 用于少數鏡頭命名實體識別的分解元學習
用于少數鏡頭命名實體識別的分解元學習

論文標題:
Decomposed Meta-Learning for Few-Shot Named Entity Recognition
論文鏈接:
https://arxiv.org/abs/2204.05751
代碼鏈接:
https://github.com/microsoft/vert-papers/tree/master/papers/DecomposedMetaNER
Abstract
少樣本 NER 的系統目的在于通過很少的標注樣本來識別新的命名實體類。本文提出了一個分解的元學習方法來解決小樣本 NER,通過將原問題分解為小樣本跨度預測和小樣本實體分類兩個過程。具體來說,我們將跨度預測當作序列標注問題并且使用 MAML 算法訓練跨度預測器來找到更好的模型初始化參數并且使模型能夠快速適配新實體。對于實體分類,我們提出 MAML-ProtoNet,一個 MAML 增強的原型網絡,能夠找到好的嵌入空間來更好的分辨不同實體類的跨度。在多個 benchmark 上的實驗表明,我們的方法取得了比之前的方法更好的效果。
Intro
NER 目的在于定位和識別文本跨度中的預定義實體類諸如 location、organization。在標準的監督學習 NER 中深度學習的架構取得了很大的成功。然而,在實際應用中,NER 的模型通常需要迅速適配一些新的未見過的實體類,且通常標注大量的新樣本開銷很大。因此,小樣本 NER 近年來得到了廣泛的研究。 