") 怎么看見(jiàn)和定量分析驗(yàn)證平臺(tái)的時(shí)間呢
怎么看見(jiàn)和定量分析驗(yàn)證平臺(tái)的時(shí)間呢

我們說(shuō)的“提速”到底提的是什么時(shí)間?
1、驗(yàn)證仿真中的“3個(gè)時(shí)間”
在驗(yàn)證仿真過(guò)程中,我們腦中需要閃過(guò)至少3個(gè)概念:
墻上時(shí)鐘時(shí)間(wall clock time)
cpu時(shí)間(cpu time)
仿真時(shí)間(simulation time)
他們都是什么呢?
1.墻上時(shí)鐘時(shí)間(wall clock time):
顧名思義,它是“掛在墻上的時(shí)鐘”的時(shí)間,這個(gè)時(shí)間也就是我們真實(shí)世界真正“走過(guò)的時(shí)間”。
你跑一個(gè)case,對(duì)于linux系統(tǒng)來(lái)說(shuō),就是一個(gè)或多個(gè)進(jìn)程,而這個(gè)wall clock time,它是進(jìn)程運(yùn)行的時(shí)鐘總量。它除了包括cpu真正的運(yùn)行時(shí)間之外,還包括了如:
就緒時(shí)間:
進(jìn)程具備運(yùn)行條件,但是還沒(méi)有CPU資源可用。例如你提交了一個(gè)case,但是半天提不上去跑不起來(lái),可能因?yàn)槠渌说腸ase太多,導(dǎo)致機(jī)器滿載了,等別人釋放了之后你的case才真正獲得cpu資源運(yùn)行起來(lái)。
阻塞時(shí)間:
例如你的case已經(jīng)跑起來(lái)了,發(fā)現(xiàn)某個(gè)vip lisence不夠了,“卡”到那里了。
或者例如你編譯運(yùn)行過(guò)程中因?yàn)榇疟P(pán)不太充足出現(xiàn)的卡頓現(xiàn)象等。
2.cpu時(shí)間(cpu time):
當(dāng)進(jìn)程運(yùn)行起來(lái)之后,占用cpu進(jìn)行計(jì)算花費(fèi)的時(shí)間。同樣是代碼在cpu上運(yùn)行,依據(jù)代碼類(lèi)別不同,cpu時(shí)間也分為用戶cpu時(shí)間和系統(tǒng)cpu時(shí)間。
用戶cpu時(shí)間是代碼在用戶態(tài)(User Mode)運(yùn)行的時(shí)間。
系統(tǒng)cpu時(shí)間是代碼在內(nèi)核態(tài)(Kernel Mode)運(yùn)行的時(shí)間。
我們可以簡(jiǎn)單理解:依據(jù)代碼權(quán)限不同,用戶態(tài)執(zhí)行用戶代碼,內(nèi)核態(tài)執(zhí)行的是操作系統(tǒng)代碼。這里不深入展開(kāi)了,感興趣的朋友可以查閱一些資料(為什么這里要多引申提一下這個(gè)概念,主要幫沒(méi)有聽(tīng)過(guò)這些概念的朋友,在仿真性能分析報(bào)告中如果碰到相關(guān)詞匯,至少可以有一個(gè)簡(jiǎn)單的感性認(rèn)知)。
此外,從前面的wall clock time解釋可以看出,比如你的case被阻塞了、掛起了是不占用cpu時(shí)間的,但是真實(shí)時(shí)間還是繼續(xù)走的。有兄弟可能會(huì)問(wèn):“照這么說(shuō),wall clock time是不是肯定是大于cpu time?”
答案是:不一定。
如果是多核處理器機(jī)器上,cpu總時(shí)間是所有不同線程或進(jìn)程cpu時(shí)間之和,此時(shí)wall clock time時(shí)間就會(huì)比cpu總時(shí)間小了。其實(shí)依據(jù)wall clock time和cpu總時(shí)間的關(guān)系,也把進(jìn)程分為計(jì)算密集型(wall clock time小于cpu time,有多核并行的優(yōu)勢(shì))和I/O密集型(wall clock time大于cpu time,沒(méi)有多核優(yōu)勢(shì),很多等待時(shí)間)。
舉一個(gè)例子,如下截圖,VCS軟件對(duì)于verilog設(shè)計(jì)部分的編譯過(guò)程中,允許通過(guò)-j選項(xiàng)指定并行數(shù)量。在選擇合適的并行數(shù)量的情況下,相關(guān)部分編譯的wall clock time就會(huì)小于cpu time哦~

