 利用深度學習在工業圖像無監督異常定位方面的最新成果
利用深度學習在工業圖像無監督異常定位方面的最新成果
導讀
本文通過全面綜述利用深度學習在工業圖像無監督異常定位方面的最新成果,幫助該領域的研究人員快速入門。
中科院自動化所、北京工商大學和印度理工學院等單位聯合發表最新的工業異常定位(檢測)綜述。20頁綜述,共計126篇參考文獻! 本綜述將工業異常定位方法根據不同的模型/方法進行分類和介紹,最新方法截止至2022年2月!同時,綜述還包括了在完整MVTec AD數據集上的性能對比,并給出了多個工業異常定位的未來研究方向!

論文題目:Deep Learning for Unsupervised Anomaly Localization in Industrial Images: A Survey
發表單位:中國科學院自動化所、北京工商大學、印度理工學院
論文地址:https://arxiv.org/abs/2207.10298
1. 概要
目前,基于深度學習的視覺檢測在監督學習方法的幫助下取得了很大的成功。然而,在實際工業場景中,缺陷樣本的稀缺性、注釋成本以及缺陷先驗知識的缺乏可能會導致基于監督的方法失效。近5年來,無監督異常定位算法在工業檢測任務中得到了更廣泛的應用。本文旨在通過全面綜述利用深度學習在工業圖像無監督異常定位方面的最新成果,幫助該領域的研究人員快速入門。該綜述分析了120多份重要文獻,涵蓋工業異常定位的不同方面,主要涵蓋各種概念、挑戰、分類、基準數據集以及所提及方法的定量性能比較。在回顧迄今為止的研究成果時,本文對未來的幾個研究方向進行了詳細的預測和分析。本綜述為對工業異常定位感興趣的研究人員以及希望將其應用于其他領域異常定位的研究人員提供了詳細的技術信息。
2. 異常定位的定義
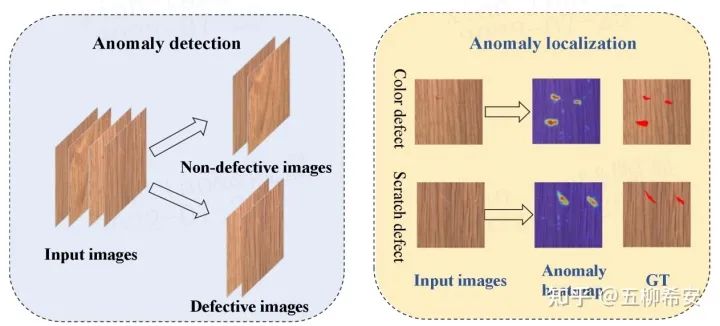
什么是AL?
人類視覺系統具有感知異常的固有能力——人不僅可以區分缺陷圖像和非缺陷圖像,即使他們以前從未見過任何缺陷樣本,而且還可以很容易的指出圖像中那些位置存在異常。異常定位(AL,anomaly localization)被引入學術界也是出于同樣的目的,即教會機器以無監督的方式“發現”異常區域。在深度學習方法中,“無監督”意味著訓練階段只包含正常圖像,沒有任何缺陷樣本。無監督范式下的AL方法首先避免了收集異常或缺陷樣本的困難,這在監督方法中是無法避免的;因為在工業場景中,沒有缺陷的正常圖像遠遠多于異常樣本。其次,在無監督方法中可以消除監督方法中訓練樣本的標記成本。最后,無監督方法還避免了標記偏差的影響,這在監督方法中常見。由于訓練數據只有正常類,因此可以將其稱為“半監督”。然而,為了與大多數現有方法統一,我們在以下內容中刪除了術語“無監督”或“半監督”,僅將其稱為AL。
AD和AL的區別:計算機視覺中異常檢測AD(anomaly detection)也常常被提及,離群點檢測或one class 分類是AD的其他術語。圖1展示了AD(anomaly detection)和AL之間的區別。AD是指在圖像級別將缺陷圖像與大多數非缺陷圖像區分開來的任務,只關注圖像類別,正常or異常。另一方面,AL也稱為異常分割,用于生成像素級異常定位結果,它不僅僅關注圖像類別,更關注異常的詳細位置。異常熱圖中的顏色越深,如圖1所示,該位置存在異常的可能性越大。
什么是異常?
