jumper就能做出決定,并且在預測之后不需要再閱讀之后的句子。在表2中可以看到,我們的模型與強基線相比達到了相似或更高的性能,與此同時,它還將文本讀取的長度縮減了30-40%,從而加速了推斷預測。

表2
除了準確率高和推斷速度快以外,我們更好奇Jumper是否能夠在信息提取式任務(例如工傷級別分類任務)中找到正確的位置做出決策。我們在400個數據點中標注關鍵支撐句(即最佳跳轉位置)作為測試基礎。需要注意的是,在這個實驗中我們仍然沒有跳轉位置的訓練標簽。我們將Jumper與使用相同神經網絡的層級CNN-GRU模型進行比較,但在訓練方法方面有所不同;層級CNN-GRU在訓練時,用段落末尾的交叉熵作為損失函數。在測試期間,我們將預測器應用于每個步驟并找到它做出預測的第一個位置。我們還列出了一個經典CNN的結果作為基線模型,并使用了最大池化操作(max-pooling)選擇的單詞最多的那些句子來作為測試數據。我們使用了跳轉動作的準確率來評測Jumper。通過表3可知,Jumper準確地找到了測試集中所有關鍵支撐句的位置,說明我們的單跳約束迫使模型更仔細地思考何時做出決策,也驗證了強化學習是學習決策正確位置的有效方法。

表3 各模型在工傷等級分類任務(OI-Level)上尋找關鍵支撐句的效果統計。該任務的關鍵支撐句在文本中通常聚集于一處,不存在歧義,便于衡量各模型效果。CA:分類準確率,JA:跳躍準確率,OA:在分類準確條件下的跳躍準確率
圖3則顯示了Jumper在閱讀時做出決策的過程。其中,Jumper在前六個句子中保持默認決策(不做跳轉),而在到達關鍵支撐句時突然跳轉,這體現了Jumper可以識別關鍵支撐句,從而找到最佳跳躍位置。因此,在這類關鍵支撐語句集中出現時,Jumper可以在完成分類任務的同時找到關鍵支撐句,因此具有較強的可解釋性。
圖3 Jumper決策序列展示
總結
我們提出了一種新的模型Jumper,它在閱讀段落時將文本分類建模為逐個句子的順序決策過程。我們通過強化學習訓練帶有跳轉約束的Jumper,實驗表明:1) Jumper的性能與基線相當或更高;2) 它在很大程度上減少了文本閱讀量;3) 如果所需信息在文中的分布是局域性的,它可以找到關鍵的支撐句子,具有很好的可解釋性。
-
控制器
+關注
關注
114文章
17082瀏覽量
183951 -
機器翻譯
+關注
關注
0文章
140瀏覽量
15181 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14136
發布評論請先 登錄
18個常用的強化學習算法整理:從基礎方法到高級模型的理論技術與代碼實現

基于RV1126開發板實現自學習圖像分類方案

詳解RAD端到端強化學習后訓練范式

淺談適用規模充電站的深度學習有序充電策略
螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
主動學習在圖像分類技術中的應用:當前狀態與未來展望






 工商網監
工商網監
評論