") 使用Merlin分層參數(shù)服務(wù)器擴(kuò)展推薦系統(tǒng)推理
使用Merlin分層參數(shù)服務(wù)器擴(kuò)展推薦系統(tǒng)推理

如今,推薦系統(tǒng)被廣泛用于個性化用戶體驗(yàn),并在電子商務(wù)、社交媒體和新聞源等各種環(huán)境中提高客戶參與度。因此,以低延遲和高精度服務(wù)用戶請求對于維持用戶參與至關(guān)重要。
這包括在使用最新更新無縫刷新模型的同時執(zhí)行高速查找和計(jì)算,這對于模型大小超過 GPU 內(nèi)存的大規(guī)模推薦者來說尤其具有挑戰(zhàn)性。
NVIDIA Merlin HugeCTR ,一個開源框架,旨在優(yōu)化 NVIDIA GPU 上的大規(guī)模推薦,最近發(fā)布 分層參數(shù)服務(wù)器( HPS )體系結(jié)構(gòu) 以專門解決工業(yè)級推理系統(tǒng)的需求。實(shí)驗(yàn)表明,該方法能夠在流行的基準(zhǔn)數(shù)據(jù)集上以低延遲進(jìn)行可拓展部署。
大規(guī)模推薦推理的挑戰(zhàn)
大型嵌入表 :典型深度推薦模型的輸入可以是數(shù)字(例如用戶年齡或商品價格)或分類特征(例如用戶 ID 或商品 ID )。與數(shù)字特征不同,分類特征需要轉(zhuǎn)換為數(shù)字向量,以輸入多層感知器( MLP )層進(jìn)行密集計(jì)算。嵌入表學(xué)習(xí)從類別到數(shù)字特征空間的映射(“嵌入”),這有助于實(shí)現(xiàn)這一點(diǎn)。
因此,嵌入表是模型參數(shù)的一部分,并且可能是內(nèi)存密集型的,對于現(xiàn)代推薦系統(tǒng),可以達(dá)到 TB 級。這遠(yuǎn)遠(yuǎn)超出了現(xiàn)代 GPU 的板載存儲容量。因此,大多數(shù)現(xiàn)有的解決方案都退回到在 CPU 內(nèi)存中托管嵌入表,這沒有利用高帶寬 GPU 內(nèi)存,從而導(dǎo)致更高的端到端延遲。