之前關于小樣本 NER 的研究都是基于 token 級的度量學習,將每個查詢 token 和原型進行度量上的比較,然后為每個 token 分配標簽。最近的很多研究都轉為跨度級的度量學習,能夠繞過 token 對標簽的以來并且明確利用短語的表征。 然而這些方法在遇到較大領域偏差時可能沒那么有效,因為他們直接使用學習的度量而沒有對目標域進行適配。換句話說,這些方法沒有完全挖掘支持集數據的信息。現在的方法還存在以下限制: 1. 解碼過程需要對重疊的跨度仔細處理; 2. 非實體類型“O”通常時噪聲,因為這些詞之間幾乎沒有共同點。 此外,當針對一個不同的領域時,唯一可用的信息僅僅是很少的支持樣本,不幸的是,這些樣本在之前的方法中僅僅被應用在推理階段計算相似度的過程中。 為了解決這些局限性,本文提出了一種分解的元學習方法,將原問題分解為跨度預測和實體分類兩個過程。具體來講: 1. 對于小樣本跨度預測來說,我們將其看作序列標注問題來解決重疊跨度的問題。這個過程目的在于定位命名實體并且是與類別無關的。然后我們僅僅對被標注出的跨度進行實體分類,這樣也可以消除“O”類噪聲的影響。當訓練跨度檢測模塊時,我們采用的 MAML 算法來找到好的模型初始化參數,在使用少量目標域支持集樣本更新后,能夠快速適配新實體類。在模型更新時,特定領域的跨度邊界信息能夠被模型有效的利用,使模型能夠更好的遷移到目標領域; 2. 對于實體分類,采用了 MAML-ProtoNet 來縮小源域和目標域的差距。 我們在一些 benchmark 上進行了實驗,實驗表明我們提出的框架比之前的 SOTA 模型表現更好,我們還進行了定性和定量的分析,不同的元學習策略對于模型表現的影響。
