") 萬能的prompt還能做可控文本生成
萬能的prompt還能做可控文本生成
可控文本生成,旨在讓語言模型的輸出帶有我們想要的某種屬性。比如情感、主題、三元組等。一般我們習(xí)慣采用 CTRL[1] 或者 PPLM[2] 等方式。但是,CTRL 是對整個語言模型進(jìn)行 Finetuning, PPLM 因?yàn)樾枰谏傻倪^程中迭代更新 hidden activations,所以推理速度非常慢。
隨著 Prompting 技術(shù)的大火,我們一直在思考,Prompt 究竟能夠帶來什么?我們都說,Prompt 本質(zhì)上是一種激發(fā)語言模型中知識的手段。因此,它應(yīng)該不僅僅局限于數(shù)據(jù)集或者說任務(wù)的層面,激發(fā)模型對于某個任務(wù)的“知識”,還應(yīng)該擴(kuò)展到范圍更廣的控制屬性層面,激發(fā)模型對于某種輸出屬性的 sense !
于是,我們不妨把視角從 task scaling 挪開,更多地關(guān)注一下 Prompt 對于可控性的 buff 加成。
今天的這篇文章來自 UCSB 和微軟,提出通過對比學(xué)習(xí)的方法找尋到了這個 buff 一般的 Prompt,能夠“調(diào)教”我們的語言模型進(jìn)行可控的生成。
論文標(biāo)題:
Controllable Natural Language Generation with Contrastive Prefixes
論文作者:
Jing Qian, Li Dong, Yelong Shen, Furu Wei, Weizhu Chen
論文鏈接:
https://arxiv.org/abs/2202.13257
模型方法
首先明確一個概念:Prefix。讀者可以簡單看一下 Prefix-Tuning[3] 的方法圖,就大概知道:Prefix 相當(dāng)于一種控制指令,加在輸入的最前面,以控制生成文本的屬性。
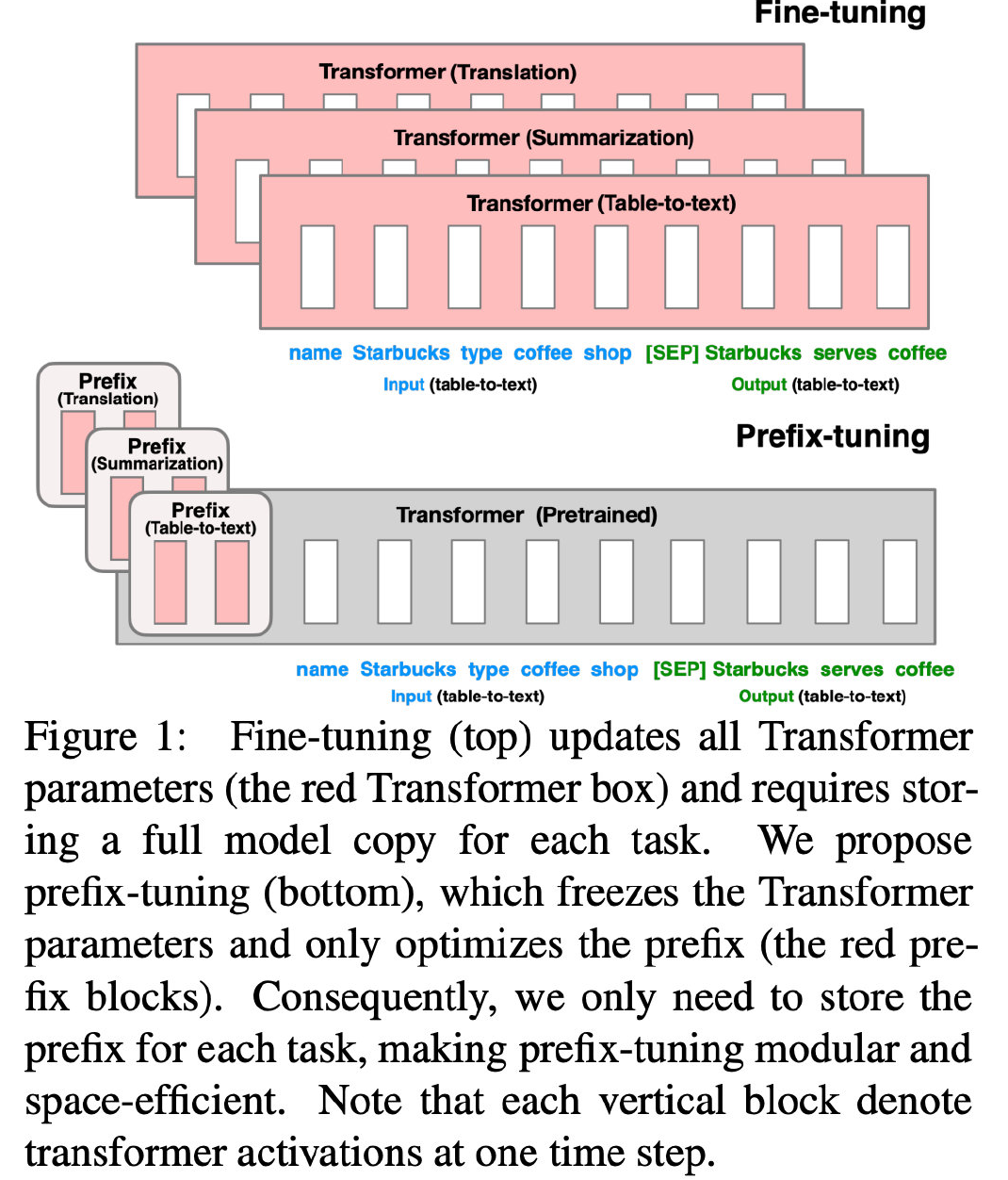
