") 面向社交媒體的多模態(tài)屬性級情感分析
面向社交媒體的多模態(tài)屬性級情感分析
導(dǎo)讀:隨著社交網(wǎng)絡(luò)的飛速發(fā)展,人們在以微博、Twitter為代表的社交平臺上發(fā)表的內(nèi)容逐漸趨于多模態(tài)化,比如用戶常以圖文并茂的方式來表達(dá)自己的態(tài)度和情感。因此,如何結(jié)合社交媒體上的圖片、視頻等富文本信息來分析用戶的情感傾向給傳統(tǒng)的單模態(tài)文本情感分析帶來了新的挑戰(zhàn)。
一方面,不同于傳統(tǒng)的文本情感分析,多模態(tài)情感分析需要利用不同網(wǎng)絡(luò)結(jié)構(gòu)對多種模態(tài)內(nèi)容進(jìn)行基于情感的表示學(xué)習(xí)。另一方面,相比于單一的文本數(shù)據(jù),多模態(tài)數(shù)據(jù)包含了多種不同信息,這些信息之間往往一一對應(yīng)、互為補(bǔ)充,如何對齊不同模態(tài)的內(nèi)容并提出有效的多模態(tài)融合機(jī)制是一個(gè)十分棘手的問題。
01 社交媒體分析的背景與發(fā)展趨勢
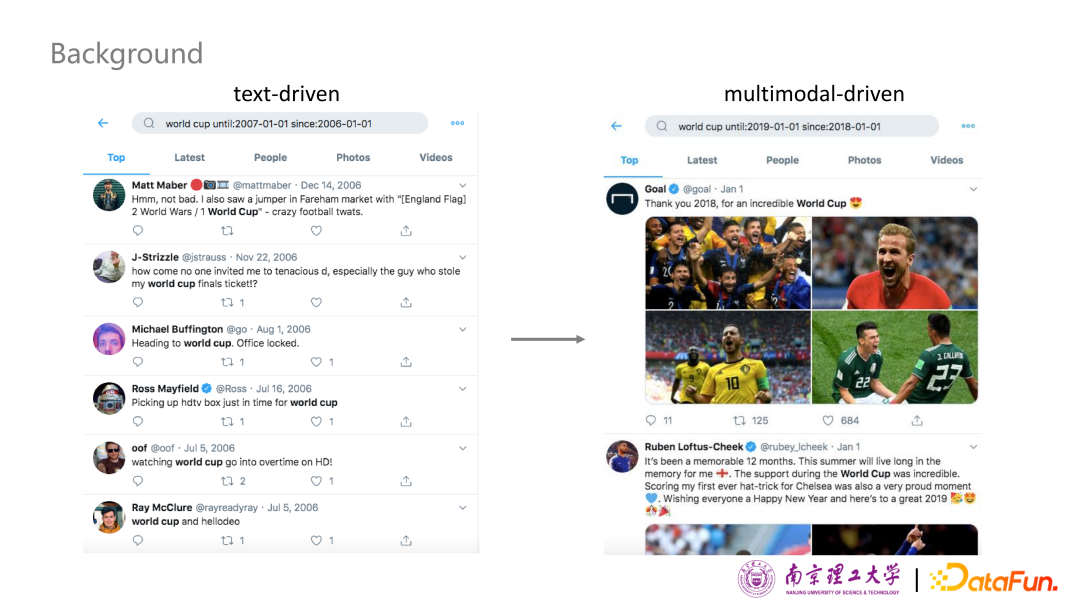
將近10年前,社交媒體才剛剛興起,社交媒體上的用戶內(nèi)容都是以純文本為主。就以我們在Twitter上搜索 world cup 這個(gè)關(guān)鍵詞為例,并把時(shí)間定在2006 年到 2007 年之間,檢索出來的內(nèi)容幾乎都是以文本內(nèi)容為主。但是把時(shí)間定在 2018 年到 2019 年之間,檢索出來的用戶發(fā)帖大多都是以圖文并茂的方式呈現(xiàn)出來。
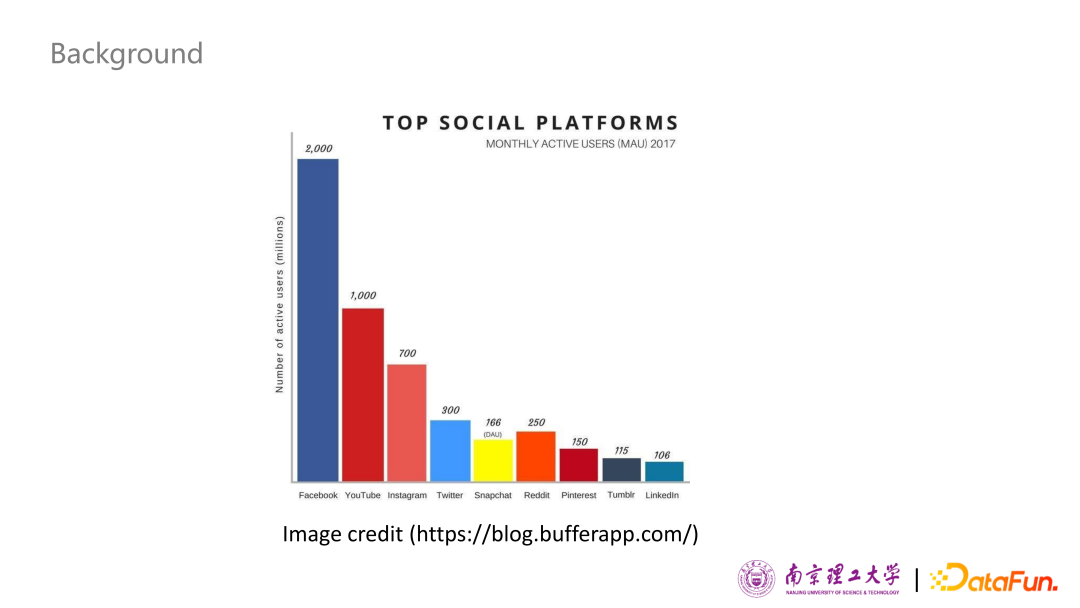
在2017年,對北美比較流行的社交媒體網(wǎng)站的月活躍用戶數(shù)量進(jìn)行了統(tǒng)計(jì),圖中橫坐標(biāo)是各大社交媒體網(wǎng)站,縱坐標(biāo)是月活躍用戶數(shù)量,單位是百萬。我們可以看到前五位中有三個(gè)社交媒體網(wǎng)站(YouTube、Instagram、Snapchat)是圖像或視頻內(nèi)容為主、文本內(nèi)容為輔的多模態(tài)形式。而其中以純文本的內(nèi)容為主的傳統(tǒng)社交媒體Facebook 和Twitter 也慢慢轉(zhuǎn)變到了多模態(tài)形式上來。
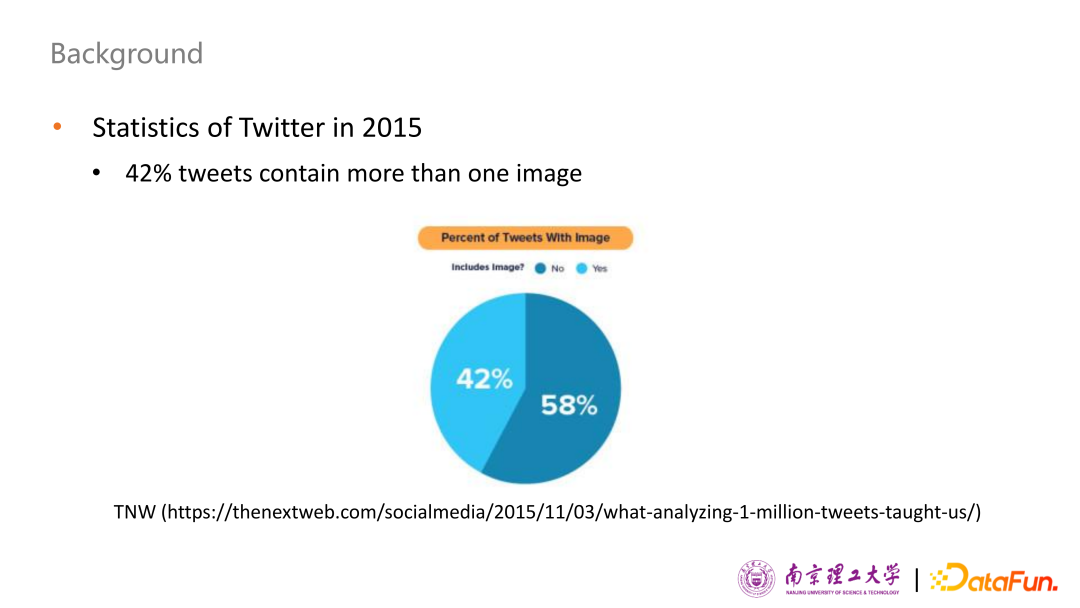
一個(gè)研究團(tuán)隊(duì)對2015年的Twitter 用戶推文進(jìn)行了統(tǒng)計(jì)分析,發(fā)現(xiàn)約 42% 的用戶推文包含至少一張圖片。因此在日趨快速發(fā)展的網(wǎng)絡(luò)時(shí)代,人們更加傾向于利用圖文結(jié)合或視頻的形式表達(dá)自己的觀點(diǎn)和情緒,社交媒體內(nèi)容的多模態(tài)性(文本、圖片等)讓傳統(tǒng)的單模態(tài)情感分析方法面臨許多局限,多模態(tài)情感分析技術(shù)對跨模態(tài)內(nèi)容的理解與分析具有重大的理論價(jià)值。
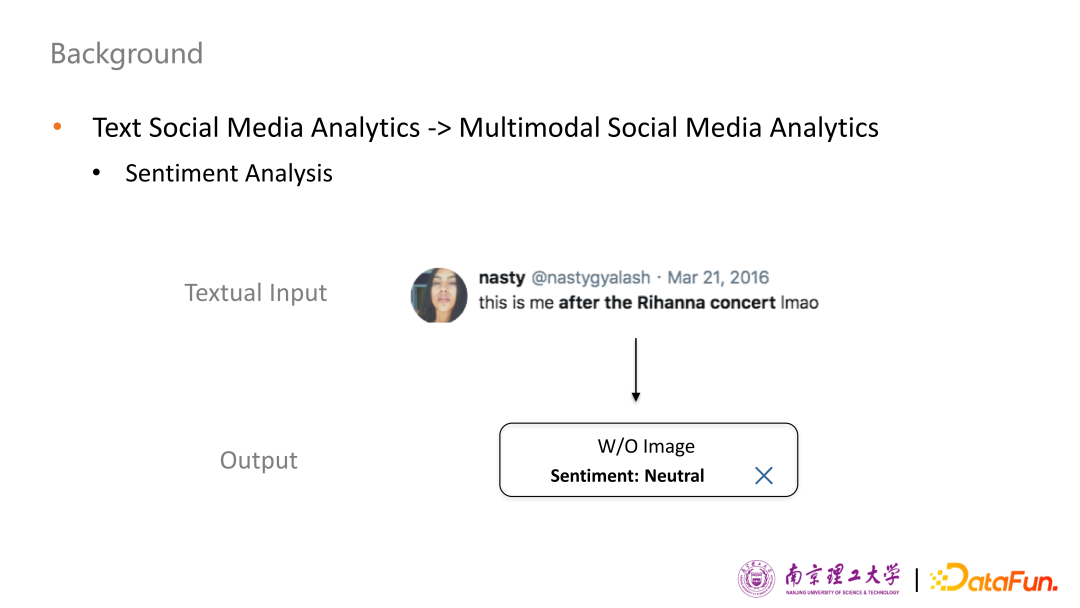
情感分析是自然語言處理的一項(xiàng)核心任務(wù),旨在識別對觀點(diǎn)、情感和評價(jià)的情感極性。由于社交媒體信息具有多樣性,為了提高針對社交媒體的情感分析的準(zhǔn)確性,綜合考慮文本和圖像信息進(jìn)行多模態(tài)情感分析具有重要意義,接下來看幾個(gè)不同的多模態(tài)情感分析子任務(wù)。
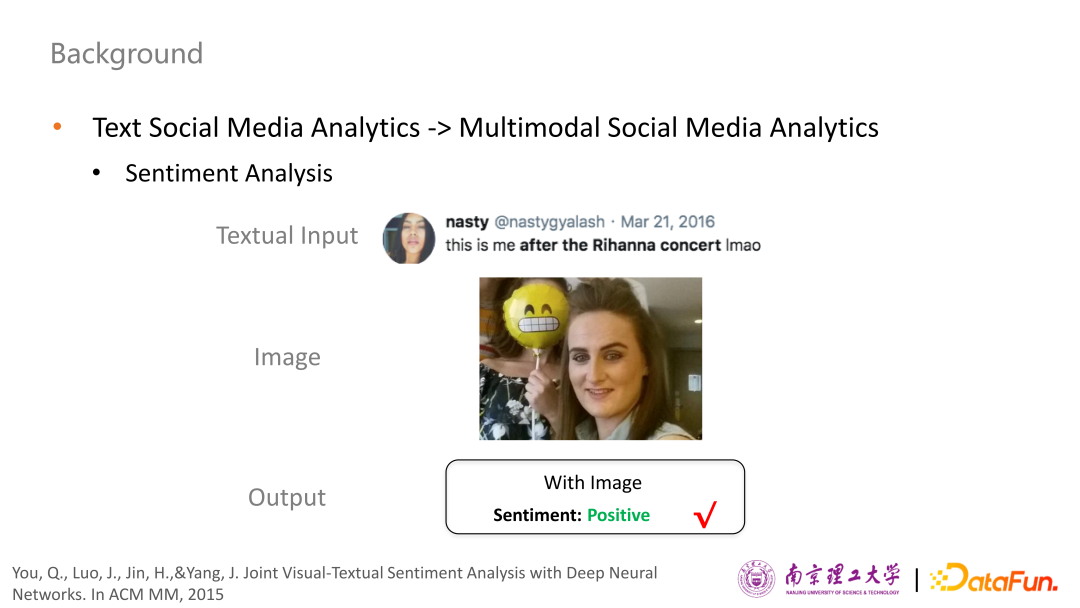
