") 如何統(tǒng)一各種信息抽取任務(wù)的輸入和輸出
如何統(tǒng)一各種信息抽取任務(wù)的輸入和輸出
信息抽取任務(wù)包括命名實(shí)體識(shí)別(NER)、關(guān)系抽取(RE)、事件抽取(EE)等各種各樣的任務(wù)。不同的信息抽取任務(wù)針對(duì)的任務(wù)不同,希望得到的輸出也不同。例如下面的例子中,對(duì)于NER任務(wù),需要識(shí)別Steve是PER、Apple是ORG;而對(duì)于關(guān)系抽取任務(wù),則需要識(shí)別出Steve和Apple是Work For的關(guān)系。此外,不同場(chǎng)景的同一個(gè)信息抽取任務(wù)的輸出可能也是不同的。
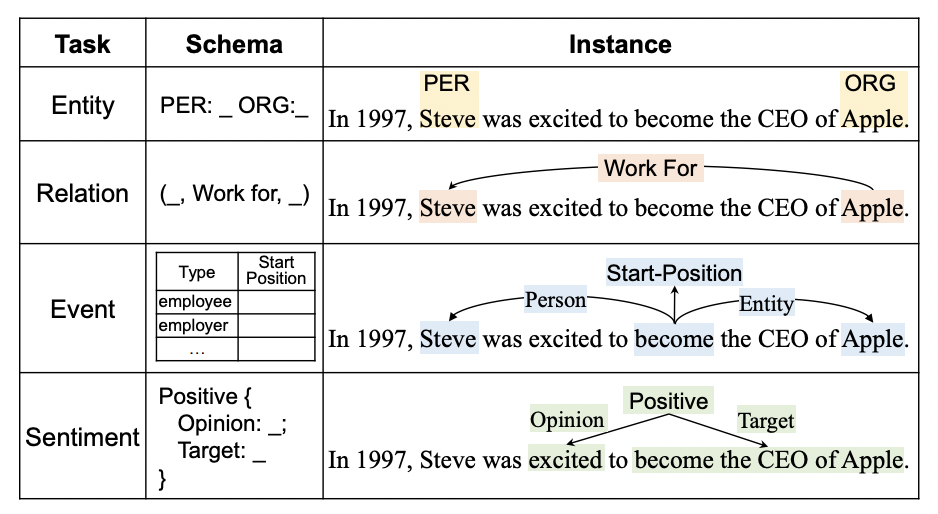
目前業(yè)內(nèi)比較常見(jiàn)的做法是針對(duì)每個(gè)場(chǎng)景的每種信息抽取任務(wù),分別獨(dú)立的訓(xùn)練一個(gè)模型。這種方法成本很高,每種任務(wù)、每種場(chǎng)景都要建立模型。此外,獨(dú)立的訓(xùn)練模型導(dǎo)致不同任務(wù)之間無(wú)法共享知識(shí),沒(méi)有發(fā)揮出數(shù)據(jù)和模型的全部能力。
中科院、百度在ACL 2022中提出了一種可以實(shí)現(xiàn)統(tǒng)一建模各類信息抽取任務(wù)的框架UIE,在4種信息檢索任務(wù)的13個(gè)數(shù)據(jù)集上都取得了顯著效果。
1 統(tǒng)一多種信息抽取任務(wù)
要想實(shí)現(xiàn)使用一個(gè)模型解決多種信息抽取任務(wù)的目標(biāo),一個(gè)核心問(wèn)題是如何統(tǒng)一各種信息抽取任務(wù)的輸入和輸出。作者提出所有信息抽取任務(wù)都可以抽象成Spotting和Associating兩個(gè)步驟:在Spotting步驟中,確定輸入文本中的實(shí)體以及該實(shí)體對(duì)應(yīng)的實(shí)體類型;在Associating中,建立兩個(gè)實(shí)體之間的關(guān)系。
