 谷歌云人工智能為機器學習提供幫助分析
谷歌云人工智能為機器學習提供幫助分析

研究表明,雖然Google Cloud AI(谷歌云人工智能)和機器學習平臺缺少一些功能,并且仍處于測試階段,但其范圍和質量在行業中仍是首屈一指的。
谷歌公司擁有行業規模最大的機器學習堆棧之一,目前以其Google Cloud AI和機器學習平臺為中心。谷歌公司在數年前就開源了TensorFlow,但TensorFlow仍然是一個最成熟的、并且廣泛引用的深度學習框架。同樣,谷歌公司幾年前將Kubernetes剝離成為開源軟件,但它仍然是主要的容器管理系統。
谷歌云平臺是開發人員、數據科學家和機器學習專家的最佳工具和基礎設施來源之一,但是從歷史上看,對于缺乏認真的數據科學或編程背景的業務分析師而言,Google Cloud AI的吸引力并不大。而這種情況現在開始改變。
Google Cloud AI和機器學習平臺包括人工智能構建塊、人工智能平臺和加速器以及人工智能解決方案。這些是針對業務主管而不是數據科學家的相當新的人工智能解決方案,其中可能包括來自谷歌公司或其合作伙伴的咨詢。
經過預先訓練但可自定義的人工智能構建塊可以在不熟悉編程或數據科學的情況下使用。盡管如此,出于實用的原因,數據科學家經常使用它們,從本質上講,無需大量的模型培訓即可完成工作。
人工智能平臺和加速器通常面向數據科學家,并且需要編碼技能、數據準備技術知識和大量培訓時間。為此建議在嘗試了相關構建模塊之后再去實施。
Google Cloud AI產品中仍然缺少一些鏈接,尤其是在數據準備方面。Google Cloud與數據導入和調節服務最接近的是Trifacta公司的第三方Cloud Dataprep。但是,內置在Cloud AutoML Tables中的功能工程很有希望,并且將這種服務用于其他情況將很有用。
人工智能的陰暗面與責任感(或缺乏道德感)以及持久的模型偏見(通常是由于用于訓練的偏見數據)有關。谷歌公司于2018年發布了人工智能原則。這項工作仍在進行中,但這是指導的基礎,最近在有關責任人工智能的博客文章中對此進行了討論。
谷歌公司在人工智能市場上有很多競爭對手,而公共云市場上也有很多競爭對手(云計算供應商超過六家)。為了公平地進行比較,并且進行總結:AWS云平臺可以完成谷歌云平臺的大部分工作,并且也非常出色,但是通常收取更高的價格。
谷歌云的人工智能構建塊不需要太多的機器學習專業知識,而需要基于預先訓練的模型和自動訓練。人工智能平臺可以讓用戶訓練和部署自己的機器學習和深度學習模型。
Google Cloud AI構建基塊
Google Cloud AI構建基塊是易于使用的組件,用戶可以將其合并到自己的應用程序中以添加視覺、語言、對話和結構化數據。許多人工智能構件都是經過預訓練的神經網絡,但是如果它們不能滿足用戶的需求,則可以使用轉移學習和神經網絡搜索進行自定義。AutoML Tables有所不同,因為它可以使用數據科學家來為表格數據集找到最佳機器學習模型的過程實現自動化。
AutoML
Google Cloud AutoML服務為語言對翻譯、文本分類、對象檢測、圖像分類和視頻對象分類和跟蹤提供定制的深層神經網絡。它們需要標記數據進行培訓,但不需要深入學習、轉移學習或編程方面的重要知識。
Google Cloud AutoML可以為用戶的標記數據自定義經過谷歌公司測試的、高精度的深度神經網絡。AutoML從數據中訓練模型,而不是從頭開始,AutoML為語言對翻譯和上面列出的其他服務實現了自動深度轉移學習(意味著從現有的基于其他數據的深層神經網絡開始)和神經結構搜索(意味著找到了額外網絡層的正確組合)。
