") 基于Zero-Shot的多語言抽取式文本摘要模型
基于Zero-Shot的多語言抽取式文本摘要模型
這項研究旨在解決零樣本下法語、德語、西班牙語、俄語和土耳其語等多語種的抽取式摘要任務(wù),并在多語言摘要數(shù)據(jù)集 MLSUM 上大幅提升了基線模型的分數(shù)。
抽取式文本摘要目前在英文上已經(jīng)取得了很好的性能,這主要得益于大規(guī)模預(yù)訓(xùn)練語言模型和豐富的標注語料。但是對于其他小語種語言,目前很難得到大規(guī)模的標注數(shù)據(jù)。
中國科學(xué)院信息工程研究所和微軟亞洲研究院聯(lián)合提出一種是基于 Zero-Shot 的多語言抽取式文本摘要模型。具體方法是使用在英文上預(yù)訓(xùn)練好的抽取式文本摘要模型來在其他低資源語言上直接進行摘要抽取;并針對多語言 Zero-Shot 中的單語言標簽偏差問題,提出了多語言標簽(Multilingual Label)標注算法和神經(jīng)標簽搜索模型(Neural Label Search for Summarization, NLSSum)。
實驗結(jié)果表明,模型 NLSSum 在多語言摘要數(shù)據(jù)集 MLSUM 的所有語言上大幅度超越 Baseline 模型的分數(shù)。其中在俄語(Ru)數(shù)據(jù)集上,零樣本模型性能已經(jīng)接近使用全量監(jiān)督數(shù)據(jù)得到的模型。
該研究發(fā)表在了 ACL 2022 會議主會長文上。

引言
隨著 BERT 在自然語言處理領(lǐng)域的發(fā)展,在大規(guī)模無標注數(shù)據(jù)上進行預(yù)訓(xùn)練的模式得到了廣泛的關(guān)注。
近些年,有很多研究工作在多種語言的無標簽語料上進行訓(xùn)練,從而得到了支持多種語言的預(yù)訓(xùn)練模型。這些基于多語言文本的預(yù)訓(xùn)練模型能夠在跨語言的下游任務(wù)上取得很好的性能,例如 mBERT、XLM 和 XLMR。對于基于 Zero-Shot 的多語言任務(wù),上述的多語言模型也能取得不錯的效果。其中,XLMR 模型的 Zero-Shot 效果在 XNLI 數(shù)據(jù)集上已經(jīng)能夠達到其他模型 Fine-tune 的水平。因此這為我們在抽取式文本摘要任務(wù)上進行基于 Zero-Shot 的探索提供了基礎(chǔ)。
在單語言的抽取式文本摘要中,數(shù)據(jù)集通常只含有原始文檔和人工編寫的摘要,因此需要使用基于貪心算法的句子標簽標注算法來對原文中的每句話進行標注。但這種算法是面向單語言的標注方法,得到的結(jié)果會產(chǎn)生單語言標簽偏差問題,在多語言的任務(wù)上仍然需要優(yōu)化。下面的圖表展示的就是單語言標簽偏差問題。

▲表1. 多語言 Zero-Shot 中的單語言標簽偏差問題
