 OCR算法能較好識別水平排布的常規文本
OCR算法能較好識別水平排布的常規文本

本文簡要介紹ECCV 2022錄用的論文“When Counting Meets HMER: Counting-Aware Network for Handwritten Mathematical Expression Recognition”的主要工作。該論文旨在緩解目前大部分基于注意力機制的手寫數學公式識別算法在處理較長或者空間結構較復雜的數學公式時,容易出現的注意力不準確的情況。本文通過將符號計數任務和手寫數學公式識別任務聯合優化來增強模型對于符號位置的感知,并驗證了聯合優化和符號計數結果都對公式識別準確率的提升有貢獻。
一、研究背景
OCR技術發展到今天,對于常規文本的識別已經達到了較高的準確率。但是對于在自動閱卷、數字圖書館建設、辦公自動化等領域經常出現的手寫數學公式,現有OCR算法的識準確率依然不太理想。不同于常規文本,手寫數學公式有著復雜的空間結構以及多樣化的書寫風格,如圖1所示。其中復雜的空間結構主要是由數學公式獨特的分式、上下標、根號等結構造成的。雖然目前的OCR算法能較好地識別水平排布的常規文本,甚至對于一些多方向以及彎曲文本也能夠有不錯的識別效果,但是依然不能很好地識別具有復雜空間結構的數學公式。
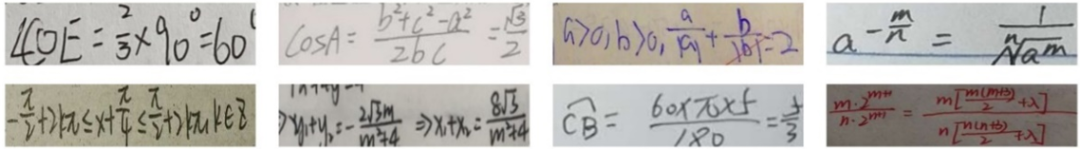
圖1 手寫數學公式示例
二、研究動機