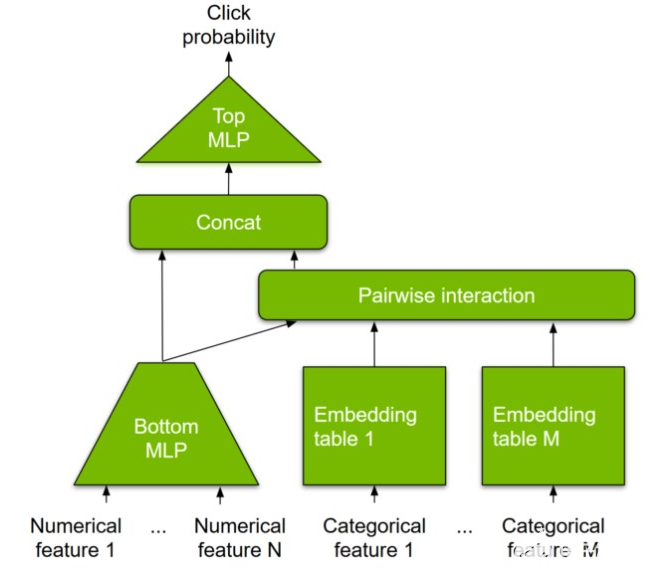
圖 1.典型深度學(xué)習(xí)推薦模型示例。顯示的架構(gòu)是 個性化和推薦系統(tǒng)的深度學(xué)習(xí)推薦模型 。
可擴(kuò)展性 :在用戶行為的驅(qū)動下,許多客戶應(yīng)用程序被構(gòu)建為服務(wù)于峰值使用,并且需要根據(jù)預(yù)期和實(shí)際負(fù)載擴(kuò)展或擴(kuò)展 AI 推理引擎的靈活性。
對不同框架和模型的高兼容性 :人工智能推理引擎必須能夠服務(wù)于兩種深度學(xué)習(xí)模型 ( 例如 DeepFM, DCN, DLRM, MMOE, DIN, 和 DIEN),由 TensorFlow 或 PyTorch 等框架以及簡單的機(jī)器學(xué)習(xí)( ML )模型訓(xùn)練。此外,客戶希望混合部署多個不同的模型架構(gòu)和單個模型的多個實(shí)例。模型還必須部署在從云到邊緣的各種硬件平臺上。
部署新模型和在線培訓(xùn)更新 :客戶希望能夠根據(jù)市場趨勢和新用戶數(shù)據(jù)頻繁更新其模型。模型更新應(yīng)無縫應(yīng)用于推理部署。
容錯和高可用性 :客戶需要保持相同級別的 SLA ,對于任務(wù)關(guān)鍵型應(yīng)用程序,最好是五個 9 或以上。
下一節(jié)提供了更多有關(guān) NVIDIA Merlin HugeCTR 如何使用 HPS 解決這些挑戰(zhàn)的詳細(xì)信息,以實(shí)現(xiàn)對建議的大規(guī)模推斷。
分層參數(shù)服務(wù)器概述