如上表 1 樣例所示,這個例子是摘要領(lǐng)域目前最常見的 CNN/DM 數(shù)據(jù)集中選取的部分文檔。CNN/DM 是一個英文數(shù)據(jù)集,示例中上半部分的即為原始文檔中的英文表示和人工編寫的英文摘要;示例中的下半部分是使用微軟開源的工業(yè)級翻譯模型 Marian,將英文的文檔和摘要全部翻譯為德語。示例中的這句話和人工編寫的摘要具有較高的相似性,因此會得到較高的 ROUGE 分數(shù)。
但是對于翻譯成德語的文檔句子和摘要,我們發(fā)現(xiàn)兩者的相似性較低,對應(yīng)的 ROUGE 分數(shù)也會較低。這種情況下,使用英語語言環(huán)境下標注的標簽直接訓(xùn)練的多語言文本摘要模型,在其他語言的語言環(huán)境中并不是最優(yōu)的。
上述實例表明同一個句子在不同語言環(huán)境下會存在標簽偏差的問題,也就是目前的貪心算標注標簽的方式無法滿足基于 Zero-Shot 的多語言文本摘要任務(wù)。
為了解決上述基于 Zero-Shot 的多語言抽取式文本摘要中單語言標簽偏置的問題,我們提出了一種多語言標簽算法。在原來單語言標簽的基礎(chǔ)上,通過使用翻譯和雙語詞典的方式在 CNN/DM 數(shù)據(jù)集上構(gòu)造出另外幾組多語言交互的句子標簽。對于這幾組語言標簽,設(shè)計出神經(jīng)語言標簽搜索模型 (NLSSum) 來充分利用它們對抽取式摘要模型進行監(jiān)督學(xué)習(xí)。
在 NLSSum 模型中,使用層次級的權(quán)重來對這幾組標簽進行句子級別 (Sentence-Level) 和組級別 (Set-Level) 的權(quán)重賦值。在抽取式模型的訓(xùn)練期間, Sentence-Level 和 Set-Level 權(quán)重預(yù)測器是和摘要抽取器一起在英文標注語料上進行訓(xùn)練的。模型推斷測試的時候,在其他語言上只使用摘要抽取器來進行摘要抽取。
技術(shù)概覽
我們針對基于 Zero-Shot 多語言摘要任務(wù)中的單語言標簽偏移問題,提出了神經(jīng)標簽搜索模型來對多語言標簽使用神經(jīng)網(wǎng)絡(luò)搜索其權(quán)重,并使用加權(quán)后的標簽監(jiān)督抽取式摘要器。具體的流程分為以下五步:
多語言數(shù)據(jù)增強:這里的目前是將原始英文文檔用翻譯、雙語詞典換等方式來減少和目標語言之間的偏差;
多語言標簽:我們的抽取式摘要模型最終是通過多語言標簽來進行監(jiān)督的,其中多語言標簽總共包含 4 組標簽,這 4 組標簽都是根據(jù)不同的策略來標注的;
神經(jīng)標簽搜索:在這步中為不同組標簽設(shè)計了層次級的權(quán)重預(yù)測,包括句子級別 (Sentence-Level) 和組級別 (Set-Level),最終使用加權(quán)的標簽來對抽取式摘要模型進行監(jiān)督;
微調(diào)訓(xùn)練 / Fine-Tunig:使用增強的文檔數(shù)據(jù)和加權(quán)平均的多語言標簽來 Fine-Tune 神經(jīng)摘要抽取模型;
基于 Zero-Shot 的多語言摘要抽取:使用在英文標注數(shù)據(jù)上訓(xùn)練完的模型可以直接在低資源語言的文檔上進行摘要句子抽取。