現有的大部分手寫數學公式識別算法采用的是基于注意力機制的編碼器-解碼器結構,模型在識別每一個符號時,需要注意到圖像中該符號對應的位置區域。在識別常規文本時,注意力的移動規律比較單一,往往是從左至右或從右至左。但是在識別數學公式時,注意力在圖像中的移動具有更多的可能性。因此,模型在解碼較復雜的數學公式時,容易出現注意力不準確的現象,導致重復識別某符號或者是漏識別某符號。
為了緩解上述現象,本文提出將符號計數引入手寫數學公式識別。這種做法主要基于以下兩方面的考慮:1)符號計數(如圖2(a)所示)可以隱式地提供符號位置信息,這種位置信息可以使得注意力更加準確(如圖2(b)所示)。2)符號計數結果可以作為額外的全局信息來提升公式識別的準確率。
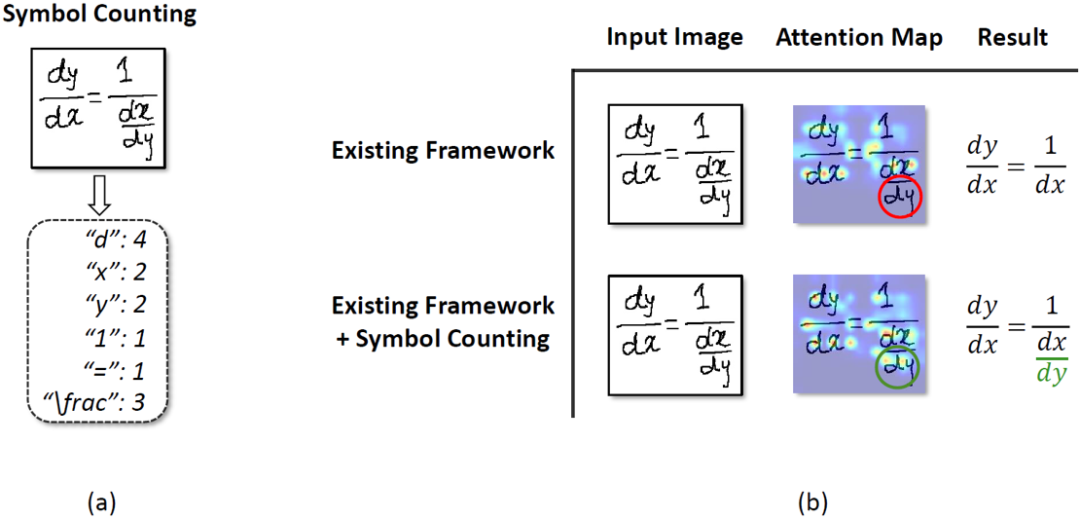
圖2 (a)符號計數任務;(b)符號計數任務讓模型擁有更準確的注意力
三、方法簡述
模型整體框架:如圖3所示,CAN模型由主干特征提取網絡、多尺度計數模塊(MSCM)和結合計數的注意力解碼器(CCAD)構成。主干特征提取網絡采用的是DenseNet[1]。對于給定的輸入圖像,主干特征提取網絡提取出2D特征圖F。隨后該特征圖F被輸入到多尺度計數模塊MSCM,輸出計數向量V。特征圖F和計數向量V都會被輸入到結合計數的注意力解碼器CCAD來產生最終的預測結果。
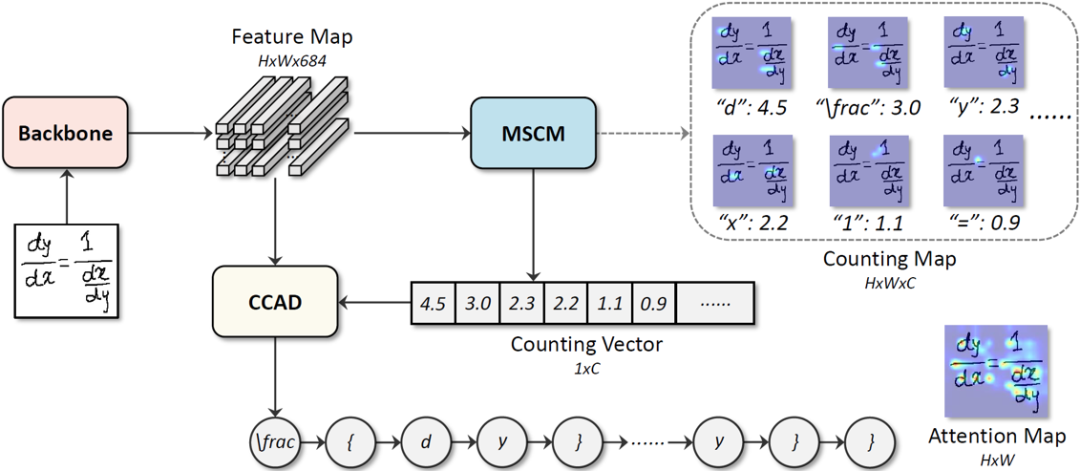
圖3 CAN模型整體框架
多尺度計數模塊:在人群計數等任務中,部分方法采用弱監督的范式,在不需要使用人群位置標注的情況下預測人群密度圖。本文借鑒了這一做法,在只使用公式識別原始標注(即LaTeX序列)而不使用符號位置標注的情況下進行多類符號計數。