首先來看第一個(gè)子任務(wù),判斷用戶所表達(dá)情感傾向是正向、負(fù)向還是中立。如果只考慮純文本內(nèi)容“this is me after the Rihanna concert”,很難判斷用戶的真實(shí)情感。對于機(jī)器而言,大概率判斷用戶情感是中立。但是加入圖片中的笑臉信息,我們可以輕松地判斷用戶表達(dá)了比較正面的情感。
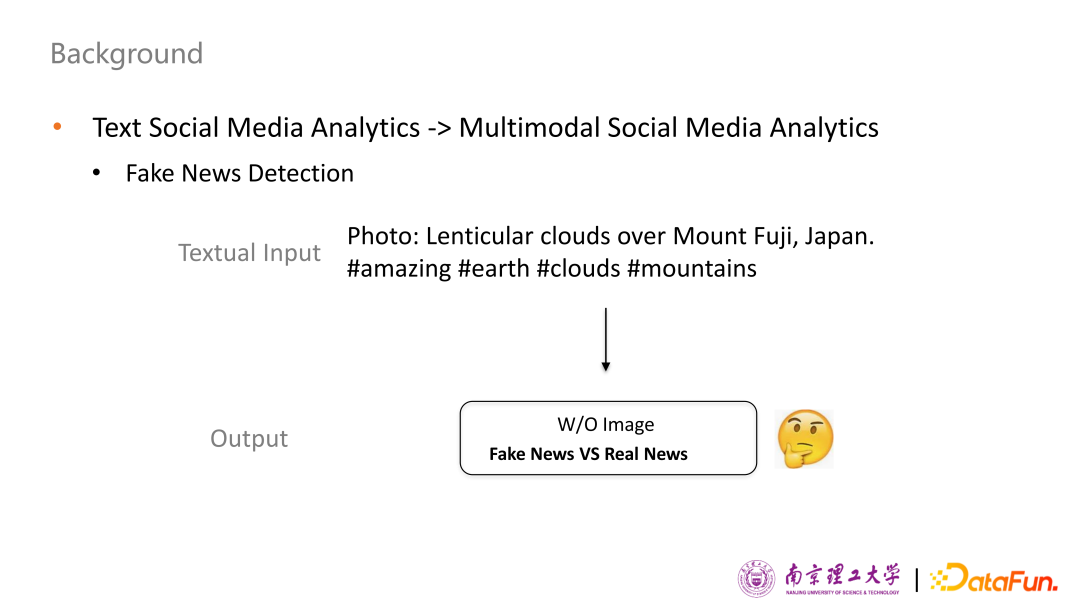
第二個(gè)任務(wù)是虛假新聞檢測。如果只看純文本內(nèi)容,意思是日本的富士山上有多層云,我們無法判斷用戶推文的真?zhèn)涡浴5?dāng)我們把圖片信息加入,可以明顯看出圖片中的云是經(jīng)過人為 PS 過的,從而輕松地判斷出用戶發(fā)帖內(nèi)容是虛假的。

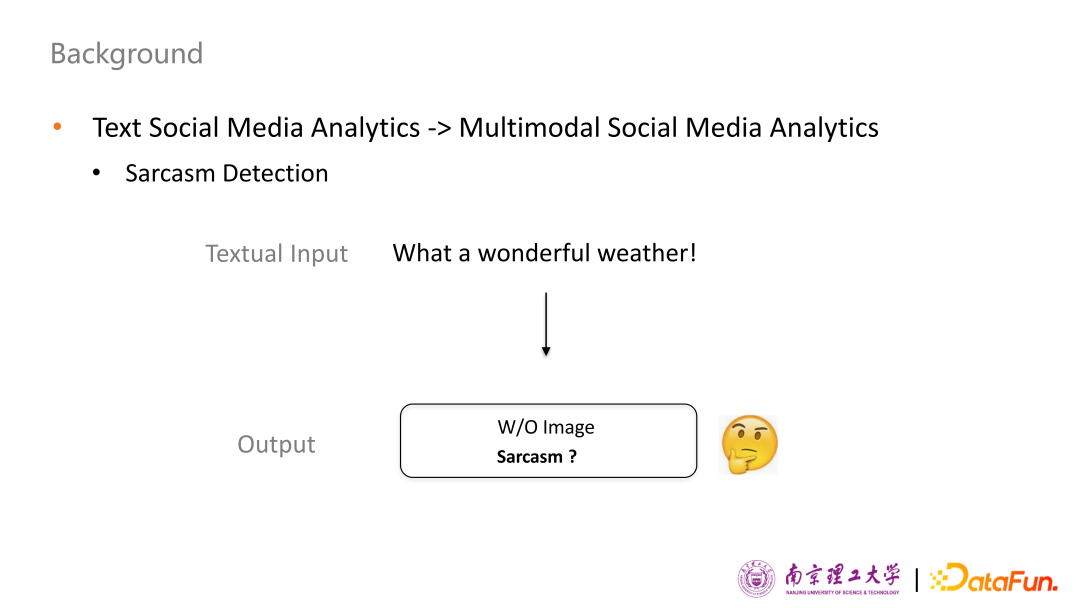
最后一個(gè)子任務(wù)叫做反諷識別,也稱為諷刺檢測。同樣地,只以純文本內(nèi)容“what wonderful weather!”看,無法判斷出用戶對天氣是否存在反諷的意思。但引入下雨的圖片之后,文本內(nèi)容和圖片內(nèi)容形成了鮮明的對比,因此用戶其實(shí)在諷刺天氣非常糟糕。

綜上所述,社交媒體的不同多模態(tài)信息能夠提供非常重要的線索,還會對提升子任務(wù)識別檢測性能起到關(guān)鍵性的作用。因此與單模態(tài)相比,通過對社交媒體的數(shù)據(jù)進(jìn)行多模態(tài)分析,有效地利用視覺信息和文本信息之間的關(guān)系及影響,不僅有利于學(xué)者準(zhǔn)確地了解人們在現(xiàn)實(shí)世界中的生活態(tài)度與生活習(xí)慣,更能把握人們在醫(yī)療保健、政治話題、電視電影及線上購物等領(lǐng)域的選擇。
02
多模態(tài)屬性級情感分析任務(wù)劃分與定義
針對上述背景,本節(jié)聚焦于多模態(tài)屬性級情感分析任務(wù),該任務(wù)主要包含三個(gè)子任務(wù):多模態(tài)屬性抽取/多模態(tài)命名實(shí)體識別、多模態(tài)屬性情感分類任務(wù)、多模態(tài)屬性情感聯(lián)合抽取。
多模態(tài)屬性抽取(MATE):給定一段多模態(tài)產(chǎn)品評論或者用戶推文,抽取文本中提到的屬性詞。
多模態(tài)命名實(shí)體識別(MNER):進(jìn)一步判斷出抽取屬性詞的類別,利用圖像來提高推文命名實(shí)體識別的準(zhǔn)確性,類別是提前預(yù)定義的,如人名、地名等。
多模態(tài)屬性情感分類任務(wù)(MASC):對每一個(gè)抽取的屬性詞進(jìn)行情感分類。
多模態(tài)屬性情感聯(lián)合抽取(JMASA):旨在同時(shí)抽取屬性詞極其相對應(yīng)的情感詞(成對抽取),識別出所有的屬性-情感詞對。
多模態(tài)屬性抽取這個(gè)子任務(wù)的目標(biāo)是從多模態(tài)輸入中抽取屬性詞。例如推文“The Yangtze is so amazing! ”加上一張配圖,抽取出推文中的屬性詞是Yangtze。

接下來需進(jìn)一步判斷出屬性詞的類別是什么,比如人名類型、地名類型、機(jī)構(gòu)名類型等,同樣以長江這個(gè)例子來看,判斷出Yangtze是一個(gè)地名類型的實(shí)體。

MASC子任務(wù)是對每一個(gè)抽取的屬性詞進(jìn)行情感分類,以長江這個(gè)例子來判斷用戶表達(dá)的情感,單從文本內(nèi)容“The Yangtze is so amazing!”,大概率會覺得用戶表達(dá)了正面的情感,但是從配圖中很多垃圾可以看出,用戶其實(shí)在反諷長江的環(huán)境污染問題比較嚴(yán)重,對長江表達(dá)的是負(fù)面情感,也可以看出圖像信息對于情感識別任務(wù)的重要性。