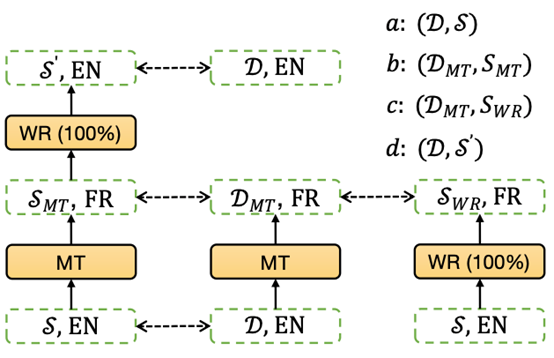
▲圖1:多語言標簽
如上圖 1 所示,在原始英文文檔 D 和人工編寫摘要 s 上設(shè)計出四組多語言標簽 (Ua,Ub,Uc,Ud),具體的構(gòu)造方法如下所示:
1. 標簽集合 Ua:定義 Ua=GetPosLabel (D,s) 為使用文檔 D 和人工編寫摘要 s 使用貪心算法得到的抽取為摘要的句子集合,其中 GetPosLabel 返回的是標簽為 1 的句子的索引。使用 (D,s) 得到的是英文文檔上的到的摘要句子,這個結(jié)果對于其他語言來說并不是最優(yōu)的,因此我們還設(shè)計了另外三組標簽。
2. 標簽集合 Ub:首先將英文原始文檔和人工編寫摘要都使用機器翻譯模型 MarianMT 將其翻譯為目標語言,標記為 DMT 和 sMT,然后使用 Ub=GetPosLabel (DMT,sMT) 的方式得到翻譯后文檔上摘要句子的索引集合。這種借助于機器翻譯模型的方法相當(dāng)于使用目標語言的句法結(jié)構(gòu)來表達原始英文的語義,因此得到的摘要句子能反應(yīng)出目標語言句法結(jié)構(gòu)對摘要信息的偏重。
3. 標簽集合 Uc:在這組標簽的構(gòu)造中,首先將原始英文文檔自動翻譯為目標語言 DMT,然后將人工編寫的英文摘要使用雙語詞典替換為目標語言 SWR (將所有摘要中的詞都進行替換),然后我們使用 Uc=GetPosLabel (DMT,SWR) 的方式得到翻譯和詞替換方式交互的摘要句子索引集合。這種方法將原始文檔使用機器翻譯來替換句法結(jié)構(gòu),摘要使用雙語詞典翻譯來保留原始語言句法結(jié)構(gòu)同時和文檔語言保持一直,因此能夠得到目標語言和原始語言之間句法結(jié)構(gòu)在抽取摘要句子上的交互。
4. 標簽集合 Ud:這個方法中,文檔使用的是原始英文文檔 D;摘要先經(jīng)過機器翻譯轉(zhuǎn)換到目標語言,然后經(jīng)過雙語詞典進行詞替換轉(zhuǎn)換回英語,使用 S′來表示。最終我們使用 Ud=GetPosLabel (D,S′) 來得到抽取式摘要句子標簽集合。在這種方法中,原始文檔保持不變,摘要則是使用目標語言的句法結(jié)構(gòu),因此能夠再次得到目標語言和原始語言之間句法結(jié)構(gòu)在抽取摘要句子上的交互。
需要注意的是,使用 GetPosLabel (D,S) 的時候,要保證 D 和 S 是同種語言的表示,因為基于貪心算法的標簽標注算法本質(zhì)上是對詞語級別進行匹配。另外,還有很多種構(gòu)造多語言標簽的方法,我們只是選取了幾組有代表性的方法。這些方法中使用的機器翻譯模型和雙語詞典替換可能會引入額外的誤差,因此需要為這幾組標簽學(xué)習(xí)合適的權(quán)重。