針對符號計數任務,該計數模塊做了兩方面獨特的設計:1)用計數圖的通道數表征類別數,并在得到計數圖前使用Sigmoid激活函數將每個元素的值限制在(0,1)的范圍內,這樣在對計數圖進行H和W維度上的加和后,可以直接表征各類符號的計數值。2)針對手寫數學公式符號大小多變的特點,采用多尺度的方式提取特征以提高符號計數準確率。
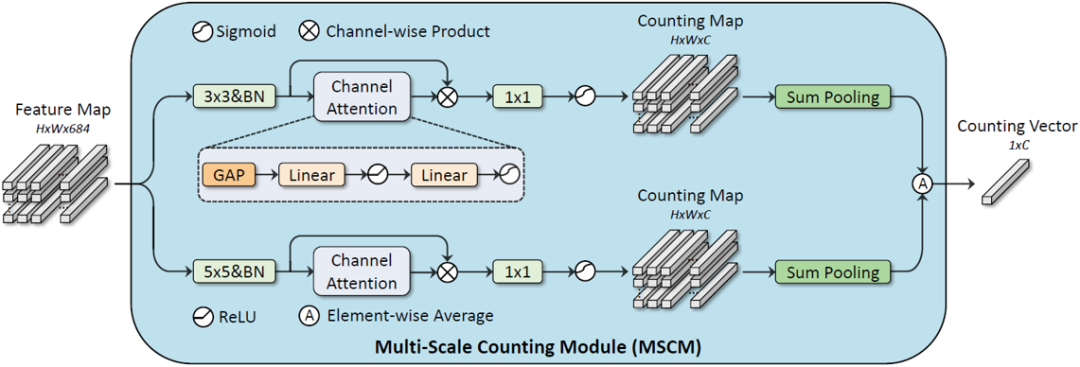
圖4 多尺度計數模塊MSCM
結合計數的注意力解碼器:為了加強模型對于空間位置的感知,使用位置編碼表征特征圖中不同空間位置。另外,不同于之前大部分公式識別方法只使用局部特征進行符號預測的做法,在進行符號類別預測時引入符號計數結果作為額外的全局信息來提升識別準確率。
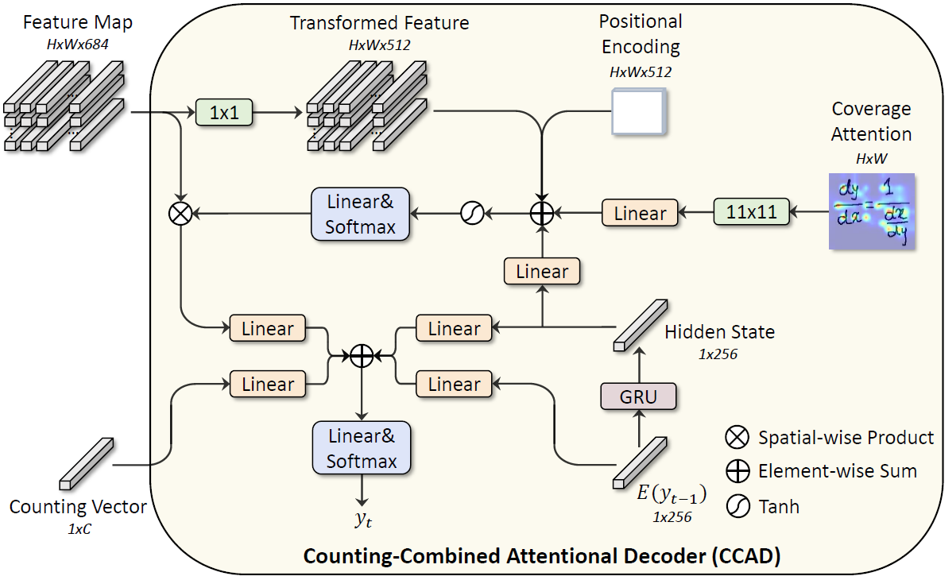
圖5 結合計數的注意力解碼器CCAD
四、實驗結果
在廣泛使用的CROHME數據集以及新出現的HME100K[2]數據集上都進行了實驗并與之前的最優方法做了比較。如表1和表2所示,可以看出CAN取得了目前最高的識別準確率。此外,使用經典模型DWAP[3]作為baseline得到的CAN-DWAP以及使用之前最優模型ABM[4]作為baseline得到的CAN-ABM,其結果都分別優于對應的baseline模型,這說明本文所提出的方法可以被應用在目前大部分編碼器-解碼器結構的公式識別模型上并提升它們的識別準確率。
表1 在CROHME數據集上的結果 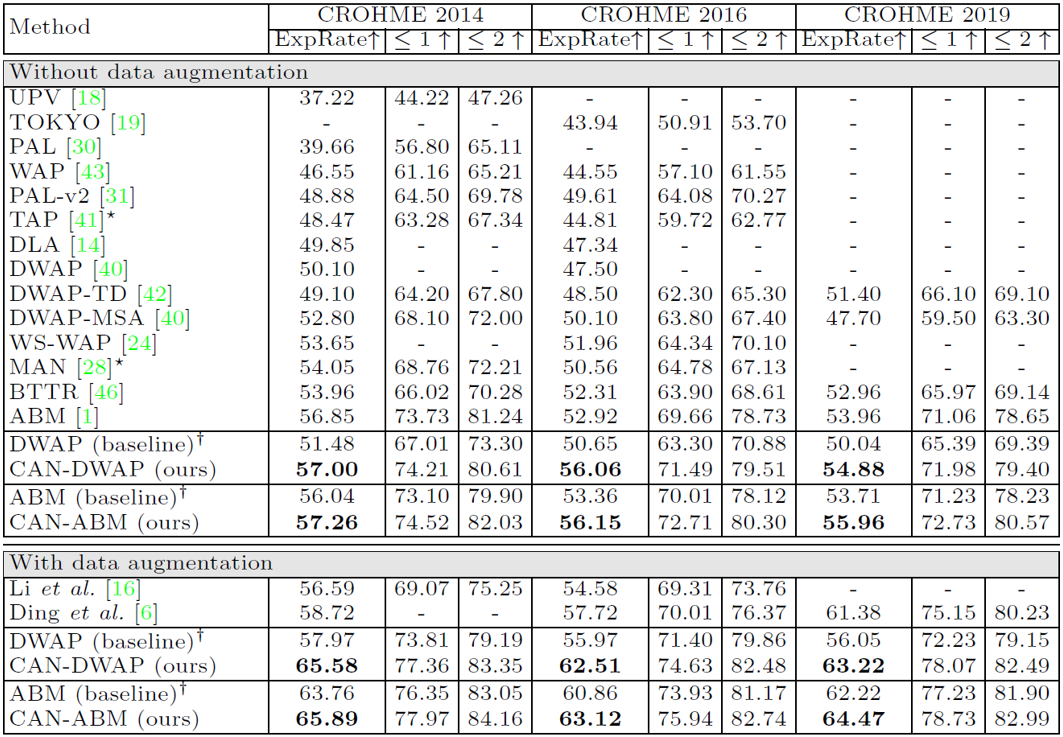 表2 在HME100K數據集上的結果?