最后一個(gè)子任務(wù)是多模態(tài)屬性情感聯(lián)合抽取,旨在同時(shí)抽取多模態(tài)輸入中的屬性詞和其所對應(yīng)的情感。還是以長江這個(gè)例子來看,抽取結(jié)果是:[Yangtze, Negative]。

03
相關(guān)研究工作
接下來這部分主要介紹,近幾年在多模態(tài)屬性情感分析任務(wù)的代表性研究工作。
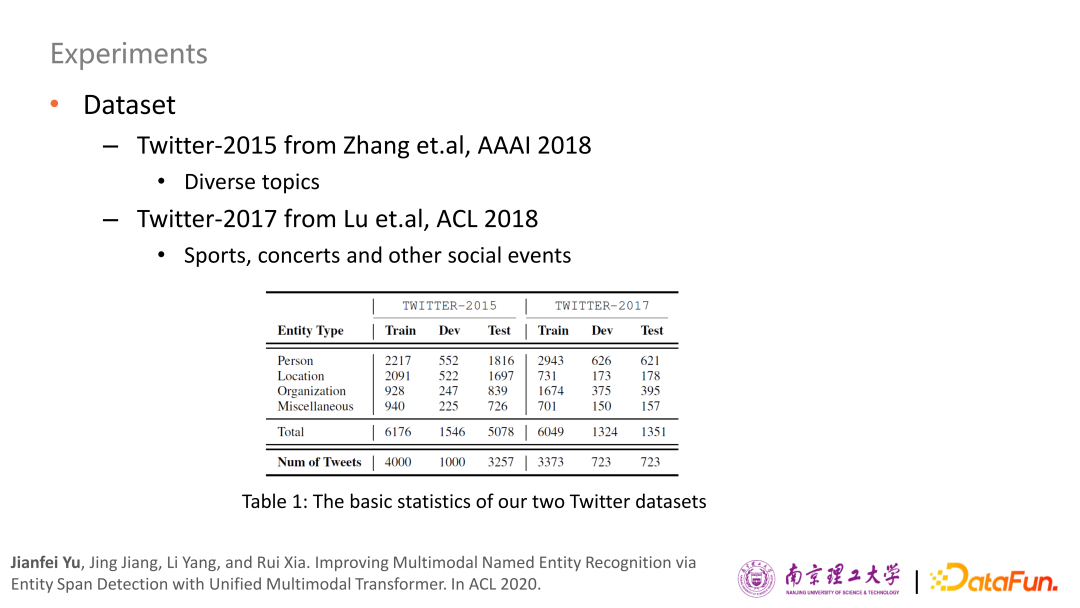
首先是社交媒體帖子的多模態(tài)命名實(shí)體識別(MNER),在 ACL 2020 上提出了一個(gè) Unified Multimodal Transformer 的模型。
具體論文參考: Jianfei Yu, Jing Jiang, Li Yang, and Rui Xia. Improving Multimodal Named Entity Recognition via Entity Span Detection with Unified Multimodal Transformer. In ACL 2020.
為什么提出這個(gè)模型?我們可以看一個(gè)例子,給定多模態(tài)用戶推文“Kevin Durant enters Oracle Arena wearing off- White x Jordan”和配圖,識別出Kevin Durant是一個(gè)人名類型的實(shí)體,Oracle Arena是一個(gè)地名類型的實(shí)體,Jordan是一個(gè)雜類類型的實(shí)體。
實(shí)際上,在大多數(shù)社交媒體帖子中,相關(guān)圖像往往只突出句子中的一兩個(gè)實(shí)體,而沒有提到其他實(shí)體。Kevin Durant可以從這個(gè)圖片當(dāng)中判斷出是一個(gè)人名,但是Oracle Arena 在這個(gè)圖片中沒有得到任何體現(xiàn),如果過分強(qiáng)調(diào)這個(gè)圖片信息,會導(dǎo)致給圖片當(dāng)中沒有出現(xiàn)的那部分實(shí)體帶來一定的噪音,可能會導(dǎo)致實(shí)識別性能變差。這就是提出Unified Multimodal Transformer模型的一個(gè)重要動機(jī)。

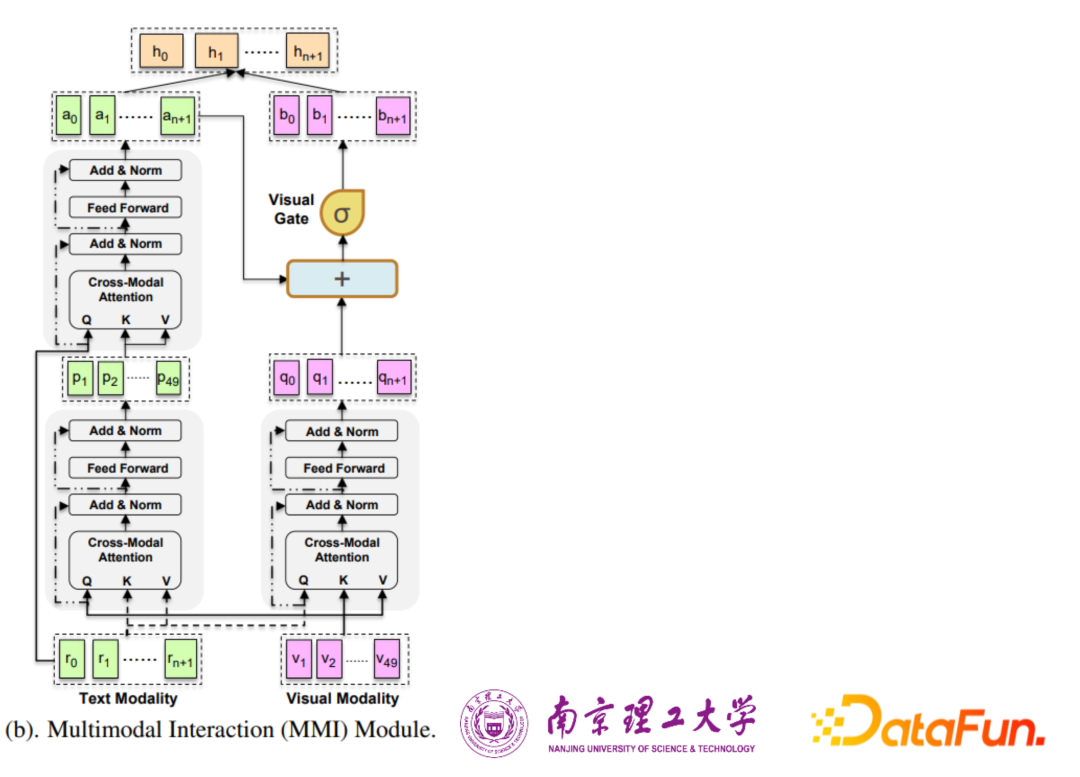
圖a是提出Unified Multimodal Transformer模型的總覽的框架圖,UMT的總體架構(gòu)包含三個(gè)主要組件:
(1)單模態(tài)輸入的表示學(xué)習(xí)
(2)用于MNER的多模態(tài) Transformer
(3)具有輔助實(shí)體跨度檢測(ESD)模塊的統(tǒng)一結(jié)構(gòu)
單模態(tài)輸入的表示學(xué)習(xí)包含文本輸入和圖像輸入。左下角表示文本輸入,選取BERT作為句子編碼器,每個(gè)輸入句子插入兩個(gè)特殊標(biāo)記,[CLS]在開始,[SEP]在結(jié)尾。右下角表示圖像輸入端,選取CNN圖像識別模型之一的ResNet作為圖像編碼器,提取輸入圖像在其深層中有意義的特征表示。
右上方是用于MNER的多模態(tài) Transformer,首先BERT編碼器得到的C上添加一個(gè)標(biāo)準(zhǔn)Transformer層,以獲得每個(gè)詞的文本隱藏表示R= (r0,r1,...,rn+1),為捕獲文本到圖像以及圖像到文本之間的雙向交互,提出了一個(gè)多模態(tài)交互(MMI)模塊來學(xué)習(xí)圖像感知的詞表示和每個(gè)詞的詞感知的視覺表示。
除此之外,為了緩解學(xué)習(xí)模型過分強(qiáng)調(diào)圖像突出顯示的實(shí)體而忽略剩余實(shí)體的偏差,附加了一個(gè)實(shí)體范圍識別的任務(wù)作為auxiliary任務(wù),即具有輔助實(shí)體跨度檢測(ESD)模塊的統(tǒng)一結(jié)構(gòu),使用純文本的ESD來指導(dǎo)我們的主要任務(wù)MNER的最終預(yù)測。