一般來說,工業領域中的異常通常指缺陷,這里不僅僅包括三傷(劃傷、碰傷和壓傷等),異色,亮痕等紋理變化的缺陷,而且有更為復雜的,需要進一步邏輯判斷的功能缺陷。例如晶體管管腳是否插入到pin中,是否裝錯,裝反或少裝。下圖第一行展示了MVTec AD數據集上的紋理缺陷,第二行展示了MVTec AD數據集上的功能缺陷。MVTec AD中大部分缺陷類型為紋理缺陷,少部分缺陷為功能缺陷,功能缺陷主要存在晶體管這個數據集中,因此這個數據集是MVTec AD15個數據集中最難檢測的。

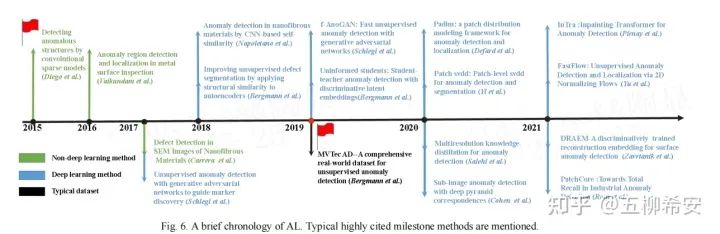
上圖追溯了工業圖像的AL的歷史。大多數基于非深度學習的AL模型依賴于稀疏編碼[14,15]和字典學習[16]。自2017年以來,由于深度學習技術在計算機視覺領域的巨大成功,出現了越來越多的深度學習方法[19]。GAN模型[17,22]和AE重建網絡[18]首次用于深度AL模型。為了一致地比較AL的影響,MTVec公司提出了一個完整的工業AL數據集,也就是MVTec AD數據集[20]。后來,基于特征嵌入的模型變得更加有效和高效,成為流行的AL架構。知識蒸餾[21,26]和預訓練特征比較[23,25,30]是典型模型的示例。然后,將幾種基于自監督學習的方法應用于上述任務[24,29]。基于Flow的生成模型[28]和ViT模型[27]作為更好的方法也嵌入到AL網絡中。盡管AL研究的歷史很短,但它已經發表了數百篇論文,我們綜合選擇了在著名雜志和會議上發表的有影響力的論文;這項調查側重于過去五年的主要進展。由于MVTec AD數據集的提出,在過去的兩年內,大量方法呈現井噴狀態被提出,該數據集的指標也被刷到非常高,這一點可以從paper with code網站 (https://paperswithcode.com/sota/anomaly-detection-on-mvtec-ad)看出。
這篇綜述和以往綜述有什么區別?
