 典型AI運算的功耗最多可減少75%?
典型AI運算的功耗最多可減少75%?
像Nvidia這樣的芯片巨頭可以負擔得起7nm技術,但初創公司和其他規模較小的公司卻因為復雜的設計規則和高昂的流片成本而掙扎不已——所有這些都是為了在晶體管速度和成本方面取得適度的改善。格芯的新型12LP+技術提供了一條替代途徑,通過減小電壓而不是晶體管尺寸來降低功耗。格芯還開發了專門針對AI加速而優化的新型SRAM和乘法累加(MAC)電路。其結果是,典型AI運算的功耗最多可減少75%。Groq和Tenstorrent等客戶已經利用初代12LP技術獲得了業界領先的結果,首批采用12LP+工藝制造的產品將于今年晚些時候流片。
為了實現這些結果,格芯(GF)采取了整體方法來加速AI運算,特別是推理卷積神經網絡(CNN)。此工作負載非常依賴MAC運算,但格芯發現,大部分功耗實際上用在從本地SRAM讀取數據并將其傳輸到MAC單元上。新的SRAM設計大大降低了CNN和其他經常訪問長數據向量的應用的功耗。新的MAC針對大多數AI加速器的較小數據類型和較低時鐘速度而設計,這也有助于節省功耗。SRAM單元中的成對晶體管經過重新設計以提高匹配度,使電壓得以降低,從而減小所需的電壓裕量。
格芯在放棄7nm及更小線寬技術的計劃之后轉而選擇了這條道路,專注于FD-SOI、SiGe和其他差異化技術(參見MPR 8/13/18,“格芯新戰略”)。12LP+和AI方面的努力就是其差異化戰略的又一例證。這種方法的優勢在某些方面要比7nm更大,但成本更低。以前,這家晶圓廠專注于制造AMD公司的高性能CPU,但隨著AMD將其業務轉移至臺積電,修訂后的戰略已幫助格芯吸引到新客戶。
為AI而設計
在典型的高性能CPU中,本地SRAM每周期提供一個完整的緩存行,然后CPU通過多路復用器(mux)選擇所需的字。例如,使用256位緩存行的64位CPU需要一個4:1多路復用器,如圖1(a)所示。在這種情況下,即使CPU每個周期僅使用64位,SRAM陣列中的所有256位緩存行也會在每次訪問時放電。這種方法最大程度地減小了SRAM延遲,從而有可能提高最大時鐘速度或減少流水線級數——這二者都是影響CPU性能的關鍵因素。
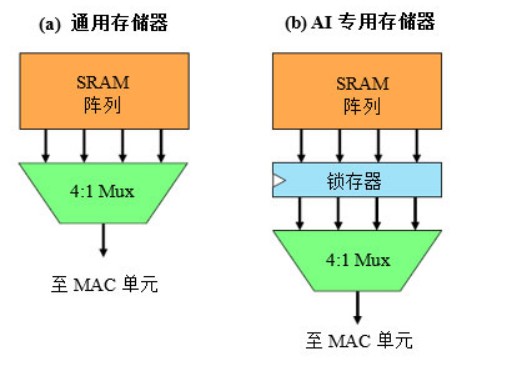
圖1. 格芯AI專用存儲器。通用陣列最大程度地減小了隨機存取的延遲。添加鎖存器會增加延遲,但會降低順序存取的功耗。?