BERT編碼器得到的C使用另一個(gè)Transformer層來獲得其特定的隱藏表示T,然后將其送到CRF層,因?yàn)镋SD與MNER這兩個(gè)任務(wù)是高度相關(guān)的,每個(gè)ESD標(biāo)簽應(yīng)該對應(yīng)于MNER中的標(biāo)簽子集,引入一個(gè)轉(zhuǎn)移矩陣來約束兩邊預(yù)測出來的實(shí)體位置保持一致。具體說,就是修改了MNER的CRF層,將實(shí)體跨度信息從ESD納入MNER任務(wù)的預(yù)測中。
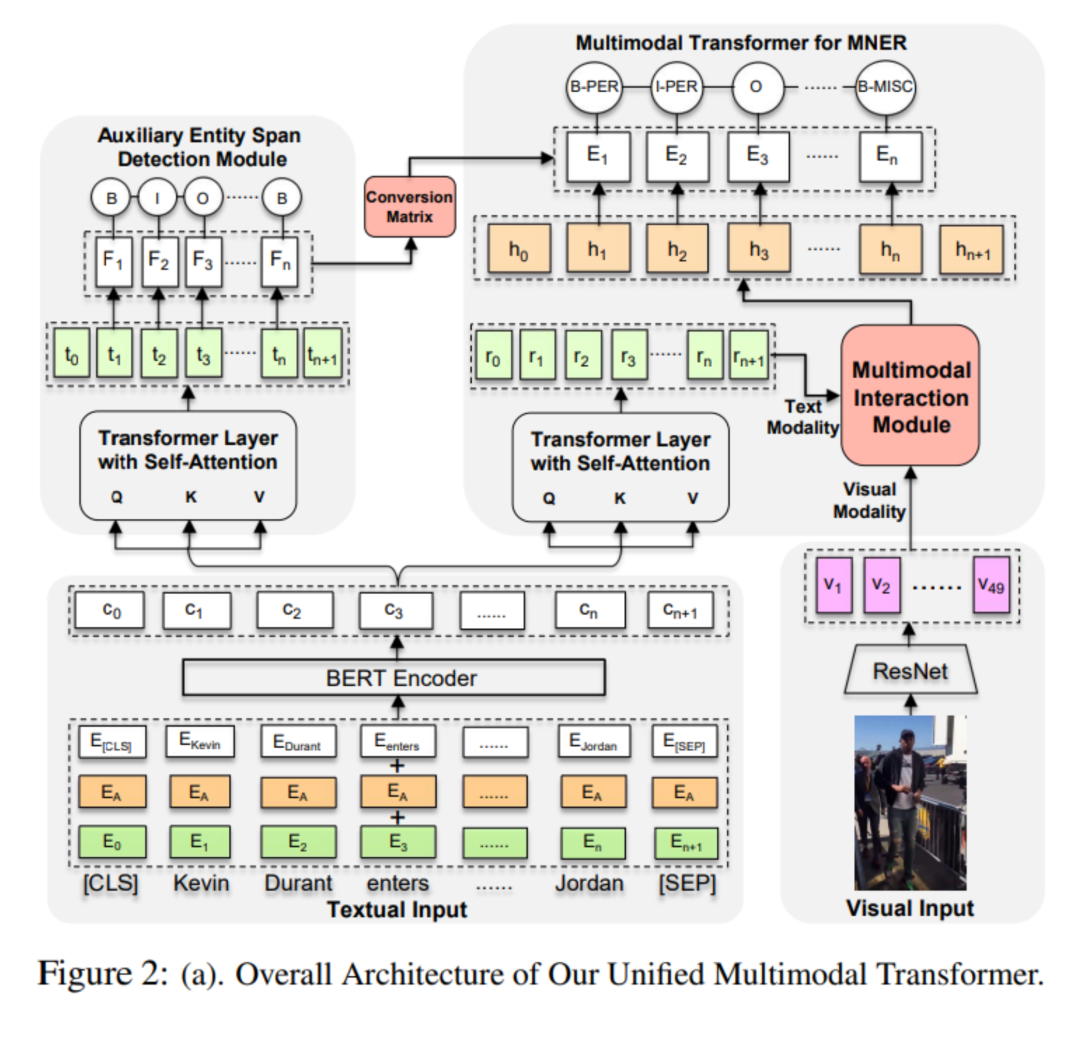
多模態(tài)交互(MMI)模塊,使用統(tǒng)一的Transformer結(jié)構(gòu)來進(jìn)行多模態(tài)信息的交互。使用三個(gè)cross transformer分別獲得圖像指導(dǎo)的文本表示、文本指導(dǎo)的圖像表示以及文本模態(tài)內(nèi)部的交互表示,在兩個(gè)模態(tài)信息交互的過程中通過一個(gè)Visual Gate動態(tài)控制兩個(gè)模態(tài)之間的交互,為了合并詞表示和視覺表示,將A和B連接起來,以獲得最終的隱藏表示H;然后,將H送到標(biāo)準(zhǔn)CRF層,進(jìn)行最終的序列標(biāo)注任務(wù)。
在兩個(gè)標(biāo)準(zhǔn)的 Twitter 數(shù)據(jù)集(Twitter15、Twitter17)進(jìn)行了實(shí)驗(yàn),其中倒數(shù)第二行是把Unified Multimodal Transformer模型左上角輔助任務(wù)去掉的結(jié)果,相較于之前的一些研究模型都有非常明顯地提升,最后一行是Unified Multimodal Transformer模型的結(jié)果相較于沒有輔助任務(wù)的結(jié)果大概有一個(gè)點(diǎn)的性能提升。
小結(jié):
第一個(gè)提出使用統(tǒng)一的Transformer結(jié)構(gòu)來進(jìn)行多模態(tài)信息的交互。
提出基于文本的具有輔助實(shí)體跨度檢測(ESD)模塊。
在兩個(gè)標(biāo)準(zhǔn)的 Twitter 數(shù)據(jù)集上都獲得了較先進(jìn)的結(jié)果。
為其他團(tuán)隊(duì)后來工作奠定了基礎(chǔ)。

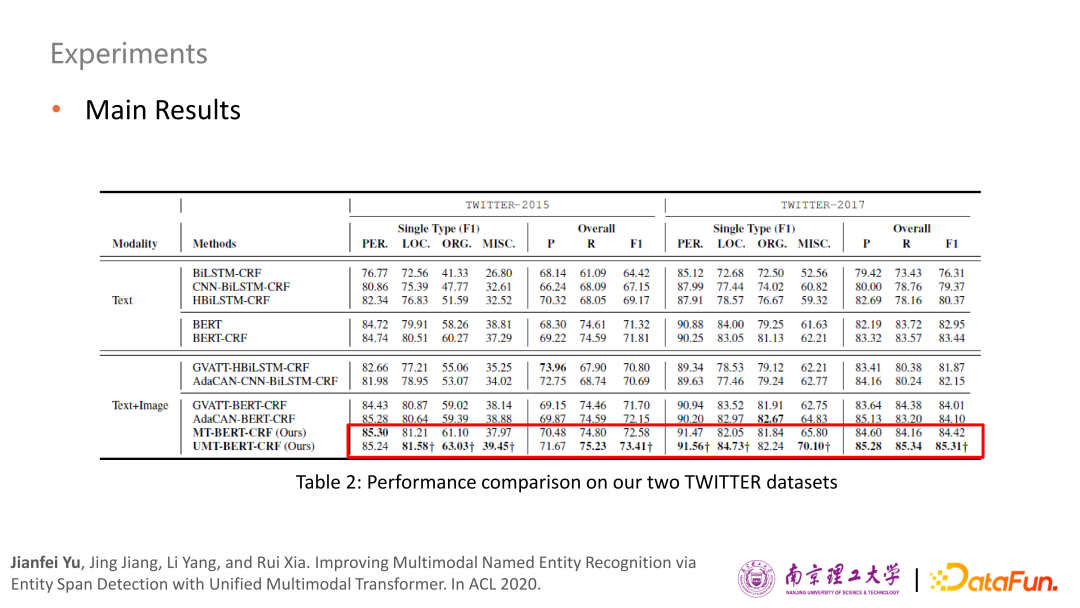
接下來,第二個(gè)是今年提出的一個(gè)從粗粒度到細(xì)粒度的圖像和評價(jià)對象匹配的網(wǎng)絡(luò),在這篇文章中的多模態(tài)屬性級情感分析任務(wù)具體是在給定評價(jià)對象的前提下,識別出用戶對這個(gè)評價(jià)對象表達(dá)了什么樣的情感,正面、負(fù)面還是中立?例如,在這個(gè)多模態(tài)推文中,提前給定了兩個(gè)評價(jià)對象 Nancy 和 Salalah Tourism Festival,根據(jù)圖文信息可以判斷出用戶對于 Nancy是正面的情感,而對于Salalah Tourism Festival表達(dá)了中立的情感。
具體論文參考: Jianfei Yu, Jieming Wang, Rui Xia, and Junjie Li. Targeted Multimodal Sentiment Classification based on Coarse-to-Fine Grained Image-Target Matching. In Proceedings of IJCAI-ECAI 2022.

