 Prometheus的架構原理從“監控”談起
Prometheus的架構原理從“監控”談起

Prometheus是繼Kubernetes(k8s)之后,CNCF畢業的第二個開源項目,其來源于Google的Borgmon。本文從“監控”這件事說起,深入淺出Prometheus的架構原理、目標發現、指標模型、聚合查詢等設計核心點。
一、前言
接觸過各式各樣的監控,開源的CAT、Zipkin、Pinpoint等等,并深度二次開發過;也接觸過收費的聽云系APM,對各類監控的亮點與局限有足夠的了解。
去年10月我們快速落地了一套易用、靈活、有亮點的業務監控平臺,其中使用到了Prometheus。從技術選型階段,Prometheus以及它的生態就讓我們印象深刻,今天就聊聊監控設計與Prometheus。
通常一個監控系統主要包含 采集(信息源:log、metrics)、上報(協議:http、tcp)、聚合、存儲、可視化以及告警等等。其中采集上報主要是客戶端的核心功能,一般有定期外圍探測的(早期的Nagios、Zabbix)、AOP方式手動織入代碼的(埋點)、字節碼自動織入等方式(無埋點)。
二、什么是監控
一套產品化的,用來量化管理技術、業務的服務體系或解決方案。
這套產品主要解決兩個問題(產品價值):
技術:將系統的各種功能、狀態等技術表現數據化、可視化,來保證技術體系的穩定、安全等。
業務:將各種業務表現數據化、可視化,以供分析、及時干預,保證業務高效開展。
三、監控的基礎原則
事前監控:架構設計階段務必需要考慮監控,而不是等到部署上線才去考慮
監控什么:全局視角,自頂(業務)向下。對于一般業務來講,建議先監控離用戶最近的地方,用戶的良好體驗是推動業務發展的動力,這也是最敏感、重要的地方。
對用戶友好:監控服務易用,易接入,盡可能自動化
技術人員、業務人員的信息源、能夠協助故障定位與解決
可視化:清晰的顯示各類數據(各類圖表展示),以及告警等信息記錄
告警:
哪些問題需要通知?(如:需要人工干預的,有意義的)
通知誰?(如:一線系統負責人)
如何通知?(如:短信、電話、其他通信工具;信息清晰、準確、可操作)
多久通知一次?(如:5分鐘)
何時停止通知以及何時升級到其他人?(如:已恢復正常;兩個小時問題未恢復,升級通知到上級負責人)
四、Prometheus設計剖析
Prometheu聚焦于當下正在發生的各類數據,而不是追蹤數周以前的數據,因為他們認為“大多數監控查詢以及告警等都是一天內的數據”,Facebook相關論文也驗證了這一點:85%的時序查詢是26小時之內的。
簡單來概括,Prometheus是一個準實時監控系統,并自帶時序數據能力。
1. 整體架構
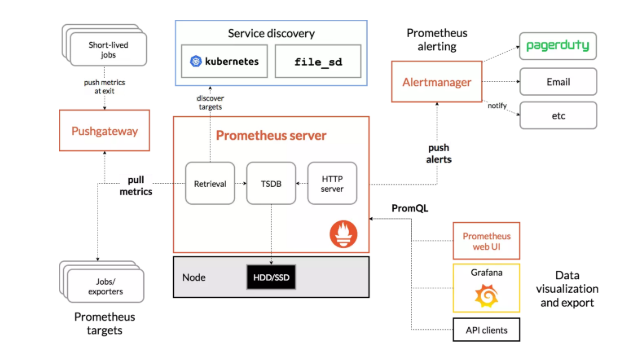
Prometheus架構圖(引用自Prometheus官網)
簡化點的架構圖如下:
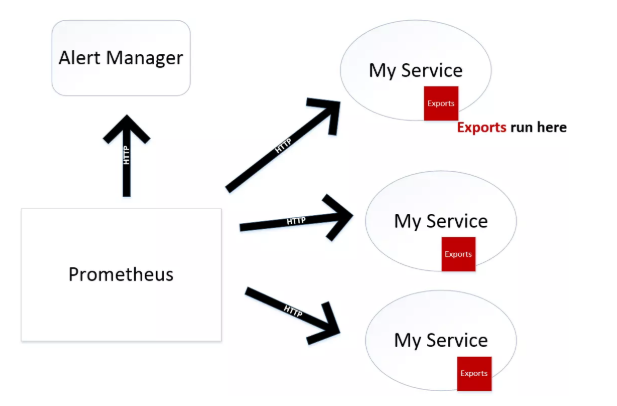
Prometheus 主要通過pull的方式獲取被監控程序(targetexports)中暴漏出來的時序數據。當然也提供了pushgateway服務,一般少量數據也可以push方式發送。
2. 目標發現
Prometheus通過pull的方式獲取服務的指標數據,那么它是如何發現這些服務的呢?