例如下面是Steve became CEO of Apple in 1997這句話使用上述方法抽象出來(lái)的描述語(yǔ)言。藍(lán)色的代表關(guān)系抽取,紅色的代表事件抽取,其他的是命名實(shí)體識(shí)別。首先能夠識(shí)別出person、organization、time三種實(shí)體。此外Steve可以識(shí)別出work for的關(guān)系,而事件以became作為start-position,關(guān)聯(lián)employee、employer、time。

通過(guò)上述方法,可以實(shí)現(xiàn)將所有信息抽取任務(wù)都抽象為相同結(jié)構(gòu)的語(yǔ)言描述,為后續(xù)的多任務(wù)統(tǒng)一建模打下了基礎(chǔ)。
2 基于prompt的多任務(wù)統(tǒng)一建模
基于上面的關(guān)系抽取統(tǒng)一描述,本文提出了UIE框架,在輸入側(cè)構(gòu)造每個(gè)任務(wù)structural schema instructor (SSI),以及原始文本,使用Encoder編碼后,使用Decoder解碼統(tǒng)一的信息抽取語(yǔ)言描述。整個(gè)過(guò)程如下圖所示。
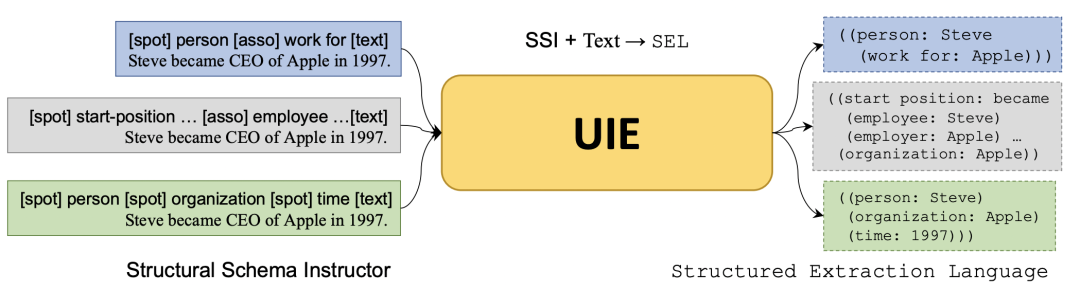
仍然以上面文本為例,輸入由SSL原始文本組成。對(duì)于關(guān)系抽取任務(wù),SSL對(duì)應(yīng)的是[spot] person [asso] word for。這會(huì)作為一個(gè)前綴prompt,用來(lái)指導(dǎo)模型根據(jù)特定的任務(wù)進(jìn)行文本生成。而對(duì)于NER任務(wù),SSL對(duì)應(yīng)的是[spot] person [spot] organization [spot] time。SSL后面接一個(gè)[text]標(biāo)識(shí)符以及原來(lái)的文本。整體的輸入文本拼接模式如下:

上述文本會(huì)通過(guò)Encoder進(jìn)行編碼,然后利用Decoder進(jìn)行文本生成,生成的目標(biāo)文本即為根據(jù)信息抽取的label生成的統(tǒng)一描述。在具體的模型結(jié)構(gòu)上,BART、T5等生成式模型,都可以作為框架的主模型的backbone。這種基于前綴的生成方式,也可以比較容易的適應(yīng)到一個(gè)新的信息抽取任務(wù)上。