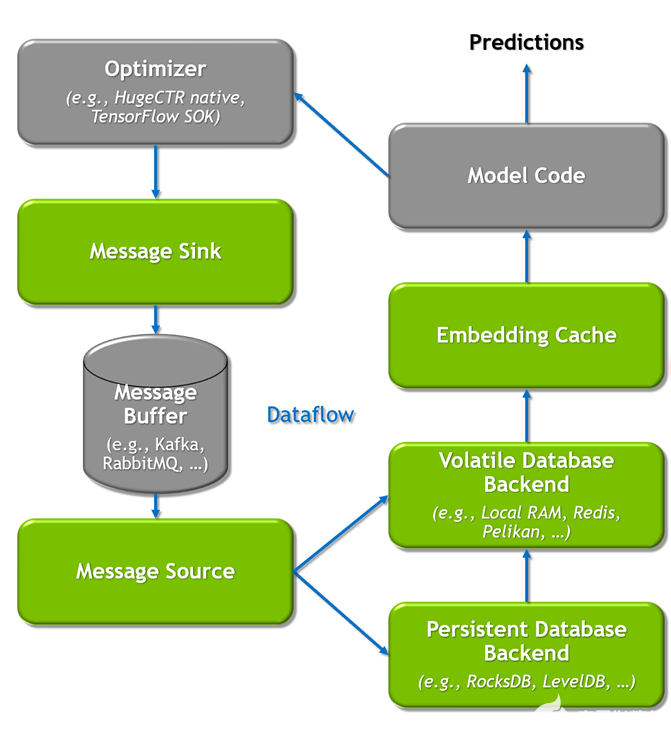
分層參數(shù)服務(wù)器支持使用多級自適應(yīng)存儲解決方案部署大型推薦推理工作負(fù)載。為了存儲大規(guī)模嵌入,它使用GPU 存儲器作為第一級高速緩存,CPU 存儲器作為二級緩存(如用于本地部署的 HashMap 和用于分布式的 Redis ),以及用于擴(kuò)展存儲容量(如 RocksDB )的 SSD 。
CPU 內(nèi)存和 SSD 均可根據(jù)用戶需求靈活配置。請注意,與嵌入相比,致密層( MLP )的尺寸要小得多。因此,密集層以數(shù)據(jù)并行的方式在各種 GPU 工作者之間復(fù)制。
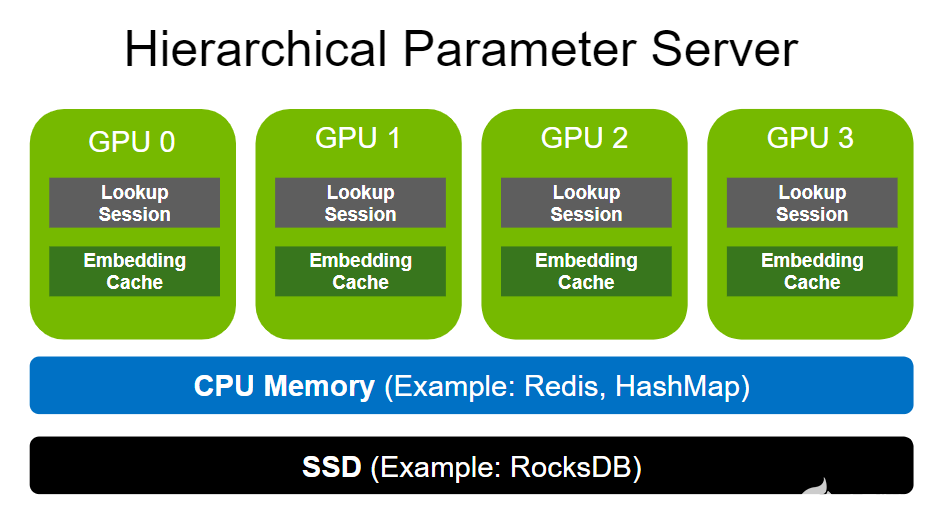
圖 2. NVIDIA Merlin HugeCTR 分層參數(shù)服務(wù)器架構(gòu)
GPU 嵌入緩存
GPU 的內(nèi)存帶寬比大多數(shù) CPU 的內(nèi)存寬度高一個數(shù)量級。例如, NVIDIA A100-80 GB 提供超過 2 TB / s 的 HBM2 帶寬。 GPU 嵌入緩存通過將內(nèi)存密集型嵌入查找移動到 GPU 中,更接近計(jì)算發(fā)生的位置,從而利用了如此高的內(nèi)存帶寬。
為了設(shè)計(jì)一個有效利用現(xiàn)代 GPU 提供的優(yōu)勢的系統(tǒng),重要的是要注意一個關(guān)鍵觀察:在現(xiàn)實(shí)世界的推薦數(shù)據(jù)集中,一些特征類別通常比其他特征類別出現(xiàn)得更頻繁。例如 標(biāo)準(zhǔn) 1 TB 點(diǎn)擊日志數(shù)據(jù)集 ,也是一個流行的基準(zhǔn)數(shù)據(jù)集 用于 MLPerf 總共 188 米中的 305K 個類別(僅占 0.16% )被 95.9% 的樣本引用。