為什么要做這個(gè)工作?對于這個(gè)多模態(tài)屬性級情感分類而言,目前大部分的研究工作都沒有對評價(jià)對象和圖像的匹配關(guān)系進(jìn)行顯示的建模。根據(jù)對benchmark數(shù)據(jù)集的觀察,發(fā)現(xiàn)其實(shí)大部分評價(jià)對象和圖片之間是完全不相關(guān)的。例如,Nancy 作為輸入的評價(jià)對象時(shí),是和圖片是相關(guān)的,同時(shí)圖中笑臉在判斷用戶正向情感提供了重要的支撐。但對于Salalah Tourism Festival來說,圖片中沒有任何體現(xiàn),因此這個(gè)評價(jià)對象和圖片其實(shí)是不相關(guān)的。基于此發(fā)現(xiàn),就對benchmark數(shù)據(jù)集進(jìn)行了人工標(biāo)注,從而發(fā)現(xiàn)約 58% 的評價(jià)對象和相應(yīng)圖片都是不相關(guān)的。

由于每張圖片包含很多的對象,可以標(biāo)注出不同區(qū)域框,例如之前圖片當(dāng)中,可以標(biāo)注出 5 個(gè)比較明顯的對象,用數(shù)字去標(biāo)識。只有第一個(gè)框和評價(jià)對象 Nancy 是相關(guān)的,而其他的框都是完全無關(guān)的,第一個(gè)框中的笑臉信息可以幫助快速判斷正向情感。因此對于那些和圖片相關(guān)的評價(jià)對象,需要進(jìn)一步判斷圖中哪個(gè)對象或區(qū)域和評價(jià)對象是相關(guān)的,否則會引入一些無關(guān)對象,給情感識別帶來一定的噪音。

基于兩個(gè)問題,對benchmark數(shù)據(jù)集進(jìn)行了人工標(biāo)注,它是一個(gè)小規(guī)模的Twitter數(shù)據(jù)集。具體流程是標(biāo)注給定評價(jià)對象是否和對應(yīng)圖像相關(guān),并進(jìn)一步標(biāo)注評價(jià)對象與圖像中的哪一個(gè)區(qū)域相關(guān),也把框標(biāo)注出來。
根據(jù)統(tǒng)計(jì),大概標(biāo)注了1200個(gè),從中發(fā)現(xiàn)用戶對大部分和圖片相關(guān)的評價(jià)對象表達(dá)的情感不是正向就是負(fù)向,很少表達(dá)中立的情感,而對那些和圖像不相關(guān)的評價(jià)對象,都傾向于表達(dá)中立的情感。這也符合我們的直觀感覺,圖像一般都反映用戶比較感興趣的對象,而用戶不感興趣的對象一般都不會放到圖像上。

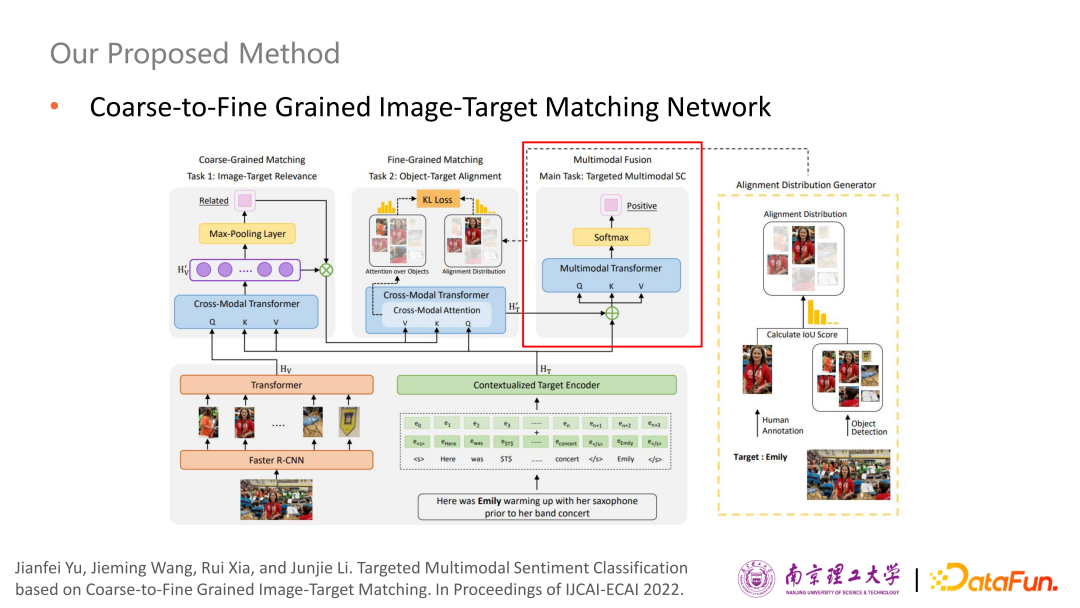
基于這個(gè)數(shù)據(jù)集,設(shè)計(jì)了一個(gè)從粗粒度到細(xì)粒度的圖像和評價(jià)對象的匹配網(wǎng)絡(luò)。這是整個(gè)網(wǎng)絡(luò)的架構(gòu)圖。
