 Merlin HugeCTR 分級參數服務器簡介
Merlin HugeCTR 分級參數服務器簡介
參數服務器是推薦系統的重要組成部分,但是目前的訓練端參數服務器由于高延遲和同步問題無法有效解決推理部署中模型過大的瓶頸。Merlin HugeCTR(以下簡稱 HugeCTR)團隊針對傳統參數服務器的問題重新設計了一種分級推理端參數服務器,將 GPU 內存作為一級緩存,Redis 集群作為二級緩存,RocksDB 作為持久化層,極大提高了推理效率。HugeCTR 團隊將分多期為大家介紹此分級參數服務器的具體設計和細節,本期為系列的第一期。
1. 引言:
傳統訓練端參數服務器及其缺陷
傳統參數服務器維護和同步模型參數僅用于訓練,worker 節點執行前向和后向計算。具體來說,在訓練中:worker 節點從 server 節點中拉取其相應的參數,進行前向計算,通過反向傳播計算梯度,最后將這些梯度推送到服務器。在推理中,它只執行前兩個步驟。如果部署在高性能設備集群中,worker 節點的計算速度非常快,因此傳統 PS 通常會遇到這兩個瓶頸:
(1)server 和 worker 之間的 pull 和 push 操作延遲;
(2)從 worker 節點收到梯度后,server 節點中的參數同步問題。
由于 GPU 停頓、同步/一致性不足,GPU 的計算結構很難通過使用基于 CPU 的實現的參數服務器來支持數據并行。在 GPU 內存中擬合完整模型以及小批量輸入數據和中間網絡狀態的需要限制了可以訓練和推理的模型的大小。同樣的瓶頸也出現在推理部署中,因為推理節點也需要從集中的參數服務器組中拉取所有需要的模型參數。當請求包含節點未加載的參數時,節點需要再次同步從參數服務器拉取參數。當模型參數版本發生變化時,需要暫停推理服務,逐個節點更新參數。
使用基于 CPU 的參數服務器進行模型推理的部署時,上述問題非常明顯,特別是推薦模型的部署。
HugeCTR 推理端分級參數服務器
為了解決上述問題,我們 HugeCTR 團隊設計了一個全新的參數服務器系統,利用分布在多個服務器機器上的 GPU 擴展深度學習應用以進行推理。我們稱為 HugeCTR Hierarchical GPU-based Inference Parameter Server,簡稱為 HPS。HPS 處理在并行模型實例的推理過程中使用的共享模型參數(Embedding 向量和權重)相關的同步和通信。
與其他系統不同,HPS 進行了許多專門針對高效利用 GPU 的優化,包括分布式參數服務器分片,以實現 GPU/CPU 中許多龐大 Embedding Table 的并行推理,以及 GPU 友好的緩存、 臨時數據移動內存、 內存管理機制。
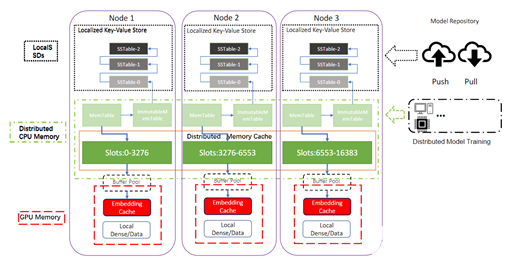
推理端參數服務器的支持
支持不同模型的混合部署:如 DeepFM、DCN、DLRM、MMOE 和序列模型 (DIN、DIEN)
支持推理的大輸入數據量:Batch_size 大于 1K,look_up per request 超過 1000。
支持更快的在線熱部署:將完整模型更新/加載到推理節點進行服務只需不到 10 分鐘(Embedding Table 大小大于 600G)
支持資源隔離:在推理中隔離 GPU 的內存,確保推理服務在生產環境基于不同的隔離策略。例如一種支持單 GPU/CPU 的模型,通過第三方工具(如 k8s)重啟和隔離。
支持不同模型獨立的巨大 Embedding Table:不同模型每個 Embedding Table 大小大于 600G。
支持單個節點的多級緩存:
部分參數(熱特征)可以放入 GPU 內存直接用于推理。
部分參數(冷特征)可以放入 CPU 內存用于 CPU 與 GPU 交換。
Embedding 的其余部分存儲在本地 SSD。
支持模型更新機制:
模型部署支持特定的性能指標,在性能下降時通過版本控制及時回滾。
通過分層緩存機制來重疊數據的轉移以緩解網絡帶寬瓶頸。
使用最小的 PS 分片粒度不間斷更新,而無需逐節點更新。
支持容錯和持久性:一個節點故障后參數和服務可以被恢復。
支持在線學習:每分鐘更新密集模型權重
2. HugeCTR 分級參數服務器組件塊:
CPU 分布式緩存
分布式 Redis 集群
Redis 集群的同步查找:每個模型實例從本地化的 GPU 緩存中查找所需的 Embedding key,這也會將丟失的 Embedding key(在 GPU 緩存中找不到的 key)存儲到丟失的鍵緩沖區中。丟失的鍵緩沖區與 Redis 實例同步交換,Redis 實例依次對任何丟失的 Embedding key 執行查找操作。因此,分布式 Redis 集群充當了二級緩存,可以完全替代本地化參數服務器來加載所有模型的完整 Embedding table。
GPU 緩存(Embedding Cache)
異步/同步插入
我們支持將丟失的 Embedding key 異步插入到 Embedding Cache 中。該功能可以通過配置文件中自定義的命中率閾值自動激活。當 Embedding Cache 的真實命中率高于自定義閾值時,Embedding Cache 會異步插入缺失的 key。反之則會以同步方式插入,以確保推理請求的高精度。通過異步插入方式,與之前的同步方式相比,在 Embedding Cache 達到用戶定義的閾值后,可以進一步提高 Embedding Cache 的真實命中率。
在線更新
