") 領(lǐng)域遷移一種簡單而有效的方法Alter
領(lǐng)域遷移一種簡單而有效的方法Alter
1. 介紹
機(jī)器閱讀理解旨在根據(jù)給定上下文來回答相關(guān)問題,近年來在工業(yè)界與學(xué)術(shù)界均得到了廣泛的關(guān)注,目前最先進(jìn)的系統(tǒng)都是基于預(yù)訓(xùn)練模型構(gòu)建的。即便如此,仍然需要大量標(biāo)注數(shù)據(jù)才能達(dá)到比較理想的結(jié)果,對于一些缺乏大規(guī)模有標(biāo)注數(shù)據(jù)領(lǐng)域和場景,現(xiàn)有模型的遷移效果往往并不令人滿意。相關(guān)工作[1,2]探索利用無標(biāo)注的目標(biāo)領(lǐng)域文本進(jìn)行領(lǐng)域遷移,但這種方法無法使模型對目標(biāo)領(lǐng)域的問題進(jìn)行有效建模。在本文中,我們利用少量的標(biāo)注數(shù)據(jù),通過對在大規(guī)模有標(biāo)注領(lǐng)域上訓(xùn)練過的模型進(jìn)行遷移,來提高在目標(biāo)領(lǐng)域上的表現(xiàn)。另一方面,基于Transformer的預(yù)訓(xùn)練模型通常包含至少上億個參數(shù),如BERT Base的大小為110M。鑒于目標(biāo)領(lǐng)域只有少量的標(biāo)注數(shù)據(jù),調(diào)整全部參數(shù)以適應(yīng)目標(biāo)領(lǐng)域非常困難,而且也是不必要的。另外,有研究[6]表明大規(guī)模稠密的神經(jīng)網(wǎng)絡(luò)模型有過參數(shù)化(over-parameterized)的趨勢。