3.仿真時(shí)間(Simulation time)
仿真時(shí)間是仿真器維護(hù)的時(shí)間,就是我們波形中看到的那個(gè)多少ns多少ps那個(gè)時(shí)間,它顯然不是仿真過(guò)程中真實(shí)的時(shí)間。這個(gè)時(shí)間是為了表示實(shí)際電路的運(yùn)行時(shí)間,給電路仿真建模用的一個(gè)“數(shù)字”。
我們知道SystemVerilog是在值的更新、計(jì)算等一個(gè)個(gè)離散事件的相互觸發(fā)“推著”往前走的(推著走的單位就是也就是我們之前講過(guò)的global time precision,也就是timeslot)。
所以仿真時(shí)間長(zhǎng)短和運(yùn)行時(shí)間長(zhǎng)短、仿真速度沒(méi)什么關(guān)系,主要是看“步子”有多少。在其他所有因素都一樣的情況下,誰(shuí)的事件少、推的步子少誰(shuí)仿真的速度也就更快。
再舉個(gè)例子:`timescale 1ns/1ps 和`timescale 10ns/10ps,它們的time unit和time precision都同時(shí)擴(kuò)大了10倍,但它們的比值是一樣的,即“步子”數(shù)量是一樣的。在其他背景完全一樣的相同仿真單位度量情況下(這里指的不帶具體單位,如,#1;前者代表運(yùn)行1ns后者表示運(yùn)行10ns),仿真速度是一樣的。
Tips:我們說(shuō)平臺(tái)提速到底要提哪個(gè)時(shí)間?
剛才Jerry給大家拋出了驗(yàn)證仿真的“3個(gè)時(shí)間”,我們回到本系列文章“驗(yàn)證仿真提速”主題,拋出一下最底層的問(wèn)題:我們追求“提速”,根本目標(biāo)是想要減少哪個(gè)時(shí)間?
沒(méi)錯(cuò),我們追求的最根本目標(biāo)是減少墻上時(shí)鐘時(shí)間(wall clock time),即我們需要的是減少自己浪費(fèi)的真實(shí)世界的時(shí)間,多跑幾輪case或者早點(diǎn)跑出結(jié)果早下班。如果你費(fèi)盡心思減少cpu time、仿真時(shí)間,最后wall clock time沒(méi)有降下來(lái)對(duì)于我們有個(gè)毛線意義??雖然如前面有提到這3個(gè)時(shí)間有相關(guān)性,但是希望大家心中一定要明確我們的根本目標(biāo)。
2、怎么看見(jiàn)和定量分析驗(yàn)證平臺(tái)的時(shí)間?
有了前面的認(rèn)知鋪墊,我們回到實(shí)戰(zhàn)。如何定量分析驗(yàn)證平臺(tái)的時(shí)間和資源,我們以VCS工具為例(其他家工具大家自行探索),一般可以有兩種抓取性能信息的方式,一種是以“輕量級(jí)”的方式輸出編譯和運(yùn)行仿真過(guò)程中的性能匯總信息,一種是相對(duì)“重量級(jí)”的方式進(jìn)一步詳細(xì)分析仿真運(yùn)行性能信息。第二種為什么說(shuō)比較“重量級(jí)”呢?主要原因是它本身就會(huì)造成很大的時(shí)間消耗。我們都簡(jiǎn)要介紹一下:
1.以“輕量級(jí)”的方式輸出編譯和運(yùn)行仿真過(guò)程中的性能匯總信息。
增加vcs編譯選項(xiàng): -reportstats
增加simv仿真選項(xiàng):-reportstats
工具將會(huì)直接把編譯和運(yùn)行的匯總性能報(bào)告直接打印在屏幕上,我們示意性跑出來(lái)的一組截圖如下:
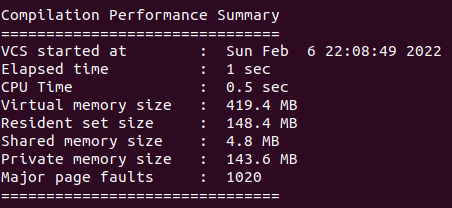
