") 如何優(yōu)雅地使用bert處理長(zhǎng)文本
如何優(yōu)雅地使用bert處理長(zhǎng)文本
這是今年清華大學(xué)及阿里巴巴發(fā)表在NIPS 2020上的一篇論文《CogLTX: Applying BERT to Long Texts》,介紹了如何優(yōu)雅地使用bert處理長(zhǎng)文本。作者同時(shí)開源了不同NLP任務(wù)下使用COGLTX的代碼:
論文題目:
CogLTX: Applying BERT to Long Texts
論文鏈接:
http://keg.cs.tsinghua.edu.cn/jietang/publications/NIPS20-Ding-et-al-CogLTX.pdf
Github:
https://github.com/Sleepychord/CogLTX
bert在長(zhǎng)文本處理一般分為三種方法[1]:
截?cái)喾ǎ?/p>
Pooling法;
壓縮法。
該論文就是壓縮法的一種,是三種方法中最好的。我們?cè)诳蒲泻凸ぷ髦卸紩?huì)遇到該問題,例如我最近關(guān)注的一個(gè)文本分類比賽:
面向數(shù)據(jù)安全治理的數(shù)據(jù)內(nèi)容智能發(fā)現(xiàn)與分級(jí)分類 競(jìng)賽 - DataFountain[2].
其文本數(shù)據(jù)長(zhǎng)度就都在3000左右,無法將其完整輸入bert,使用COGLTX就可以很好地處理該問題,那么就一起來看看該論文具體是怎么做的吧。
1.背景
基于以下情形:
bert作為目前最優(yōu)秀的PLM,不用是不可能的;
長(zhǎng)文本數(shù)據(jù)普遍存在,且文本中包含的信息非常分散,難以使用滑動(dòng)窗口[3]截?cái)唷?/p>
而由于bert消耗計(jì)算資源和時(shí)間隨著token的長(zhǎng)度是平方級(jí)別增長(zhǎng)的,所以其無法處理太長(zhǎng)的token,目前最長(zhǎng)只支持512個(gè)token,token過長(zhǎng)也很容易會(huì)內(nèi)存溢出,所以在使用bert處理長(zhǎng)文本時(shí)需要設(shè)計(jì)巧妙的方法來解決這個(gè)問題。

2.提出模型
COGLTX模型在三類NLP任務(wù)中的結(jié)構(gòu)如下:
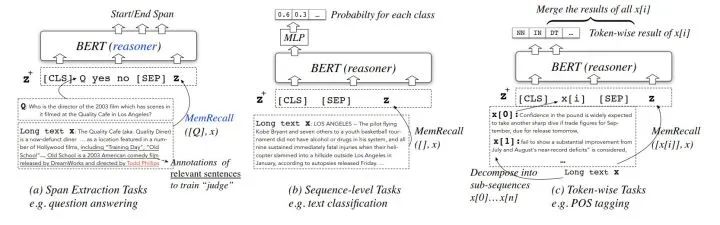
首先假設(shè):存在短文本 可以完全表達(dá)原長(zhǎng)文本 的語義:
那么令 代替 輸入原來的模型即可,那么怎么找到這個(gè) 呢
1、使用動(dòng)態(tài)規(guī)劃算法將長(zhǎng)文本 劃分為文本塊集合 ;
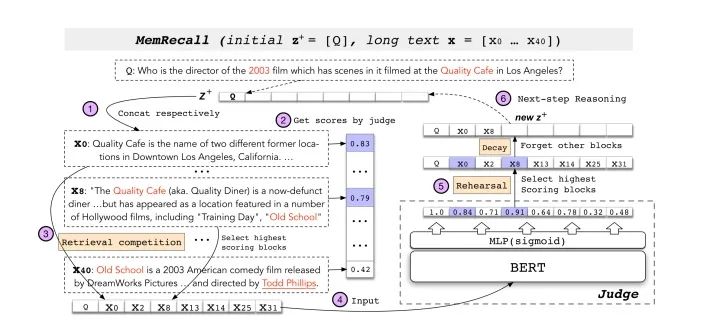
2、使用MemRecall對(duì)原長(zhǎng)句中的子句進(jìn)行打分,MemRecall結(jié)構(gòu)如圖,而表現(xiàn)如下式:
從而選擇出分?jǐn)?shù)最高的子句組成 再進(jìn)行訓(xùn)練,這樣一來的話,COGLTX相當(dāng)于使用了了兩個(gè)bert,MemRecall中bert就是負(fù)責(zé)打分,另一個(gè)bert執(zhí)行原本的NLP任務(wù)。
可以發(fā)現(xiàn)剛才找到 例子將問題Q放在了初始化 的開頭,但是并不是每個(gè)NLP任務(wù)都可以這么做,分類的時(shí)候就沒有類似Q的監(jiān)督,這時(shí)候COGLTX采用的策略是將每個(gè)子句從原句中移除判斷其是否是必不可少的(t是一個(gè)閾值):
作者通過設(shè)計(jì)不同任務(wù)下的MemRecall實(shí)現(xiàn)了在長(zhǎng)文本中使用bert并通過實(shí)驗(yàn)證明了方法的有效性。
3.實(shí)驗(yàn)
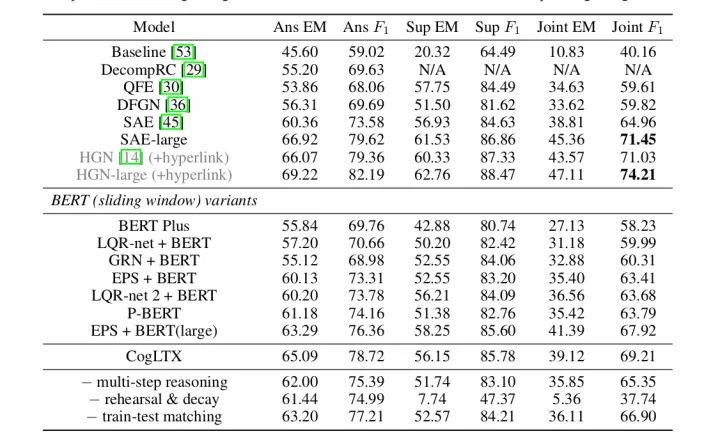
通過多維度地對(duì)比,證明了本文提出算法的有效性。
參考文獻(xiàn)
[1]https://zhuanlan.zhihu.com/p/88944564
[2]https://www.datafountain.cn/competitions/471
[3]Z. Wang, P. Ng, X. Ma, R. Nallapati, and B. Xiang. Multi-passage bert: A globally normalized bert model for open-domain question answering. arXiv preprint arXiv:1908.08167, 2019.
責(zé)任編輯:xj
原文標(biāo)題:【NIPS 2020】通過文本壓縮,讓BERT支持長(zhǎng)文本
文章出處:【微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
文本
+關(guān)注
關(guān)注
0文章
119瀏覽量
17383 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22524
原文標(biāo)題:【NIPS 2020】通過文本壓縮,讓BERT支持長(zhǎng)文本
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
把樹莓派打造成識(shí)別文本的“神器”!

?VLM(視覺語言模型)?詳細(xì)解析

飛凌RK3588開發(fā)板上部署DeepSeek-R1大模型的完整指南(一)

BQ3588/BQ3576系列開發(fā)板深度融合DeepSeek-R1大模型
阿里云通義開源長(zhǎng)文本新模型Qwen2.5-1M
Linux三劍客之Sed:文本處理神器

如何使用自然語言處理分析文本數(shù)據(jù)
圖紙模板中的文本變量
如何在文本字段中使用上標(biāo)、下標(biāo)及變量






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論