我們探索只利用一小部分參數(shù)進(jìn)行領(lǐng)域遷移,這些參數(shù)對應(yīng)原稠密神經(jīng)網(wǎng)絡(luò)模型中的一個稀疏子網(wǎng)絡(luò)。此外,我們還引入對自注意力模塊的分析,來找到更具遷移性的稀疏子網(wǎng)絡(luò)。最后,我們在多個目標(biāo)領(lǐng)域上進(jìn)行了實驗,取得超過多種基線方法的效果,我們還對提出的方法進(jìn)行了仔細(xì)的分析。
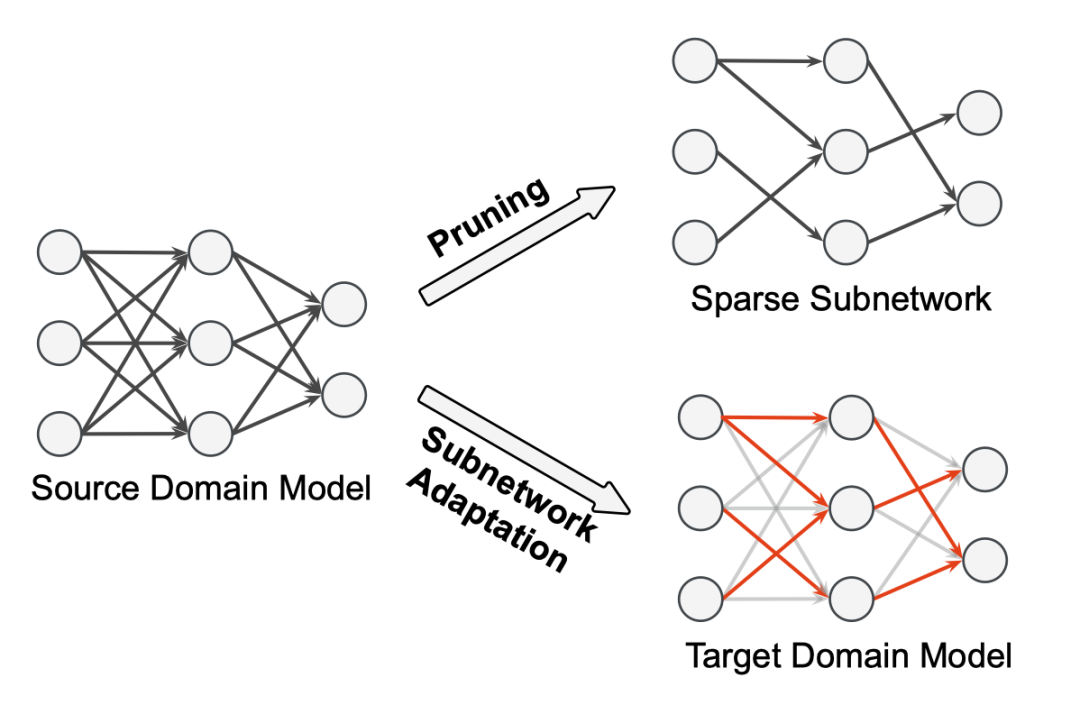
圖1. 基于稀疏子網(wǎng)絡(luò)的領(lǐng)域遷移方法
2. 背景
2.1 Transformer架構(gòu)
如圖2所示,Transformer模型一般由輸入嵌入層、輸出層和若干結(jié)構(gòu)相同的Transformer層堆疊組成。更具體地,每層由一個多頭自注意力模塊和前饋模塊組成,共包含6個參數(shù)矩陣。
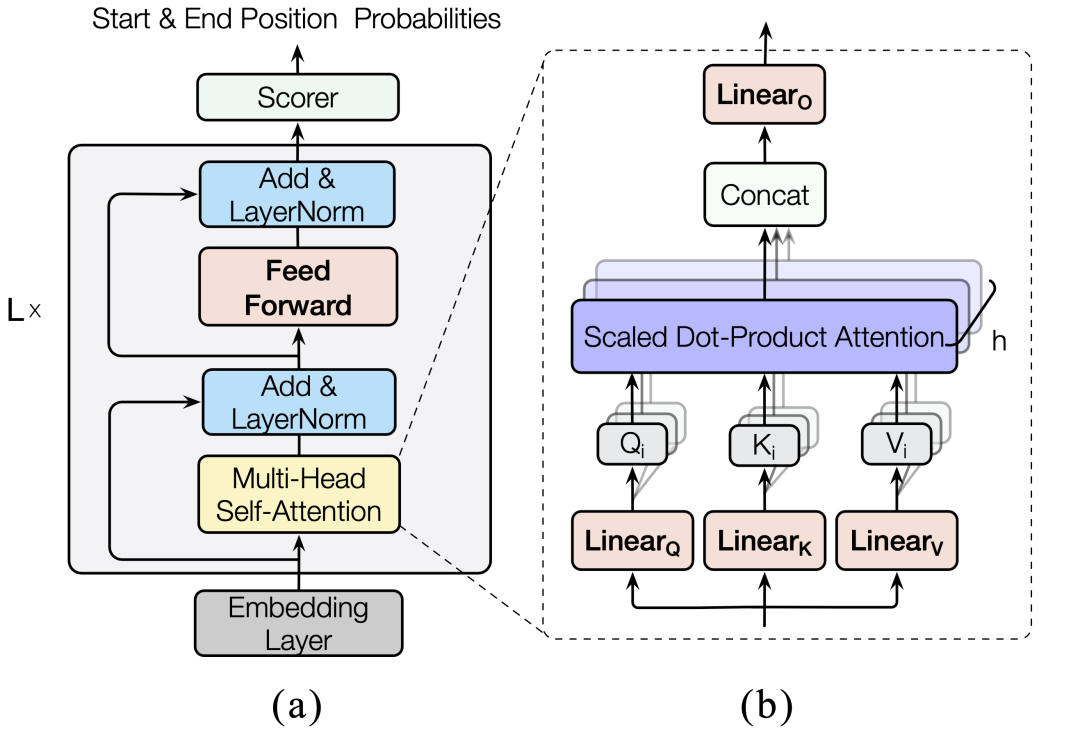
圖2. Transformer模型
2.2 自注意力分析
有許多工作[3,4]嘗試分析解釋Transformer模型的行為,最近,Hao[5]等人提出一種新的分析方法AttAttr可以估計每個自注意力頭對模型輸出的貢獻(xiàn)。本文采用此方法對在不同閱讀理解領(lǐng)域數(shù)據(jù)集上微調(diào)過的BERT模型進(jìn)行分析,如圖3所示,我們發(fā)現(xiàn)重要的注意力頭在不同的領(lǐng)域上呈強(qiáng)正相關(guān)分布,即在一個領(lǐng)域上重要的自注意力頭,也極有可能在其它領(lǐng)域上也非常重要。基于這一發(fā)現(xiàn),我們提出了本文的面向閱讀理解任務(wù)的少樣本領(lǐng)域遷移方法。
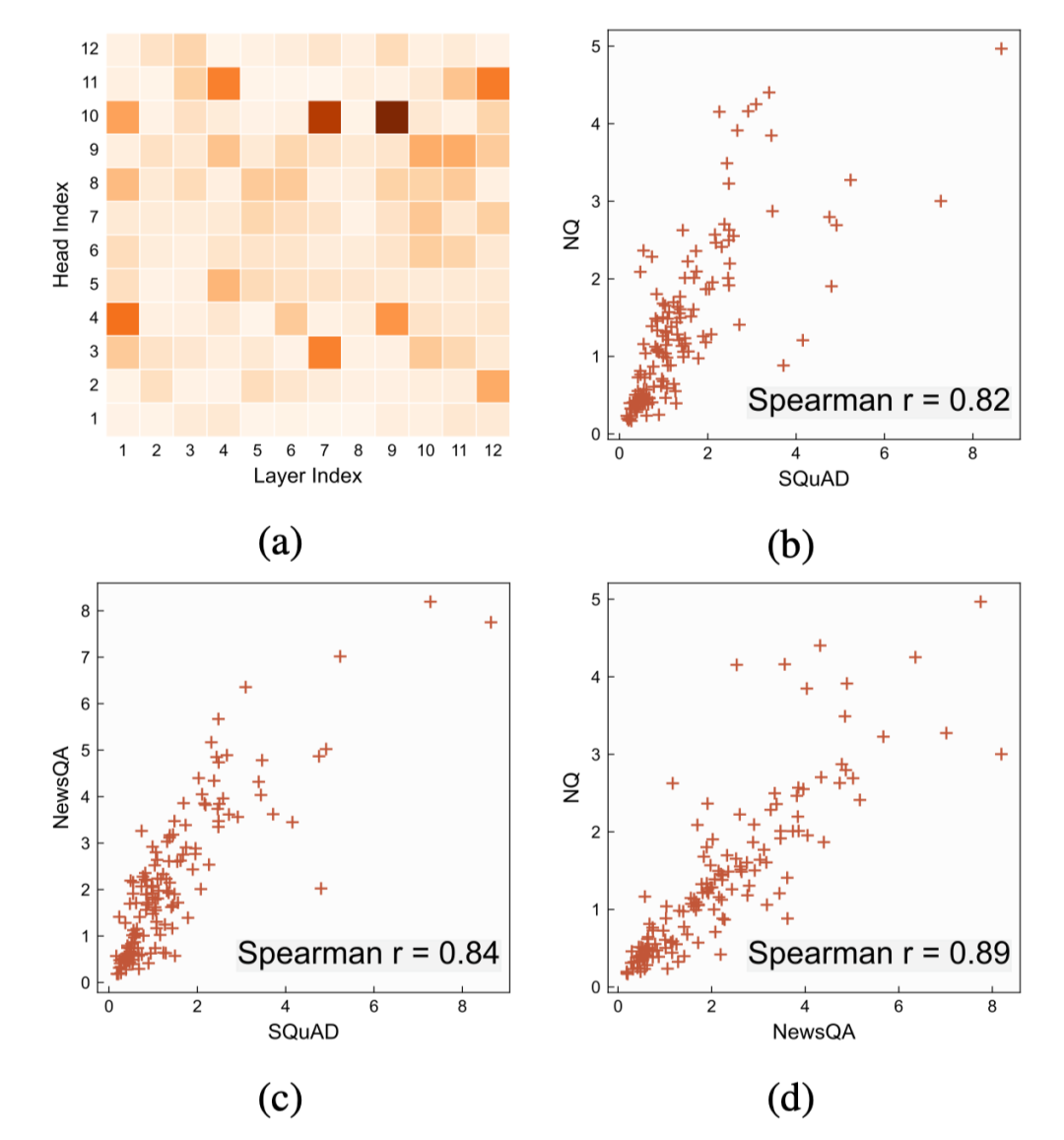