本文提出了兩種方法,分別是監(jiān)督方法和無監(jiān)督方法。
下面的方法介紹以 Sentiment Control 為例(即生成給定帶有情感的文本)。該任務(wù)要訓(xùn)練的,正是 positive 和 negative 的兩種情感類別所對應(yīng)的 prefix.
監(jiān)督方法

整個訓(xùn)練過程和 Prefix-Tuning[3] 相似,LM 的參數(shù)是凍結(jié)的,只調(diào)整 Prefix 相關(guān)聯(lián)的參數(shù)。在訓(xùn)練的時候,除了LM loss 之外,新增一個判別損失:
其中, 代表生成文本, 代表控制信號的類別(positive 或 negative)。
無監(jiān)督方法
在監(jiān)督方法中,控制信號是已知的。實(shí)際場景中還會常常出現(xiàn)控制信號未知的情況,因此需要通過變分的無監(jiān)督方法找到這個“虛擬的類別信號“并使用 latent variable 表征,即 VQ-VAE[4] 的思想。
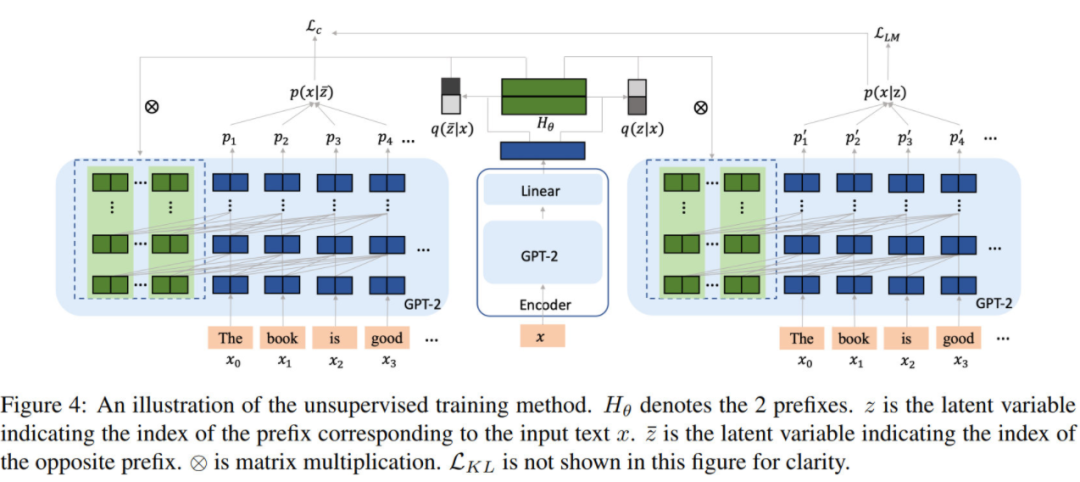
如圖,需要先通過一個 encoder 預(yù)測相應(yīng)輸入對應(yīng)的 latent variable 作為 prefix index(指代當(dāng)前要使用哪個 prefix)。設(shè) prefix index 為 ,則這個 encoder 就是要學(xué)習(xí) 這個分布。
一方面,除了 LM loss ,還需要保證后驗(yàn)概率 或 盡可能的準(zhǔn)確,故引入 KL 散度:
這里的 假設(shè)是 uniform distribution。其中,
GS 表示 Gumbel Softmax, 是 GS 的 temperature 參數(shù)。
關(guān)于這塊兒的詳細(xì)原理,就是我們小學(xué)二年級就學(xué)過的 EM 算法啦~
幫讀者回憶一下:
......
