") Adversarial T-shirt可讓你在AI目標(biāo)檢測系統(tǒng)中“消失無形”
Adversarial T-shirt可讓你在AI目標(biāo)檢測系統(tǒng)中“消失無形”

基于 AI 目標(biāo)檢測系統(tǒng)生成的對抗樣本可以使穿戴者面對攝像頭「隱身」。
由美國東北大學(xué)林雪研究組,MIT-IBM Watson AI Lab 和 MIT 聯(lián)合研發(fā)的這款基于對抗樣本設(shè)計(jì)的 T-shirt (adversarial T-shirt),讓大家對當(dāng)下深度神經(jīng)網(wǎng)絡(luò)的現(xiàn)實(shí)安全意義引發(fā)更深入的探討。目前該文章已經(jīng)被 ECCV 2020 會議收錄為 spotlight paper(焦點(diǎn)文章)。
在人臉識別和目標(biāo)檢測越來越普及的今天,如果說有一件衣服能讓你在 AI 檢測系統(tǒng)中「消失無形」,請不要感到驚訝。
熟悉Adversarial Machine Learning(對抗性機(jī)器學(xué)習(xí))的朋友可能不會覺得陌生,早在 2013 年由 Christian Szegedy 等人就在論文 Intriguing properties of neural networks 中首次提出了 Adversarial Examples(對抗樣本)的概念。而下面這張將大熊貓變成長臂猿的示例圖也多次出現(xiàn)在多種深度學(xué)習(xí)課程中。
很顯然,人眼一般無法感知到對抗樣本的存在,但是對于基于深度學(xué)習(xí)的 AI 系統(tǒng)而言,這些微小的擾動卻是致命的。
隨著科研人員對神經(jīng)網(wǎng)絡(luò)的研究,針對神經(jīng)網(wǎng)絡(luò)的 Adversarial Attack(對抗攻擊)也越來越強(qiáng)大,然而大多數(shù)的研究還停留在數(shù)字領(lǐng)域?qū)用妗iajun Lu 等人也在 2017 年認(rèn)為:現(xiàn)實(shí)世界中不需要擔(dān)心對抗樣本(NO Need to Worry about Adversarial Examples in Object Detection in Autonomous Vehicles)。
他們通過大量實(shí)驗(yàn)證明,單純地將在數(shù)字世界里生成的對抗樣本通過打印再通過相機(jī)的捕捉,是無法對 AI 檢測系統(tǒng)造成影響的。這也證明了現(xiàn)實(shí)世界中的對抗樣本生成是較為困難的,主要原因歸于以下幾點(diǎn):
像素變化過于細(xì)微,無法通過打印機(jī)表現(xiàn)出來:我們熟知的對抗樣本,通常對圖像修改的規(guī)模有一定的限制,例如限制修改像素的個(gè)數(shù),或總體像素修改大小。而打印的過程往往無法對極小的像素值的改變做出響應(yīng),這使得很多對于對抗樣本非常有用的信息通過打印機(jī)的打印損失掉了。
通過相機(jī)的捕捉會再次改變對抗樣本:這也很好理解,因?yàn)橄鄼C(jī)自身成像的原理,以及對目標(biāo)捕捉能力的限制,相機(jī)無法將數(shù)字領(lǐng)域通過打印得到的結(jié)果再次完美地還原回?cái)?shù)字領(lǐng)域。
環(huán)境和目標(biāo)本身發(fā)生變化:這一點(diǎn)是至關(guān)重要的。對抗樣本在生成階段可能只考慮了十分有限的環(huán)境及目標(biāo)的多樣性,從而該樣本在現(xiàn)實(shí)中效果會大大降低。
近年來,Mahmood Sharif 等人(Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition.)首次在現(xiàn)實(shí)世界中,通過一個(gè)精心設(shè)計(jì)的眼鏡框,可以人臉檢測系統(tǒng)對佩戴者做出錯(cuò)誤的判斷。但這項(xiàng)研究對佩戴者的角度和離攝像頭的距離都有嚴(yán)格的要求。之后 Kevin Eykholt 等人(Robust Physical-World Attacks on Deep Learning Visual Classification)對 stop sign(交通停止符號)進(jìn)行了攻擊。通過給 stop sign 上面貼上生成的對抗樣本,可以使得 stop sign 被目標(biāo)檢測或分類系統(tǒng)識別成限速 80 的標(biāo)志!這也使得社會和媒體對神經(jīng)網(wǎng)絡(luò)的安全性引發(fā)了很大的探討。
然而,這些研究都還沒有觸及到柔性物體的對抗樣本生成。可以很容易地想象到,鏡框或者 stop sign 都是典型的剛性物體,不易發(fā)生形變且這個(gè)類別本身沒有很大的變化性,但是 T 恤不同,人類自身的姿態(tài),動作都會影響它的形態(tài),這對攻擊目標(biāo)檢測系統(tǒng)的人類類別產(chǎn)生了很大的困擾。
最近的一些工作例如 Simen Thys 等人(Fooling automated surveillance cameras: adversarial patches to attack person detection)通過將對抗樣本打印到一個(gè)紙板上掛在人身前也可以成功在特定環(huán)境下攻擊目標(biāo)檢測器,但是卻沒有 T 恤上的圖案顯得自然且對對抗樣本的形變和運(yùn)動中的目標(biāo)沒有進(jìn)行研究。
來自美國東北大學(xué),MIT-IBM Watson AI Lab 和 MIT 聯(lián)合研發(fā)的這款 Adversarial T-shirt 試圖解決上述問題,并在對抗 YOLOV2 和 Faster R-CNN(兩種非常普及的目標(biāo)檢測系統(tǒng))中取得了較好的效果。通過采集實(shí)驗(yàn)者穿上這件 Adversarial T-shirt 進(jìn)行多個(gè)場景和姿態(tài)的視頻采集,在 YOLOV2 中,可以達(dá)到 57% 的攻擊成功率,相較而言,YOLOV2 對沒有穿 Adversarial T-shirt 的人類目標(biāo)的檢測成功率為 97%。
設(shè)計(jì)原理
從多個(gè)已有的成功的攻擊算法中得到啟發(fā),研究者們通過一種叫 EOT (Expectation over Transformation) 的算法,將可能發(fā)生在現(xiàn)實(shí)世界中的多種 Transformation(轉(zhuǎn)換)通過模擬和求期望來擬合現(xiàn)實(shí)。這些轉(zhuǎn)換一般包括:縮放、旋轉(zhuǎn)、模糊、光線變化和隨機(jī)噪聲等。利用 EOT,我們可以對剛性物體進(jìn)行對抗樣本的生成。
但是當(dāng)研究者們僅僅使用 EOT,將得到的對抗樣本打印到一件 T 恤上時(shí),僅僅只能達(dá)到 19% 的攻擊成功率。這其中的主要原因就是文章上述提到的,人類的姿態(tài)會使對抗樣本產(chǎn)生褶皺,而這種褶皺是無法通過已有的 EOT 進(jìn)行模擬的。而對抗樣本自身也是非常脆弱的,一旦部分信息丟失往往會導(dǎo)致整個(gè)樣本失去效力。
基于以上觀察,研究者們利用一種叫做 thin plate spline (TPS) 的變化來模擬衣服的褶皺規(guī)律。這種變化需要記錄一些 anchor points(錨點(diǎn))數(shù)據(jù)來擬合變化。于是研究者將一個(gè)棋盤格樣式的圖案打印到 T 恤上來記錄棋盤格中的每個(gè)方塊角的坐標(biāo)信息,如下圖所示:

這些錨點(diǎn)的坐標(biāo)可以通過特定的算法自動得到無需手動標(biāo)記。這樣一個(gè)人工構(gòu)建的 TPS 變化被加入了傳統(tǒng)的 EOT 算法。這使得生成的對抗樣本具備抗褶皺擾動的能力。
除此之外,研究者們還針對光線和攝像頭可能引起的潛在變化利用一種色譜圖進(jìn)行的模擬,如下圖所示:(a)數(shù)字領(lǐng)域中的色譜圖;(b)該圖通過打印機(jī)打印到 T 恤只會在通過相機(jī)捕捉到的結(jié)果;(c)通過映射 a-b 學(xué)到的一種色彩變換。

基于學(xué)習(xí)出的色彩變化系統(tǒng),使得生成的對抗樣本能最大限度的接近現(xiàn)實(shí)。最終該方法的整體框架如下:
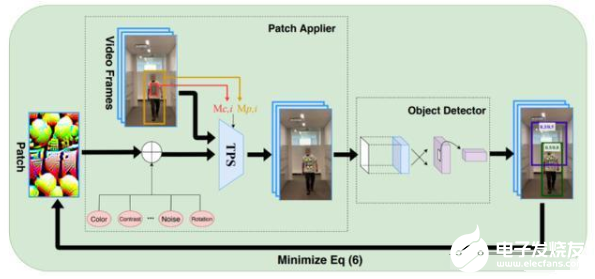
通過增強(qiáng)的 EOT 和顏色轉(zhuǎn)換系統(tǒng),最小化 YOLOV2 的檢測置信度,最終得到一個(gè)對抗樣本。
除此之外,研究者們也第一次嘗試了 ensemble attack (多模型攻擊)。利用一張對抗樣本同時(shí)攻擊兩個(gè)目標(biāo)檢測系統(tǒng) YOLOV2 和 Faster R-CNN。結(jié)果顯示不同于傳統(tǒng)的加權(quán)平均的攻擊方,利用魯棒優(yōu)化技術(shù)可以提高對兩個(gè)目標(biāo)檢測系統(tǒng)的平均攻擊成功率。
實(shí)驗(yàn)結(jié)果
首先,研究者們在數(shù)字領(lǐng)域做了基礎(chǔ)的比較試驗(yàn),結(jié)果發(fā)現(xiàn)相較于非剛性變化—仿射變換,TPS 變化可以將攻擊成功率在 YOLOV2 上從 48% 提升到 74%,在 Faster R-CNN 上由 34% 提升到 61%!這證明了對于柔性物體,加入 TPS 變化的必要性。
之后研究人員將這些對抗樣本打印到白色 T 恤上,讓穿戴者在不同場合以各種姿態(tài)移動并對其錄制視頻。最后將采集到的所有視頻送入目標(biāo)檢測系統(tǒng)進(jìn)行檢測,統(tǒng)計(jì)攻擊成功率。
如下面的動圖所示:

最終,在現(xiàn)實(shí)世界中,該方法利用 TPS 生成的樣本對抗 YOLOV2 可以達(dá)到 57% 的攻擊成功率,相較而言,僅使用仿射變換只能達(dá)到 37% 攻擊成功率。
除此之外,研究者們還做了非常詳盡的 ablation study:針對不同場景,距離,角度,穿戴者姿勢進(jìn)行研究。
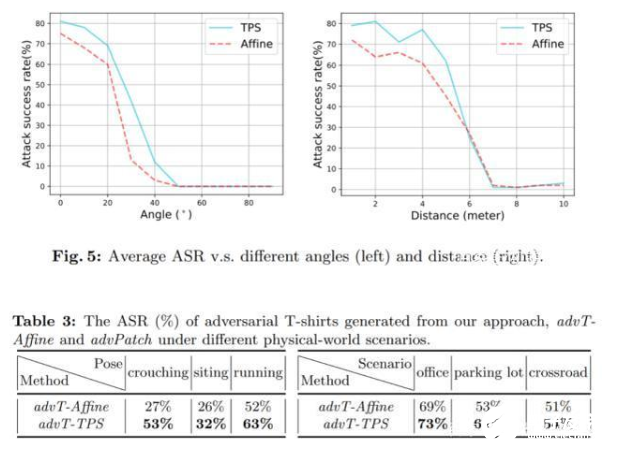
結(jié)果顯示,提出的方法對距離的遠(yuǎn)近和角度變化較為敏感,對不同的穿戴者和背景環(huán)境變化表現(xiàn)出的差異不大。
關(guān)于 AI 安全的更多討論
生成對抗樣本其實(shí)和深度神經(jīng)網(wǎng)絡(luò)的訓(xùn)練是同根同源的。通過大量樣本學(xué)習(xí)得到的深度神經(jīng)網(wǎng)絡(luò)幾乎是必然的存在大量的對抗樣本。就像無數(shù)從事 Adversarial Machine Learning(對抗性機(jī)器學(xué)習(xí))的研究者一樣,大家充分意識到了神經(jīng)網(wǎng)絡(luò)的脆弱性和易攻擊性。但是這并沒有阻礙我們對深度學(xué)習(xí)的進(jìn)一步研究和思考,因?yàn)檫@種特殊且奇妙的現(xiàn)象來源于神經(jīng)網(wǎng)絡(luò)本身,且形成原因至今沒有明確的定論。而如何構(gòu)建更加魯棒的神經(jīng)網(wǎng)絡(luò)也是目前該領(lǐng)域的 open issue。
該研究旨在通過指出這種特性,以及它有可能造成的社會潛在危害從而讓更多的人意識到神經(jīng)網(wǎng)絡(luò)的安全問題,最終目的是幫助 AI 領(lǐng)域構(gòu)建更加魯棒的神經(jīng)網(wǎng)絡(luò)從而可以對這些對抗樣本不再如此敏感。
-
檢測系統(tǒng)
+關(guān)注
關(guān)注
3文章
974瀏覽量
43805 -
AI
+關(guān)注
關(guān)注
88文章
34784瀏覽量
277182 -
隱身技術(shù)
+關(guān)注
關(guān)注
1文章
10瀏覽量
7974
發(fā)布評論請先 登錄
軒轅智駕紅外目標(biāo)檢測算法在汽車領(lǐng)域的應(yīng)用
睿創(chuàng)微納推出新一代目標(biāo)檢測算法
AI智能質(zhì)檢系統(tǒng) 工業(yè)AI視覺檢測
AI Cube進(jìn)行yolov8n模型訓(xùn)練,創(chuàng)建項(xiàng)目目標(biāo)檢測時(shí)顯示數(shù)據(jù)集目錄下存在除標(biāo)注和圖片外的其他目錄如何處理?
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測模型
直播報(bào)名丨第4講:AI檢測系統(tǒng)落地工具詳解

直播報(bào)名丨第2講:熱門AI檢測案例解析
在目標(biāo)檢測中大物體的重要性

圖像分割與目標(biāo)檢測的區(qū)別是什么
目標(biāo)檢測與圖像識別的區(qū)別在哪
目標(biāo)檢測與識別技術(shù)有哪些
目標(biāo)檢測與識別技術(shù)的關(guān)系是什么
目標(biāo)檢測識別主要應(yīng)用于哪些方面
慧視小目標(biāo)識別算法 解決目標(biāo)檢測中的老大難問題






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論