AI加速器通常以比PC處理器低的時鐘速度運行,其設計師更關心吞吐量而不是延遲。此外,CPU通常具有隨機存取模式,但CNN產生的則是順序存儲器存取,其處理的向量常常具有數以百計或數以千計的元素。為了更好地支持這些設計,格芯在SRAM陣列和多路復用器之間添加了一個鎖存器,如圖1(b)所示。這樣做會給讀取路徑增加一個周期,CPU設計師絕不會接受這種做法,但它為AI加速器帶來了可觀的好處。
首先,鎖存器將多路復用器與陣列解耦,從而減小位緩存行上的電容,進而降低每次SRAM存取的功耗。但更大的好處是,在讀操作之后,完整的256位輸出仍位于鎖存器中。如果隨后的讀操作訪問下一個遞增存儲器地址,那么可以從鎖存器中讀取該值,而根本無需驅動陣列。對于從很長的一系列順序地址讀取數據的程序,此設計只需在25%的時間內為SRAM陣列供電。考慮到包括多路復用器和鎖存器的整個電路,格芯估計:相對于標準編譯的SRAM,CNN工作負載的功耗可降低53%。由于時序約束變得寬松,新的SRAM也縮小了25%。
盡管MAC單元的功耗僅占總功耗的一小部分,但其面積常常占總芯片面積的最大部分。新設計具有一個16x16位乘法器,與高端CPU所需的64位設計不同。基數為4的Booth乘法器饋入一個48位加法器,以進行高精度累加。對于CNN推理中常見的8位整數(INT8)數據,可以將MAC單元拆分為每個周期產生兩個8x8乘法,并進行24位累加。格芯的目標工作頻率為1.0GHz,物理設計因而得以簡化,功耗和芯片面積得以減小。新的MAC單元比之前的12LP單元小12%;在相同電壓下都以1.0GHz運行時,所需的功耗減少25%。
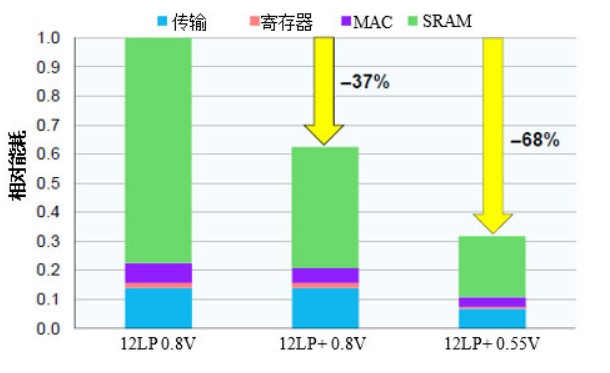
圖2. 12LP+的能耗降幅。在典型的脈動MAC陣列中,新的SRAM和MAC設計使總功耗比之前的12LP技術降低了三分之一,而降低工作電壓又使總功耗降低了三分之一。
為減小電壓而付出的大量工作
為了進一步降低功耗,格芯在工作電壓上狠下功夫。無論什么節點,一個重要挑戰是管理晶體管的制造偏差。柵極和溝道在形狀、厚度或摻雜上的微小差異可能會改變晶體管的功函數(衡量電子移動通過材料所需能量的參數)。功函數會修改閾值電壓,從而決定晶體管何時切換狀態。對于給定工藝,晶圓廠會將工作電壓設置得足夠高,以確保芯片上的所有晶體管都能可靠地開關,即它必須超過最壞情況下的閾值電壓。
為了應對這一挑戰,12LP+增加了雙功函數晶體管。此技術原本是為7nm工藝而開發的,格芯將其移植到了12nm節點中。新設計以不同方式摻雜NMOS和PMOS晶體管,以便更好地平衡其功函數。這種方法會使成本略有增加,但大大降低了所需的裕量:對于1.0GHz的目標頻率,SRAM的工作電壓從12LP的0.7V降至12LP+的0.55V。12LP邏輯的標稱電壓為0.8V,欠驅電壓為0.7V,但在12LP+中,它也可以采用0.55V工作。由于功耗與電壓的平方成比例,因此這些變化可以使功耗減半。
SRAM是主要的耗電器件,所以格芯專注于開發低壓存儲器單元。測試芯片顯示,即使在0.45V電壓下,新型LVSRAM的良率仍超過95%,這意味著設計在0.55V電壓下具有充足的裕量。為使邏輯功能受益,格芯委托Arm的物理知識產權(physical-IP)小組為12LP+工藝創建了一個完整的低壓標準單元庫。該庫定于9月上市,客戶可利用它來構建完整的AI加速器以讓SRAM和MAC單元采用0.55V電壓工作。