圖3. (a)在SQuADv1.1上的自注意力頭重要性分布。(b)-(d)不同領(lǐng)域上的自注意力頭相關(guān)性分析。每個點(diǎn)對應(yīng)同一個自注意力頭在兩個對應(yīng)的領(lǐng)域上的重要性。
3. 方法
我們在大規(guī)模標(biāo)注數(shù)據(jù)的源領(lǐng)域上訓(xùn)練過的Transformer模型遷移到只有少量標(biāo)注數(shù)據(jù)的目標(biāo)領(lǐng)域上。在遷移時,我們通過減枝來識別只包含少量參數(shù)的稀疏子網(wǎng)絡(luò),并只對子網(wǎng)絡(luò)的參數(shù)進(jìn)行更新來適應(yīng)目標(biāo)領(lǐng)域,在尋找子網(wǎng)絡(luò)時,通過引入自注意力歸因,來同時考慮參數(shù)的結(jié)構(gòu)化與非結(jié)構(gòu)化的重要性。
3.1 子網(wǎng)絡(luò)識別
Magnitude Pruning是一種簡單有效的非結(jié)構(gòu)化減枝方法,這個方法根據(jù)參數(shù)的絕對值大小進(jìn)行減值。我們以該方法為基礎(chǔ),通過迭代的方式分若干步來逐漸刪減參數(shù)到目標(biāo)數(shù)量,并且每次刪減部分參數(shù)后,都會對網(wǎng)絡(luò)進(jìn)行一定步數(shù)的訓(xùn)練,恢復(fù)模型在源領(lǐng)域上的效果,然后再進(jìn)行下一步的參數(shù)刪減。在本文中,我們只對每層Transformer層中的6個參數(shù)矩陣進(jìn)行刪減,其余的參數(shù)矩陣和偏置完全保留。