在每一個領域,谷歌公司已經有一個或多個基于深度神經網絡和大量標簽數據的預先訓練服務。這些方法很可能適用于未經修改的數據,用戶應該對此進行測試,以節省時間和成本。如果他們沒有做到,Google Cloud AutoML可以幫助用戶創建一個能做到的模型,而不需要用戶知道如何執行轉移學習或如何設計神經網絡。
與從頭開始訓練神經網絡相比,轉移學習具有兩個主要優點:首先,它需要的訓練數據要少得多,因為網絡的大多數層已經經過了良好的訓練。其次,它訓練得更快,因為它只優化最后一層。
雖然過去通常將Google Cloud AutoML服務打包在一起提供,但現在列出了它們的基本預訓練服務。其他大多數公司所說的AutoML是由Google Cloud AutoML Tables執行的。
為此測試AutoML Vision自定義花卉分類器,采用一個小時的時間從Google樣本圖像中訓練了這個分類器,并在附近藝術博物館拍攝了郁金香的照片進行比較。
AutoML Tables
對于許多回歸和分類問題,通常的數據科學過程是創建數據表以進行訓練、清理和整理數據,執行特征工程,并嘗試在轉換后的表上訓練所有適當的模型,包括進行優化的步驟最佳模型的超參數。在人工識別目標字段后,Google Cloud AutoML Tables可以自動執行整個過程。
AutoML Tables會自動在Google的model-zoo中搜索結構化數據,以找到最適合的模型,從線性/邏輯回歸模型(用于更簡單的數據集)到高級的深度、集成和架構搜索方法(用于更大型、更復雜的模型)不等。它可以自動執行各種表格數據原語(例如數字、類、字符串、時間戳和列表)上的要素工程,并幫助用戶檢測和處理缺失值、異常值和其他常見數據問題。
其無代碼界面可指導用戶完成整個端到端機器學習生命周期,從而使團隊中的任何人都可以輕松構建模型,并將其可靠地集成到更廣泛的應用程序中。AutoMLTables提供了廣泛的輸入數據和模型行為可解釋性功能,以及用于防止出現常見的錯誤。AutoMLTables也可在API和筆記本環境中使用。
AutoML Tables與其他幾種AutoML實現和框架競爭。
從功能設計到部署,AutoML Tables實現了用于為表格數據創建預測模型的整個流程的自動化。
在AutoML Tables的分析階段可以看到所有原始功能的描述性統計信息。
免費的Google Cloud Vision“嘗試API”界面允許將圖片拖動到網頁上并查看結果。可以看到孩子在微笑,因此“Joy”標簽正確。但該算法無法完全識別所戴的帽子。
Vision API
Google Cloud Vision API是一項經過預先訓練的機器學習服務,用于對圖像進行分類并提取各種功能。它可以將圖像分為數千種經過預先訓練的類別,從圖像中發現的通用對象和動物(例如貓)到一般情況(例如黃昏),再到特定地標(艾菲爾鐵塔和大峽谷),并確定圖像的一般屬性,例如其主導色。它可以隔離臉部區域,然后對臉部進行幾何分析(面部方位和地標)和情感分析,盡管它不會將某人臉部識別為特定人物,但名人(需要特殊使用許可)除外。Vision API使用OCR檢測圖像中超過50種語言和各種文件類型的文本。它還可以識別產品徽標,并檢測成人、暴力和醫療內容。
Video Intelligence API
谷歌云的Video Intelligence API會自動識別存儲和流式視頻中的2萬多個對象、位置和動作。它還可以區分場景變化,并在視頻、快照或幀級別提取豐富的元數據。它還使用OCR執行文本檢測和提取,檢測顯式內容,自動關閉字幕和說明,識別徽標,并檢測人臉、人物和姿勢。
谷歌公司建議使用Video Intelligence API來提取元數據以索引、組織和搜索用戶的視頻內容。它可以錄制視頻并生成隱藏字幕,以及標記和過濾不適當的內容,所有這些都比人工錄制更具成本效益。用例包括內容審核、內容推薦、媒體存檔、廣告。