文章中列出了與AD/AL相關的多項綜述,涉及早期非深度學習AD方法[6]、基于深度學習的AD方法[5,7-9]、有限的AL模型[10]或僅關注GAN的AD/AL[11]等領域的研究。然而,很少有綜述致力于完整和全面的異常定位AL方法。另一方面,大多數現有綜述僅僅關注圖像級分類的AD方法,該方法很容易忽略工業場景中的細微異常區域。此外,近五年來,所有方法已經從圖像級比較(重建或生成)發展到特征級比較,也從簡單的缺陷合成代理任務發展到基于對比學習的自監督方法。我們的工作系統全面地回顧了無監督人工智能的最新進展。其中包括對該領域以前從未探索過的許多方面的深入分析和討論。特別是,我們總結和討論了解決各種問題和挑戰的現有方法,提供了路線圖和分類,回顧了現有的數據集和評估指標,對最先進的方法進行了全面的性能比較,并對未來的方向提出了見解。我們希望我們的綜述能夠提供新的見解和靈感,促進深入了解AL,并鼓勵對本文提出的開放主題進行研究。
3. 代表性方法的分類
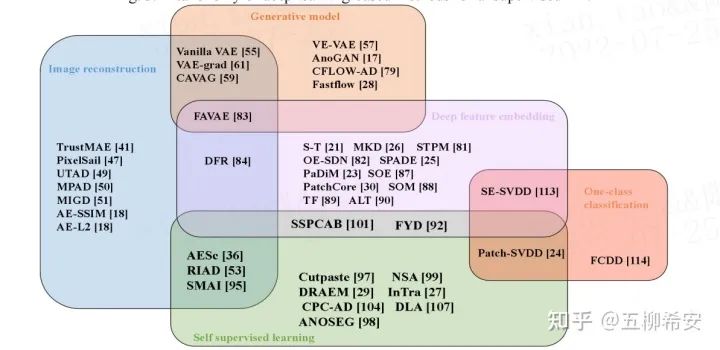
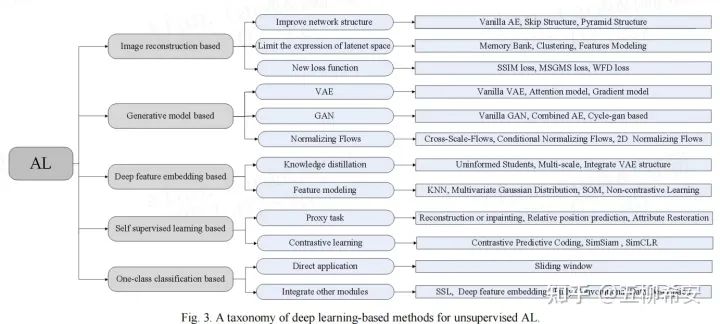
我們將目前的方法分為5大子方法,并對每個子方法進行了詳細的介紹和對比分析。在每個小節中,我們對其代表文章進行了進一步細分。然而,有些工作屬于不止一個類別。因此,我們利用文章中圖4的維恩圖劃分工作,重疊區域包括方法的交叉部分。
主要包括:
1)基于圖像重建的方法:這是最早出現的方法,也非常直觀,期待AE自動編碼器能夠對異常圖像重建成正常圖像,然后重建圖像和正常圖像作差,得到定位結果。主要的改進包括網絡結構、隱空間和損失函數的改進。該方法的問題在于難以保證異常圖像中的異常區域被很好重建為正常,同時圖像中的正常區域重建的效果和輸入一致,這樣兩者作差的結果并不能完全代表異常區域。
2)基于生成網絡的方法:代表的方法就是VAE、GAN和Normalizing Flow (NF)。VAE中引入了類似CAM這種求梯度方式來判斷異常位置的方法。GAN主要是通過多個生成器和判別器的設置,來提升生成或重建的圖像效果。然而,GAN和VAE都缺乏對概率分布的精確評估和推理,這往往導致VAE中的模糊結果質量不高,GAN訓練也面臨著如模式崩潰和后置崩潰等挑戰。NF能夠較好的解決上述問題,同時NF會和后面的基于特征的方法進行結合,也是目前在MVTec AD上取得效果最好的方法。
3)基于深度特征建模的方法:主要包括知識蒸餾和特征建模兩大類。特別是特征建模,可以細分為很多小類,例如:KNN,SOM,高斯建模等,詳細的內容可以見文章。
4)基于自監督的方法:主要分為代理任務和對比學習。代理任務包括常見的重建、補全、相對關系預測和屬性修護等。
5)基于one-class分類的方法:這個方法主要是異常檢測AD采用的,如果將圖像劃分為滑動窗口,所有的AD方法也適用于AL。此外,它也可以與前面4種方法相結合。
4. 實驗評估和對比分析
數據集:準確來說常用于AL定位的數據集有三個:NanoTWICE、MVTec AD和BTAD。這三個數據集也是做AL論文中引用最多的。當然還有一些有監督的分割數據集也會被拿過來做評測,包括KolektorSDD、KolektorSDD2和MT Defect等。