這意味著某些嵌入的訪問頻率遠(yuǎn)遠(yuǎn)高于其他嵌入。嵌入鍵訪問大致遵循冪律分布。因此,在 GPU 內(nèi)存中緩存這些最頻繁訪問的參數(shù)將使推薦系統(tǒng)能夠利用高 GPU 內(nèi)存帶寬。單個嵌入查找是獨(dú)立的,這使得 GPU 成為向量查找處理的理想平臺,因?yàn)樗鼈兡軌蛲瑫r運(yùn)行數(shù)千個線程。
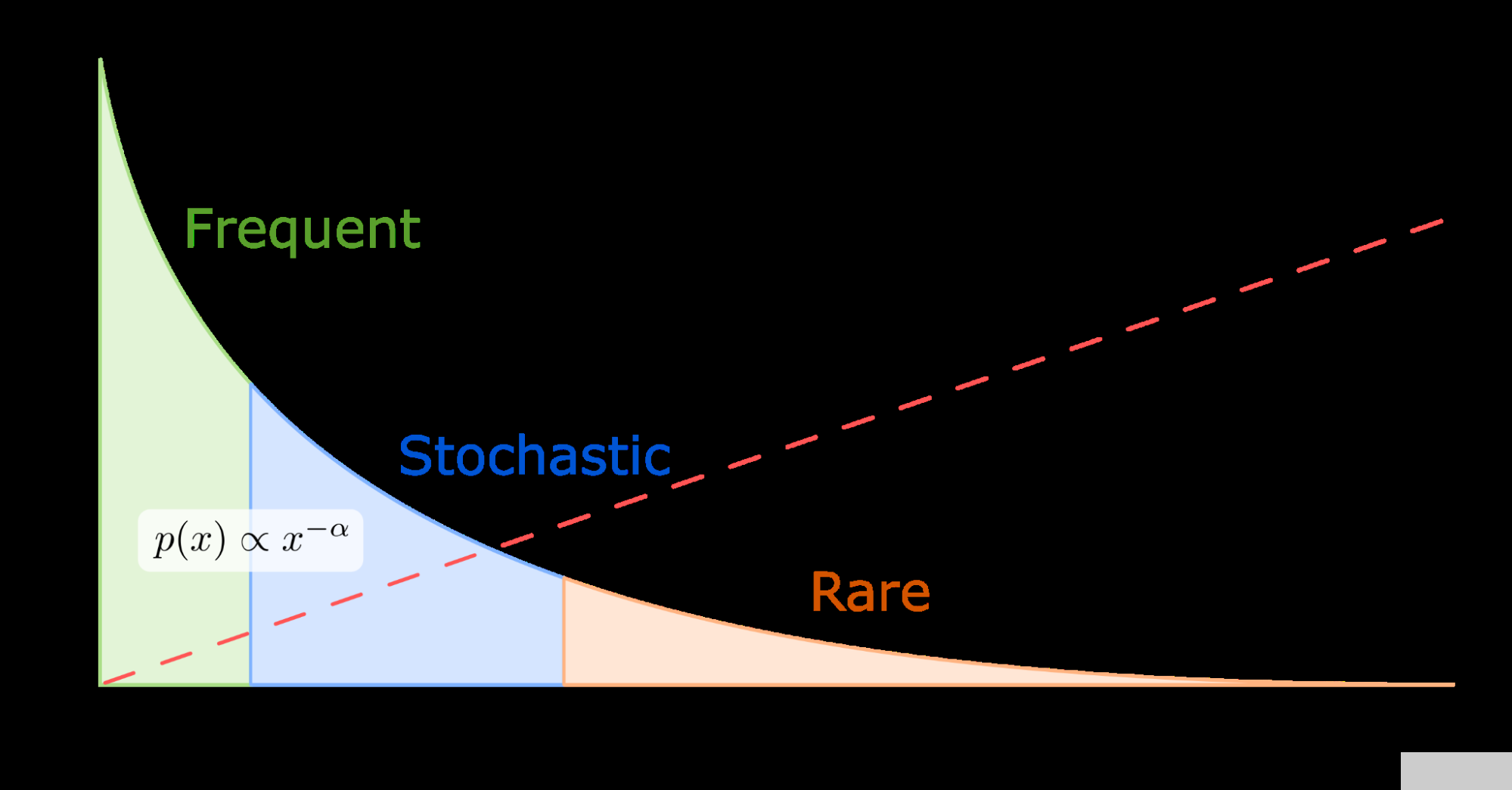
圖 3.冪律分布的可視化
這些特性激發(fā)了 HPS GPU 嵌入緩存的設(shè)計(jì),該緩存將熱嵌入保留在[Z1K11]內(nèi)存中,通過減少額外的或重復(fù)的參數(shù)在較慢的 CPU- GPU 總線上的移動來提高查找性能。它由保留所有嵌入表的完整副本的輔助存儲器支持。下文將對此進(jìn)行更全面的探討。對于與 GPU 上托管的每個模型相關(guān)聯(lián)的每個嵌入表,存在唯一的 GPU 嵌入緩存。
嵌入鍵插入機(jī)制
當(dāng)在推理過程中 GPU 緩存中缺少查找到的嵌入鍵時,將觸發(fā)鍵插入以從層次結(jié)構(gòu)的較低級別獲取相關(guān)數(shù)據(jù)。 HPS 實(shí)現(xiàn)了同步和異步鍵插入機(jī)制,以及用戶定義的[VZX1 8],以在兩個選項(xiàng)之間進(jìn)行選擇,以平衡準(zhǔn)確性和延遲。
Synchronous insertion: 如果實(shí)際命中率低于命中率閾值,則在等待將丟失的鍵插入 GPU 緩存時,會阻止推理請求。這通常發(fā)生在模型剛加載時、預(yù)熱期間或進(jìn)行重要模型更新后。
