 ARM攢機指南 - 基礎篇
ARM攢機指南 - 基礎篇
本文轉載于極術社區
極術專欄:ARM攢機指南
作者:djygrdzh
CCI400是怎么做到硬件一致性的呢?簡單來說,就是處理器組C1,發一個包含地址信息的特殊讀寫的命令到總線,然后總線把這個命令轉給另一個處理器組C2。C2收到請求后,根據地址逐步查找二級和一級緩存,如果發現自己也有,那么就返回數據或者做相應的緩存一致性操作,這個過程稱作snooping(監聽)。
具體的操作我不展開,ARM使用MOESI一致性協議,里面都有定義。在這個過程中,被請求的C2中的處理器核心并不參與這個過程,所有的工作由緩存和總線接口單元BIU等部件來做。
為了符合從設備不主動發起請求的定義,需要兩組主從設備,每個處理器組占一個主和一個從。這樣就可以使得兩組處理器互相保持一致性。而有些設備如DMA控制器,它本身不包含緩存,也不需要被別人監聽,所以它只包含從設備,如上圖桔黃色的部分。在ARM的定義中,具有雙向功能的接口被稱作ACE,只能監聽別人的稱作ACE-Lite。它們除了具有AXI的讀寫通道外,還多了個監聽通道。
多出來的監聽通道,同樣也有地址(從到主),回應(主到從)和數據(主到從)。每組信號內都包含和AXI一樣的標志符,用來支持多OT。如果在主設備找到數據(稱為命中),那么數據通道會被使用,如果沒有,那告知從設備未命中就可以了,不需要傳數據。由此,對于上文的DMA控制器,它永遠不可能傳數據給別人,所以不需要數據組,這也就是ACE和ACE-Lite的主要區別。
我們還可以看到,在讀通道上有個額外的線RACK,它的用途是,當從設備發送讀操作中的數據給主,它并不知道何時主能收到這個數據,因為我們說過插入寄存器會導致總線延遲變長。萬一這個時候,對同樣的地址A,它需要發送新的監聽請求給主,就會產生一個問題:主是不是已經收到前面發出的地址A的數據了呢?如果沒收到,那它可能會告知監聽未命中。但實際上地址A的數據已經發給主了,它該返回命中。加了這個RACK后,從設備在收到主給的確認RACK之前,不會發送新的監聽請求給主,從而避免了上述問題。寫通道上的WACK同樣如此。
我們之前計算過NIC400上的延遲,有了CCI400的硬件同步,是不是訪問更快了呢?首先,硬件一致性的設計目的不是為了更快,而是軟件更簡單。而實際上,它也未必就快。因為給定一個地址,我們并不知道它是不是在另一組處理器的緩存內,所以無論如何都需要額外的監聽動作。當未命中的時候,這個監聽動作就是多余的,因為我們還是得從內存去抓數據。這個多余的動作就意味著額外的延遲,10加10一共20個總線周期,增長了100%。當然,如果命中,雖然總線總共上也同樣需要10周期,可是從緩存拿數據比從內存拿快些,所以此時是有好處的。綜合起來看,當命中大于一定比例,總體還是受益的。
可從實際的應用程序情況來看,除了特殊設計的程序,通常命中不會大于10%。所以我們必須想一些辦法來提高性能。一個辦法就是,無論結果是命中還是未命中,都讓總線先去內存抓數據。等到數據抓回來,我們也已經知道監聽的結果,再決定把哪邊的數據送回去。這個辦法的缺點,功耗增大,因為無論如何都要去讀內存。第二,在內存訪問本身就很頻繁的時候,這么做會降低總體性能。