Natural Language API
自然語言處理(NLP)是其“秘方”的重要組成部分,可以使對Google Search和Google Assistant的輸入效果很好。Natural Language API將相同的技術公開給用戶的程序。它可以使用10種語言執行語法分析、實體提取、情感分析和內容分類。如果用戶了解某種語言,可以指定使用。否則,API將嘗試自動檢測語言。當前可應要求提前提供一個單獨的API,專門處理與醫療保健相關的內容。
Translation API
Translation API可以翻譯一百多種語言,如果用戶沒有指定,則可以自動檢測源語言,并提供三種版本:基本翻譯、高級翻譯、媒體翻譯。高級翻譯API支持詞匯表,批處理翻譯和自定義模型的使用。基本翻譯API本質上是消費者Google翻譯界面所使用的API。而AutoML Translation允許用戶使用轉移學習來訓練自定義模型。
Media Translation API直接以12種語言從音頻文件或流文件中轉換內容,并自動生成標點符號。視頻和電話通話音頻有不同的模型。
Text-to-Speech
Text-to-Speech(文字轉聲音)的 API可以將純文本和SSML標記轉換為聲音,可以選擇200多種聲音和40種語言和變體。其變體包括不同的國家和民族口音,例如美國、英國、南非、印度、愛爾蘭和澳大利亞的語言。
其基本的聲音聽起來通常很機械。WaveNet聲音通常聽起來更自然,但使用成本較高。用戶還可以從自己的錄音室質量的錄音中創建自定義聲音。
用戶可以將合成聲音的速度調高或調慢4倍,將音調調高或調低20個半音。SSML標簽允許用戶添加暫停、數字、日期和時間格式以及其他發音說明。還可以將音量增益最多增加16分貝,或將音量最多減小96分貝。
Speech-to-Text
Speech-to-Text (聲音轉文字)API使用谷歌公司先進的深度學習神經網絡算法將語音轉換為文字,以實現自動語音識別(ASR)。它支持超過125種語言和變體,可以在本地(帶有許可證)以及在谷歌云平臺中進行部署。Speech-to-Text可以針對較短的音頻樣本(一分鐘或更短)進行同步運行,針對較長的音頻(最長達到480分鐘)進行異步處理,并可以進行流傳輸以進行實時識別。
用戶可以通過提供提示來自定義語音識別,以轉錄特定于領域的術語和稀有單詞。有專門的ASR模型用于視頻、電話、命令和搜索,以及“默認”(其他任何東西)。雖然用戶可以在API請求中嵌入編碼的音頻,但更多情況下,用戶將為存儲在Google云存儲桶中的二進制音頻文件提供URI。
Dialogflow
Dialogflow Essentials建立在“Speech-to-Text” (聲音轉文字)和“Text-to-Speech” (文字轉聲音)的基礎上,并且可以利用40多個預先構建的代理作為模板,用于具有單個主題對話的小型機器人。Dialogflow CX是一個高級開發套件,用于創建會話式人工智能應用程序,包括聊天機器人、語音機器人和IVR(交互式語音響應)機器人程序。它包括一個可視化的機器人構建平臺(見下面的屏幕截圖)、協作和版本控制工具以及高級IVR功能支持,并針對企業規模和復雜性進行了優化。
Dialogflow CX是用于復雜語音交互虛擬代理的設計器。設計師在此處列出了意圖“store.location”的十個短語。類似的短語也會被識別出來。
Inference API
時間序列數據通常需要進行一些特殊的處理,尤其是如果用戶希望除了處理大型歷史數據集之外還對流數據實時執行數據處理,尤其如此。完全托管的無服務器Inference API目前處于有限的Alpha測試中,可使用事件時間標記檢測趨勢和異常,處理包含多達數百億個事件的數據集,每秒可以運行數千個查詢,并以低延遲進行響應。