Asynchronous insertion: 如果實(shí)際命中率高于命中率閾值,則立即返回預(yù)配置的默認(rèn)向量,以允許查詢管道繼續(xù)執(zhí)行,而不會延遲。“惰性”插入本身發(fā)生在后臺。當(dāng)已達(dá)到所需精度且主要關(guān)注點(diǎn)是保持低延遲時,使用該方法。在實(shí)際的行業(yè)場景中,即使緩存了完整模型,推理也可能仍然缺少功能,因?yàn)樵谕评碇锌赡軙霈F(xiàn)從未出現(xiàn)在訓(xùn)練數(shù)據(jù)集中的新項(xiàng)目和用戶。
GPU 嵌入緩存性能
圖 4 顯示了使用 標(biāo)準(zhǔn) 1 TB 點(diǎn)擊日志數(shù)據(jù)集 和 90GB 個性化和推薦系統(tǒng)的深度學(xué)習(xí)推薦模型 NVIDIA T4 ( 16 GB 內(nèi)存)、 A30 ( 24 GB 內(nèi)存)和 A100 GPU ( 80 GB 內(nèi)存)上的( DLRM )型號,緩存了型號大小的 10% 。命中率閾值設(shè)置為 1.0 ,以便所有鍵插入都是同步的。在穩(wěn)定階段進(jìn)行測量。
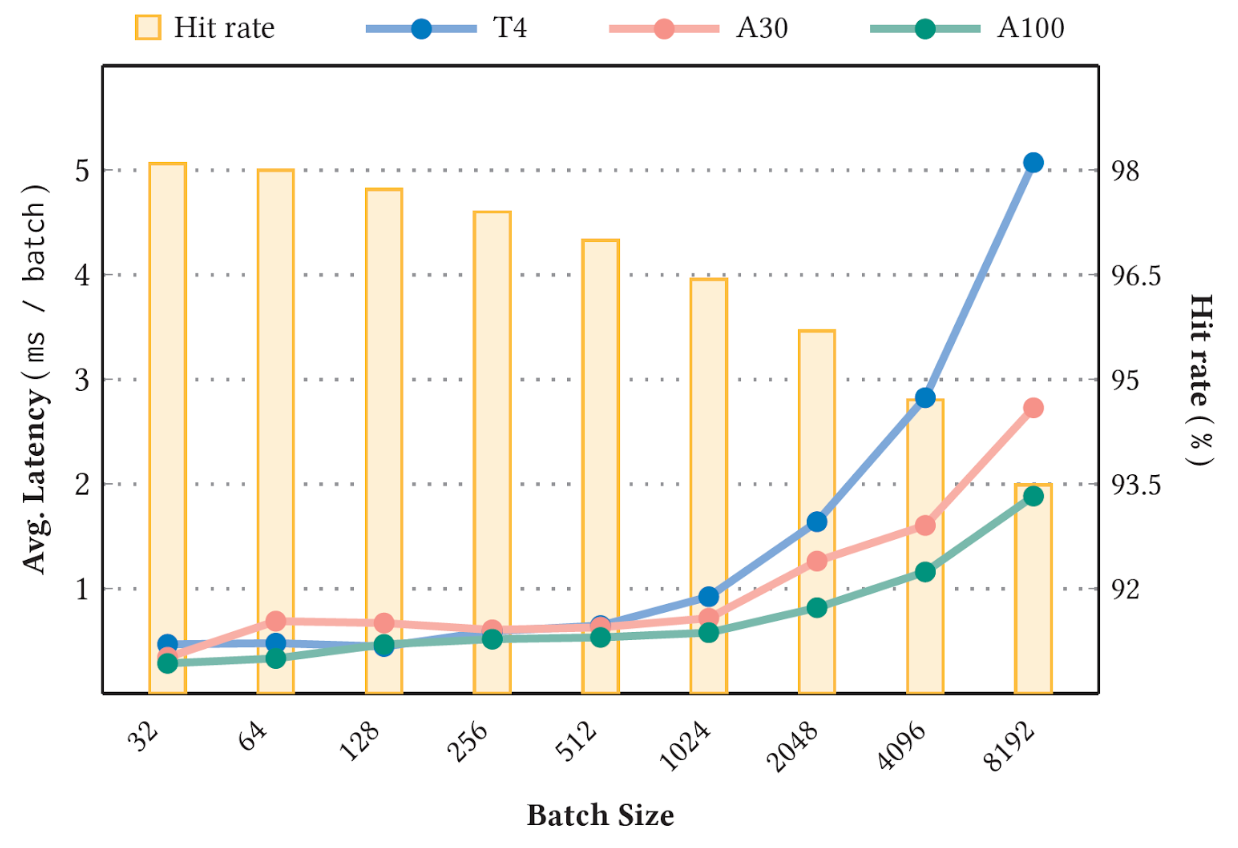
圖 4.不同批量大小的平均延遲和 GPU 嵌入緩存命中率
可以預(yù)期,較高的穩(wěn)定緩存命中率(圖 4 中的條形圖)對應(yīng)于較低的平均延遲(圖 4 的折線圖)。此外,由于鍵丟失的可能性越來越大,更大的批大小也會導(dǎo)致命中率降低和延遲增加。有關(guān)基準(zhǔn)的更多詳細(xì)信息,請參閱 用于大規(guī)模深度推薦模型的 GPU 專用推理參數(shù)服務(wù)器 。
HPS 包括兩個額外的層,通過利用CPU 存儲器和 SSD 。這些層高度可配置,以支持各種后端實(shí)現(xiàn)。以下各節(jié)將更詳細(xì)地介紹這些。
CPU 緩存