另外一個方法就是,如果預先知道數據不在別的處理器組緩存,那就可以讓發出讀寫請求的主設備,特別注明不需要監聽,總線就不會去做這個動作。這個方法的缺點就是需要軟件干預,雖然代價并不大,分配操作系統頁面的時候設下寄存器就可以,可是對程序員的要求就高了,必須充分理解目標系統。
CCI總線還使用了一個新的方法來提高性能,那就是在總線里加入一個監聽過濾器(SnoopFilter)。這其實也是一塊緩存(TAG RAM),把它所有處理器組內部一級二級緩存的狀態信息都放在里面。數據緩存(DATA RAM)是不需要的,因為它只負責查看命中與否。這樣做的好處就是,監聽請求不必發到各組處理器,在總線內部就可以完成,省了將近10個總線周期,功耗也優于訪問內存。它的代價是增加了一點緩存(一二級緩存10%左右的容量)。并且,如果監聽過濾器里的某行緩存被替換(比如寫監聽命中,需要無效化(Invalidate)緩存行,MOESI協議定義),同樣的操作必須在對應處理器組的一二級緩存也做一遍,以保持一致性。這個過程被稱作反向無效化,它添加了額外的負擔,因為在更新一二級緩存的時候,監聽過濾器本身也需要追蹤更新的狀態,否則就無法保證一致性。幸好,在實際測試中發現,這樣的操作并不頻繁,一般不超過5%的可能性。當然,有些測試代碼會頻繁的觸發這個操作,此時監聽過濾器的缺點就顯出來了。
以上的想法在CCI500中實現,示意圖如下:
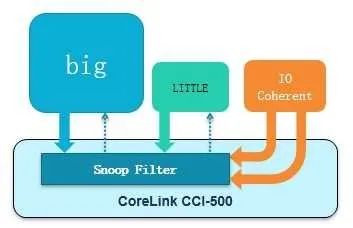
在經過實際性能測試后,CCI設計人員發現總線瓶頸移到了訪問這個監聽過濾器的窗口,這個瓶頸其實掩蓋了上文的反向無效化問題,它總是先于反向無效化被發現。把這個窗口加大后,又在做測試時發現,如果每個主從接口都拼命灌數據(主從設備都是OT無限大,并且一主多從有前后交叉),在主從設備接口處經常出現等待的情況,也就是說,明明數據已經準備好了,設備卻來不及接收。于是,又增加了一些緩沖來存放這些數據。其代價是稍大的面積和功耗。請注意,這個緩沖和存放OT的狀態緩沖并不重復。
根據實測數據,在做完所有改進后,新的總線帶寬性能同頻增加50%以上。而頻率可以從500Mhz提高到1GMhz。當然這個結果只是一個模糊的統計,如果我們考慮處理器和內存控制器OT數量有限,被監聽數據的百分比有不同,命中率有變化,監聽過濾器大小有變化,那肯定會得到不同的結果。
作為一個手機芯片領域的總線,需要支持傳輸的多優先級也就是QoS。因為顯示控制器等設備對實時性要求高,而處理器組的請求也很重要。支持QoS本身沒什么困難,只需要把各類請求放在一個緩沖,根據優先級傳送即可。但是在實際測試中,發現如果各個設備的請求太多太頻繁,緩沖很快就被填滿,從而阻塞了新的高優先級請求。為了解決這個問題,又把緩沖按優先級分組,每一組只接受同等或更高優先級的請求,這樣就避免了阻塞。