Recommendations API
使用機器學習來建立有效的推薦系統被認為是一個棘手和耗時的問題。谷歌公司已經用推薦API實現了這一過程的自動化,目前還在測試階段。這項完全管理的服務負責預處理用戶的數據、培訓和調整機器學習模型,以及提供基礎設施。它也糾正了偏見和季節性。它集成了相關的谷歌服務,如Analytics 360、Tag Manager、Merchant Center、云存儲和BigQuery。初始模型培訓和調整需要兩到五天的時間才能完成。
Google Cloud AI平臺
Google Cloud AI平臺和加速器面向開發者、數據科學家和數據工程師。大多數情況下,使用Google Cloud AI平臺來解決問題可能是一項巨大的努力。如果用戶可以通過使用人工智能構建塊來避免這種努力,則應該這樣做。
Google Cloud AI平臺促進了開發人員、數據科學家和數據工程師的端到端機器學習工作流程。雖然它不能幫助用戶獲取數據或為模型編碼,但可以幫助將其余的機器學習工作流程結合在一起。
Google Cloud AI平臺將大多數機器學習工作流程聯系在一起,從模型培訓到模型版本控制和管理。
人工智能平臺包括幾個模型訓練服務和各種機器類型的訓練和調整,包括GPU和TPU加速器。預測服務允許用戶從任何經過培訓的模型中提供預測;它不僅限于用戶自己訓練的模型或用戶在谷歌云平臺上訓練的模型。
AI Platform Notebooks在谷歌云平臺的虛擬機實現了JupyterLab Notebooks,并預先配置了TensorFlow、PyTorch和其他深度學習軟件包。人工智能平臺數據標簽服務使用戶可以為要用于訓練模型的數據集請求人工標簽。人工智能平臺深度學習虛擬機映像針對關鍵的機器學習框架和工具以及GPU支持針對數據科學和機器學習任務進行了優化。
AI Platform Notebooks
對于許多數據科學家來說,使用Jupyter或JupyterLab Notebook是開發、共享模型和機器學習工作流的最簡單方法之一。 AI Platform Notebooks使創建和管理通過JupyterLab、Git、GCP集成,以及用戶選擇的Python 2或Python 3、R、Python或R核心程序包、TensorFlow、PyTorch和CUDA預先配置的安全虛擬機變得更加簡單。
雖然Kaggle和Colab也支持Jupyter Notebooks,但Kaggle面向的是愛好者和學習專業人士,Colab面向的是研究人員和學生,而AI Platform Notebooks則面向企業用戶。對于繁重的工作,AI Platform Notebooks可以使用深度學習虛擬機、Dataproc集群和Dataflow,并且可以連接到GCP數據源,例如BigQuery。
用戶可以從小型虛擬機開始開發,然后再擴展到具有更多內存和CPU的功能更強大的虛擬機,并可能使用GPU或TPU進行深度學習培訓。用戶還可以將Notebooks保存在Git存儲庫中,并將其加載到其他實例中。或者可以使用下面討論的人工智能平臺培訓服務。
以下是一個使用AI Notebooks的實施代碼實驗室。以下是該實驗的屏幕截圖。里面的一個目錄有預先加載到JupyterLab中的示例Notebooks。它們看起來很有趣。
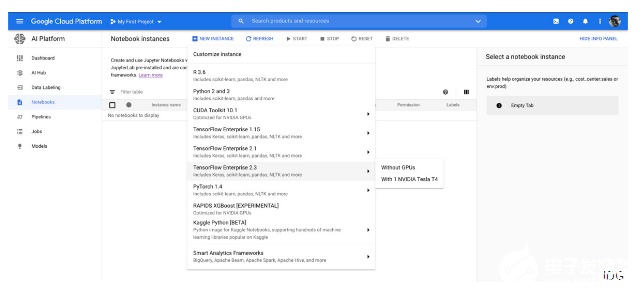
當創建新的Google Cloud AI Notebook實例時,可以選擇環境的起點。以后可以優化虛擬機。