可以通過多種方式來處理目標資源的發現:
2.1 人工的配置文件列表
通過手工方式,添加靜態配置,指定需要監控的服務,如下target塊:
prometheus.yml
scrape_configs:
。..。.
#監控活動
- job_name: ‘xxxxxxactivity-wap’ metrics_path: /prometheus/metrics static_configs:
- targets: [‘10.xx.xx.xx:8080’,
。..。.. 。..。..]
#監控優惠券
- job_name: ‘xxxxxxshop-coupon’ metrics_path: /prometheus/metrics static_configs:
- targets: [‘10.xx.xx.xx:8080’,
。..。.. 。..。..]
#營銷
- job_name: ‘xxxxxx-sales-api’ metrics_path: /prometheus/metrics static_configs:
- targets: [‘10.xx.xx.xx:8080’,
。..。.. 。..。..
]
。..。..
顯而易見,這種方式雖然很簡單,但是在繁忙的工作中持續維護一長串服務主機列表并不是一個可擴展的優雅方式,動態性、大規模會讓這種方式無法繼續下去。
指定加載目錄,這些目錄文件的變更將通過磁盤監視檢測發現,然后Prometheus會立即應用這些變更。作為備用方案,文件內容也將以指定的刷新間隔(refresh_interval)定期被Prometheus重新讀取,發現變更后生效。
示例如下:
prometheus.yml
。..。.. #監控 訂單中心OMS-API scrape_configs: - job_name: ‘oms-api’ metrics_path: /prometheus/metrics file_sd_configs: - files: - ‘conf/oms-targets.json’ #默認 5分鐘 refresh_interval:5m 。..。..
conf/oms-targets.json文件(此文件的變動將被監聽,通常這個文件由另一個程序產生,如CMDB源):
oms-targets.json
[
{ “labels”: { “job”: “oms-api” }, “targets”: [
‘ip1:8080’,‘ip2:8080’,。..。..
]
}
]
2.3 基于API的自動發現
當前可以用的本機服務發現插件有AmazonEC2、Azure、Consul、Kubernetes等等。
下文以Consul為例,實例啟動成功時可以通過腳本(或其他)方式將當前節點信息,注冊到Consul上(類似啟動后向zk或redis寫入當前節點信息)。Prometheus會實時的感知到Consul數據的變動,并自動去做熱加載。
prometheus.yml
#監控 訂單中心OMS-API - job_name: ‘oms-api’ consul_sd_configs: #consul 地址,默認監聽所有服務地址信息 - server: ‘xxxxxx’ services: []