如下圖 2 所示,對于已經(jīng)得到的幾組多語言標簽 (Ua,Ub,Uc,Ud),需要設(shè)計神經(jīng)標簽搜索的模型來對不同組的標簽設(shè)置權(quán)重。權(quán)重包含兩部分,句子級別 (Sentence-Level) 和組級別 (Set-Level)。對應(yīng)這兩個級別的權(quán)重,我們分別定義兩個權(quán)重預(yù)測器,句子級別權(quán)重預(yù)測 Transformeralpha 和組級別權(quán)重預(yù)測 Transformerbeta。
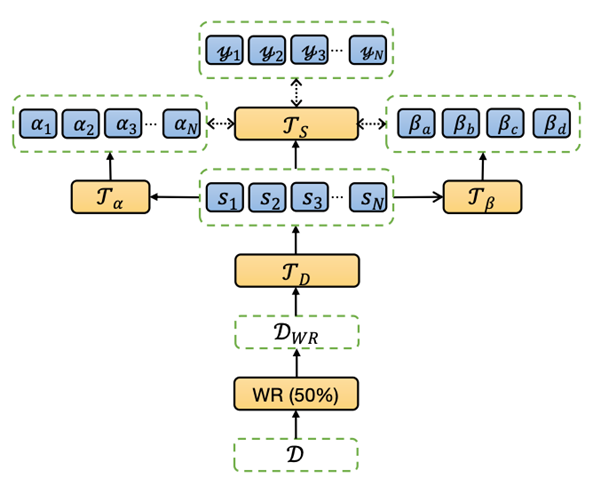
▲圖2:多語言神經(jīng)標簽搜索摘要模型
實驗結(jié)果
NLSSum 是通過神經(jīng)搜索的方式來對 MultilingualLabel 中不同標簽集合賦予不同的權(quán)重,并最終得到加權(quán)平均的標簽。使用這種最終的標簽在英文數(shù)據(jù)集上訓(xùn)練抽取式摘要模型。和單語言標簽相比,多語言標簽中存在更多的跨語言語義和語法信息,因此本文的模型能夠在 Baseline 基礎(chǔ)上獲得較大的提升。
如下表 2 所示,實驗使用的數(shù)據(jù)集包括 CNN/DM 和 MLSUM,具體數(shù)據(jù)集描述如表 6.2 所示。MLSUM 是第一個大規(guī)模的多語言文本摘要數(shù)據(jù)集,它從新網(wǎng)網(wǎng)站上爬取了 150 萬條文檔和摘要,包含五種語言:法語 (French,F(xiàn)r)、德語 (German,De)、西班牙語 (Spanish,ES)、俄語 (Russian,Ru) 和土耳其語 (Turkish,Tr)。MLSUM 是在測試推斷的時候驗證 Zero-Shot 多語言模型的跨語言遷移能力。在訓(xùn)練階段使用的是文本摘要領(lǐng)域最常見的 CNN/DM 英文數(shù)據(jù)集。
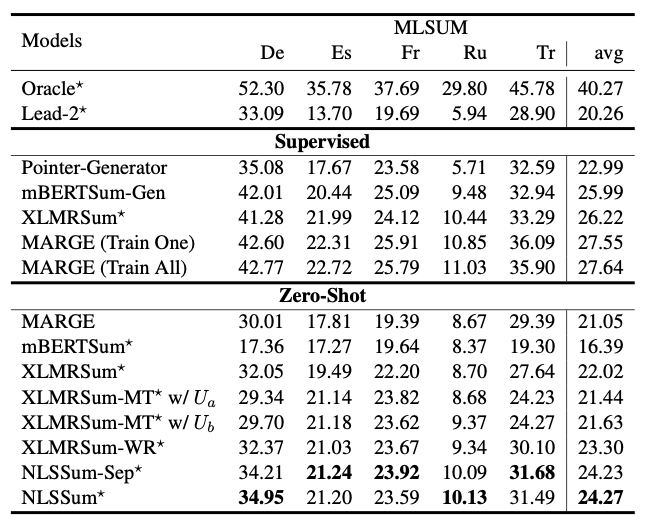
▲表2:MLSUM 數(shù)據(jù)集上的 ROUGE 結(jié)果
這里對 MLSUM 數(shù)據(jù)集上各個基線模型的的 ROUGE 結(jié)果進行對比。表格總共分為三部分。
第一部分展示的是 Oracle 和 Lead 這些簡單的基線模型;
第二部分展示的是基于監(jiān)督學(xué)習(xí)的一些基線模型,其中 (TrainAll) 是在所有語言的數(shù)據(jù)集上進行訓(xùn)練,(TrainOne) 是在每個語言的數(shù)據(jù)集上單獨訓(xùn)練;
第三部分展示的是無監(jiān)督學(xué)習(xí)的結(jié)果,所有的模型都是只在英文數(shù)據(jù)集上進行訓(xùn)練。
其中,根據(jù)第二部分的結(jié)果很容易發(fā)現(xiàn),在監(jiān)督學(xué)習(xí)中,基于生成式的摘要方式比抽取式的更加合適。在第三部分中,基線模型 XLMRSum 的性能能夠超越生成式模型的 MARGE,這說明無監(jiān)督學(xué)習(xí)中使用抽取式方法更加合適。