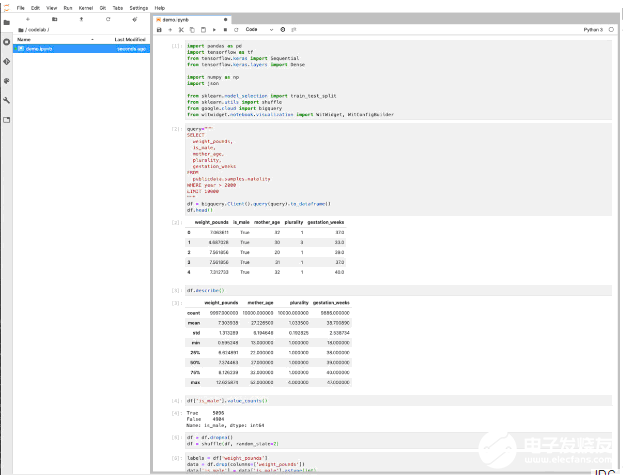
代碼實驗室的開頭設置了程序包導入,并針對公共BigQuery數據集運行查詢以獲取用于分析和模型訓練的數據。該代碼實驗室自由地混合了Pandas、TensorFlow、NumPy和Scikit-learn的方法。Witwidget是Google假設工具。

在導入數據后,代碼實驗室會將其拆分以進行測試和培訓,并訓練一個簡單的完全連接的神經網絡。該實驗的重點是演示Google Cloud AI Notebook,而不是訓練最佳的模型,因此只有10個周期,最終的均方誤差并不是那么大。
可解釋人工智能和假設工具
如果用戶使用TensorFlow作為框架來構建和擬合模型,則可以使用谷歌公司的假設分析工具來了解更改訓練數據中的值可能如何影響模型。在其他領域稱之為敏感性研究。假設分析工具還可以顯示許多有用的圖形。

如果適合TensorFlow模型,則可以使用Cloud AI Notebook中的Google假設工具來探索模型的可解釋性。
人工智能平臺訓練
與模型開發相比,模型訓練通常需要更多的計算資源。用戶可以在Google Cloud AI Notebook或自己的小型數據集上訓練簡單模型。要在大型數據集上訓練復雜的模型,使用AI Platform Training服務可能會更好。
訓練服務針對存儲在Cloud Storage存儲桶、Cloud Bigtable或其他GCP存儲服務中的訓練和驗證數據,運行存儲在Cloud Storage存儲桶中的訓練應用程序。如果用戶運行內置算法,則無需構建自己的訓練應用程序。
用戶可以訓練使用云存儲(目前是TensorFlow、Scikit learn和XGBoost)的代碼包的模型,以及使用來自云存儲的自定義容器映像的模型和使用內置算法的模型。用戶還可以使用從人工智能平臺深度學習容器派生的預構建PyTorch容器映像。
目前的內置算法有XGBoost、分布式XGBoost、線性學習、廣度和深度學習、圖像分類、圖像對象檢測和TabNet。除了圖像分類和圖像對象檢測之外,所有這些算法都是從表格數據中訓練出來的。目前,除XGBoost以外的所有算法都依賴TensorFlow 1.14。
用戶可以從人工智能平臺控制臺的“作業”選項卡運行人工智能平臺培訓,也可以發出Google Cloud AI平臺作業提交訓練命令來運行人工智能平臺培訓。命令行調用方法還可以自動將模型代碼上傳到Cloud Storage存儲桶。
用戶可以使用分布式XGBoost、TensorFlow和PyTorch進行分布式人工智能平臺訓練。每個框架的設置都不同。對于TensorFlow,有三種可能的分配策略,以及“規模等級”的六個選項,它們定義了訓練集群的配置。
超參數調整通過對具有不同訓練過程變量的模型進行多次訓練(以設置可變權重)(例如通過設置學習率來控制算法)來工作。用戶可以相當簡單地在TensorFlow模型上執行超參數調整,因為TensorFlow在摘要事件報告中返回其訓練指標。對于其他框架,用戶可能需要使用cloud ml-hypertune Python軟件包,以便人工智能平臺訓練可以檢測模型的指標。定義訓練作業時,用戶可以設置要調整的超參數、范圍以及調整搜索策略。
用戶可以使用GPU或TPU進行訓練。通常,用戶需要指定一個實例類型,其中包括要使用的GPU或TPU,然后從代碼中啟用它們。模型越大,越復雜,GPU或TPU加速其訓練的可能性就越大。

Google Cloud AI Platform Jobs是用戶如何使用三個機器學習框架之一或自定義容器映像來設置模型訓練的方法。選擇框架時,還必須選擇一個版本。
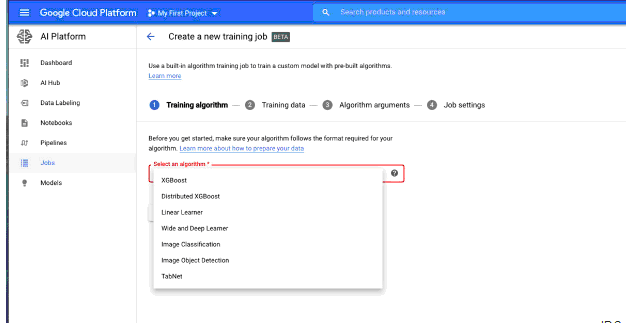