第二級存儲是 CPU 緩存,通過 CPU- GPU 總線訪問,并以較低的成本作為[Z1K11]嵌入緩存的擴(kuò)展存儲。如果 GPU 嵌入緩存中缺少嵌入鍵, HPS 接下來將查詢 CPU 緩存。
如果找到鍵(緩存命中),則返回結(jié)果并記錄訪問時間。這些最后訪問的時間戳用于以后的鍵逐出。
如果鍵丟失, HPS 將轉(zhuǎn)到下一層獲取嵌入,同時還調(diào)度將丟失的嵌入向量插入 CPU 緩存。
“ CPU 緩存”層支持各種數(shù)據(jù)庫后端。 HugeCTR HPS 提供 易失性數(shù)據(jù)庫示例 具有基于哈希映射的本地 CPU 內(nèi)存數(shù)據(jù)庫實(shí)現(xiàn),以及 Redis 集群 – 基于后端,利用分布式集群實(shí)例進(jìn)行可擴(kuò)展部署。
固態(tài)硬盤
緩存層次結(jié)構(gòu)的最低層以更低的成本在 SSD 、硬盤或網(wǎng)絡(luò)存儲卷上存儲每個嵌入表的完整副本。對于表現(xiàn)出極端長尾分布的數(shù)據(jù)集(大量類別,其中許多類別不經(jīng)常被引用),保持高精度對于手頭的任務(wù)至關(guān)重要,這一點(diǎn)尤其有效。這個 HugeCTR HPS 參考配置 將嵌入表映射到 RocksDB 本地 SSD 上的數(shù)據(jù)庫。
整個模型通過設(shè)計(jì)保存在每個推理節(jié)點(diǎn)中。這種資源隔離策略增強(qiáng)了系統(tǒng)可用性。即使在災(zāi)難性事件后只有一個節(jié)點(diǎn)是活動的,也可以恢復(fù)模型參數(shù)和推理服務(wù)。
增量訓(xùn)練更新
推薦模型有兩種培訓(xùn)模式:離線和在線。在線培訓(xùn)將新的模型更新部署到實(shí)時生產(chǎn)中,對于推薦的有效性至關(guān)重要。 HPS 雇傭 無縫更新機(jī)制 通過 Apache Kafka – 基于消息緩沖區(qū)連接訓(xùn)練和推理節(jié)點(diǎn),如圖 5 所示。