Method
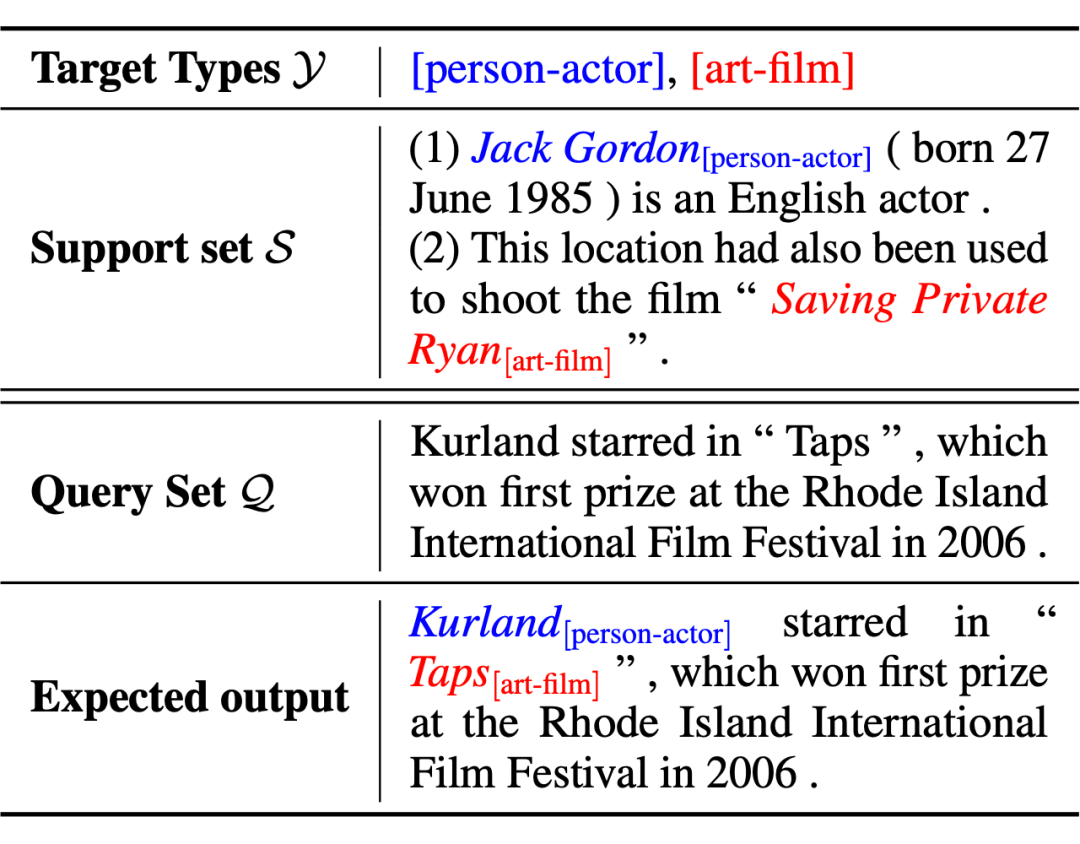
本文遵循傳統的 N-way-K-shot 的小樣本設置,示例如下表(2-way-1-shot):
下圖為模型的總體結構:
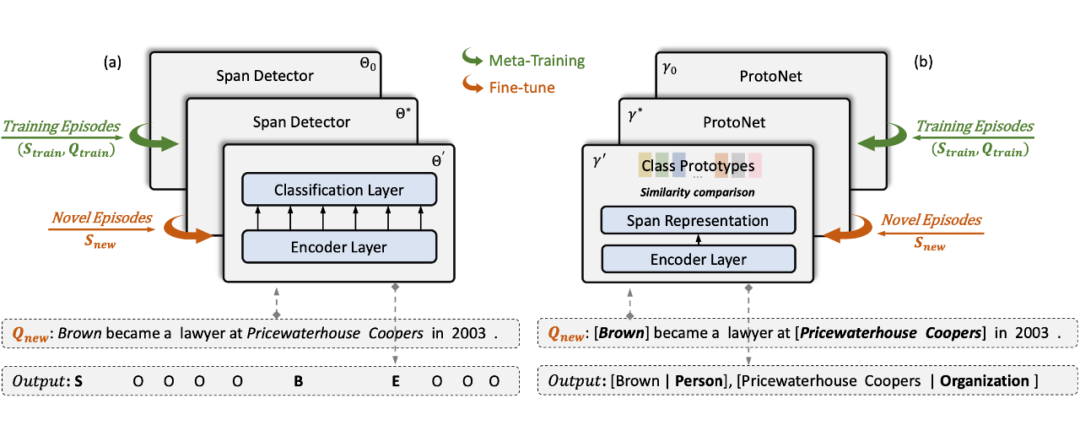
2.1 Entity Span Detection
跨度檢測階段不需要分類具體的實體類,因此模型的參數可以在不同的領域之間共享。基于此,我們采用 MAML 來促進領域不變的內部表征學習而不是針對特定領域特征的學習。這種方式訓練的元學習模型對于目標域的樣本更加敏感,因此只需要少量樣本進行微調就能取得很好的效果而不會過擬合。 2.1.1 Basic Detector 基檢測器是一個標準的序列標注任務,采用 BIOES 的標注策略,對于一個句子序列 {xi},使用一個編碼器得到其上下文表征 h,然后通過 softmax 生成概率分布。
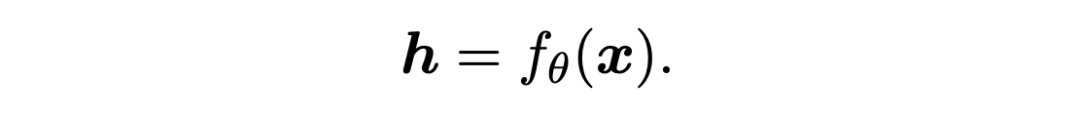
▲ fθ:編碼器
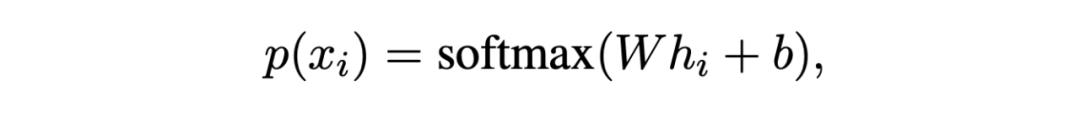
▲概率分布 模型的訓練誤差在交叉熵損失基礎上添加了最大值項來緩解對于損失較高的 token 學習不足的問題:

▲交叉熵損失 推理階段采用了維特比解碼,這里我們沒有訓練轉移矩陣,簡單的添加了一些限制保證預測的標簽不違反 BIOES 的標注規則。 2.1.2 Meta-Learning Procedure 元訓練過程具體來說,首先隨機采樣一組訓練 episode:
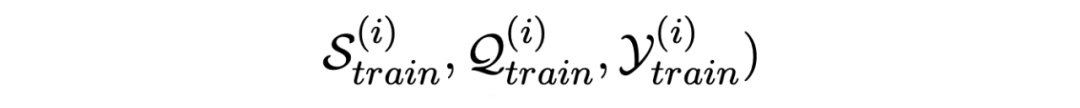
使用支持集進行 inner-update 過程:
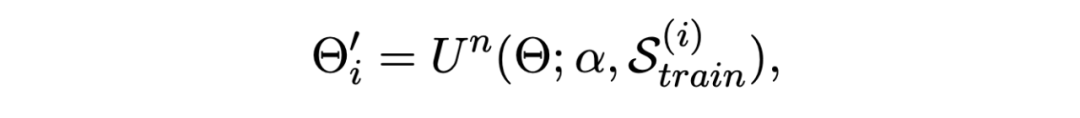
其中 Un 代表 n 步梯度更新,損失采用上文所述的損失函數。然后使用更新后的參數 Θ' 在查詢集上進行評估,將一個 batch 內的所有 episode 的損失求和,訓練目標是最小化該損失:
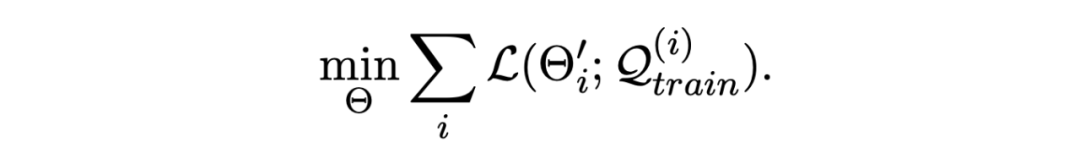
用上述損失來更新模型的原參數 Θ,這里使用一階導數來近似計算:
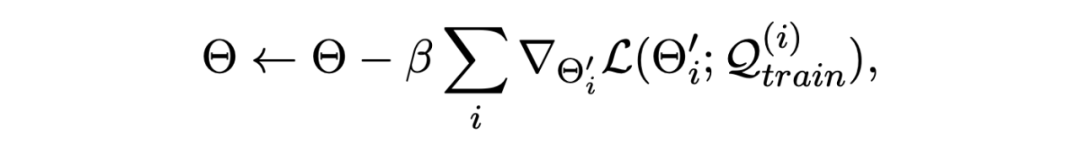
MAML 數學推導參考:MAML
https://zhuanlan.zhihu.com/p/181709693
在推理階段先使用基模型中提到的交叉熵損失在支持集上微調,然后在查詢集上使用微調后的模型進行測試。
2.2 Entity Typing
實體分類模塊采用原型網絡作為基礎模型,使用 MAML 算法對模型進行增強,使模型得到一個更具代表性的嵌入空間來更好的區分不同的實體類。 2.2.1 Basic Model 這里使用了另一個編碼器來對輸入 token 進行編碼,然后使用跨度檢測模塊輸出的跨度 x[i,j],將跨度中所有的 token 表征取平均來代表此跨度的表征:
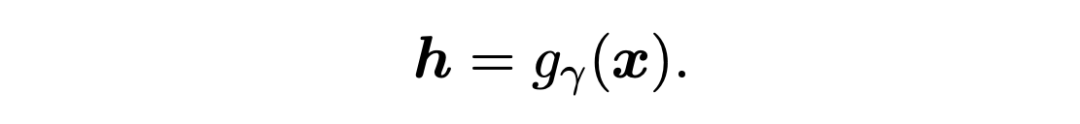
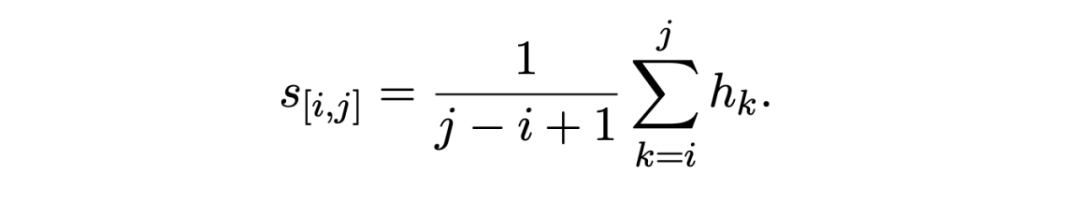
遵循原型網絡的設置,使用支持集中屬于同一實體類的跨度的求和平均作為類原型的表示:
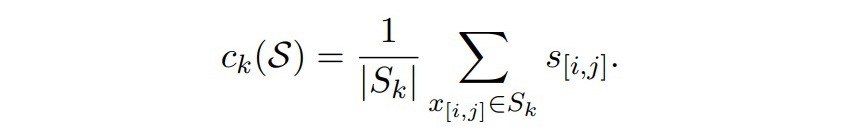
模型的訓練過程先采用支持集計算每個類原型的表示,然后對于查詢集中的每個跨度,通過計算其到某一類原型的距離來計算其屬于該類的概率:
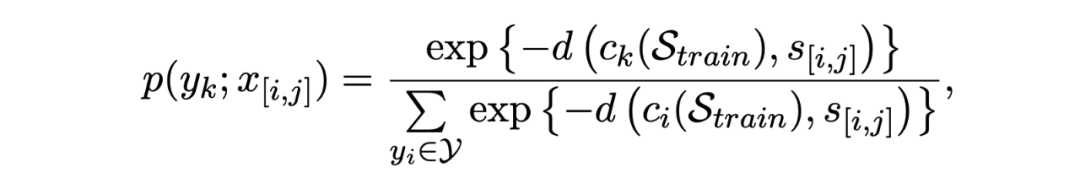
模型的訓練目標是一個交叉熵損失:
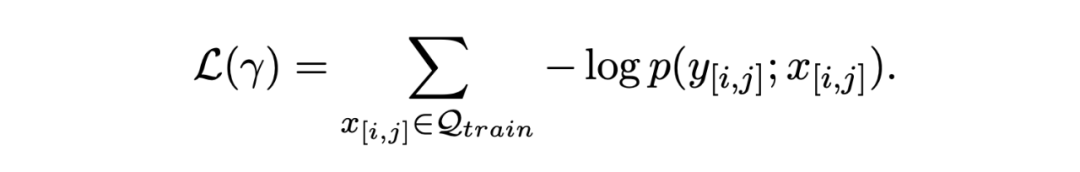
推理階段就是簡單的計算與哪一類原型距離最近即可:
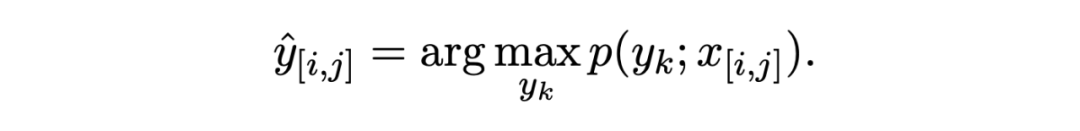
2.2.2 MAML Enhanced ProtoNet 這一過程的設置與跨度檢測中應用的 MAML 一致,同樣是使用 MAML 算法來找到一個更好的初始化參數,詳細過程參考上文:
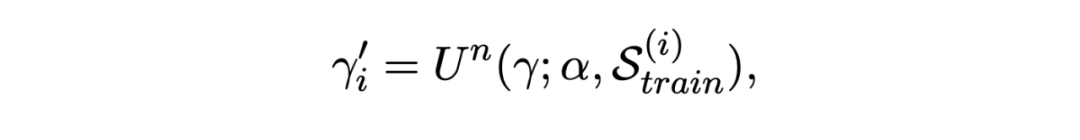
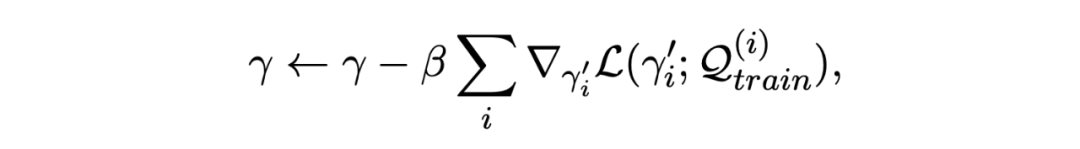
推理階段也與上文一致,這里不詳細說明了。
實驗
3.1 數據集和設置