此外,在進(jìn)行參數(shù)的重要性比較以選擇要刪減的參數(shù)時,通常有兩種策略,一種是所有參數(shù)一起進(jìn)行全局比較,另一種是只在參數(shù)矩陣內(nèi)部進(jìn)行局部比較。在我們對參數(shù)矩陣的分析中發(fā)現(xiàn),不同的參數(shù)矩陣的絕對值均值分布有較大的差異,若采用全局減枝,最后的結(jié)果會很大程度上被均值差異影響,而局部比較則最后所有參數(shù)矩陣具有相同的稀疏度,并且忽略了參數(shù)矩陣本身的所在模塊的重要性。所以,我們提出一種分組比較策略,根據(jù)不同參數(shù)矩陣的均值進(jìn)行分組,在組內(nèi)進(jìn)行全局比較,具體地,將均值相當(dāng)?shù)膮?shù)矩陣分為一組,最后劃分為三組。
根據(jù)之前對閱讀理解任務(wù)的自注意力分析發(fā)現(xiàn),Transformer中的不同自注意力頭對于模型最后的預(yù)測并不是同等重要的,并且重要性的分布在不同的領(lǐng)域上高度正相關(guān)。所以,我們引入自注意力歸因來補(bǔ)充Magnitude Pruning,以期得到能夠更好的遷移到目標(biāo)領(lǐng)域的子網(wǎng)絡(luò)。具體地,在進(jìn)行每一步減枝時,我們先估計出當(dāng)前模型中不同注意力的重要性得分并進(jìn)行歸一化,以此作為對參數(shù)絕對值進(jìn)行縮放,需要注意的是,同一個注意力頭中的參數(shù)矩陣共享同一個重要性得分。此外,還通過超參數(shù)來控制歸因得分對最后參數(shù)重要性的影響。總體來說,通過這種方式,我們同時考慮到了參數(shù)的非結(jié)構(gòu)化與結(jié)構(gòu)化重要性,整體算法如圖4所示。

圖4. 稀疏子網(wǎng)絡(luò)識別算法
3.2 子網(wǎng)絡(luò)遷移