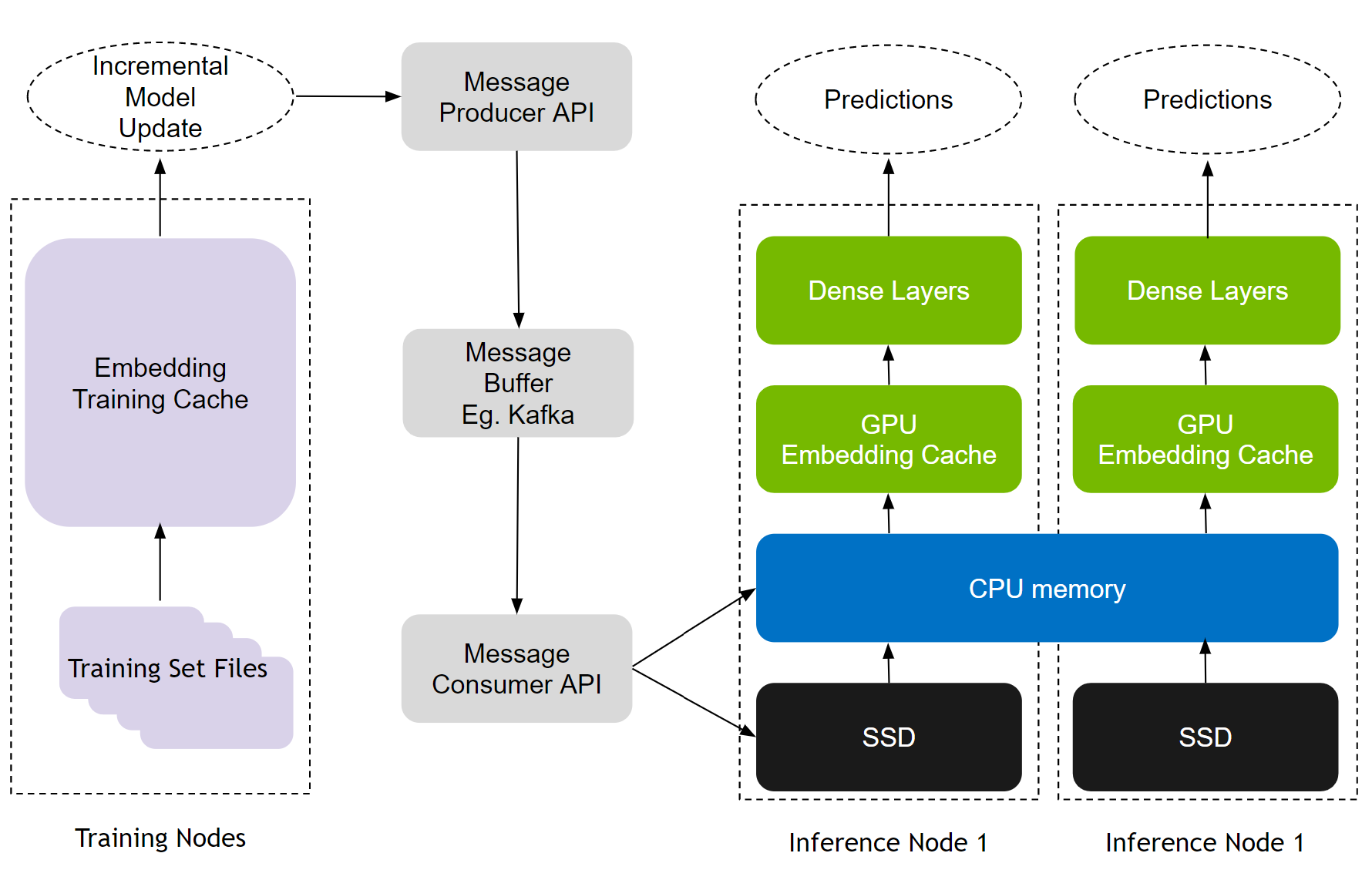
圖 5. HugeCTR 推理在線更新機(jī)制
更新機(jī)制有助于 MLOps 工作流,支持在線/頻繁以及離線/再培訓(xùn)更新,無需停機(jī)。它還通過設(shè)計(jì)賦予了容錯能力,因?yàn)榧词雇评矸?wù)器關(guān)閉,訓(xùn)練更新也會繼續(xù)在 Kafka 消息緩沖區(qū)中排隊(duì)。通過方便易用的 Python API ,開發(fā)人員可以使用所有這些功能。
HPS 性能基準(zhǔn)
為了證明 HugeCTR HPS 的優(yōu)勢,我們評估了其在 DLRM 模型上的端到端推理性能,并 標(biāo)準(zhǔn) 1 TB 點(diǎn)擊日志數(shù)據(jù)集 ,并將其與僅在 GPU 上運(yùn)行密集層計(jì)算和僅 CPU 解決方案的場景進(jìn)行了比較。
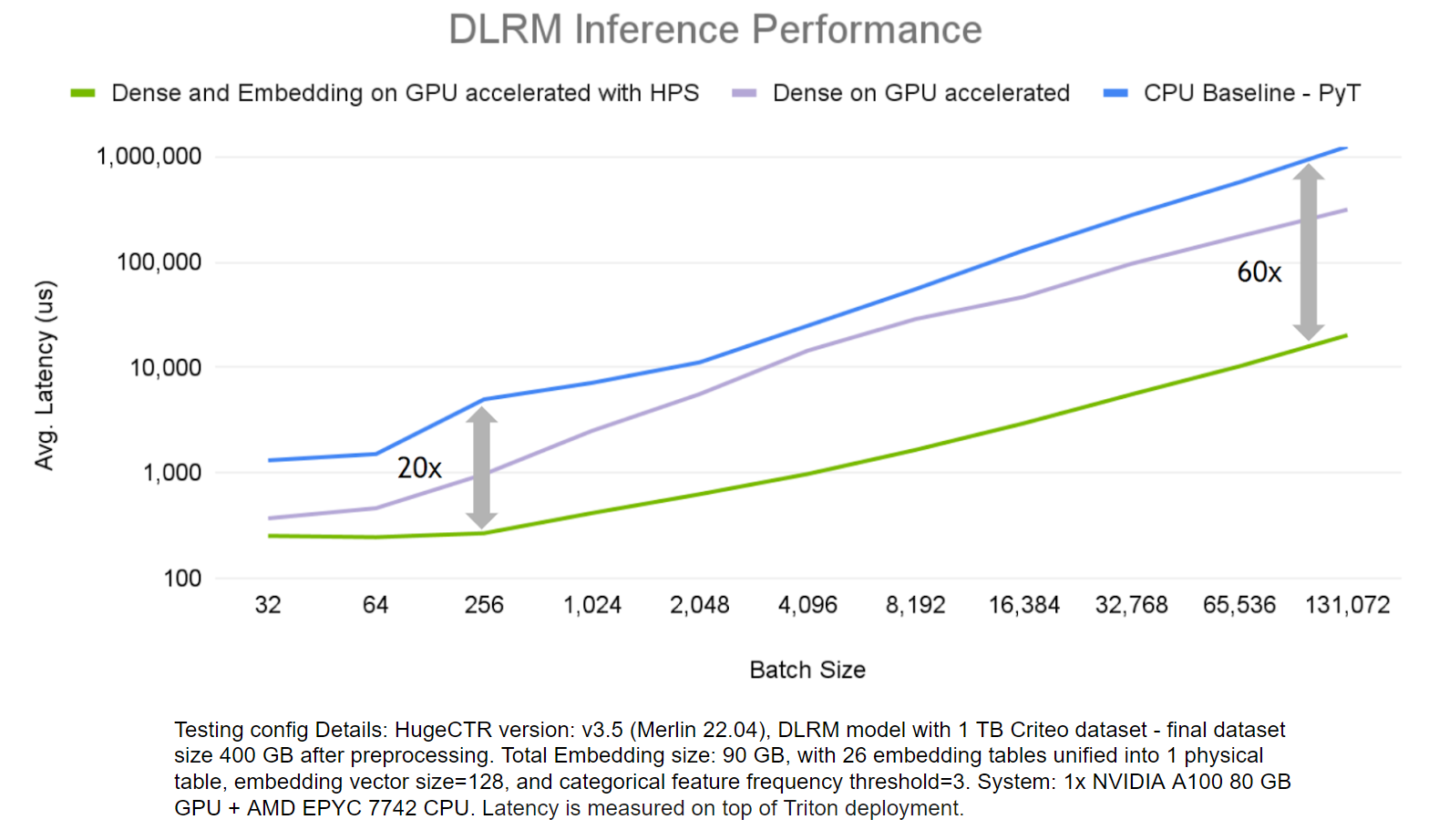
圖 6.推理性能比較
HPS 解決方案加快了嵌入和密集層的速度,遠(yuǎn)遠(yuǎn)優(yōu)于僅使用 CPU 的解決方案,在更大批量的情況下,其速度高達(dá) 60 倍。
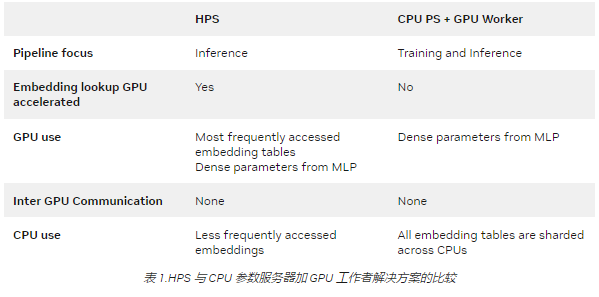
HPS 與 CPU PS 加 GPU 工作解決方案的區(qū)別
您可能熟悉 CPU 參數(shù)服務(wù)器( PS )和 GPU 工作解決方案。表 1 顯示了 HPS 與大多數(shù) PS plus worker 解決方案的不同之處。
總結(jié)