本文采用 Few-NERD,一個專門為 few-shot NER 推出的數據集以及 cross-dataset,四種不同領域的數據集的整合。對于 Few-NERD 使用 P、R、micro-F1 作為評價指標,cross-dataset 采用 P、R、F1 作為評價指標。文中兩個編碼器采用兩個獨立的 BERT,優化器使用 AdamW。
3.2 主實驗
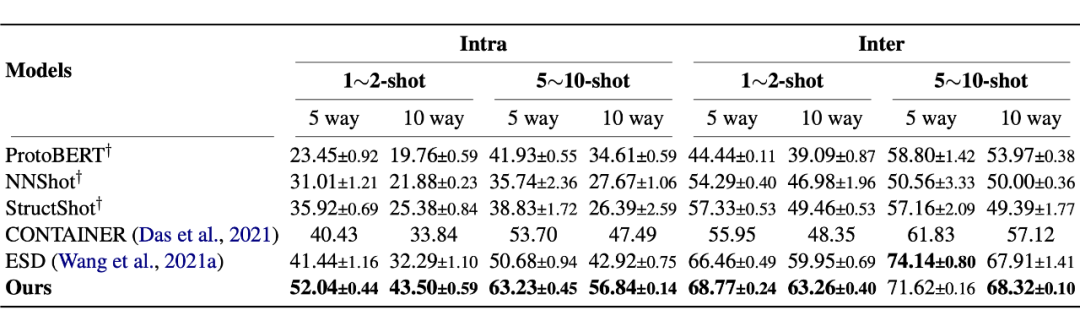
▲ Few-NERD
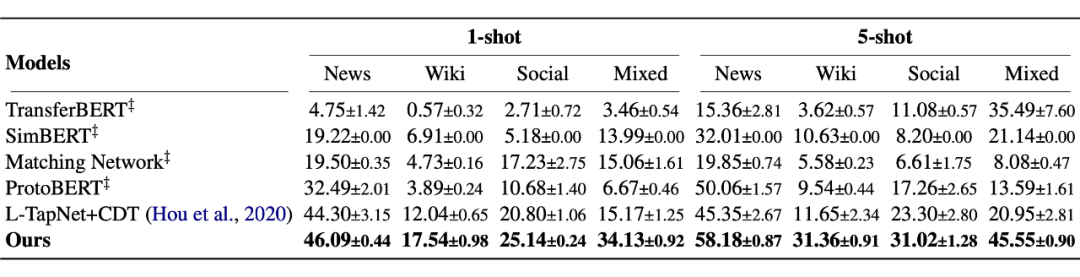
▲Cross-Dataset
3.3 消融實驗

3.4 分析
對于跨度檢測,作者用一個全監督的跨度檢測器進行實驗:

作者分析,未精調的模型預測的 Broadway 對于新實體類來說是一個錯誤的預測(Broadway 出現在了訓練數據中),然后通過對該模型采用新實體類樣本進行精調,可以看出模型能夠預測出正確的跨度,但是 Broadway 這一跨度仍然被預測了。這表明傳統的精調雖然可以使模型獲取一定的新類信息,但是其還是存在很大偏差。 然后作者對比了 MAML 增強的模型和未使用 MAML 模型的 F1 指標:
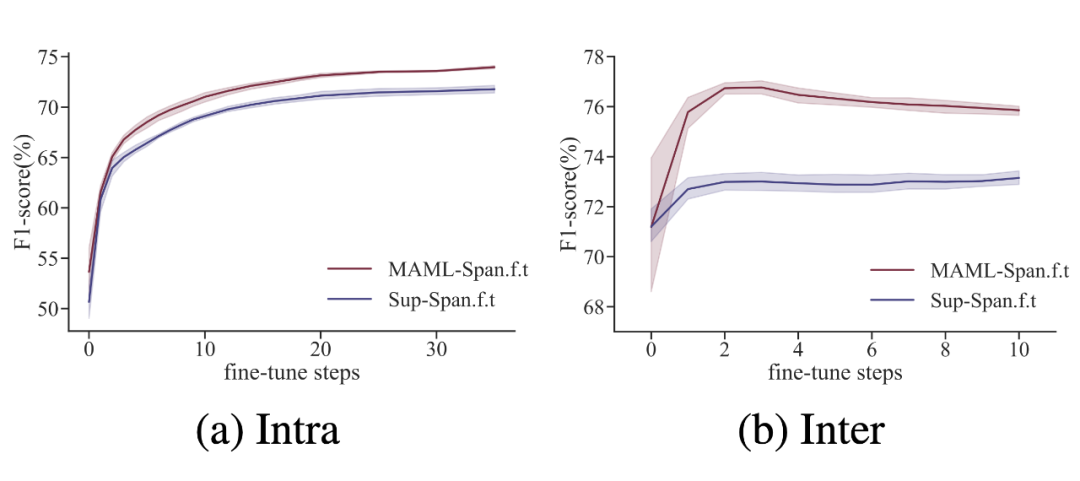
MAML 算法可以更好的利用支持集的數據,找到一個更好的初始化參數,使模型能夠快速適配到新域中。 然后作者分析了 MAML 如何提升原型網絡,首先是指標上 MAML 增強的原型網絡會有一定的提升:

接著作者進行了可視化分析:
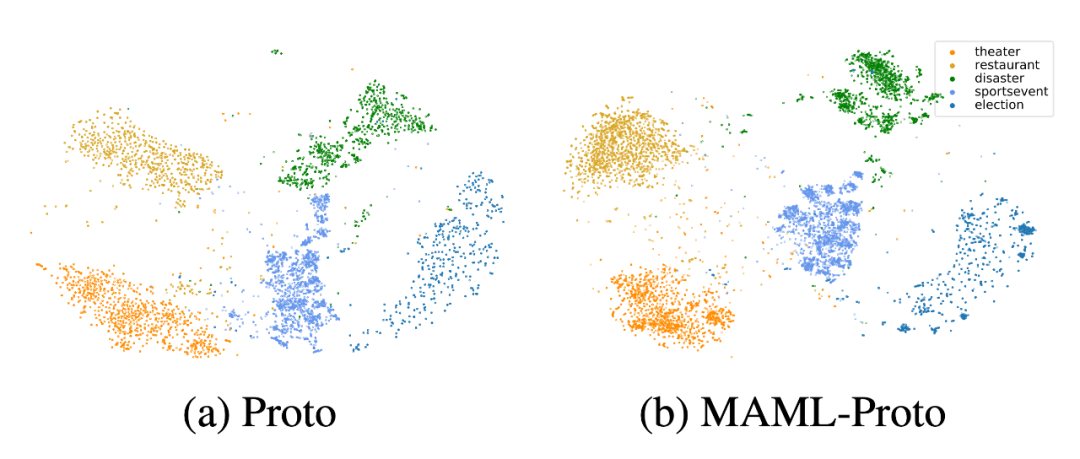
從上圖可以看出,MAML 增強的原型網絡能夠更好的區分各個類原型。