此外,為了支持多時鐘和電源域,使得每一組處理器都可以動態調節電壓和時鐘頻率,CCI系列總線還可以搭配異步橋ADB(Asynchronous Domain Bridge)。它對于性能有一定的影響,在倍頻是2的時候,信號穿過它需要一個額外的總線時鐘周期。如果是3,那更大些。在對于訪問延遲有嚴格要求的系統里面,這個時間不可忽略。如果不需要額外的電源域,我們可以不用它,省一點延遲。NIC/CCI/CCN/NoC總線天然就支持異步傳輸。
和一致性相關的是訪存次序和鎖,有些程序員把它們搞混了。假設我們有兩個核C0和C1。當C0和C1分別訪問同一地址A0,無論何時,都要保證看到的數據一致,這是一致性。然后在C0里面,它需要保證先后訪問地址A0和A1,這稱作訪問次序,此時不需要鎖,只需要壁壘指令。如果C0和C1上同時運行兩個線程,當C0和C1分別訪問同一地址A0,并且需要保證C0和C1按照先后次序訪問A0,這就需要鎖。所以,單單壁壘指令只能保證單核單線程的次序,多核多線程的次序需要鎖。而一致性保證了在做鎖操作時,同一變量在緩存或者內存的不同拷貝,都是一致的。
ARM的壁壘指令分為強壁壘DSB和弱壁壘DMB。我們知道讀寫指令會被分成請求和完成兩部分,強壁壘要求上一條讀寫指令完成后才能開始下一個請求,弱壁壘則只要求上一條讀寫指令發出請求后就可以繼續下一條讀寫指令的請求,且只能保證,它之后的讀寫指令完成時,它之前的讀寫指令肯定已經完成了。顯然,后一種情況性能更高,OT》1。但測試表明,多個處理器組的情況下,壁壘指令如果傳輸到總線,只能另整體系統性能降低,因此在新的ARM總線中是不支持壁壘的,必須在芯片設計階段,通過配置選項告訴處理器自己處理壁壘指令,不要送到總線。但這并不影響程序中的壁壘指令,處理器會在總線之前把它過濾掉。
具體到CCI總線上,壁壘機制是怎么實現的呢?首先,壁壘和讀寫一樣,也是使用讀寫通道的,只不過它地址總是0,且沒有數據。標志符也是有的,此外還有額外的2根線BAR0/1,表明本次傳輸是不是壁壘,是哪種壁壘。他是怎么傳輸的呢?先看弱壁壘,如下圖:
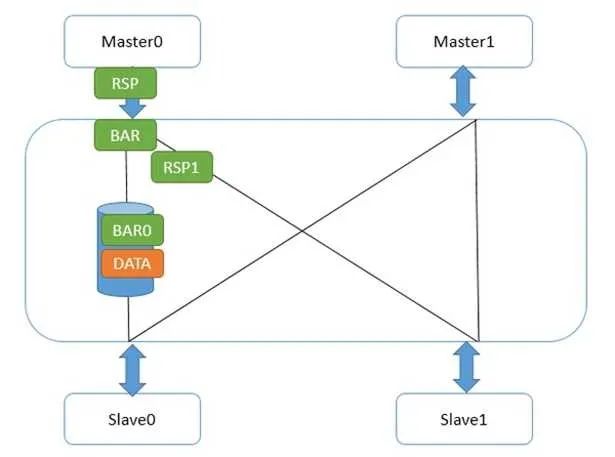
Master0寫了一個數據data,然后又發了弱壁壘請求。CCI和主設備接口的地方,一旦收到壁壘請求,立刻做兩件事,第一,給Master0發送壁壘響應;第二,把壁壘請求發到和從設備Slave0/1的接口。Slave1接口很快給了壁壘響應,因為它那里沒有任何未完成傳輸。而Slave0接口不能給壁壘響應,因為data還沒發到從設備,在這條路徑上的壁壘請求必須等待,并且不能和data的寫請求交換次序。這并不能阻撓Master0發出第二個數據,因為它已經收到它的所有下級(Master0接口)的壁壘回應,所以它又寫出了flag。如下圖:
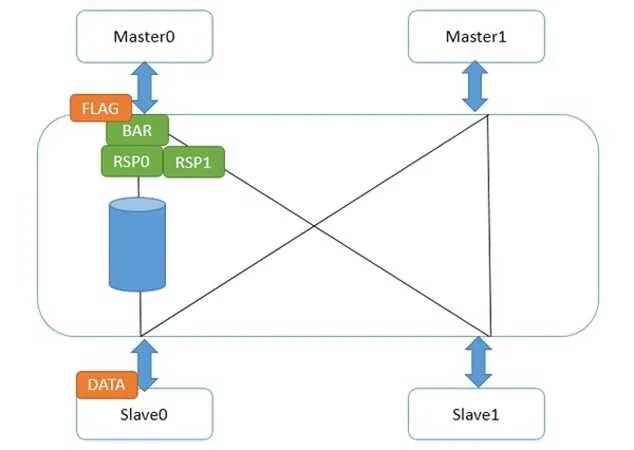
此時,flag在Master0接口中等待它的所有下一級接口的壁壘響應。而data達到了Slave0后,壁壘響應走到了Master0接口,flag繼續往下走。此時,我們不必擔心data沒有到slave0,因為那之前,來自Slave0接口的壁壘響應不會被送到Master0接口。這樣,就做到了弱壁壘的次序保證,并且在壁壘指令完成前,flag的請求就可以被送出來。