通過上述步驟后,最后剩下的參數(shù)即為找到的子網(wǎng)絡(luò)的結(jié)構(gòu),在進(jìn)行領(lǐng)域適應(yīng)時,我們保留得到的結(jié)構(gòu),但將參數(shù)回滾到減枝前,即源領(lǐng)域模型上的狀態(tài),在后續(xù)的參數(shù)更新時只更新子網(wǎng)絡(luò)對應(yīng)的參數(shù),其余參數(shù)不進(jìn)行梯度更新。但需要注意的是,所有的參數(shù)均參與前向計算過程。
4. 實驗及分析
4.1 數(shù)據(jù)集
在我們的實驗中,以SQuAD為源領(lǐng)域數(shù)據(jù)集,通過對五個目標(biāo)領(lǐng)域數(shù)據(jù)集采樣來模擬少樣本領(lǐng)域遷移的場景,具體的領(lǐng)域數(shù)據(jù)集信息如表1所示。
表1. 數(shù)據(jù)集特征及統(tǒng)計信息

4.2 基線方法
Zero-Shot 不進(jìn)行遷移,直接在目標(biāo)領(lǐng)域上進(jìn)行預(yù)測。
Fine-tuning 微調(diào)源領(lǐng)域模型的全部參數(shù)進(jìn)行領(lǐng)域適應(yīng)。
EWC(Elastic Weight Consolidation) 一種正則化算法,使得參數(shù)在更新時不至大幅偏離原始參數(shù)。
Layer Freeze 只調(diào)整Tranformer模型接近輸出層的若干層的參數(shù),其余參數(shù)則保持不動。
Adapter 保持源領(lǐng)域模型的參數(shù)不動,通過添加并調(diào)整額外的adapter模塊來進(jìn)行領(lǐng)域適應(yīng)。
4.3 實驗結(jié)果與分析