我們支持將增量 Embedding Key 異步刷新到 Embedding Cache 中。當稀疏模型文件需要更新到 GPU Embedding Cache 時,會觸發刷新操作。基于在線訓練完成模型的模型版本迭代或增量參數更新后,需要將最新的 Embedding table 更新到推理服務器上的 Embedding Cache 中。為了保證運行模型可以在線更新,我們將通過分布式事件流平臺(Kafka)更新分布式數據庫和持久化數據庫。同時,GPU Embedding Cache 會刷新現有 Embedding key 的值,并替換為最新的增量 Embedding vector。
本地鍵值存儲
本地 RocksDB 查詢引擎
對于仍然無法完全加載到 Redis 集群中的超大規模 Embdding table 我們將在每個節點上啟用本地鍵值存儲(RocksDB)。
RocksDB 的同步查詢:Redis 集群客戶端在分布式 GPU 緩存中查找 Embedding key 時,會記錄丟失的 Embedding key(在 Redis 集群中未找到的 key),記錄到丟失的 key buffer 中。丟失的 key buffer 與本地 RocksDB 客戶端同步交換,然后將嘗試在本地 SSD 中查找這些 key。最終,SSD 查詢引擎將對所有模型缺失的 Embedding key 執行第三次查找操作。
對于已經存儲在云端的模型存儲庫,RocksDB 將作為本地 SSD 緩存,用于存儲 Redis 集群無法加載的剩余部分。因此,在實踐中,本地化的 RocksDB 實例充當了三級緩存。
3. HugeCTR 分級參數服務器的配置和使用:
訓練端
配置模型名和 Kafka broker
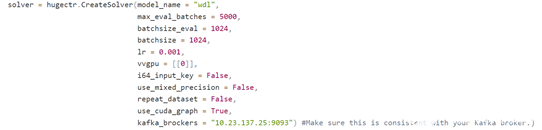
在訓練段,用戶在 CreateSolver 時需要為當前訓練的模型提供一個模型名,這個模型名將會被參數服務器用于區分不同模型。
同時,用戶還需要配置 Kafka broker 的端口和 ip,用于將模型發送到到 Kafka。
增量模型導出接口

用戶可以使用以上接口,將增量模型導出到 Kafka broker,參數服務器端將會自動消化 Kafka 的消息。
推理端
Embedding Cache配置:
gpucache: 用戶可自由配置是否使用 GPU 緩存。
gpucacheper: 用于決定 Embedding table 導入到 GPU 緩存的比例,默認為 0.5。
hit_rate_threshold: 用戶自定義的閾值,將會決定 GPU 緩存的更新方式。
使用 hashmap/parallel hashmap 作為 CPU 緩存時的相關配置:
num_partitions: Embedding table 將會被分為多個分片進行存儲,這里用于指定分片數量。
overflow_policy: 當緩存占滿時,可選擇隨機移除或移除最老的 Embedding。
overflow_margin: 用于指定每個分片儲存的最大 Embedding 數量。
overflow_resolution_target: 用于指定每個分片移除 Embedding 的比例,取值為 0 到 1 之間。
initial_cache_rate: 初始的緩存率。
使用 Redis 作為 CPU 緩存時的相關配置:
需要配置服務器 ip 和端口,用戶名以及密碼,其他與 hashmap/parallel hashmap 相同。需要注意的是 num_partitions 必須大于等于 redis 節點的數量。
RocksDB:
path: RocksDB 存儲數據的路徑,由用戶自行配置。
read_only: 啟用 read_only 后,RocksDB 將無法更新,適用于靜態 Embedding 的推理。
Kafka:
brokers: 用于設置 Kafka 服務器的 ip 和端口。
poll_timeout_ms: 用于數據接收的最大等待時長,超過該時間將自動把參數更新送往數據存儲層。
max_receive_buffer_size: 用于數據接收緩沖區大小,超過該大小將自動把參數更新送往數據存儲層。
max_batch_size: 用于設置每次批量數據發送的大小。
4. 結語
在這一期的 HugeCTR 分級參數服務器簡介中,我們介紹了傳統參數服務器的結構以及 HugeCTR 分級推理參數服務器是如何在其基礎上進行設計和改進的。我們還介紹了我們的三級存儲結構以及相關配置使用。在下一期中,我們將著重介紹 HugeCTR 分級參數服務器各個部件的設計細節,敬請期待。
關于作者
About Yingcan Wei
GPU計算專家,畢業于香港大學,HugeCTR算法組負責人。當前主要從事HugeCTR的算法設計與推理架構工作。研究領域包括深度學習域適應,生成對抗網絡,推薦算法設計優化。在2020年加入英偉達前,任職于歐美外資以及互聯網等企業,擁有多年圖像處理 、數據挖掘,推薦系統設計開發相關經驗。
About Jerry Shi
本科畢業于加州大學伯克利分校,在康奈爾大學獲得碩士文憑。于2021年加入英偉達,在Merlin HugeCTR團隊算法組負責推薦系統架構與算法的相關設計及開發。
審核編輯:郭婷
-
cpu
+關注
關注
68文章
11048瀏覽量
216111 -
gpu
+關注
關注
28文章
4915瀏覽量
130723 -
服務器
+關注
關注
13文章
9717瀏覽量
87361
發布評論請先 登錄
四路串口服務器的功能特點及規格參數簡介
Merlin HugeCTR V3.4.1版本新增內容介紹
GPU加速的推薦程序框架Merlin HugeCTR
Merlin HugeCTR分級參數服務器:緩存和在線更新設計
如何使用NVIDIA Merlin推薦系統框架實現嵌入優化





 工商網監
工商網監
評論