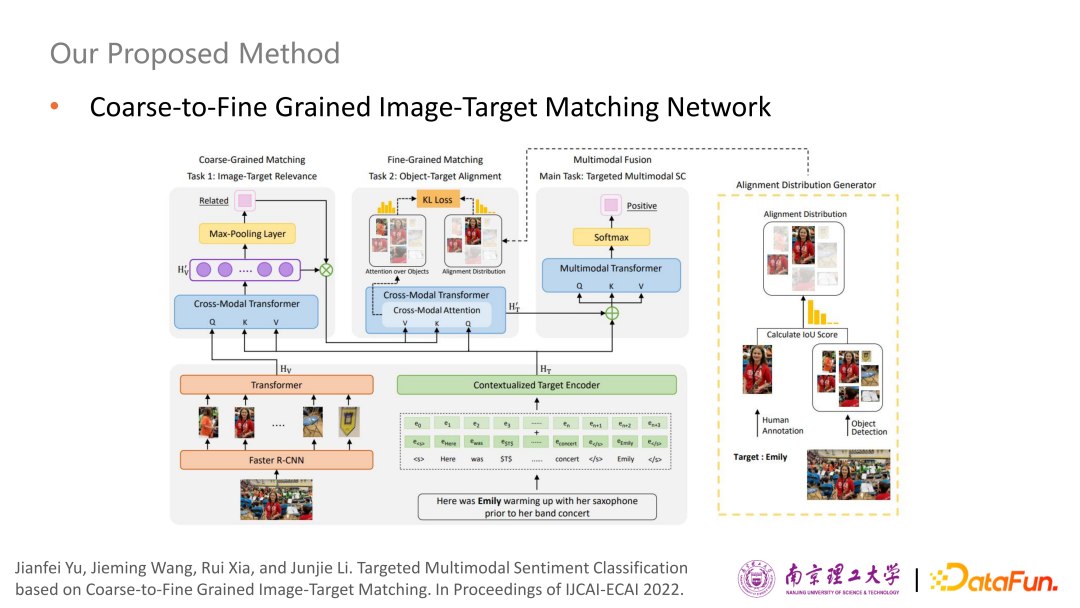
首先,分別使用文本編碼器和圖像編碼器來對輸入文本和圖像進(jìn)行編碼。值得注意的是,給定了評價(jià)對象如Emily,需對文本輸入進(jìn)行一個(gè)特殊處理,把Emily作為第二個(gè)句子放最后,然后把原句中的Emily用一個(gè)特殊指令$T$來代替,就得到一個(gè)帶有上下文和評價(jià)對象的文本輸入。左邊是圖像輸入,由于要判斷圖像中哪塊區(qū)域與評價(jià)對象是相關(guān)的,使用了一個(gè)廣泛使用的目標(biāo)檢測模型Faster R-CNN。
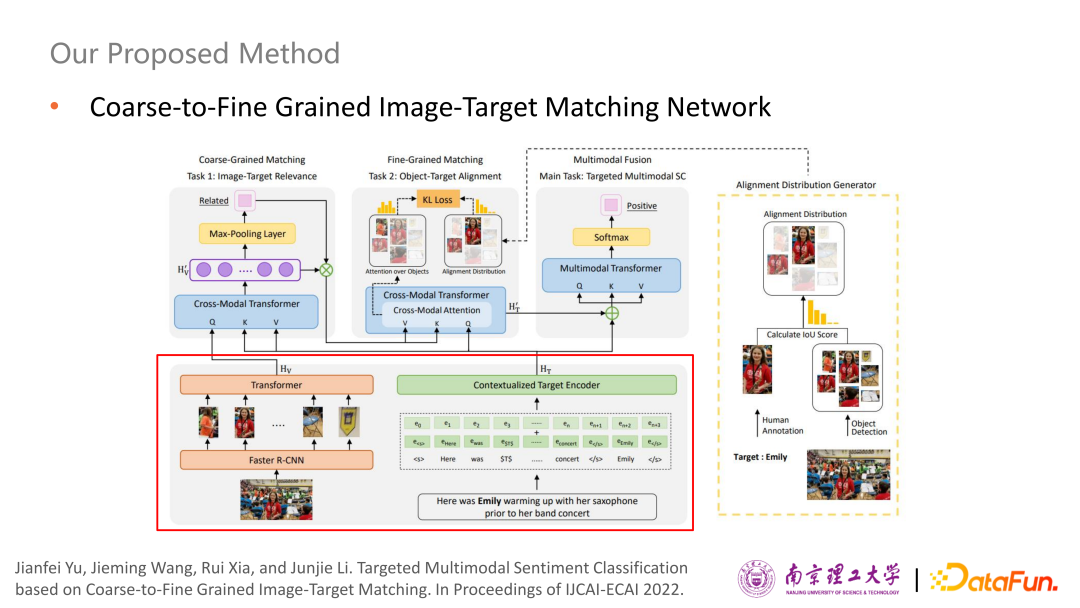
經(jīng)過編碼后,得到圖像和文本的表示Hv與HT,送到左上角的 Cross-Model Transformer 進(jìn)行交互,使用簡單的二分類來判斷粗粒度的圖像和評價(jià)對象是否相關(guān),再把概率乘回融合之后的圖像表示上,如果不相關(guān)的話概率比較小,基本上會把圖像信息過濾掉。
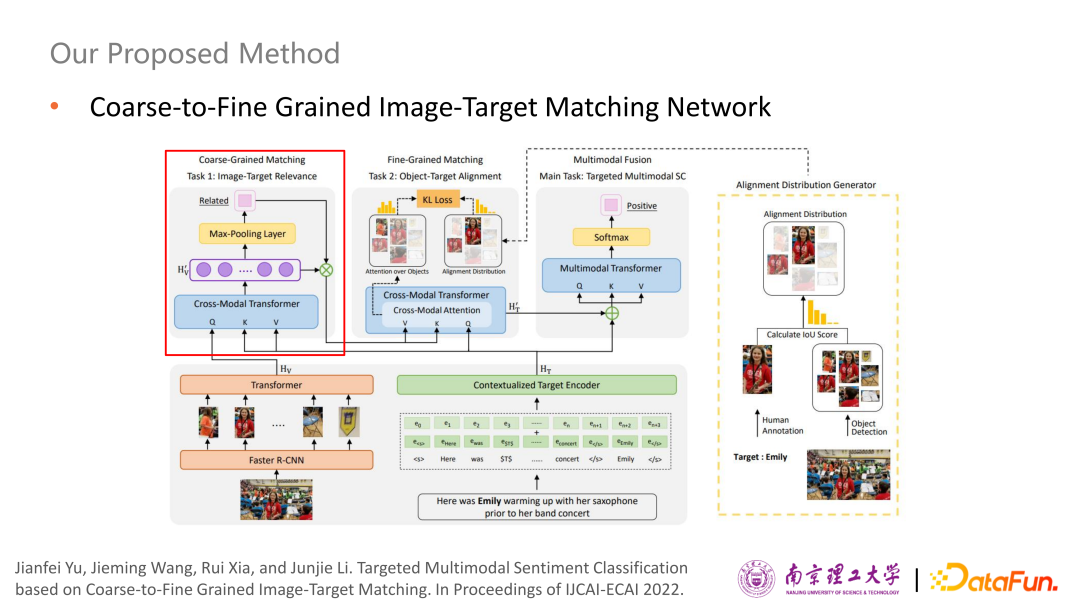
上一步得到的結(jié)果進(jìn)一步送到中間模塊進(jìn)行細(xì)粒度的匹配,也就是評價(jià)對象和相關(guān)object 進(jìn)行對齊模塊。評價(jià)對象的表示和過濾后的圖像表示送到另外一個(gè)Cross-Model Transformer進(jìn)行多模態(tài)信息的交互,這時(shí)候利用人工標(biāo)注的圖片里對應(yīng)的區(qū)域與Faster R-CNN提取出來的區(qū)域進(jìn)行交并比計(jì)算,得到IOU Score,如果IOU Score 大于0.5,認(rèn)為是一個(gè)有效的檢測,否則屬于無效的匹配,從而得到一個(gè)Ground Truth分布,作為監(jiān)督信號。最后使用Cross-Model Transformer中的Cross-Model Attention的分布來逼近Ground Truth 分布,這樣會使得與評價(jià)對象相關(guān)的區(qū)域Attention位置會比較大,而與評價(jià)對象不相關(guān)的區(qū)域Attention位置就會比較小。
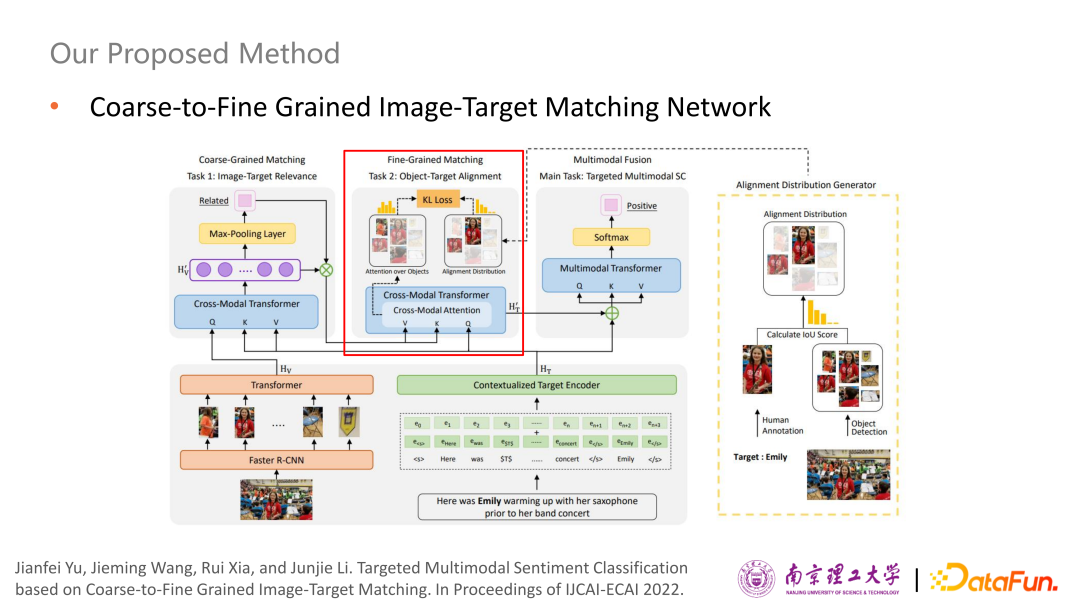
最后可以得到經(jīng)過多模態(tài)融合之后的表示,把它和原始的純文本表示拼起來送到一個(gè) Multimodal Transformer進(jìn)行情感分類。
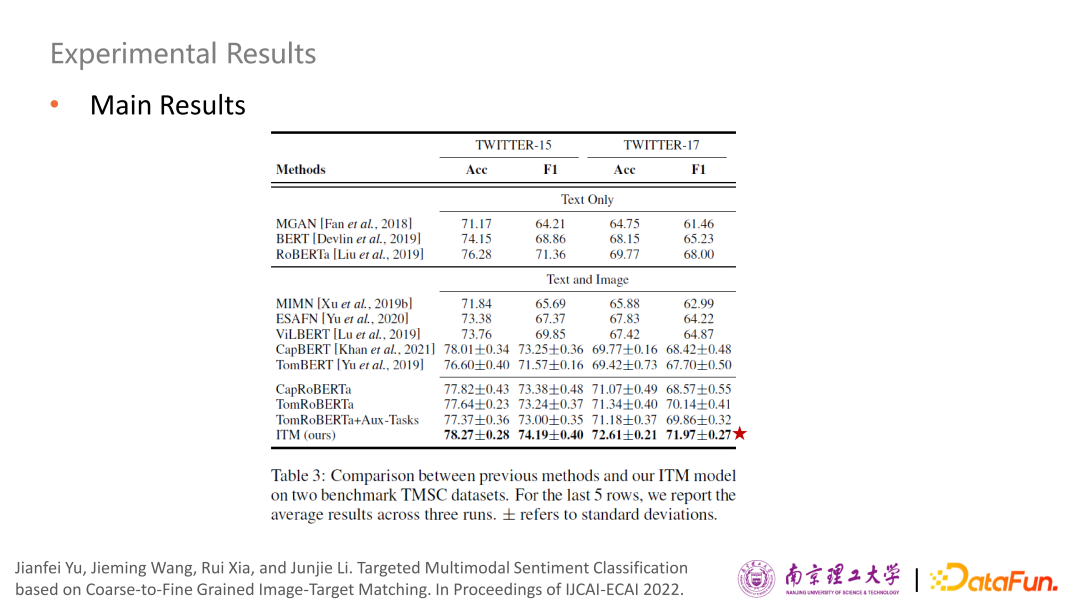