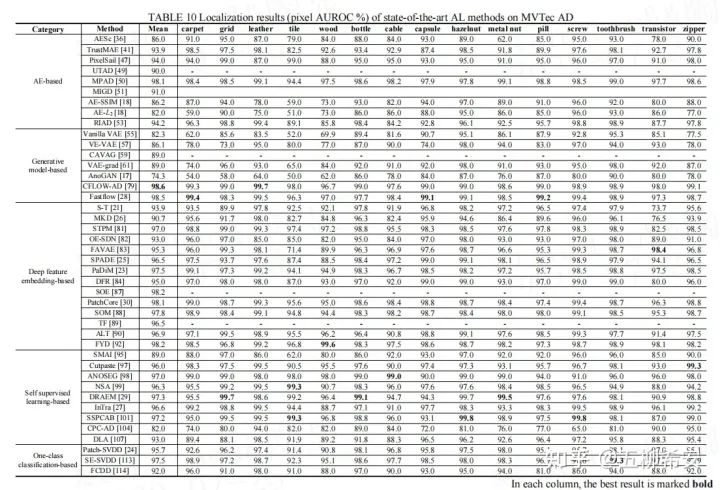

MVTec AD數據集上的性能:文章中表10和11總結了目前AL方法(主要發布于2017至2021)在MVTec AD數據集上的性能。我們觀察到,大多數方法在AE的幫助下達到了基線性能。一些嘗試致力于設計更強大的模塊,如圖像修復和GAN生成網絡。例如RIAD方法,在MVTec AD數據集上的像素AUROC已達到94.2%[53]。然而,實驗結果表明,這些純基于AE自動編碼器的重建或生成方法很難在MVTec AD數據集上表現良好。
相比之下,基于深度特征嵌入的方法很快在AL中展示了它們的優勢。過去論文中的結果表明,三種典型的特征比較方法,S-T[21]、SPADE[25]和DFR[84],在MVTec AD數據集上分別實現了93.9%、96.5%和95.0%的像素AUROC。從通用特征建模方法[23]開始,當引入更有效的策略時,基于特征嵌入的方法穩步改進,例如,將特征選擇引入半正交嵌入[87]、注意力策略[23,43]、帶內存庫的KNN[30]、自組織特征[88]和對齊特征[92]。因此,在MVTec AD數據集上,大多數方法產生約93%的像素AUROC和91%的PRO分數。
此外,CFLOW-AD[79]與一種新型的生成網絡相結合,性能優于其他最先進的模型,并實現了迄今為止MVTec AD上最好的像素AUROC。另一方面,MPAD[50]結合預先訓練的功能,超越了其他最先進的模型,并在MVTec AD上取得了迄今為止最好的PRO分數。在這里,在文章中圖13中,我們展示了MVTec AD上四種典型特征嵌入方法的AL結果的可視化,包括STPM[81]、PatchCore[30]、PaDiM[23]和CFLOW-AD[79]。這些結果是使用Intel corporation維護的標準圖像庫Anomalib[125]獲得的。基于自監督學習的方法可以從未標記的圖像中學習視覺特征,并作為附加模塊嵌入到上述網絡結構中。與原始的基于AE自動編碼器的方法相比,這種方法,例如ANOSEG[98]、NSA[99]和DRAEM[29]可以獲得更好的結果。此外,與圖像重建或預訓練特征相比,基于對比學習的方法[92107]由于異常區域的判別信息,表現出非常有競爭力的性能。基于One class分類的方法通常耗時且定位結果不準確,尤其是裁剪局部斑塊和提取單個局部特征的計算時間。然而,一些方法包括更復雜的特征比較過程,例如,patch-SVDD[24]和SE-SVDD[113]。
總之,基于深度學習的人工智能方法可以通過采用不同的策略在MVTec AD數據集上獲得相對滿意的結果。特別是,15個數據集中有3個數據集沒有被大多數方法克服;這些是瓷磚、木材和晶體管數據集。瓷磚和木材是典型的紋理數據集,包含多尺度和多類型的缺陷,目前主要方法未達到95%的AUROC。晶體管數據集具有包含高級語義信息的缺失缺陷類型,也就是功能異常。在該數據集中,它將所有缺失范圍視為ground-truth。因此,目前的主要方法也沒有達到理想的性能。
5. 未來的研究方向