內置算法是為自定義模型提供機器學習框架和代碼的替代方法。
AI Platform Vizier
執行超參數優化的另一種方法是使用AI平臺Vizier(黑盒優化服務)。Vizier進行了多次試驗研究,并且可以解決許多類型的優化問題,而不僅僅是人工智能訓練。Vizier仍處于Beta測試中。
AI Platform Prediction
在擁有訓練有素的模型后,用戶需要將其部署以進行預測。AI Platform Prediction管理云平臺中的計算資源以運行用戶的模型。用戶將模型導出為可部署到AI Platform Prediction的工件。無需在Google Cloud AI上訓練模型。
AI Platform Prediction假設模型會隨著時間而變化,因此模型包含版本,并且可以部署版本。這些版本可以基于完全不同的機器學習模型,盡管如果模型的所有版本都使用相同的輸入和輸出會有所幫助。
這張照片和它的疊加顯示了有助于模型將動物識別為貓而不是狗的區域。
AI Platform Prediction分配節點以處理發送到模型版本的在線預測請求。部署模型版本時,可以自定義AI Platform Prediction用于這些節點的虛擬機的數量和類型。節點并非完全是虛擬機,但是底層的機器類型是相似的。
用戶可以允許AI Platform Prediction自動或人工縮放節點。如果將GPU用于模型版本,則無法自動縮放節點。如果分配的計算機類型對于模型而言太大,則可以嘗試自動縮放節點,但是可能永遠無法滿足用于縮放的CPU負載條件。在理想情況下,用戶將使用剛好適合其機器學習模型的節點。
除了預測之外,該平臺還可以針對特定預測以特征歸因的形式提供人工智能解釋。目前正在進行Beta測試。可以將特征歸因用作表格數據的條形圖和圖像數據的覆蓋圖。
AI Platform Deep Learning VM Images
當用戶從普通的原始操作系統開始時,配置其環境以進行機器學習和深度學習,CUDA驅動程序以及JupyterLab有時可能需要訓練模型的時間,至少對于簡單模型而言是這樣。使用預配置的映像可以解決這個問題。
用戶可以使用TensorFlow、TensorFlow Enterprise、PyTorch、R或其他六種框架來選擇人工智能平臺深度學習虛擬機映像。所有圖像都可以包括JupyterLab,并且打算與GPU一起使用的圖像可以具有CUDA驅動程序。

用戶可以通過Google Cloud命令行(通過Google Cloud SDK安裝)或Google Cloud市場創建實例。創建虛擬機時,用戶可以選擇虛擬CPU的數量(也需確定內存數量)以及GPU的數量和種類。用戶會根據所選的硬件看到每月費用的估算值,并獲得持續使用的折扣。這些框架不收取額外費用。如果選擇帶有GPU的虛擬機,則需要等待幾分鐘來安裝CUDA驅動程序。
用戶可以從Google Cloud Console和命令行創建深度學習虛擬機。需要注意,CUDA驅動程序和JupyterLab安裝均只需要選中一個復選框。框架、GPU、機器類型和區域選擇是從下拉列表中完成的。
AI Platform Deep Learning Containers
谷歌公司還提供了適用于本地計算機或Google Kubernetes Engine(GKE)上的Docker的深度學習容器。容器具有用戶可能需要的所有框架、驅動程序和支持軟件,與虛擬機映像不同,虛擬機映像僅允許用戶選擇所需的內容。深度學習容器目前處于beta測試中。
AI Platform Pipelines
MLOps(機器學習操作)將DevOps(開發人員操作)實踐應用于機器學習工作流。許多Google Cloud AI平臺都以某種方式支持MLOps,但人工智能平臺管道是MLOps的核心。