另外,當(dāng)使用機器翻譯和雙語詞典替換來對原始文檔進行數(shù)據(jù)增強的時候 (基線模型 XLMRSum-MT 和 XLMRSum-WR),可以發(fā)現(xiàn) XLMRSum-MT 模型會帶來模型性能下降,而 XLMRSum-WR 會帶來性能的提升,因此最終的模型中數(shù)據(jù)增強選擇的是基于雙語詞典的詞替換方式。
因此對于我們 NLSSum 模型,我們同樣有兩種配置,NLSSum-Sep是將 CNN/DM 單獨詞替換為對應(yīng)的一種目標語言并進行微調(diào)訓(xùn)練;NLSSum是 CNN/DM 詞分別替換為所有的目標語言并在所有語言的替換后的數(shù)據(jù)集上進行微調(diào)訓(xùn)練。
最終結(jié)果顯示,在所有語言上進行訓(xùn)練的 NLSSum 效果更好。從表格中我們可以總結(jié)出以下結(jié)論:
基于翻譯模型的輸入數(shù)據(jù)增強會引入誤差,所以應(yīng)該避免在輸入中使用翻譯模型;相反,雙語詞典的詞替換方式是一個不錯的數(shù)據(jù)增強方法;
標簽的構(gòu)造過程中不涉及模型輸入,所以可以使用機器翻譯模型來輔助標簽生成。
如下圖 3 所示,通過可視化分析進一步研究不同語言間重要信息的分布位置,從中可以看出英文語言中重要信息分布較為靠前,而其他語言中的重要信息則比較分散,這也是多語言標簽?zāi)軌蛱嵘P托阅苤匾颉?/p>
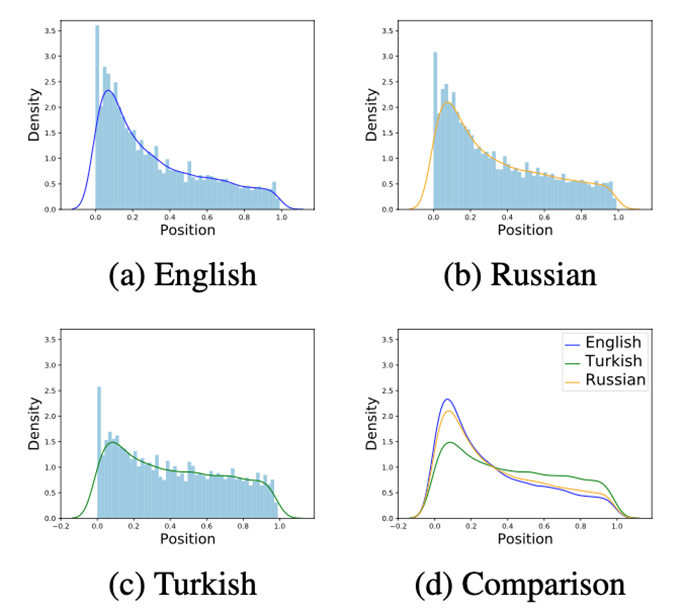
▲圖3:不同語言中摘要句子的分布位置
未來研究將關(guān)注于:1. 尋找更加合理的多語言句子級別標簽標注算法;2. 研究如何提升低資源語言摘要結(jié)果,同時不降低英語語料上的結(jié)果。
審核編輯:郭婷
-
微軟
+關(guān)注
關(guān)注
4文章
6675瀏覽量
105416 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7246瀏覽量
91174 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25300
原文標題:ACL2022 | 基于神經(jīng)標簽搜索的零樣本多語言抽取式文本摘要
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
小白學(xué)大模型:從零實現(xiàn) LLM語言模型

?VLM(視覺語言模型)?詳細解析

了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應(yīng)用選擇

Meta與UNESCO合作推動多語言AI發(fā)展
微軟Copilot Voice升級,積極拓展多語言支持
Llama 3 語言模型應(yīng)用
ChatGPT 的多語言支持特點
科大訊飛發(fā)布訊飛星火4.0 Turbo大模型及星火多語言大模型
谷歌全新推出開放式視覺語言模型PaliGemma
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論