對于強壁壘指令來說,僅僅有一個區別,就是Master0接口在收到所有下一級接口的壁壘響應前,它不會發送自身的壁壘響應給Master0。這就造成flag發不出來,直到壁壘指令完成。如下圖:
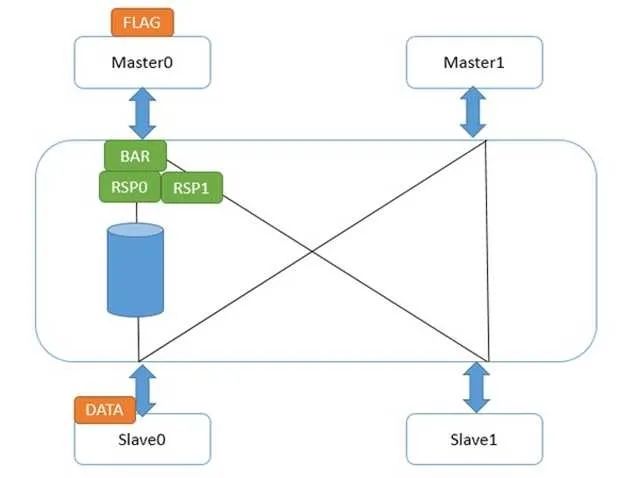
這樣,就保證了強壁壘完成后,下一條讀寫指令才能發出請求。此時,強壁壘前的讀寫指令肯定是完成了的。
另外需要特別注意的是,ARM的弱壁壘只是針對顯式數據訪問的次序。什么叫顯式數據訪問?讀寫指令,緩存,TLB操作都算。相對的,什么是隱式數據訪問?在處理器那一節,我們提到,處理器會有推測執行,預先執行讀寫指令;緩存也有硬件預取機制,根據之前數據訪問的規律,自動抓取可能用到的緩存行。這些都不包含在當前指令中,弱壁壘對他們無能為力。因此,切記,弱壁壘只能保證你給出的指令次序,并不能保證在它們之間沒有別的模塊去訪問內存,哪怕這個模塊來自于同一個核。
簡單來說,如果只需要保證讀寫次序,用弱壁壘;如果需要某個讀寫指令完成才能做別的事情,用強壁壘。以上都是針對普通內存類型。當我們把類型設成設備時,自動保證強壁壘。
我們提到,壁壘只是針對單核。在多核多線程時,哪怕使用了壁壘指令,也沒法保證讀寫的原子性。解決辦法有兩個,一個是軟件鎖,一個是原子操作。AXI/ACE協議不支持原子操作。所以手機通常需要用到軟件鎖。
軟件鎖中有個自旋鎖,能用一個ARM硬件機制exclusive access來實現。當使用特殊指令對一個地址寫入值,相應緩存行上會做一個特殊標記,表示還沒有別的核去寫這行緩存。然后下條指令讀這個行,如果標記沒變,說明寫和讀之間沒有人打擾,那么就拿到鎖了。如果變了,那么回到寫的過程重新獲取鎖。由于緩存一致性,這個鎖變量可以被多個核與線程使用。當然,過程中還是需要壁壘指令來保證次序。
在支持ARMv8.2和AMBA 5.0 CHI接口的系統中,原子操作被重新引入。在硬件層面,其實原子操作非常容易理解,如果某個數據存在于自己的緩存,那就直接修改;如果存在于別人的緩存,那對所有其他緩存執行Eviction操作,踢出后,放到自己的緩存繼續操作。這個過程其實和exclusive access非常類似。
對于普通內存,還會產生一個問題,就是讀寫操作可能會經過緩存,你不知道數據是否最終寫到了內存中。通常我們使用clean操作來刷緩存。但是刷緩存本身是個模糊的概念,緩存存在多級,有些在處理器內,有些在總線之后,到底刷到哪里算是終結呢?還有,為了保證一致性,刷的時候是不是需要通知別的處理器和緩存?為了把這些問題規范化,ARM引入了Point of Unification/Coherency,Inner/Outer Cacheable和System/Inner/Outer/Non Shareable的概念。
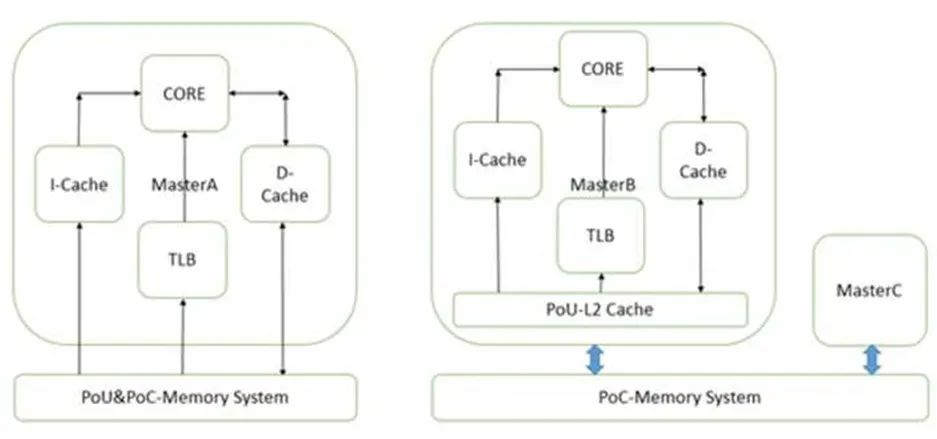