在Twitter 15 和 Twitter 17 的這兩個(gè)標(biāo)準(zhǔn)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),可以發(fā)現(xiàn)此方法有非常顯著地提升。還對TomBERT和CapBERT做了一些變形,并把輔助任務(wù)加到里面,做了一些探索實(shí)驗(yàn),可以看到此方法相比于這些變形系統(tǒng)也有一個(gè)明顯的提升。
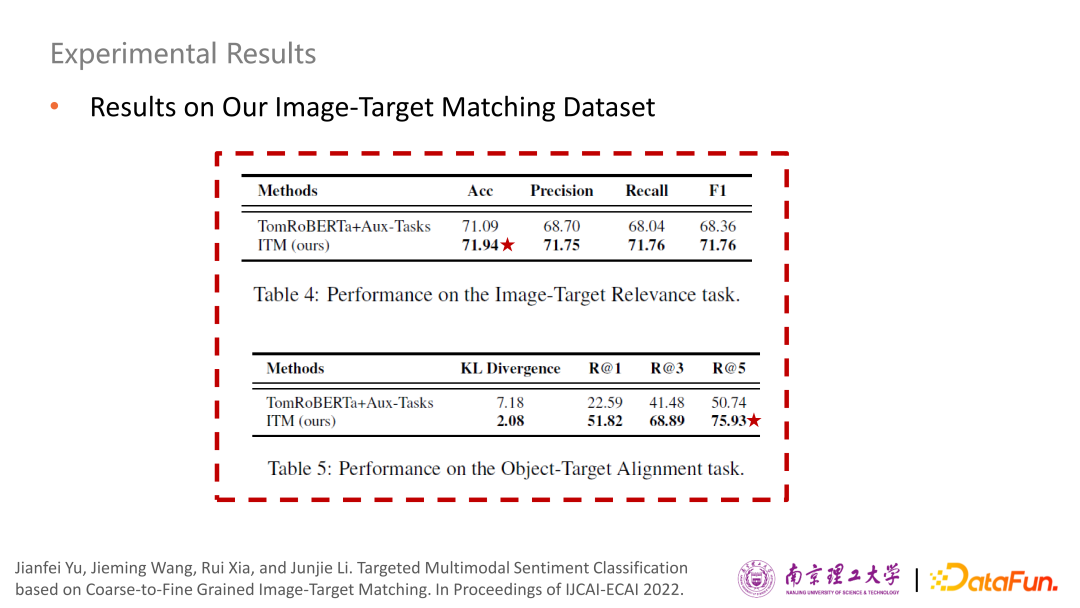
下面是使用兩個(gè)輔助任務(wù)的性能,一個(gè)是圖文粗粒度匹配,另一個(gè)是細(xì)粒度的圖像區(qū)域和評價(jià)對象的對齊。這兩個(gè)任務(wù)我們提出的模型相比于基礎(chǔ)方法都有較明顯的性能提升。

小結(jié):
人工標(biāo)注了一個(gè)圖像和評價(jià)對象匹配的數(shù)據(jù)集。
提出了一個(gè)新的圖像和評價(jià)對象匹配模型,主要是一個(gè)從粗粒度到細(xì)粒度進(jìn)行匹配的網(wǎng)絡(luò)結(jié)構(gòu)。
實(shí)驗(yàn)結(jié)果也表明這個(gè)模型取得了較先進(jìn)的效果。
近些年,多模態(tài)情感分析任務(wù)(MABSA任務(wù)又叫做Target-Oriented Multimodal Sentiment Analysis 或 Entity-Based Multimodal Sentiment Analysis)發(fā)展迅猛。之前大多數(shù)MABSA研究存在以下不足:
采用單模態(tài)預(yù)訓(xùn)練模型來獲得文本的表示和圖像的表示,忽略兩個(gè)模態(tài)之間的對齊和交互。
使用通用的預(yù)訓(xùn)練任務(wù),和下游任務(wù)無相關(guān)性,不足以識別細(xì)粒度的屬性、情感及其跨模態(tài)的對齊。
未能充分利用生成型模型。

為了解決這些不足,針對MABSA任務(wù),我們在今年的 ACL 上提出了一個(gè)特定任務(wù)的視覺-文本(vision-language)預(yù)訓(xùn)練框架,這是一個(gè)通用的基于預(yù)訓(xùn)練的 BERT 模型的編碼、解碼框架,適用于所有的預(yù)訓(xùn)練和下游任務(wù)。此外,針對文本、視覺和多模態(tài),分別設(shè)計(jì)了5個(gè)預(yù)訓(xùn)練任務(wù):
MLM:類似BERT的做法,以15%的概率隨機(jī)遮蔽輸入文本的tokens,目標(biāo)是基于圖像和文本上下文預(yù)測出遮蔽的文本內(nèi)容。
AOE:目標(biāo)是根據(jù)文本生成出其中包含的所有aspect和opinion。模型需要輸出一個(gè)序列,包含分隔符和終止符的token,以及每條aspect和每條opinion在原文本token序列中的位置編號。aspect的ground-truth采用的是NER工具對原文本提取出的所有實(shí)體,opinion的ground-truth采用的是SentiWordNet情感詞典[4]對原文本提取出的所有情感詞。