3 模型訓(xùn)練
為了訓(xùn)練上面說(shuō)的從SSL+文本到描述的生成式模型,文中采用了三個(gè)預(yù)訓(xùn)練任務(wù)聯(lián)合學(xué)習(xí)。構(gòu)造了3種數(shù)據(jù),分別是SSL+原始文本到結(jié)構(gòu)化文本的pair對(duì)、單獨(dú)的原始文本以及單獨(dú)的結(jié)構(gòu)化文本。第一個(gè)任務(wù)是SSL+原始文本到結(jié)構(gòu)化文本的匹配關(guān)系,匹配的label為1,不匹配label為0,label為0的樣本是通過(guò)隨機(jī)替換spot或associate實(shí)現(xiàn)的。第二個(gè)任務(wù)是使用結(jié)構(gòu)化文本訓(xùn)練Decoder,這一步是為了讓Decoder適應(yīng)結(jié)構(gòu)化文本的語(yǔ)言形式。第三個(gè)任務(wù)是在訓(xùn)練過(guò)程中引入一般的mask language modeling任務(wù),目的是防止模型在訓(xùn)練過(guò)程中丟失了文本原始的語(yǔ)義信息。最終的預(yù)訓(xùn)練loss是下面3個(gè)loss的和:
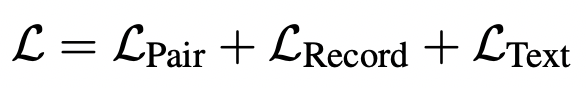
預(yù)訓(xùn)練好的模型可以在下游任務(wù)進(jìn)行finetune以應(yīng)用到各類任務(wù)上。同時(shí)作者引入rejection mechanism,在結(jié)構(gòu)化文本中插入一些在原始輸入中沒(méi)有的實(shí)體以及NULL,讓模型可以通過(guò)生成NULL避免被誤導(dǎo)生成不正確的結(jié)果。

4 實(shí)驗(yàn)結(jié)果
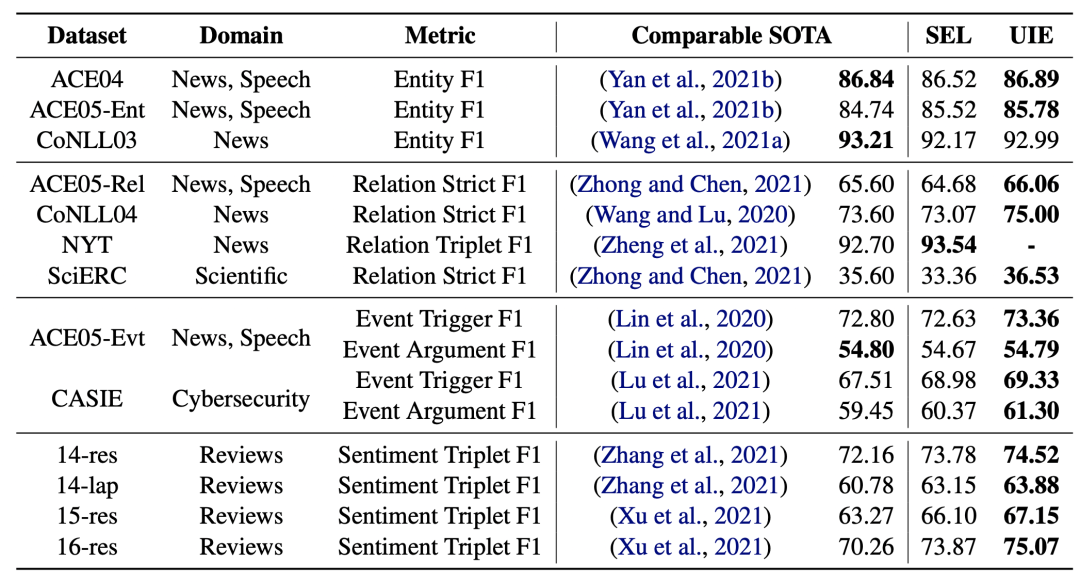
UIE框架在信息抽取任務(wù)中的整體效果如下,主要對(duì)比了UIE和各個(gè)數(shù)據(jù)集上各類SOTA模型的效果。可以看到在大部分?jǐn)?shù)據(jù)集上,UIE的效果都是最優(yōu)的。對(duì)比沒(méi)有經(jīng)過(guò)預(yù)訓(xùn)練的模型(SEL),UIE取得非常顯著的提升,通過(guò)將多任務(wù)使用統(tǒng)一框架聯(lián)合訓(xùn)練,實(shí)現(xiàn)了知識(shí)的共享和效果的互相促進(jìn)。