PoU是指,對于某一個核Master,附屬于它的指令,數據緩存和TLB,如果在某一點上,它們能看到一致的內容,那么這個點就是PoU。如上圖右側,MasterB包含了指令,數據緩存和TLB,還有二級緩存。指令,數據緩存和TLB的數據交換都建立在二級緩存,此時二級緩存就成了PoU。而對于上圖左側的MasterA,由于沒有二級緩存,指令,數據緩存和TLB的數據交換都建立在內存上,所以內存成了PoU。還有一種情況,就是指令緩存可以去監聽數據緩存,此時,不需要二級緩存也能保持數據一致,那一級數據緩存就變成了PoU。
PoC是指,對于系統中所有Master(注意是所有的,而不是某個核),如果存在某個點,它們的指令,數據緩存和TLB能看到同一個源,那么這個點就是PoC。如上圖右側,二級緩存此時不能作為PoC,因為MasterB在它的范圍之外,直接訪問內存。所以此時內存是PoC。在左圖,由于只有一個Master,所以內存是PoC。
再進一步,如果我們把右圖的內存換成三級緩存,把內存接在三級緩存后面,那PoC就變成了三級緩存。
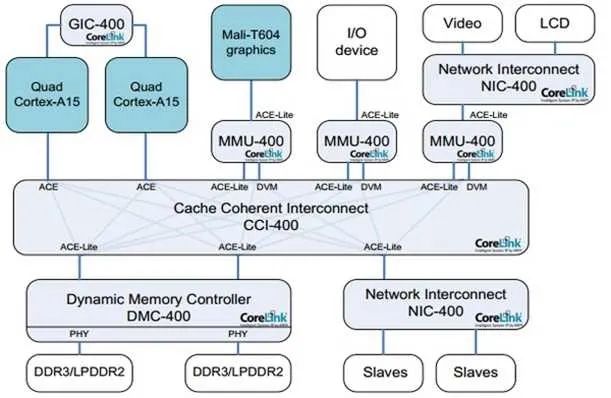
有了這兩個定義,我們就可以指定TLB和緩存操作指令到底發到哪個范圍。比如在下圖的系統上,有兩組A15,每組四個核,組內含二級緩存。系統的PoC在內存,而A15的PoU分別在它們自己組內的二級緩存上。在某個A15上執行Clean清指令緩存,范圍指定PoU。顯然,所有四個A15的一級指令緩存都會被清掉。那么其他的各個Master是不是受影響?那就要用到Inner/Outer/Non Shareable。
Shareable的很容易理解,就是某個地址的可能被別人使用。我們在定義某個頁屬性的時候會給出。Non-Shareable就是只有自己使用。當然,定義成Non-Shareable不表示別人不可以用。某個地址A如果在核1上映射成Shareable,核2映射成Non-Shareable,并且兩個核通過CCI400相連。那么核1在訪問A的時候,總線會去監聽核2,而核2訪問A的時候,總線直接訪問內存,不監聽核1。顯然這種做法是錯誤的。
對于Inner和Outer Shareable,有個簡單的的理解,就是認為他們都是一個東西。在最近的ARM A系列處理器上上,配置處理器RTL的時候,會選擇是不是把inner的傳輸送到ACE口上。當存在多個處理器簇或者需要雙向一致性的GPU時,就需要設成送到ACE端口。這樣,內部的操作,無論inner shareable還是outer shareable,都會經由CCI廣播到別的ACE口上。
說了這么多概念,你可能會想這有什么用處?回到上文的Clean指令,PoU使得四個A7的指令緩存中對應的行都被清掉。由于是指令緩存操作,Inner Shareable屬性使得這個操作被擴散到總線。而CCI400總線會把這個操作廣播到所有可能接受的口上。ACE口首當其沖,所以四個A15也會清它們對應的指令緩存行。對于Mali和DMA控制器,他們是ACE-Lite,本不必清。但是請注意它們還連了DVM接口,專門負責收發緩存維護指令,所以它們的對應指令緩存行也會被清。不過事實上,它們沒有對應的指令緩存,所以只是接受請求,并沒有任何動作。