功能異常:從上表中提到的優缺點可以看出,許多方法的異常定位效果在某些特定數據集上顯著下降。例如,DFR[84]的缺點是晶體管數據集的性能較差(參見文章表6、10)。這是因為文章表10中顯示的大多數數據集是紋理缺陷,例如劃痕和凹痕,而非功能異常。功能異常違反了基本約束,例如,允許的對象位于無效位置或缺少所需的對象。在工業場景中,這兩種類型同等重要。目前,Bergmann等人[126]已經提出了一種聯合檢測紋理和功能異常的方法。因此,對功能缺陷或異常的研究將是未來的一個重要方向。
發布豐富的AL數據集:與真實行業場景相比,公共異常位置數據集還不夠大或豐富。應提供具有變化成像條件(如照明、透視、比例、陰影、模糊等)的更復雜數據集,以更客觀地評估AL算法的效果。現有的MVTec AD具有單成像、相對良好的圖像質量和某些類別的對齊。一些現有的方法甚至利用這一特性來提高性能。盡管取得了有希望的結果,但這些方法無法適應實際復雜的工業場景。因此,有必要擁有一些現實而豐富的工業數據集。
基于ViT的方法:基于ViT的方法由于其優越的性能,目前在計算機視覺領域占據主導地位。還提出了一些基于ViT的工作[27、124、79]來解決AL問題。ViT在長距離特征建模中具有獨特的優勢。綜合考慮多尺度異常區域是ViT可以改進的方向。此外,AL的最佳框架是基于NF的生成模型。因此,ViT和NF的結合也一直是一個重要的方向。
有意義的模型評估:如文章中圖13所示,高像素AUROC值和精細的定位性能之間存在偏差,這可能會導致模型有效性問題。許多方法仍然使用像素AUROC評估指標,但AL的可視化結果表現并不佳,背景存在大量過檢,也就是異常被定位出來的效果很粗,缺陷的輪廓并不精細。建議未來的工作在建立模型時考慮精細邊界問題,或選擇IoU度量進行模型評估。
準確的異常類型:實際工業場景中的異常類型多種多樣,不同異常類型的重要性不同。現有的AD/AL方法,僅僅給出缺陷這一單一類別或位置,無法得到詳細的缺陷類型,例如劃傷、異物、異色等,這個問題挑戰了AD或AL的經典范式,需要開發能夠區分異常類型的學習方法。已有方法[122]對異常類型進行聚類,并將異常數據分組到語義一致的類別中,但這僅僅是一個開始。
無監督三維異常定位:隨著三維傳感器的普及,工業場景中越來越多的缺陷檢測任務正在從二維場景轉移到三維場景。相應地,三維場景中的人工智能也將成為一種發展趨勢。最近,MVTec公司在2021年底公開了一個3D AD/AL數據集[123]。因此,我們認為3D AD/AL構成了一個相關的未來方向。
審核編輯 :李倩
-
計算機視覺
+關注
關注
9文章
1708瀏覽量
46638 -
數據集
+關注
關注
4文章
1223瀏覽量
25330 -
深度學習
+關注
關注
73文章
5557瀏覽量
122610
原文標題:基于深度學習的工業圖像異常定位(檢測)綜述
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
機器學習異常檢測實戰:用Isolation Forest快速構建無標簽異常檢測系統

提高IT運維效率,深度解讀京東云AIOps落地實踐(異常檢測篇)






 工商網監
工商網監
評論