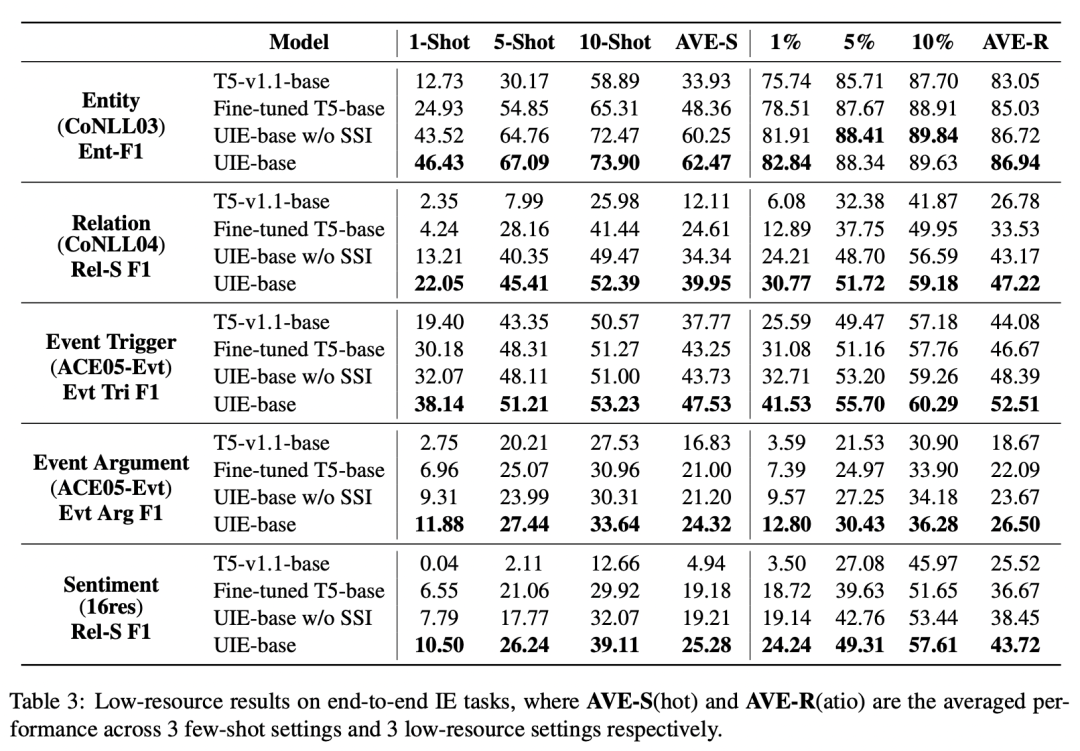
除了在正常的有監(jiān)督任務(wù)上效果外,本文也對(duì)小樣本場(chǎng)景的效果進(jìn)行了實(shí)驗(yàn),主要對(duì)比了使用T5模型finetune和使用UIE方法的效果,UIE在小樣本上的效果非常顯著。
5 開(kāi)源代碼
與此論文相應(yīng)的開(kāi)源代碼發(fā)布在百度PaddleNLP上https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7247瀏覽量
91279 -
模型
+關(guān)注
關(guān)注
1文章
3500瀏覽量
50098 -
NER
+關(guān)注
關(guān)注
0文章
7瀏覽量
6304
原文標(biāo)題:一個(gè)模型解決所有信息抽取任務(wù)!(含代碼)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
文本信息抽取的分階段詳細(xì)介紹
基于子樹(shù)廣度的Web信息抽取
基于重復(fù)模式的自動(dòng)Web信息抽取
基于XML的WEB信息抽取模型設(shè)計(jì)
基于WebHarvest的健康領(lǐng)域Web信息抽取方法
節(jié)點(diǎn)屬性的海量Web信息抽取方法
抽取式摘要方法中如何合理設(shè)置抽取單元?
了解信息抽取必須要知道關(guān)系抽取

開(kāi)放域信息抽取和文本知識(shí)結(jié)構(gòu)化的3篇論文詳細(xì)解析

面向知識(shí)圖譜的信息抽取

實(shí)體關(guān)系抽取模型CasRel
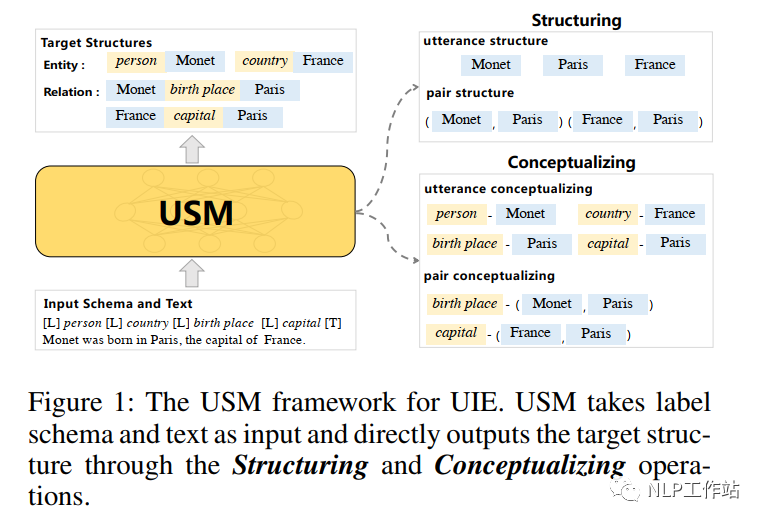
基于統(tǒng)一語(yǔ)義匹配的通用信息抽取框架USM
介紹一種信息抽取的大一統(tǒng)方法USM
基于統(tǒng)一語(yǔ)義匹配的通用信息抽取框架-USM
Instruct-UIE:信息抽取統(tǒng)一大模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論