要這么復雜的定義有什么用?用處是,精確定義TLB/緩存維護和讀寫指令的范圍。如果我們改變一下,總線不支持Inner/Outer Shareable的廣播,那么就只有A7處理器組會清緩存行。顯然這么做在邏輯上不對,因為A7/A15可能運行同一行代碼。并且,我們之前提到過,如果把讀寫屬性設成Non-Shareable,那么總線就不會去監聽其他主,減少訪問延遲,這樣可以非常靈活的提高性能。
再回到前面的問題,刷某行緩存的時候,怎么知道數據是否最終寫到了內存中?對不起,非常抱歉,還是沒法知道。你只能做到把范圍設成PoC。如果PoC是三級緩存,那么最終刷到三級緩存,如果是內存,那就刷到內存。不過這在邏輯上沒有錯,按照定義,所有Master如果都在三級緩存統一數據的話,那就不必刷到內存了。
簡而言之,PoU/PoC定義了指令和命令的所能抵達的緩存或內存,在到達了指定地點后,Inner/Outer Shareable定義了它們被廣播的范圍。
再來看看Inner/Outer Cacheable,這個就簡單了,僅僅是一個緩存的前后界定。一級緩存一定是Inner Cacheable的,而最外層的緩存,比如三級,可能是Outer Cacheable,也可能是Inner Cacheable。他們的用處在于,在定義內存頁屬性的時候,可以在不同層的緩存上有不同的處理策略。
在ARM的處理器和總線手冊中,還會出現幾個PoS(Point of Serialization)。它的意思是,在總線中,所有主設備來的各類請求,都必須由控制器檢查地址和類型,如果存在競爭,那就會進行串行化。這個概念和其他幾個沒什么關系。
縱觀整個總線的變化,還有一個核心問題并沒有被提及,那就是動態規劃re-scheduling與合并Merging。處理器和內存控制器中都有同樣的模塊,專門負責把所有的傳輸進行分類,合并,調整次序,甚至預測未來可能接收到的讀寫請求地址,以實現最大效率的傳輸。這個問題在分析性能時會重新提到。但是在總線這層,軟件能起的影響很小。清楚了總線延遲和OT最大的好處是可以和性能計數器的統計結果精確匹配,看看是不是達到預期了。
現在手機和平板上最常見的用法,CCI連接CPU和GPU,作為子網,網內有硬件一致性。NoC連接子網,同時連接其余的設備,包括多個內存控制器和視頻,顯示控制器,不需要一致性。優點是兼顧一致性,大帶寬和靈活性,缺點是CPU/GPU到內存控制器要跨過兩個網,延遲有點大。
訪存路徑的最后一步是內存。有的程序員認為內存是一個所有地址訪問時間相等的設備,是這樣的么?這要看情況。
DDR地址有三個部分組成,行,bank,列。一旦這三個部分定了,那么就可以選中確定的一個物理頁,通常有2-8KB大小。我們買內存的時候,有3個性能參數,比如10-10-10。這個表示訪問一個地址所需要的三個操作時間,行有效(包括選bank),列選通(命令/數據訪問),還有預充電。前兩個好理解,第三個的意思是,某個內存物理頁暫時用不著,必須關閉,保持電容電壓,否則再次使用這頁數據就丟失了。如果連續的內存訪問都是在同行同bank,那么第一和第三個10都可以省略,每一次訪問只需要10單位時間;同行不同bank,表示需要打開一個新的頁,只有第三個10可以省略,共20單位時間;不同行同bank,那么需要關閉老頁面,打開一個新頁面,預充電沒法省,共30單位時間。