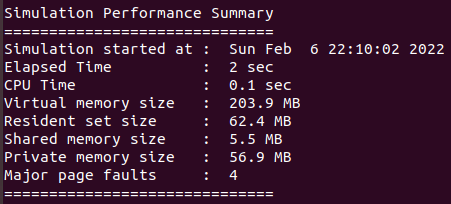
上面的主要細(xì)節(jié)vcs手冊(cè)解釋原文如下:
? VCS start time
? Elapsed real time: wall clock time from VCS start to VCS end
? CPU time: Accumulated user time + system time from all
processes spawned from VCS
? Peak virtual memory size summarized from all the contributing
processes at specific time points
? Sum of resident set size from all the contributing processes at
specific time points
? Sum of shared memory from all the contributing processes at
specific time points
? Sum of private memory from all the contributing processes at
specific time points
? Major fault accumulated from all processes spawned from VCS
我們本篇主要關(guān)心時(shí)間,有了前文的鋪墊相信這里可以看得比較清楚了。
從上面的解釋可知:Elapsed real time就是編譯或運(yùn)行階段的墻上時(shí)鐘時(shí)間(wall clock time),cpu time是vcs產(chǎn)生所有進(jìn)程的用戶cpu時(shí)間和系統(tǒng)cpu時(shí)間總和。
順便,從這個(gè)舉例的截圖報(bào)告也可以明顯看出wall clock time大于cpu time,沒(méi)有任何多核優(yōu)勢(shì),屬于I/O密集型。
這里提一個(gè)點(diǎn),我們前面討論3種時(shí)間的時(shí)候可以了解到:即使是跑同樣的case,用同樣的種子,跑出來(lái)的時(shí)間統(tǒng)計(jì)信息也一定會(huì)因?yàn)榇疟P(pán)狀態(tài)等原因而不同。所以對(duì)于測(cè)試某種手段是否減少了總時(shí)間花費(fèi),是否有收益(尤其是不太明顯的手段),單純的通過(guò)前后兩次跑同樣的case,對(duì)比統(tǒng)計(jì)結(jié)果是不足以判別的,如果不是明顯的提速手段,可能會(huì)出現(xiàn)使用后wall clock time和cpu time反而比使用前花費(fèi)更多時(shí)間。但是如果基于相同的服務(wù)器等因素的狀態(tài),或基于統(tǒng)計(jì)的方式多次測(cè)試評(píng)估,就可以看出總體速度的提升趨勢(shì)。
2.以相對(duì)“重量級(jí)”的方式進(jìn)一步詳細(xì)分析仿真運(yùn)行的性能信息。
增加vcs編譯選項(xiàng) -lca -simprofile
增加simv仿真選項(xiàng) -simprofile time
(這個(gè)仿真選項(xiàng)后面除了跟time觀測(cè)仿真時(shí)間信息還可以加:如mem收集服務(wù)器內(nèi)存消耗信息等,當(dāng)然也可以如time+mem同時(shí)收集) 這些選項(xiàng)加了之后,工具會(huì)生成如下帶“profile”關(guān)鍵詞的文件和文件夾,我們主要看profileReport.html文件。