當前處于beta測試的AI Platform Pipelines通過減輕用戶使用TensorFlow Extended(TFX)設置Kubeflow Pipelines的難度,使開始使用MLOps更加容易。開源Kubeflow項目致力于使機器學習工作流在Kubernetes上的部署簡單,可移植且可擴展。Kubeflow Pipelines是Kubeflow的一個組件,目前處于beta測試中,它是用于部署和管理端到端機器學習工作流的全面解決方案。
當Spotify將其MLOps切換到Kubeflow Pipelines和TFX時,一些團隊將其實驗數量增加了7倍。
TensorFlow Extended是用于部署生產機器學習管道的端到端平臺。 TFX提供了一個工具包,可幫助用戶在各種編排器(如Apache Airflow、Apache Beam和Kubeflow Pipelines)上協調機器學習過程,從而使實施MLOps更加容易。Google Cloud AI Platform Pipelines使用TFX Pipelines,這是DAG(有向無環圖),使用Kubeflow Pipelines,而不是Airflow或Beam。
用戶可以通過Google Cloud控制臺中人工智能平臺的“管道”標簽管理人工智能平臺管道。創建一個新的管道實例將創建一個Kubernetes集群,一個云存儲桶和一個Kubeflow管道。然后,用戶可以根據示例定義管道,也可以使用TFX從頭開始定義管道。
Spotify使用TFX和Kubeflow改進了其MLOps。該公司報告說,一些團隊正在進行7倍以上的實驗。
AI Platform Data Labeling Service
Google Cloud AI Platform數據標簽服務可讓用戶與人工標簽人員一起為可在機器學習模型中使用的數據集合生成高度準確的標簽。該服務目前處于beta測試階段,由于發生新冠疫情,因此可用性非常有限。
AI Hub
Google Cloud AI Hub目前處于beta測試中,可為構建人工智能系統的開發人員和數據科學家提供一系列資產。用戶可以查找和共享資產。即使以beta形式,AI Hub似乎也很有用。
Google Cloud AI Hub是一種在谷歌云平臺上學習、構建和共享人工智能項目的快速方法。
TensorFlow Enterprise
TensorFlow Enterprise為用戶提供了TensorFlow的Google Cloud優化發行版,并具有長期版本支持。TensorFlow Enterprise發行版包含定制的TensorFlow二進制文件和相關軟件包。每個版本的TensorFlow企業版發行版都基于特定版本的TensorFlow;包含的所有軟件包都可以在開源中獲得。
Google Cloud AI Solutions
谷歌公司針對企業高管,而不是面向數據科學家或程序員推出人工智能解決方案。解決方案通常帶有可選的咨詢或合同開發組件。咨詢服務也可單獨提供。
Contact Center AI
Contact Center AI(CCAI)是用于聯絡中心的谷歌解決方案,旨在提供人性化的互動。它建立在Dialogflow的基礎上,可以提供虛擬代理,監視客戶意圖,在必要時切換到實時座席并為人工代理提供幫助。谷歌公司有六家合作伙伴,可幫助用戶開發和部署CCAI解決方案,并支持和培訓您的代理商。
Build and Use AI
Build and Use AI是通用定義的解決方案,主要提供谷歌公司的人工智能專業知識,人工智能構建基塊和人工智能平臺來解決用戶的業務問題。除其他好處之外,該解決方案還可以幫助用戶通過管道自動化和CI/CD設置MLop。