注:Consul 是基于 GO 語言開發的開源工具,主要面向分布式,服務化的系統提供服務注冊、服務發現和配置管理的功能。Consul 提供服務注冊/發現、健康檢查、Key/Value存儲、多數據中心和分布式一致性保證等功能
2.4 基于DNS的自動發現
在前幾種方式都不適合的情況下,DNS服務發現允許你指定DNS條目列表,然后查詢這些條目中的記錄,以發現獲取目標列表。用的比較少,不贅述。
被監控的目標成功被發現后,可以在自帶的web頁面上可視化查看,如圖(本地模擬環境):

3. 指標收集與聚合
Prometheus通過pull的方式拉取外部進程中的時序數據指標(Exporter),拉取過程細節允許用戶配置相關信息:如頻率、提前聚合規則、目標進程暴漏方式(http url)、如何連接、連接身份驗證等等。
指標
所謂指標就是軟件或硬件多種屬性的量化度量。有別于日志采集的那種ELK監控,Prometheus通過四種指標類型完成:
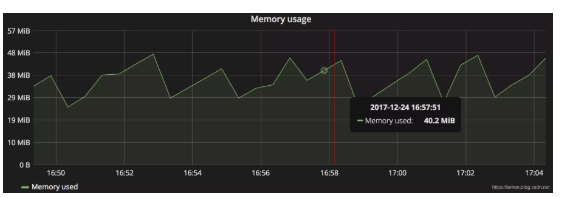
(1)測量型(Gauge):可增可減的數字(本質上是度量的快照)。常見的如內存使用率。
(2)計數型(counter):只增不減,除非重置為0。比如某系統的HTTP請求量。
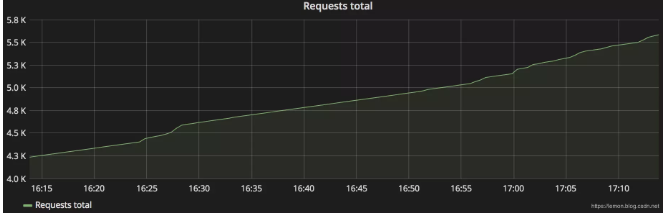
(3)直方圖(histogram):通過對監控的指標點進行抽樣,展示數據分布頻率情況的類型。
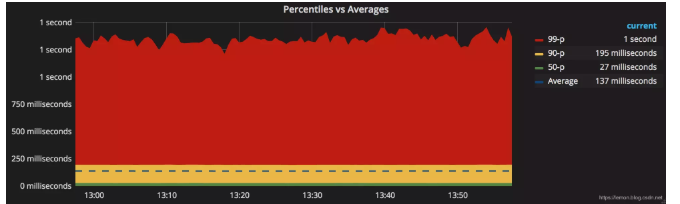
上圖強調了分布情況對于理解延遲等指標的重要性。如果我們假設這個指標的SLO(服務等級目標)為150ms,那么137ms的平均延遲看起來是可以接受的;但實際上,每10個請求中就有1個在193ms以上完成,每100個請求中就有10個不達標!(如圖:90線、99線均不達標)
(4)摘要(summary):與Histogram非常類似,主要區別是summary在客戶端完成聚合,而Histogram在服務端完成。因此summary只適合不需要集中聚合的單體指標(如GC相關指標)。
三條經驗法則:
如果需要多個采集節點的數據聚合、匯總,請選擇直方圖;
如果需要觀察多個采集節點數據的分布情況,請選擇直方圖;
如果不需要考慮集群(如GC相關信息),可選擇summary,它可以提供更加準確的分位數。
4. 聚合、查詢
內置的數據查詢DSL語言:PromQL,它可以快速的支持聚合和多種形式的查詢,并通過自帶的web界面,可以快速在瀏覽器中查詢使用。在我們的實踐中,使用Grafana做可視化更加實用、美觀。
關于PromQL更多語法使用,可以查看官網文檔,不贅述。
關于指標聚合
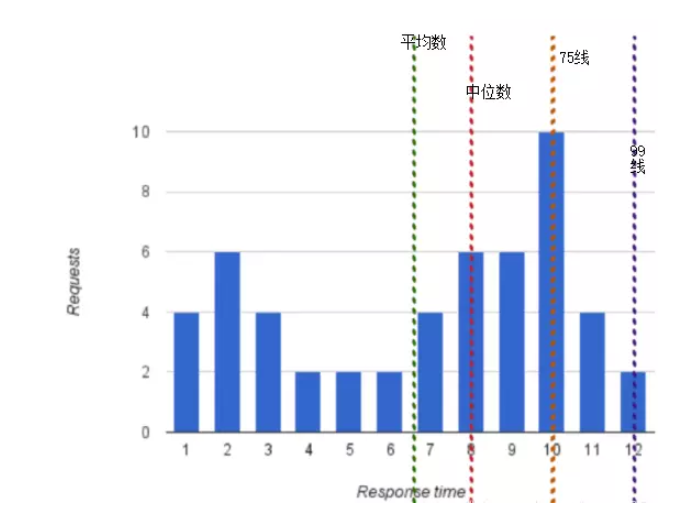
對于指標的聚合,Prometheus提供了多種函數。以下列聚合指標為例:
平均數
中間數
百分位數(如下圖99線:百分之99的請求要低于12s這個值)
標準差(衡量數據集差異情況,0代表與平均數一樣,越大表示數據差異越大)
變化率
5. 數據模型
Prometheus與其他主流時序數據庫一樣,在數據模型定義上,也會包含metric name、一個或多個labels(同InfluxDB里的tags含義)以及metric value。
如用JSON表示一個時序數據庫中的原始時序數據:
一個json表示的時序數據示例
##用JSON表示一個時序數據
{ “timestamp”: 1346846400, // 時間戳 “metric”: “total_website_visits”, // 指標名 “tags”:{ // 標簽組 “instance”: “aaa”, “job”: “job001” }, “value”: 18 // 指標值 }
metric name加一組labels作為唯一標識來定義time series(也就是時間線)。一旦label改變,則會創建新的時間序列,原有基于這個時間序列的配置將無效。在查詢時,支持根據labels條件查找time series,支持簡單的條件也支持復雜的條件。
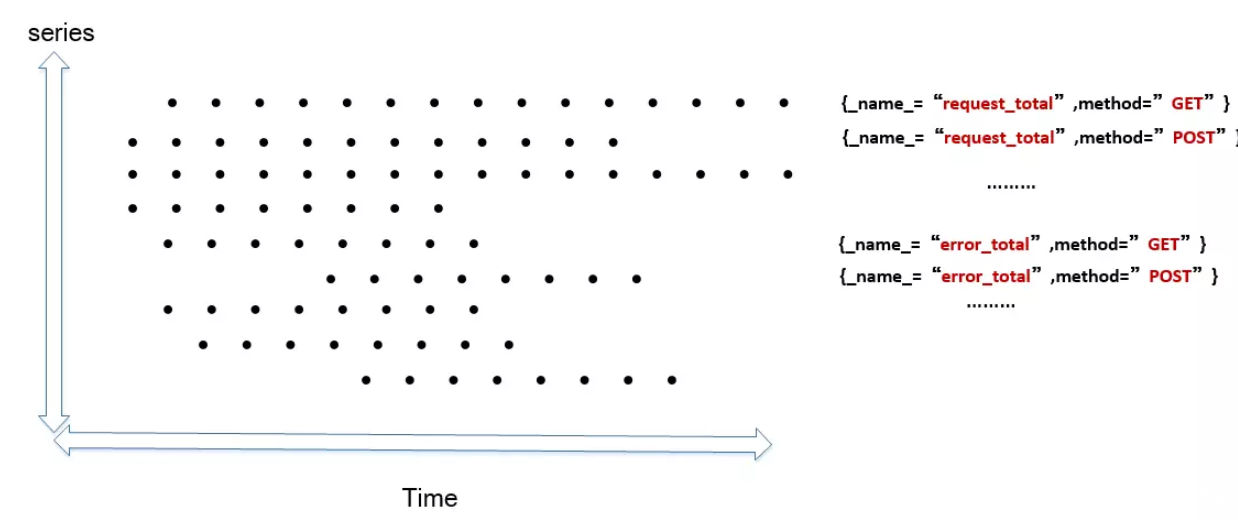
上圖是所有數據點分布的一個簡單視圖,橫軸是時間,縱軸是時間線,區域內每個點就是數據點。Prometheus每次接收數據,收到的是圖中區域內縱向的一條線。這個表述很形象,因為在同一時刻,每條時間線只會產生一個數據點,但同時會有多條時間線產生數據,把這些數據點連在一起,就是一條豎線。這個特征很重要,影響數據寫入和壓縮的優化策略。
保留時間
Prometheus專注于短期監控、告警而設計,所以默認它只保存15天的時間序列數據。如果要更長期,建議考慮數據單獨存儲到其他平臺。目前我們的方案是遠端存儲,Prometheus拉取的數據會落到InfluxDB上,這樣保證了更好的存儲彈性,數據的實時落地存儲。
6.Prometheus開源生態
Prometheus生態系統包括了提供告警引擎、告警管理的AlertManager,支持push模式數據上報的PushGateWay,提供更優雅美觀的可視化界面的Grafana,支持遠端存儲的RemoteStoreAdapter;log轉換為metric的Mtail等等。
除此之外,還有一系列Exporter(可以理解為監控agent),這些Exporter可以直接安裝使用。自動監控應用程序、機器、主流數據庫、MQ等等。
Prometheus生態中還有一系列客戶端庫,支持各種主流編程語言Java、C、Python等等。
可以說Prometheus的生態是比較完善的,并且社區足夠活躍,未來可期。
編輯:hfy
-
DNS
+關注
關注
0文章
226瀏覽量
20459 -
監控設計
+關注
關注
0文章
3瀏覽量
7200 -
Prometheus
+關注
關注
0文章
30瀏覽量
1898
發布評論請先 登錄
Prometheus的基本原理與開發指南


使用Thanos+Prometheus+Grafana構建監控系統
監控神器:Prometheus
關于Prometheus監控系統相關的知識體系
prometheus下載安裝教程
兩種監控工具prometheus和zabbix架構對比
Prometheus存儲引擎簡析
基于kube-prometheus的大數據平臺監控系統設計
40個步驟安裝部署Prometheus監控系統
基于Prometheus開源的完整監控解決方案

從零入門Prometheus:構建企業級監控與報警系統的最佳實踐指南
使用Prometheus與Grafana實現MindIE服務可視化監控功能





 工商網監
工商網監
評論