我們得到什么結論?如果控制好物理地址,就能使某段時間內的訪存都集中在一個頁內,從而節省大量的時間。根據經驗,在突發訪問時,最多可以省50%。那怎么做到這一點?去查查芯片手冊中物理內存地址到內存管腳的映射,就可以得到需要的物理地址。然后調用系統函數,為這個物理地址分配虛擬地址,就可以使得程序只訪問某個固定的物理內存頁。
在訪問有些數據結構時,特定的大小和偏移有可能會不小心觸發不同行同bank這個條件。這樣可能每次訪問都是最差情況。為了避免這種最差情況的產生,有些內存控制器可以自動讓最終地址哈希化,打亂原有的不同行同bank條件,從而在一定程度上減少延遲。我們也可以通過計算和調整軟件物理地址來避免上述情況的發生。
在實際的訪問中,通常無法保證訪問只在一個頁中。DDR內存支持同時打開多個頁,比如4個。而通過交替訪問,我們可以同時利用這4個頁,不必等到上一次完成就開始下一個頁的訪問。這樣就可以減少平均延遲。如下圖:
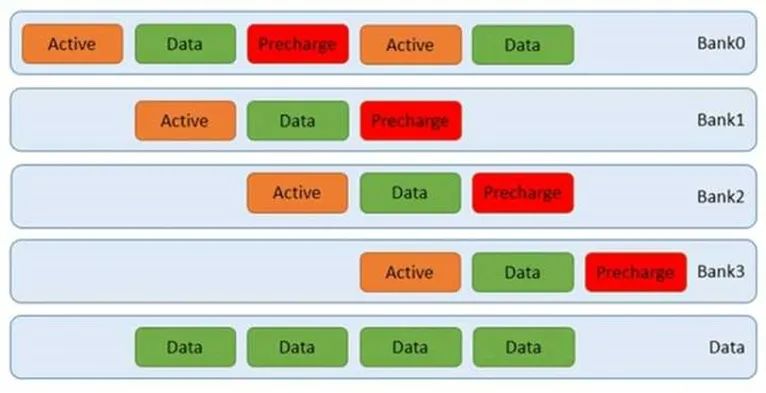
我們可以通過突發訪問,讓上圖中的綠色數據塊更長,那么相應的利用率就越高。此時甚至不需要用到四個bank,如下圖:
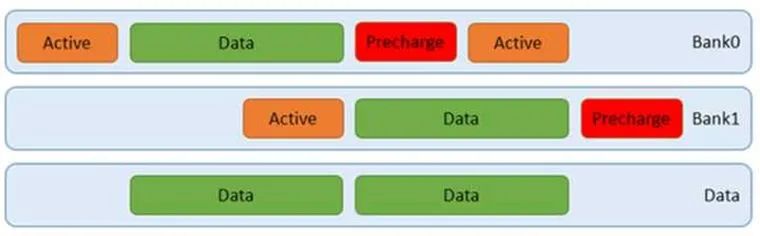
如果做的更好些,我們可以通過軟件控制地址,讓上圖中的預充電,甚至行有效盡量減少,那么就可以達到更高的效率。還有,使用更好的內存顆粒,調整配置參數,減少行有效,列選通,還有預充電的時間,提高DDR傳輸頻率,也是好辦法,這點PC機超頻玩家應該有體會。此外,在DDR板級布線的時候,控制每組時鐘,控制線,數據線之間的長度差,調整好走線阻抗,做好自校準,設置合理的內存控制器參數,調好眼圖,都有助于提高信號質量,從而可以使用更短的時序參數。
如果列出所有數據突發長度情況,我們就得到了下圖:
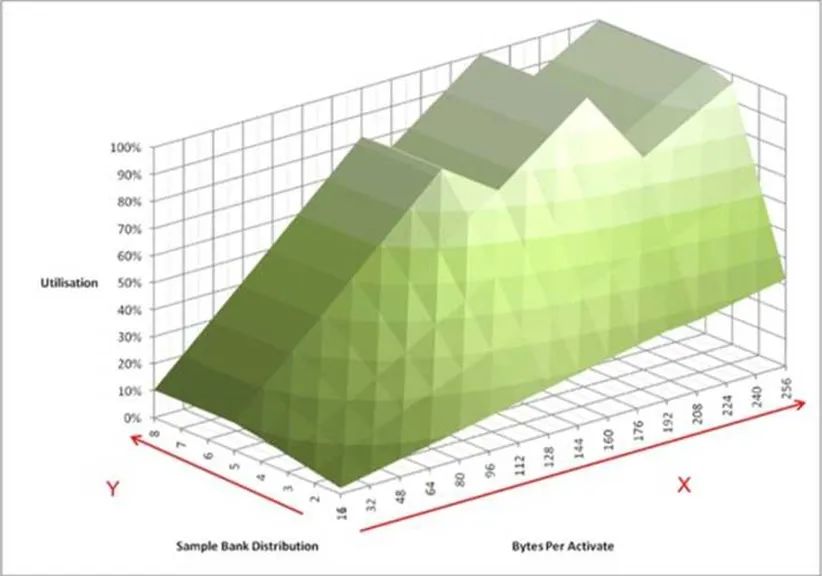
上面這個圖包含了更直觀的信息。它模擬內存控制器連續不斷的向內存顆粒發起訪問。X軸表示在訪問某個內存物理頁的時候,連續地址的大小。這里有個默認的前提,這塊地址是和內存物理頁對齊的。Y軸表示同時打開了多少個頁。Z軸表示內存控制器訪問內存顆粒時帶寬的利用率。我們可以看到,有三個波峰,其中一個在128字節,利用率80%。而100%的情況下,訪問長度分別為192字節和256字節。這個大小恰恰是64字節緩存行的整數倍,意味著我們可以利用三個或者四個8拍的突發訪問完成。此時,我們需要至少4個頁被打開。
還有一個重要的信息,就是X軸和Z軸的斜率。它對應了DDR時序參數中的tFAW,限定單位時間內同時進行的頁訪問數量。這個數字越小,性能可能越低,但是同樣的功耗就越低。
對于不同的DDR,上面的模型會不斷變化。而設計DDR控制器的目的,就是讓利用率盡量保持在100%。要做到這點,需要不斷的把收到的讀寫請求分類,合并,調整次序。而從軟件角度,產生更多的緩存行對齊的讀寫,保持地址連續,盡量命中已打開頁,減少行地址和bank地址切換,都是減少內存訪問延遲的方法。