新技術的總節電效果非常顯著。格芯對MAC單元的脈動陣列(這是CNN加速的常見配置)的功耗進行了仿真。仿真讀取權重和激活(圖2中顯示為SRAM功耗),讓數據移動通過脈動陣列(傳輸),然后執行計算(MAC)。相對于基本設計,新的MAC單元和鎖存SRAM使總能耗減少了三分之一以上,而傳輸能耗保持不變。以0.55V電壓工作會產生一個全面的大壓降,使該設計的總節電量達到68%。
與往常一樣,格芯通過廣泛的物理元件庫(包括數字、模擬和無源器件)來支持12LP+工藝。格芯提供EDA工具(如Cadence和Synopsys插件)、Spice模型、設計規則檢查器、時序模型以及布局布線功能。為了提高良率,格芯提供了完整的可制造性設計(DFM)流程。格芯已針對12LP+重新優化了12LP物理IP,包括存儲器和I/O接口。除了Arm的低壓標準單元庫外,Rambus和Synopsys等第三方IP供應商也支持12LP+。
助力AI領先公司
這項新技術建立在格芯成功的12LP工藝基礎上,為行業領先的AI產品提供助力。例如,硅谷初創公司Groq開發了一種新的架構方法來加速集數百個功能單元于單個核心中的神經網絡。龐大的設計包括220MB的SRAM和200,000以上的MAC單元(參見MPR 1/6/20,“Groq撼動神經網絡”)。Groq采用12LP使如此大型設計的功耗保持在300W的預算之內。該芯片以1.0GHz的初始速度,對INT8數據實現了每秒820萬億次運算(TOPS)的峰值吞吐量,超過了所有其他已發布的加速器。
加拿大初創公司Tenstorrent也加快了推理速度,但它選擇了一個不同的設計目標:總線供電的PCIe卡的功耗限值為75W。其第一款芯片具有120個獨立的核心,每個核心包含1MB的SRAM和大約500個MAC單元。這種方法仍然需要大量的SRAM和MAC單元。該芯片以1.3GHz的初始速度可提供368 TOPS(參見MPR 4/13/20,“Tenstorrent提升AI性能”)。12LP技術幫助Tenstorrent實現了每瓦4.9 TOPS的性能,這一效率在數據中心產品中遙遙領先,如圖3所示。
在這個市場上占有最大份額的Nvidia最近發布了基于新型Ampere架構的A100加速器。Ampere引入了許多創新特性,峰值性能提高到624 TOPS,超過了除Groq之外的所有已發布芯片。然而,盡管采用7nm工藝,但A100仍需要400W TDP,比之前的12nm產品還高33%。為了適應功耗預算的增加,Nvidia不得不降低時鐘速度(相對于12nm產品),并禁用芯片上15%的核心。這是一種不尋常的策略,可能意味著芯片功耗大大高于仿真功耗(參見MPR 6/8/20,“Nvidia A100稱霸AI性能”)。因此,雖然A100的晶體管較小,但其每瓦性能嚴重落后于Groq和Tenstorrent芯片。
與格芯的12nm工藝相比,臺積電7nm工藝的一個優點是晶體管密度增加一倍,使得Nvidia可將超過500億個晶體管封裝到A100中。為了幫助客戶在這方面競爭,格芯支持各種小芯片方法。格芯在多芯片封裝方面擁有豐富的經驗,包括具有高帶寬存儲器(HBM)的2.5D硅中介層設計。針對3D芯片堆疊,格芯已開發出混合晶圓鍵合(HWB)技術,其使用間距為5.76微米的硅通孔(TSV),并有密度提升的路線圖。對于低密度互連,客戶可以在便宜的有機襯底上構建小芯片配置,類似于AMD的Rome處理器。這些小芯片方法中的任何一種都能在不遷移到7nm工藝的情況下實現很高的晶體管數量。