如表2所示,當(dāng)使用1024條目標(biāo)領(lǐng)域標(biāo)注數(shù)據(jù),并將用于領(lǐng)域遷移的參數(shù)數(shù)量限定在21M時,本文提出的Alter在4個目標(biāo)領(lǐng)域上取得了超過基線方法的效果。其中,我們的方法和Layer Freeze還有Adapter調(diào)整數(shù)量相當(dāng)?shù)膮?shù)量來進(jìn)行領(lǐng)域適應(yīng)。在NQ數(shù)據(jù)集上,當(dāng)使用42M參數(shù)時,我們的方法與Fine-tuning表現(xiàn)相當(dāng)。進(jìn)一步地,當(dāng)不對參數(shù)數(shù)量進(jìn)行限制時的實驗結(jié)果如圖5-8所示,除NQ外我們的方法也均取得了超過基線方法的效果,并且通常只需要完整模型的20%-30%的參數(shù)即可。
表2. 使用1024條目標(biāo)領(lǐng)域標(biāo)注數(shù)據(jù)時的EM與F1得分
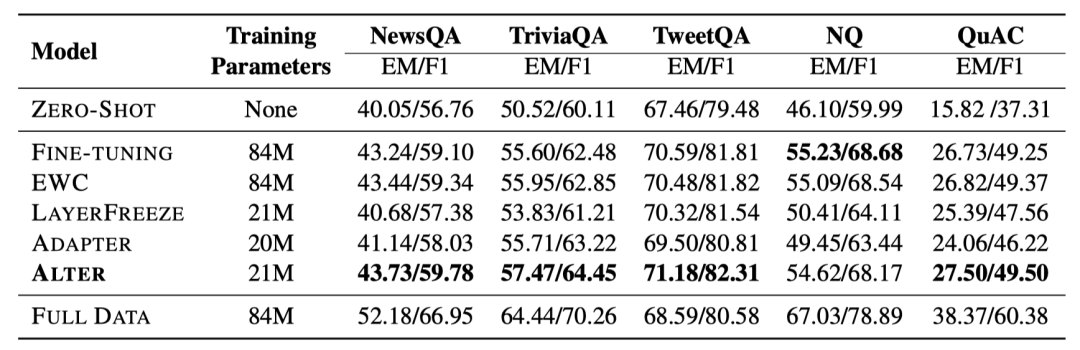
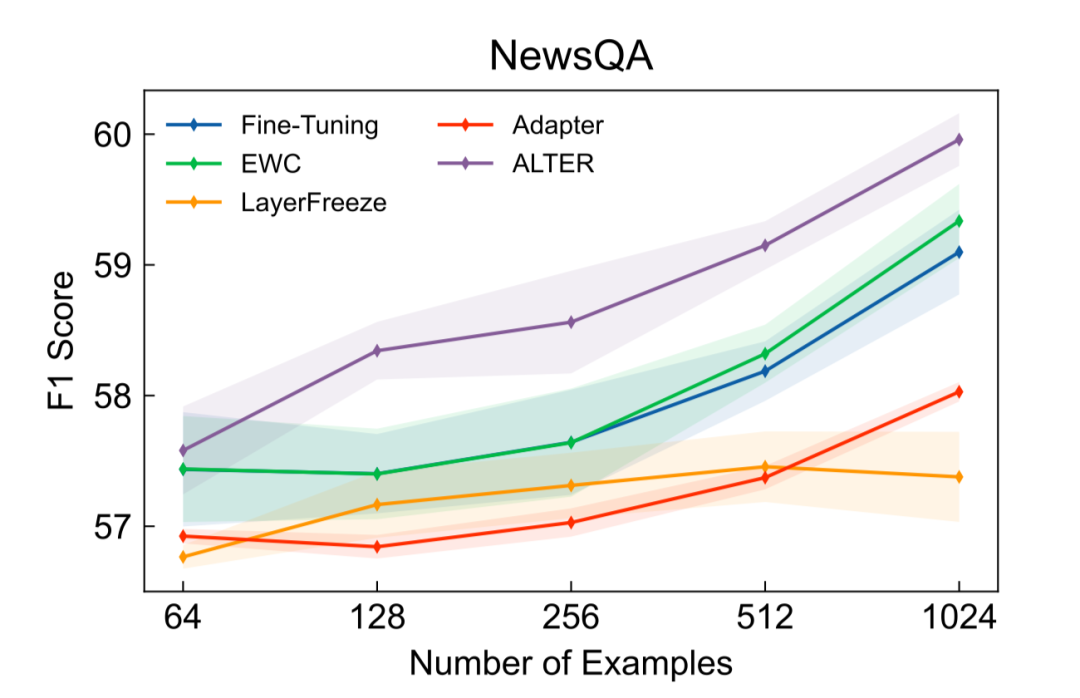
圖5. NewsQA實驗結(jié)果
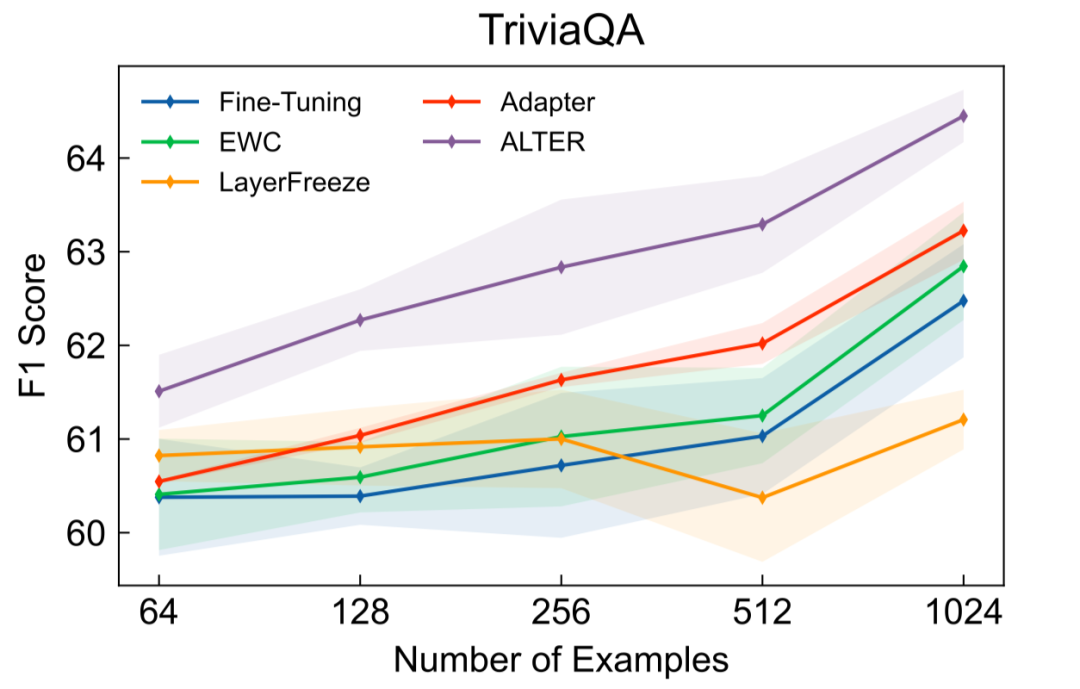
圖6. TriviaQA實驗結(jié)果
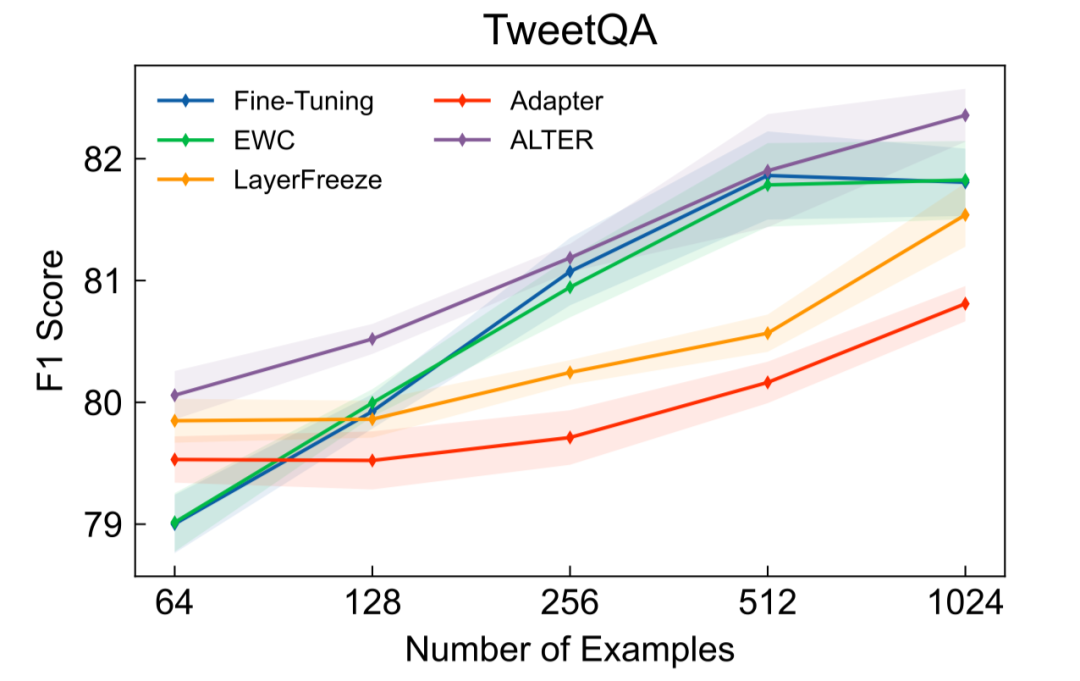
圖7. TweetQA實驗結(jié)果
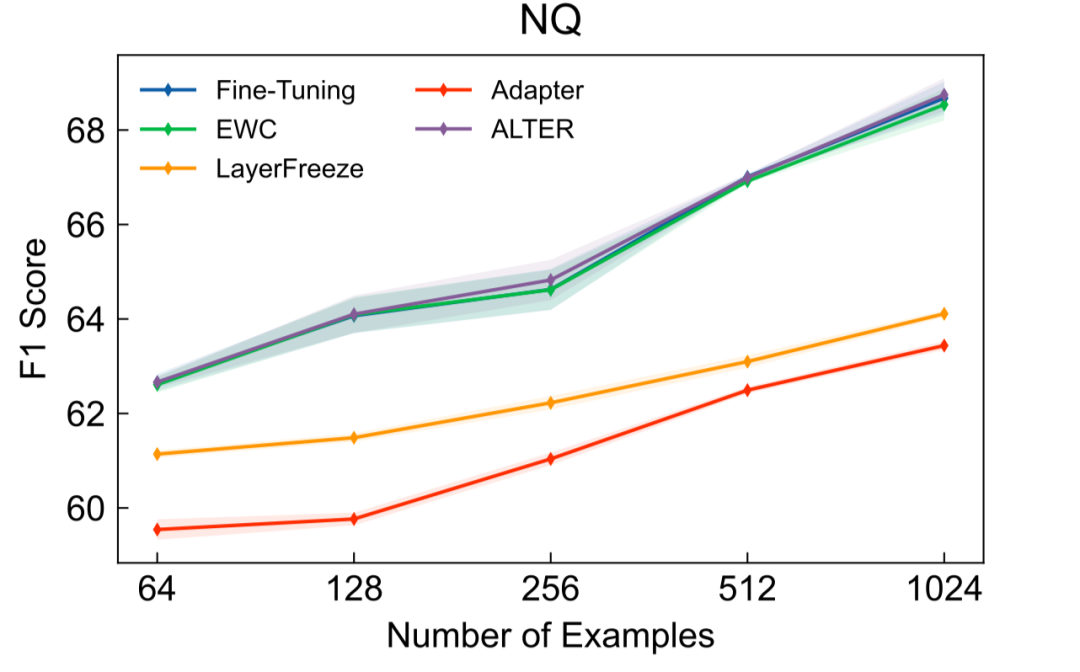
圖8. NQ實驗結(jié)果
圖9展示了引入自注意力頭來幫助尋找稀疏子網(wǎng)絡(luò)的結(jié)果,通過對比可以發(fā)現(xiàn),在使用不同數(shù)量的目標(biāo)領(lǐng)域標(biāo)注數(shù)據(jù)及不同規(guī)模的參數(shù)進(jìn)行領(lǐng)域遷移時,自注意力頭均能夠幫助找到遷移效果更好的子網(wǎng)絡(luò)。