另外,作者又提出了一個無監(jiān)督對比損失:其中, 和 是根據(jù) decoder 的文本生成概率得到的,具體計算方式如下:
最后總的損失函數(shù)為 ,, 的加權(quán)求和,
實(shí)驗(yàn)結(jié)果
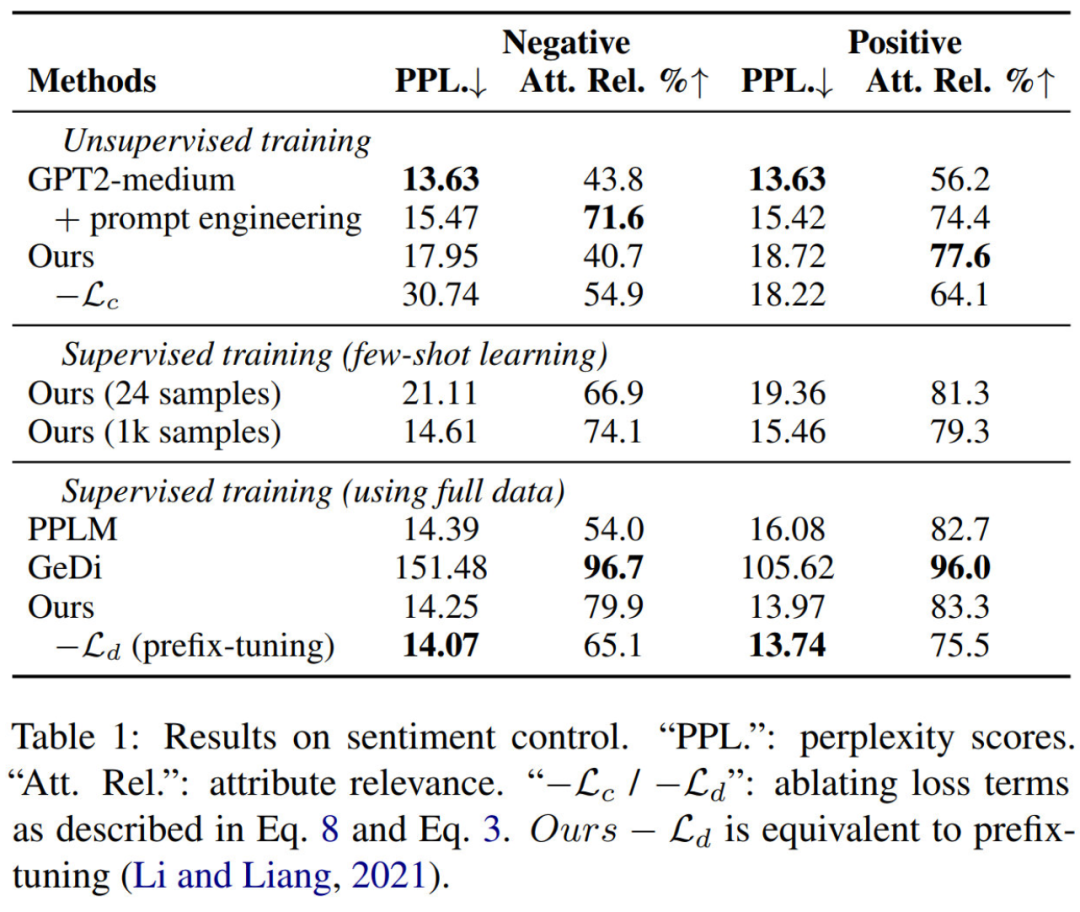
Sentiment Control
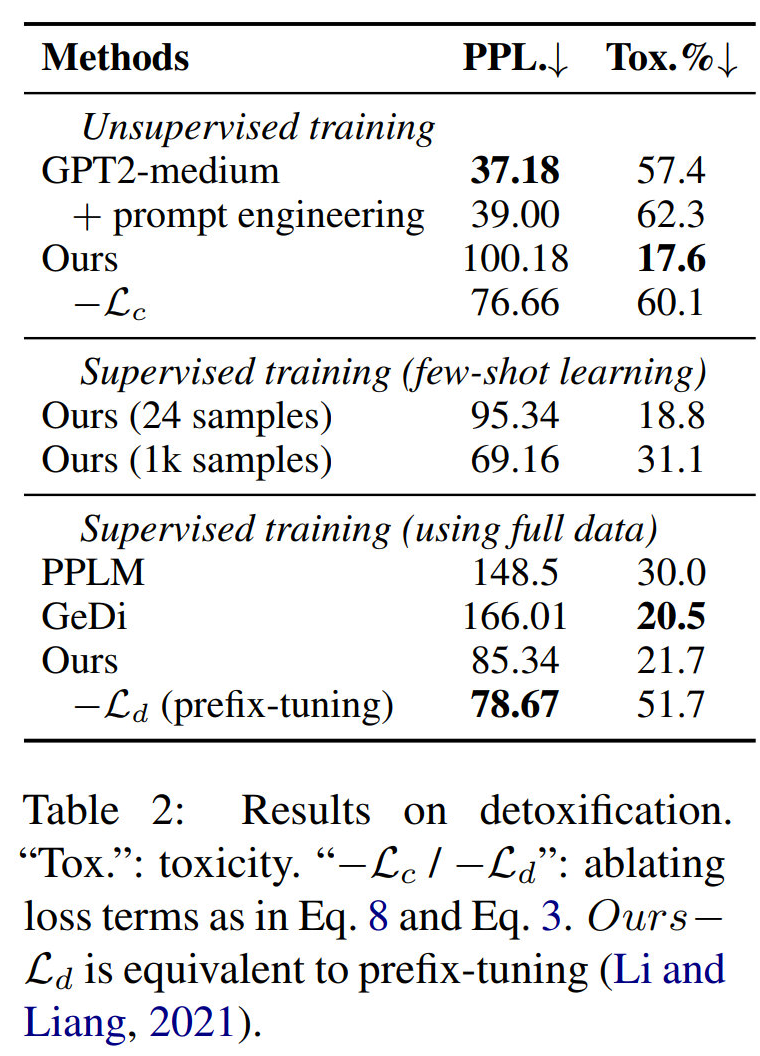
Detoxification
Topic Control
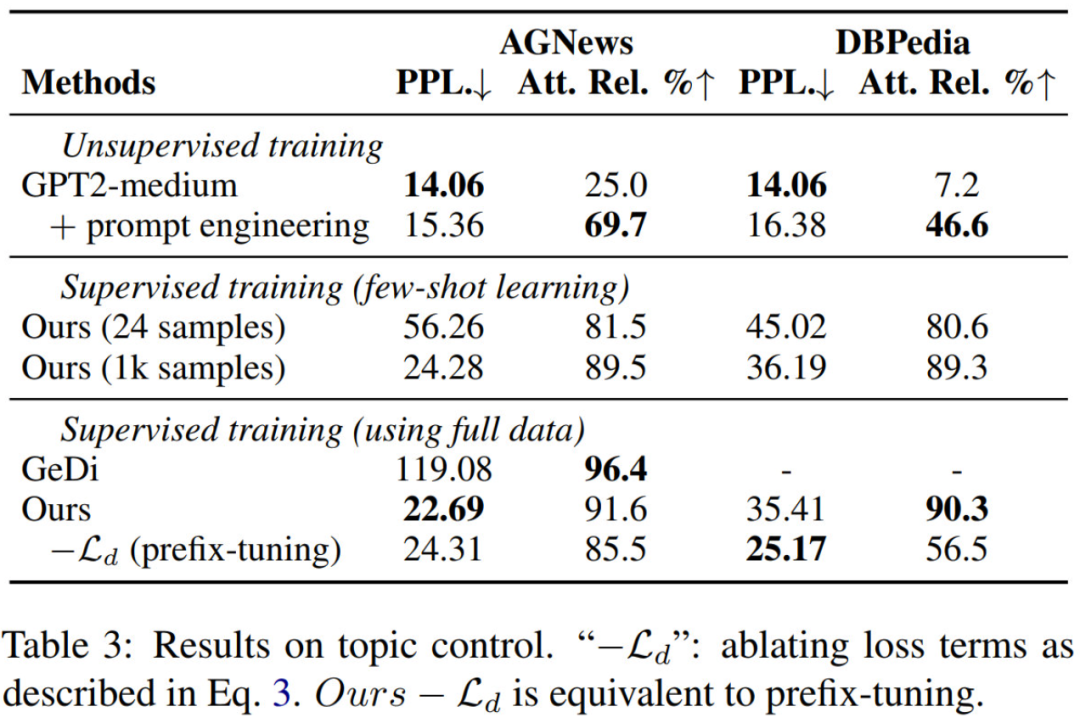
推理速度
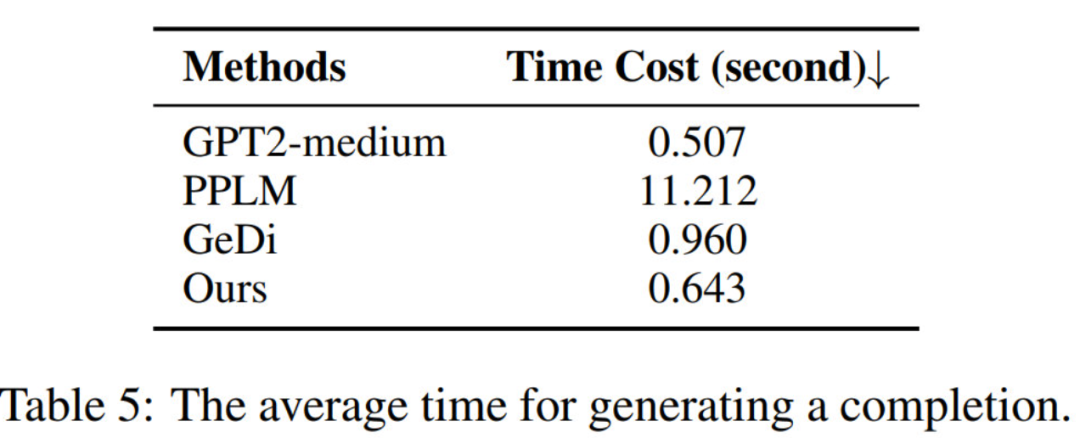
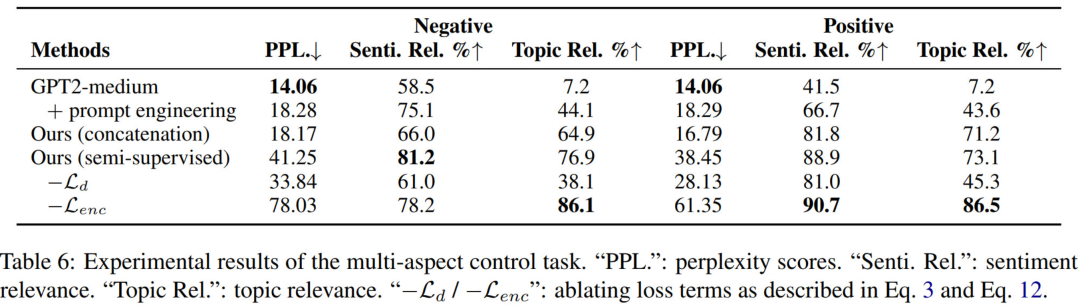
Multi-Aspect Control
實(shí)際場景中,很少有 multi-aspect labeled data,只有 single-aspect labeled data.