html文件打開(kāi)后會(huì)發(fā)現(xiàn)分左右兩個(gè)區(qū)域,通過(guò)左邊區(qū)域可以控制出現(xiàn)在右邊區(qū)域你想要看到的性能信息,示意圖如下:

Jerry通過(guò)time+mem的選項(xiàng),隨意跑了一個(gè)case,相關(guān)的summary示意圖如下:
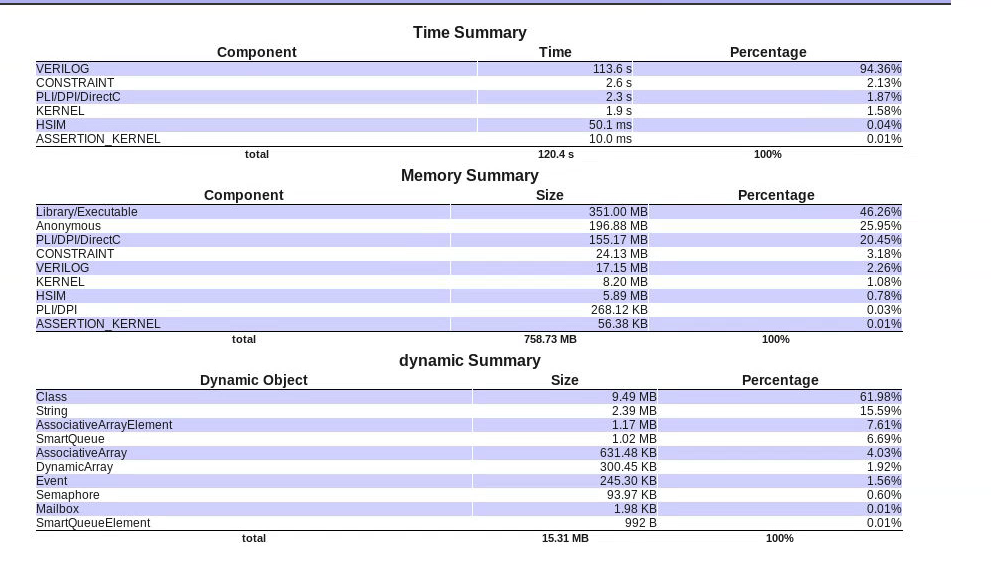
我們還是關(guān)心time,主要貼下time的相關(guān)copmponent的含義(下面有的條目在上圖例子中不涉及,別的case也許就會(huì)有):
?CONSTRAINT
The CPU time needed to solve and simulate the SystemVerilog constraint blocks.
?KERNEL
The CPU time needed by the VCS kernel. This CPU time is separate from the CPU time needed to simulated your Verilog or SystemVerilog, VHDL, SystemC, or C or C++ code for your design and testbench.
?VERILOG
The CPU time needed by VCS to simulate this example’s SystemVerilog code, which is a program block. For Verilog and SystemVerilog there are sub-components.
?DEBUG
The CPU time needed by VCS to simulate this example with the debugging capabilities of Verdi and the UCLI or to write a simulation history VCD or FSDB file.
?Value Change Dumping
The CPU time needed by VCS to write a simulation history VCD or VPD file.
?VHDL
For VCS only, the CPU time needed to simulate the VHDL code design.
?PLI/DPI/DirectC
The CPU time needed by VCS to simulate the C/C++ in a PLI, DPI, or DirectC application.
?HSIM (Hybrid Simulation)
This is about the CPU time used by HSOPT (Hybrid Simulation Optimization). The HSIM bucket indicates the CPU time consumption of design constructs that are optimized by HSOPT. It has become prominent in GLS design/RTL. The HSIM cost is more with GLS design because most constructs are optimized by HSOPT. But it cannot be zero because there are some global HSIM activities.
?COVERAGE
The CPU time needed for functional coverage (testbench and assertion coverage). Code coverage is not part of this component.
?SystemC
The CPU time needed for SystemC simulation.
通過(guò)調(diào)節(jié)前面提到html左邊區(qū)域選項(xiàng),還可以看到更多的信息,如進(jìn)一步查看仿真過(guò)程中rtl和tb各個(gè)模塊層級(jí)花費(fèi)的時(shí)間信息,這里就不多贅述了,其他的玩法大家感興趣可以自己研究。
這種“重量級(jí)”的方式,雖然會(huì)拖慢仿真時(shí)間,但一個(gè)優(yōu)勢(shì)是收集的信息更加詳細(xì),可以更直觀的看到各部分資源消耗百分比,更好的協(xié)助我們找到消耗時(shí)間的性能瓶頸,提供優(yōu)化方向和縮小優(yōu)化范圍。
結(jié)語(yǔ)
我們今天圍繞“時(shí)間”這個(gè)主題,首先討論了驗(yàn)證仿真中的“3個(gè)時(shí)間”建立了基礎(chǔ)認(rèn)知,接著明確了平臺(tái)提速到底要提哪個(gè)時(shí)間?最后以vcs工具舉例了怎么收集和分析相關(guān)信息。
審核編輯:劉清
-
cpu
+關(guān)注
關(guān)注
68文章
11080瀏覽量
217084 -
時(shí)鐘
+關(guān)注
關(guān)注
11文章
1901瀏覽量
133231 -
多核處理器
+關(guān)注
關(guān)注
0文章
110瀏覽量
20310
原文標(biāo)題:驗(yàn)證仿真提速系列--認(rèn)識(shí)“時(shí)間”與平臺(tái)速度定量分析
文章出處:【微信號(hào):處芯積律,微信公眾號(hào):處芯積律】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
時(shí)間間隔測(cè)量分析儀特點(diǎn)總結(jié)

Fluke福祿克435電能質(zhì)量分析儀B通道電流測(cè)試不準(zhǔn)維修過(guò)程分享

飛行時(shí)間質(zhì)譜儀數(shù)據(jù)讀出解決方案

基于LIBS技術(shù)的銀合金分類(lèi)及定量分析研究
電能質(zhì)量分析儀在電力監(jiān)測(cè)中的應(yīng)用
電能質(zhì)量分析儀的作用與用途
透射電鏡中的EDS定性與定量分析
FPD-link裕量分析程序(MAP)用戶指南

基于LIBS技術(shù)的煤炭灰分、揮發(fā)分和熱值定量分析及特征工程研究

中國(guó)開(kāi)發(fā)出基于可編程DNA水凝膠的紙基比距傳感器
什么是成分分析?
基于LIBS的馬鈴薯中鉻元素定量分析方法研究
定量光學(xué)氣體成像的優(yōu)勢(shì)和工作流程
基于LIBS的土壤中銅元素和鉛元素定量分析

氣體泄漏定量報(bào)警系統(tǒng)SF6 的組成——每日了解電力知識(shí)

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車(chē)電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專(zhuān)欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 社區(qū)
- 小組
- 論壇
- 問(wèn)答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開(kāi)發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開(kāi)發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論