本文介紹了 Merlin HugeCTR HPS ,其中 GPU 嵌入緩存作為一種工具,用于加速 NVIDIA GPU 上大規(guī)模嵌入的推理。 HPS 方便易用 配置 ,包括 例子 讓你開始。還將有一個 TensorFlow 插件 這使得能夠在現(xiàn)有 TF 推理管道中使用 HPS 。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5284瀏覽量
106144 -
gpu
+關(guān)注
關(guān)注
28文章
4930瀏覽量
131019 -
服務(wù)器
+關(guān)注
關(guān)注
13文章
9765瀏覽量
87694
發(fā)布評論請先 登錄
服務(wù)器特點(diǎn)
什么是服務(wù)器
云服務(wù)器與物理服務(wù)器的區(qū)別是什么?
服務(wù)器配置參數(shù)主要有哪些
基于SNMP Agent擴(kuò)展的服務(wù)器監(jiān)
Merlin HugeCTR分級參數(shù)服務(wù)器:緩存和在線更新設(shè)計(jì)
Merlin HugeCTR 分級參數(shù)服務(wù)器簡介
使用MIG和Kubernetes部署Triton推理服務(wù)器
NVIDIA Triton推理服務(wù)器的功能與架構(gòu)簡介
AI服務(wù)器與傳統(tǒng)服務(wù)器的區(qū)別是什么?
如何使用NVIDIA Triton 推理服務(wù)器來運(yùn)行推理管道
使用NVIDIA Triton推理服務(wù)器來加速AI預(yù)測
國產(chǎn)推理服務(wù)器如何選擇?深度解析選型指南與華頡科技實(shí)戰(zhàn)案例

AI 推理服務(wù)器都有什么?2025年服務(wù)器品牌排行TOP10與選購技巧






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論