本文使用了兩種方式來解決多種屬性的可控生成問題:
Ours (concatenation):使用 single-aspect labeled data 分別訓(xùn)練各自的 prefix, 然后在 multi-aspect control 任務(wù)中將其拼接起來。
Ours (semi-supervised):同時訓(xùn)練 multi-aspect prefixes, 在訓(xùn)練時把 single-aspect labeled example 當(dāng)做 partially labeled. 此外,multi-aspect prefixes 經(jīng)過了 trained single-aspect prefixes 的初始化。
Ours (semi-supervised) 是上述監(jiān)督方法和無監(jiān)督方法的組合,因此架構(gòu)圖和無監(jiān)督方法的圖是一樣的。
寫在最后
這里也推薦讀者品讀一下 DeepMind & ICL 的相似工作:Control Prefixes [5].
古人云:“君子生非異也,善假于物也”。我們把語言模型比作“人”,把可控性比作“物”,也許,大大小小的語言模型在能力的本質(zhì)上并沒有什么不同,但是如果可以通過不同的 Control Prefixes,假之以物,則語言模型可成“君子”也!(哈哈,搞一個俏皮的比喻~)
無論是本文介紹的 Contrastive Prefixes 也好,還是 Control Prefixes 也好,我們都可以從中發(fā)現(xiàn) Prompt 對于”調(diào)教“語言模型的偉大能力。從 task 到 controllability, 可能會是 prompt 向前發(fā)展的又一個新階段吧~
審核編輯 :李倩
-
語言模型
+關(guān)注
關(guān)注
0文章
560瀏覽量
10693 -
prompt
+關(guān)注
關(guān)注
0文章
15瀏覽量
2749
原文標(biāo)題:搭配對比學(xué)習(xí),萬能的 prompt 還能做可控文本生成
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
電子萬能試驗(yàn)機(jī)與液壓萬能試驗(yàn)機(jī)的區(qū)別

萬能遙控器設(shè)置方法_萬能遙控器代碼

萬能轉(zhuǎn)換開關(guān)原理_萬能轉(zhuǎn)換開關(guān)結(jié)構(gòu)
萬能轉(zhuǎn)換開關(guān)選型_萬能轉(zhuǎn)換開關(guān)使用
文本生成任務(wù)中引入編輯方法的文本生成

受控文本生成模型的一般架構(gòu)及故事生成任務(wù)等方面的具體應(yīng)用
基于GPT-2進(jìn)行文本生成
基于VQVAE的長文本生成 利用離散code來建模文本篇章結(jié)構(gòu)的方法
基于文本到圖像模型的可控文本到視頻生成

面向結(jié)構(gòu)化數(shù)據(jù)的文本生成技術(shù)研究

如何使用 Llama 3 進(jìn)行文本生成
效率大升!AI賦能鴻蒙萬能卡片開發(fā)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論