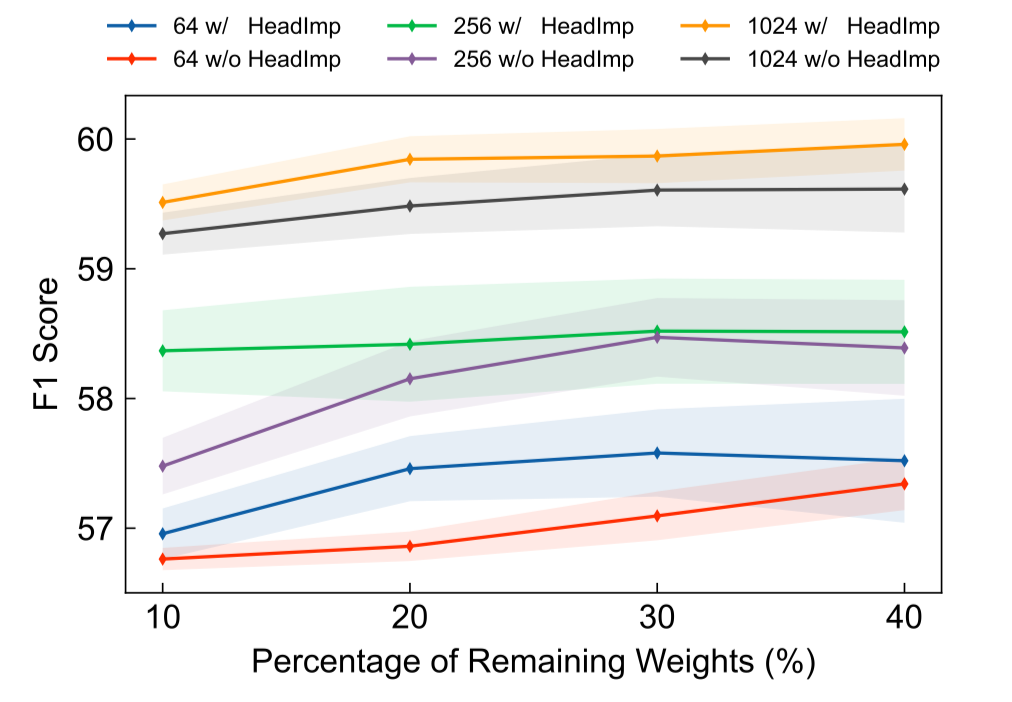
圖9. 引入自注意力歸因與否的領(lǐng)域遷移結(jié)果
為了探究不同的子網(wǎng)絡(luò)識別方法得到的結(jié)構(gòu)對遷移效果的影響,我們進(jìn)行嘗試了以下四種候選方法:
Random 隨機(jī)選取目標(biāo)數(shù)量的參數(shù)
Magnitude 只根據(jù)參數(shù)的絕對值大小進(jìn)行選擇
Salvage 采用與本文提出的相同的流程,但采用相反的策略選擇參數(shù),即使用原本被減掉的參數(shù)進(jìn)行遷移
AttrHead 采用結(jié)構(gòu)化減枝的方式得到,將若干自注意力頭的參數(shù)整體剪掉,對于前饋層的參數(shù)則仍采用非結(jié)構(gòu)化的方式減枝
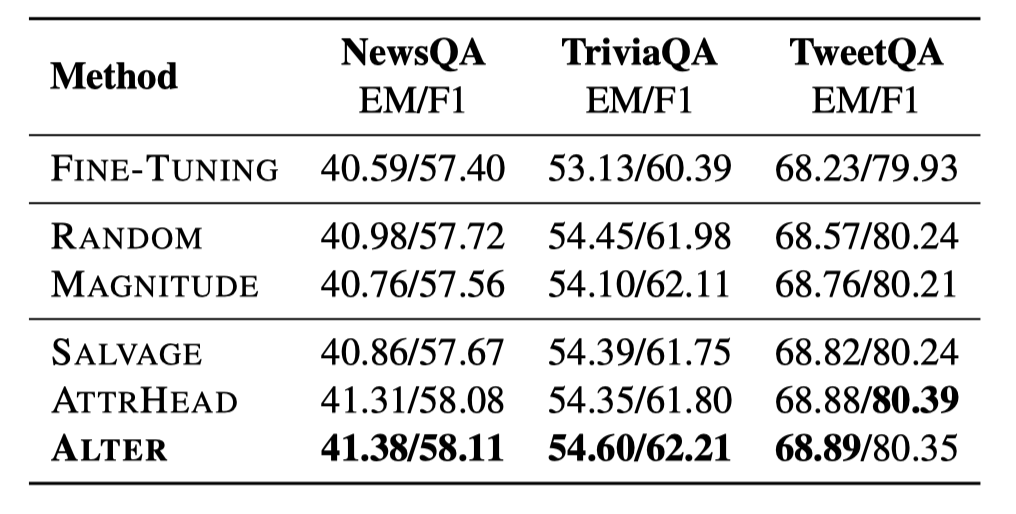
實驗結(jié)果如表3所示,使用不同方法得到的子網(wǎng)絡(luò)大小一致,不同的方法的效果差別并不明顯,但均超過了調(diào)整全部參數(shù)的方法。對比Salvage和Alter,我們發(fā)現(xiàn)使用對模型輸出影響更大的參數(shù)的效果更好。通過與AttrHead方法進(jìn)行比較,我們可以發(fā)現(xiàn),重要性得分較低的自注意力頭中絕對值較大的參數(shù)對領(lǐng)域遷移也有用。
表3. 不同子網(wǎng)絡(luò)識別方法的領(lǐng)域遷移結(jié)果
5. 結(jié)論