交替訪問也能提高訪存性能。上文已經提到了物理頁的交替,還可以有片選信號的交替訪問。當有兩個內存控制器的時候,控制器之間還可以交替。無論哪種交替訪問,都是在前一個訪問完成前,同時開始下一個傳輸。當然,前提必須是他們使用的硬件不沖突。物理頁,片選,控制器符合這一個要求。交替訪問之后,原本連續分布在一個控制器的地址被分散到幾個不同的控制器。最終期望的效果如下圖:
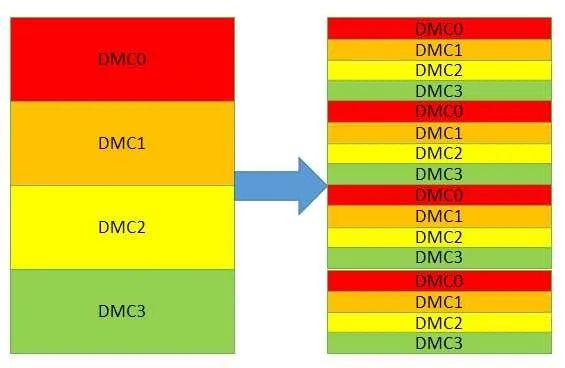
這種方法對連續的地址訪問效果最好。但是實際的訪存并沒有上圖那么理想,因為哪怕是連續的讀,由于緩存中存在替換eviction和硬件預取,最終送出的連續地址序列也會插入擾動,而如果取消緩存直接訪存,可能又沒法利用到硬件的預取機制和額外的OT資源。
實測下來,可能會提升30%左右。此外,由于多個主設備的存在,每一個主都產生不同的連續地址,使得效果進一步降低。因此,只有采用交織訪問才能真正的實現均勻訪問多個內存控制器。
當然,此時的突發長度和粒度要匹配,不然粒度太大也沒法均勻,就算均勻了也未必是最優的。對于某個內存控制來說,最好的期望是總收到同一個物理頁內的請求。
還有一點需要提及。如果使用了帶ecc的內存,那么最好所有的訪問都是ddr帶寬對齊(一般64位)。因為使能ecc后,所有內存訪問都是帶寬對齊的,不然ecc沒法算。如果你寫入小于帶寬的數據,內存控制器需要知道原來的數據是多少,于是就去讀,然后改動其中一部分,再計算新的ecc值,再寫入。這樣就多了一個讀的過程。根據經驗,如果訪存很多,關閉ecc會快8%。
編輯:jq
-
處理器
+關注
關注
68文章
19485瀏覽量
231501 -
數據
+關注
關注
8文章
7217瀏覽量
89916 -
總線
+關注
關注
10文章
2910瀏覽量
88532
原文標題:技術分享 | ARM攢機指南 - 基礎篇
文章出處:【微信號:Ithingedu,微信公眾號:安芯教育科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Arm預測2025年芯片設計發展趨勢
華為PCB的EMC設計指南

迅為iTOP-RK3568開發板驅動開發指南-第十八篇 PWM
【北京迅為】i.mx8mm嵌入式linux開發指南第四篇 嵌入式Linux系統移植篇第六十九章uboot移植

從Renesas RL78到基于Arm的MSPM0的遷移指南

安森美OBC系統解決方案設計指南
安森美光伏逆變器系統設計指南
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
文檔更新 |迅為 RK3568開發板驅動指南-第十五/十六篇
Arm新Arm Neoverse計算子系統(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3

RT-Thread驅動開發指南進階篇-動手驅動先楫未適配的外設LCD





 工商網監
工商網監
評論