表2 在HME100K數據集上的結果?  ?
? 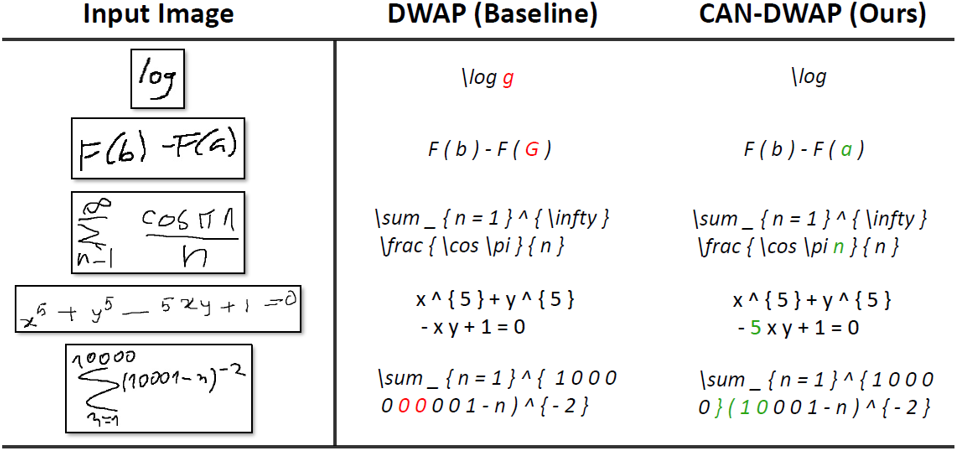
圖6 在CROHME數據集上DWAP和CAN-DWAP的識別結果展示
對于模型各部分帶來的提升,本文做了消融實驗。如表3所示,加入位置編碼、將兩種任務聯合優化以及融合符號計數結果進行預測都能提升模型對于手寫數學公式的識別準確率。此外,為了驗證采用多尺度的方式提取特征的有效性以及研究符號計數結果對于公式識別準確率的影響,本文做了實驗進行驗證。如表4所示,使用大小不同的卷積核提取多尺度特征有助于獲得更高的符號計數準確率。并且計數結果越準確,對公式識別的提升也越大。表5則展示了當使用符號計數的GT(Ground Truth)時對于模型識別準確率的提升。
表3 模型各部分帶來的提升

表4 計數模塊中卷積核大小的影響
 表5 符號計數結果對公式識別準確率的影響?
表5 符號計數結果對公式識別準確率的影響? 
符號計數對于公式識別有促進作用,那么反過來公式識別能否提升符號計數的準確率呢?本文對這一問題也做了探討,實驗結果和符號計數可視化結果如表6和圖7所示,可以看出公式識別任務也可以提升符號計數的準確率。本文認為這是因為公式識別的解碼過程提供了符號計數任務缺少的上下文語義信息。
表6 公式識別對符號計數準確率的影響

 圖7 符號計數結果及計數圖可視化
圖7 符號計數結果及計數圖可視化
五、文本結論
本文設計了一種新穎的多尺度計數模塊,該計數模塊能夠在只使用公式識別原始標注(即LaTeX序列)而不使用符號位置標注的情況下進行多類別符號計數。通過將該符號計數模塊插入到現有的基于注意力機制的編碼器-解碼器結構的公式識別網絡中,能夠提升現有模型的公式識別準確率。此外,本文還驗證了公式識別任務也能通過聯合優化來提升符號計數的準確率。
-
編碼器
+關注
關注
45文章
3791瀏覽量
137865 -
模型
+關注
關注
1文章
3516瀏覽量
50342 -
OCR
+關注
關注
0文章
161瀏覽量
16780
原文標題:ECCV 2022 | 白翔團隊提出CAN:手寫數學公式識別新算法
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
提供銀行卡識別API免費接入的OCR SDK開發者平臺
首發 | 告別手動錄入,開放平臺OCR上線印刷文字識別!
c#+halcon1.5 ocr字符識別
自編通用視覺框架實現基本算子以及OCR識別功能
Python OCR 識別庫-ddddocr
【KV260視覺入門套件試用體驗】七、VITis AI字符和文本檢測(OCR&Textmountain)
基于FPGA的OCR文字識別技術的深度解析
關于開放平臺OCR上線印刷文字識別的介紹
一篇包羅萬象的場景文本檢測算法綜述
OCR識別技術
一篇包羅萬象的場景文本檢測算法綜述
機器視覺運動控制一體機應用例程|OCR字符識別應用

OCR實戰教程
easyocr:超級簡單且強大的OCR文本識別工具

OCR如何自動識別圖片文字





 工商網監
工商網監
評論