在本文中,我們針對少樣本閱讀理解領(lǐng)域遷移提出了一種簡單而有效的方法Alter,該方法只使用過參數(shù)化的源領(lǐng)域模型中的一部分參數(shù)進(jìn)行目標(biāo)領(lǐng)域遷移,我們還引入了自注意力歸因來識別子網(wǎng)絡(luò)以取得更好的遷移效果,通過進(jìn)一步探索不同的子網(wǎng)絡(luò)識別方法,發(fā)現(xiàn)除了使用更少的參數(shù)以外,子網(wǎng)絡(luò)的結(jié)構(gòu)也非常重要。
審核編輯 :李倩
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25330 -
Transformer
+關(guān)注
關(guān)注
0文章
151瀏覽量
6439
原文標(biāo)題:6. 參考文獻(xiàn)
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
載流子遷移率提高技術(shù)詳解

如何精準(zhǔn)提取MOSFET溝道遷移率
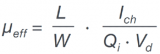
一種永磁電機(jī)用轉(zhuǎn)子組件制作方法
一種使用LDO簡單電源電路解決方案
一種提升無人機(jī)小物體跟蹤精度的方法

一種創(chuàng)新的動態(tài)軌跡預(yù)測方法
一種基于光強(qiáng)度相關(guān)反饋的波前整形方法
一種簡單高效配置FPGA的方法
BitEnergy AI公司開發(fā)出一種新AI處理方法
一種利用wireshark對遠(yuǎn)程服務(wù)器/路由器網(wǎng)絡(luò)抓包方法

光耦的應(yīng)用領(lǐng)域
一種無透鏡成像的新方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論