Conclusion
本文提出了一個兩階段的模型,跨度檢測和實體分類來進行小樣本 NER 任務,兩個階段的模型均使用元學習 MAML 的方法來進行增強,獲取了更好的初始化參數,能夠使模型通過少量樣本快速適配到新域中。本文也算是一篇啟發性的文章,在指標上可以看出,元學習的方法對小樣本 NER 任務有著巨大的提升。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3521瀏覽量
50445 -
深度學習
+關注
關注
73文章
5561瀏覽量
122811
原文標題:ACL2022 | 分解的元學習小樣本命名實體識別
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于LockAI視覺識別模塊:C++人臉識別
ADS1274識別的信號可以小于噪聲1000倍,是真的嗎?
適用于內窺鏡鏡頭模組的環氧樹脂封裝膠
千萬級 FA 鏡頭應用線路板缺陷檢測

【「嵌入式系統設計與實現」閱讀體驗】“基于車牌識別的自動地鎖”案例學習
使用TUSB1046插入USB3.0的U盤,發現有不識別的現象,為什么?
ASR與傳統語音識別的區別
風華貼片瓷介電容型號識別及命名方法

GPU深度學習應用案例
TAC5242EVM-K通過usb連接電腦出現不能識別的問題,怎么解決?
深度識別人臉識別有什么重要作用嗎
使用 TMP1826 嵌入式 EEPROM 替換用于模塊識別的外部存儲器






 工商網監
工商網監
評論