價格和供貨情況
格芯的12LP+技術已可用于設計啟動。我們預計量產將從2021年下半年開始。
優于7nm
臺積電聲稱,相對于其10nm節點,其7nm技術可使時鐘速度提高多達20%,功耗降低多達40%(參見MPR 5/20/19,“EUV工藝實現量產”)。但是,這些最佳情況下的數字都假定晶體管的負載很輕。復雜的處理器設計通常受限于金屬電容而不是晶體管速度,因此只能獲得上述好處的一半或更少。如前所述,Nvidia的7nm A100比其12nm的前代產品要慢,而高通公司首款7nm處理器Snapdragon 855的最大CPU速度僅比Snapdragon 845提高了2%。臺積電預期5nm的收益將小于7nm,因為更多地使用EUV會增加每片晶圓和流片的成本。
格芯的12LP+提供了一條替代路徑,與臺積電的7nm相比,功耗大幅降低,成本則沒有增加。功耗降低主要歸功于新的雙功函數晶體管,它支持0.55V電壓選項。臺積電的7nm技術提供超低VT (ULVT)晶體管,其工作電壓最低為0.6V。臺積電長期以來服務于智能手機客戶,專注于低壓操作,而格芯更側重于PC,直到最近才發生改變,因此其在這方面的進步在很大程度上是彌補差距。
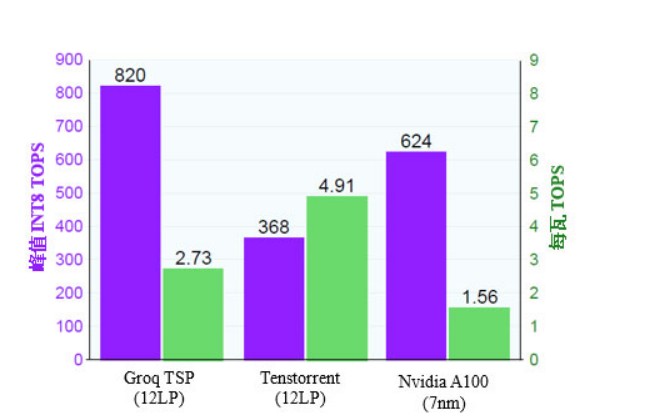
圖3. 高端AI加速器比較。與Nvidia的新產品A100相比,Groq TSP的性能更強勁(以每秒萬億次運算或TOPS衡量),而功耗卻更低。Tenstorrent的性能目標較低,但功效(每瓦TOPS)是A100的三倍。
12LP+的其余優勢來自于該技術專為AI設計的SRAM和MAC單元。這種方法反映了晶圓廠的差異化:臺積電必須服務于廣泛的客戶,而格芯可以專注于特定的新興工作負載。AI市場尤其成果豐碩,因為有太多的公司(特別是初創公司)在開發CNN加速器。大型客戶通常會自行設計緩存和MAC單元,但格芯的設計對于希望將開發成本降至最低而專注于獨特架構的初創公司很有用。
更長期問題是,在沒有7nm及更小線寬技術的路線圖的情況下,格芯能否保持競爭力。臺積電的5nm技術正在量產中,客戶已經啟動未來節點的設計。這些先進的工藝使設計師能夠將更多存儲器和MAC單元放入芯片中。市場份額最大的大型公司將繼續沿這條路走下去。面向AI市場的小型公司則會發現12LP+更實惠,而且可以使用小芯片來經濟高效地提高晶體管數量。Groq和Tenstorrent通過格芯的12LP技術實現了領先的AI性能,12LP+中的AI增強功能將使新技術更加卓越。
責任編輯:tzh
-
芯片
+關注
關注
458文章
51425瀏覽量
428779 -
晶體管
+關注
關注
77文章
9811瀏覽量
139175 -
AI
+關注
關注
87文章
32023瀏覽量
270913
發布評論請先 登錄
相關推薦
行業集結:共同定制 RK3566 集成 AI 眼鏡的前沿 AR 方案
當我問DeepSeek AI爆發時代的FPGA是否重要?答案是......
FPGA在AI方面有哪些應用

了解運算放大器電路中的功耗設計

嵌入式系統中低功耗設計要點
5962-8859301VPA OP200S 數據手冊和產品信息 | 亞德諾(ADI)半導體 航空航天用雙通道、低失調、低功耗運算放大器
risc-v多核芯片在AI方面的應用
NanoEdge AI的技術原理、應用場景及優勢






 工商網監
工商網監
評論