Document AI
Document AI將Google Vision API OCR構建塊與Cloud Natural Language結合使用,以從通常以PDF格式提供的商業文檔中提取和解釋信息。其他組件可解析常規表格和發票表格。針對抵押貸款處理和采購的行業特定解決方案目前正在測試中。谷歌公司有六個合作伙伴可以幫助實施Document AI解決方案。
各種工具的定價
Cloud AutoML Translation:訓練:每小時76美元;分類:在前50萬個字符后,每百萬個字符需支付80美元。
Cloud AutoML Natural Language:訓練:每小時3美元;分類:在前3萬條記錄之后的每千條記錄需要支付5美元。
Cloud AutoML Vision:訓練:在第一個小時后每小時為20美元;分類:前1000個圖像后每千個圖像為3美元。
Cloud AutoML Tables: 訓練:6小時免費一次性使用+每小時19.32美元(并行使用92臺n1-standard-4等效服務器);批量預測:6小時免費一次性使用+每小時1.16 美元(并行使用5.5臺n1-standard-4等效服務器);在線預測:每小時0.21美元(1臺n1-standard-4等效服務器)。
Video:在每月第一個1000分鐘后,每分鐘將支付4美分到7美分。
Natural Language:每月第5,000個單元后,每1,000個單元需要支付0.5美元到2美元。
Translation:在每月前50萬個字符之后,每百萬個字符需要支付20美元。
Media Translation:每月首個60分鐘之后,每分鐘需要支付0.068美元至0.084美元。
Text to speech:每月首個400萬個字符后,每100萬個字符需要支付4美元,
Speech to text:每月首個60分鐘后,每15秒需要支付0.004至0.009美元。
Dialogflow CX代理:100次聊天會話需要支付20美元,100次語音會話需要支付45美元。
Dialogflow ES代理:因模式而異,反映了基本的語音和自然語言收費。
Recommendations AI: 2.5美元/節點/小時,用于訓練和調整;每月2000萬個請求以上的數量折扣的預測為0.27美元/1000個。
GPU:0.11到2.48美元/GPU/小時。
TPU:每小時需要支付1.35到8美元。
AI Platform Training:每小時需要支付0.19到21.36美元。
AI Platform Predictions: 需要支付0.045到1.13美元/節點/小時,加上GPU價格為0.45到2.48美元/ GPU /小時。
平臺
所有服務均在Google Cloud Platform上運行;一些也可以在內部部署設施或容器中運行。
責任編輯:PSY
-
谷歌
+關注
關注
27文章
6230瀏覽量
107801 -
人工智能
+關注
關注
1805文章
48873瀏覽量
247695 -
機器學習
+關注
關注
66文章
8499瀏覽量
134283
發布評論請先 登錄
數學專業轉人工智能方向:考研/就業前景分析及大學四年學習路徑全揭秘

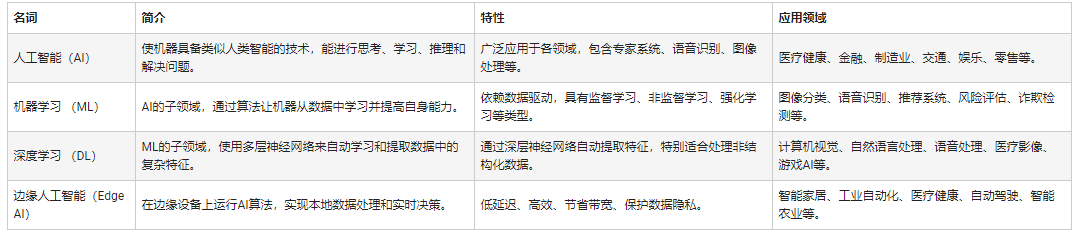
人工智能和機器學習以及Edge AI的概念與應用
【「具身智能機器人系統」閱讀體驗】+初品的體驗
Infosys與谷歌云加強合作,推動企業人工智能創新,建立卓越中心
嵌入式和人工智能究竟是什么關系?
人工智能、機器學習和深度學習存在什么區別






 工商網監
工商網監
評論