MRM:類似UNITER中的MRM-kl的做法,以15%的概率隨機(jī)遮蔽image regions并替換為零向量,預(yù)測每個(gè)遮蔽掉的region的語義類別分布,將模型預(yù)測的分布與Faster R-CNN對該region預(yù)測的類別分布兩者的KL散度作為該任務(wù)的損失值。
AOG:目標(biāo)是從輸入圖像中生成所有的aspect-opinion pair。將DeepSentiBank對輸入圖像提取出的置信度最高的ANP(形容詞-名詞對)作為ground-truth。模型需要預(yù)測出一個(gè)序列,包含一個(gè)這樣的ANP以及終止符token。
MSP:將MVSA-Multi提供的粗粒度情感標(biāo)簽作為監(jiān)督信號。根據(jù)兩個(gè)模態(tài)的信息,預(yù)測出圖文對的情感類別。
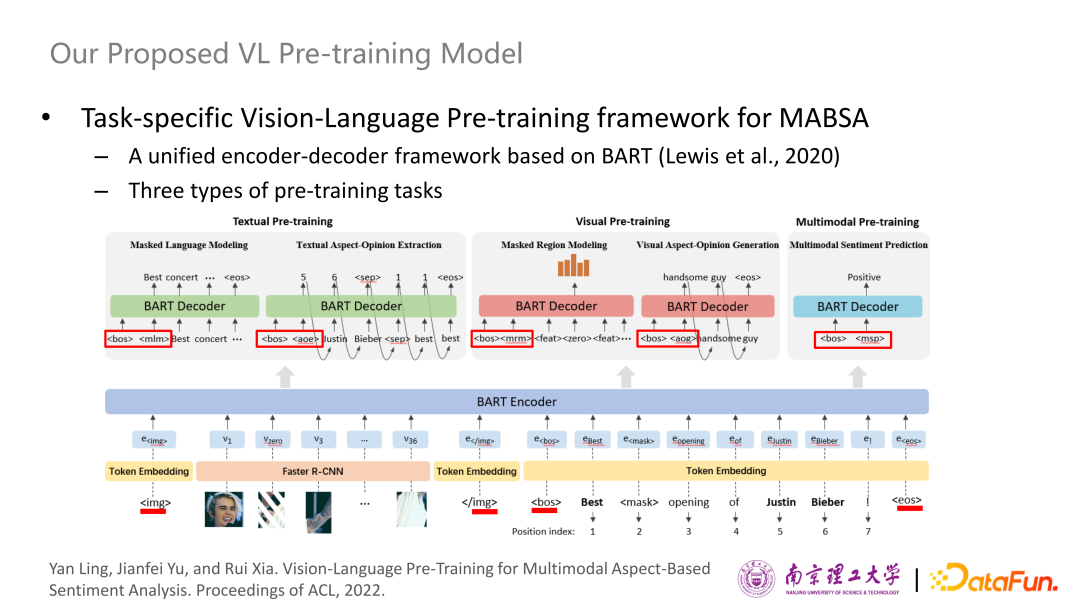
對于下游任務(wù)來講,建模和預(yù)訓(xùn)練的框架是一樣的,使用了一個(gè)BART-based的生成框架,為了區(qū)分不同的輸入,我們使用表示圖片特征的開始,使用表示圖片特征的結(jié)束,使用
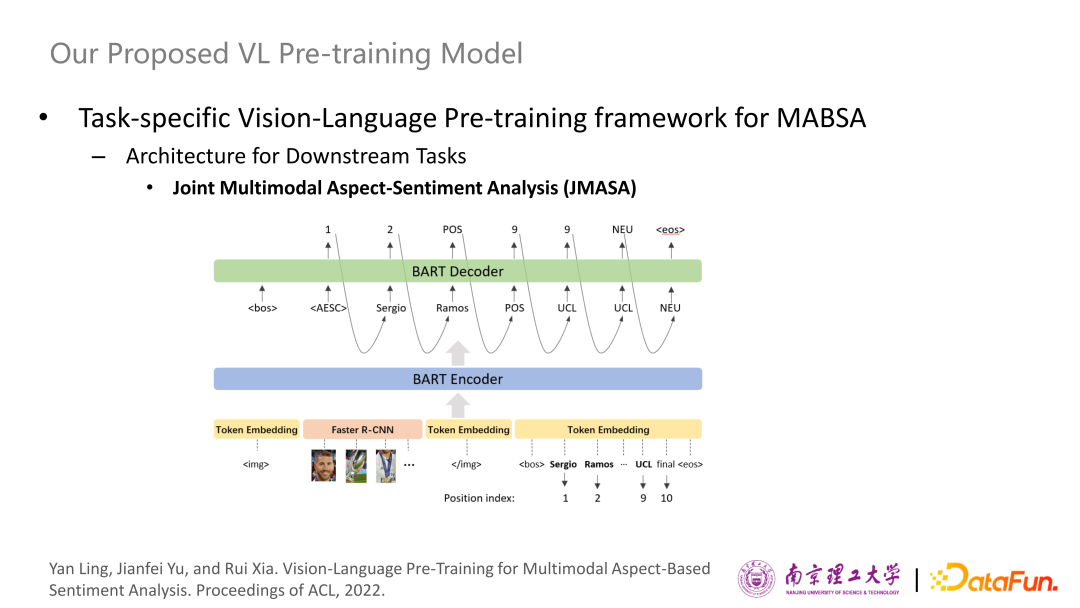
利用帶有粗粒度情感標(biāo)注的MVSA-Multi數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,這個(gè)數(shù)據(jù)集提供了文本-圖片成對輸入,以及關(guān)于其的粗粒度情感。在TWITTER-2015和TWITTER-2017兩個(gè)細(xì)粒度視覺語言情感數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),在各下游任務(wù)上基本都能勝過其它SOTA方法的表現(xiàn)。
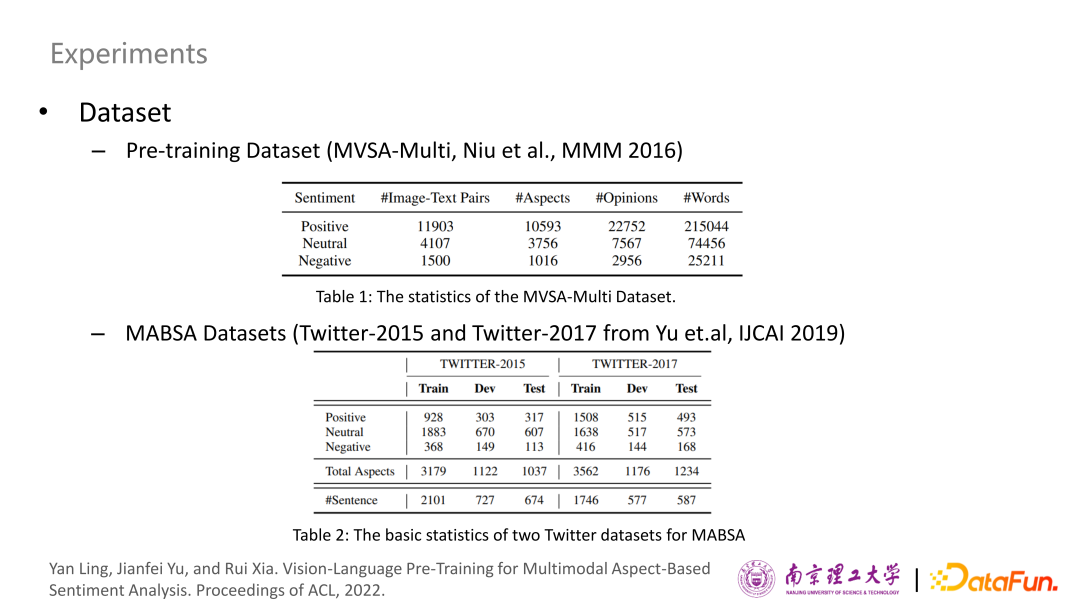
進(jìn)一步的實(shí)驗(yàn)和分析表明在所有的方法中,VLP-MABSA在兩個(gè)數(shù)據(jù)集中,性能都最優(yōu)。
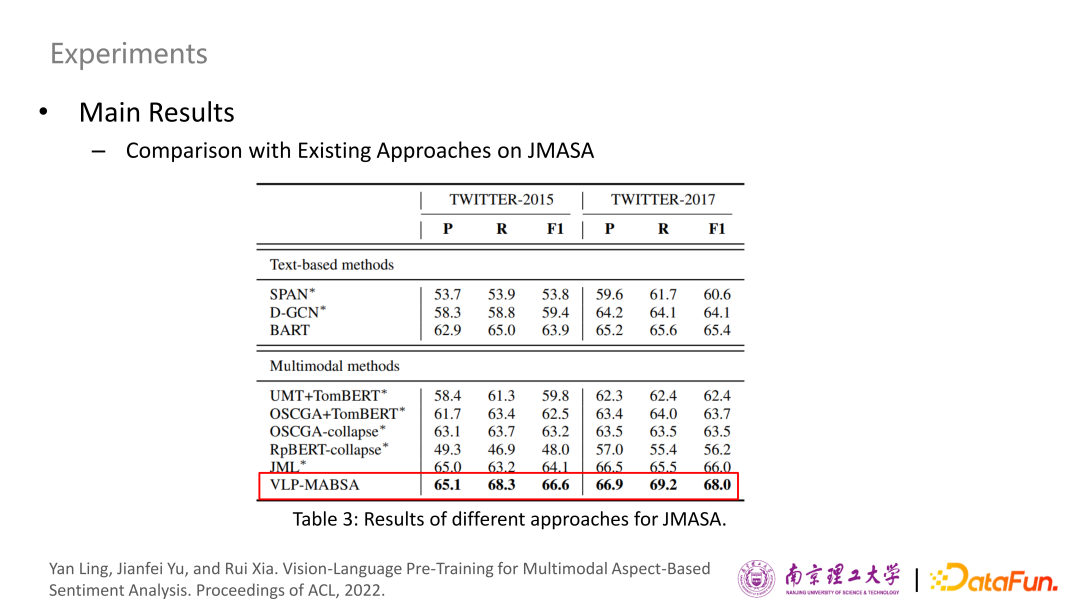
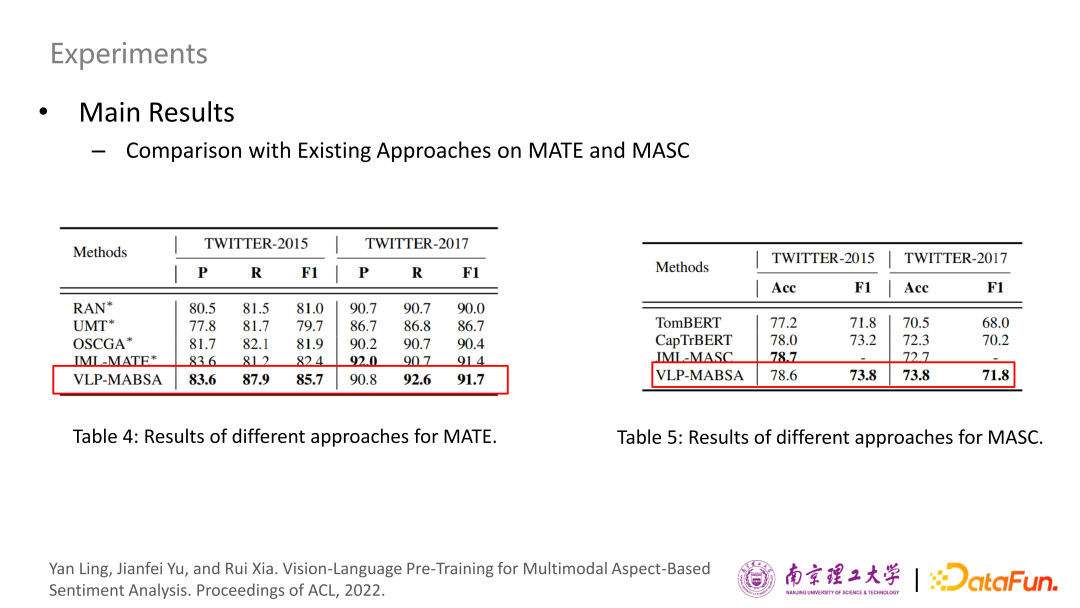
以下分別是MATE和MAS任務(wù)的結(jié)果,與JMASA子任務(wù)的趨勢相似,我們可以清楚地觀察到,VLP-MABSA方法通常在兩個(gè)數(shù)據(jù)集上取得最好的性能,除了twitter-2015的準(zhǔn)確性度量,進(jìn)一步證明了我們提出的預(yù)訓(xùn)練方法的一般有效性。
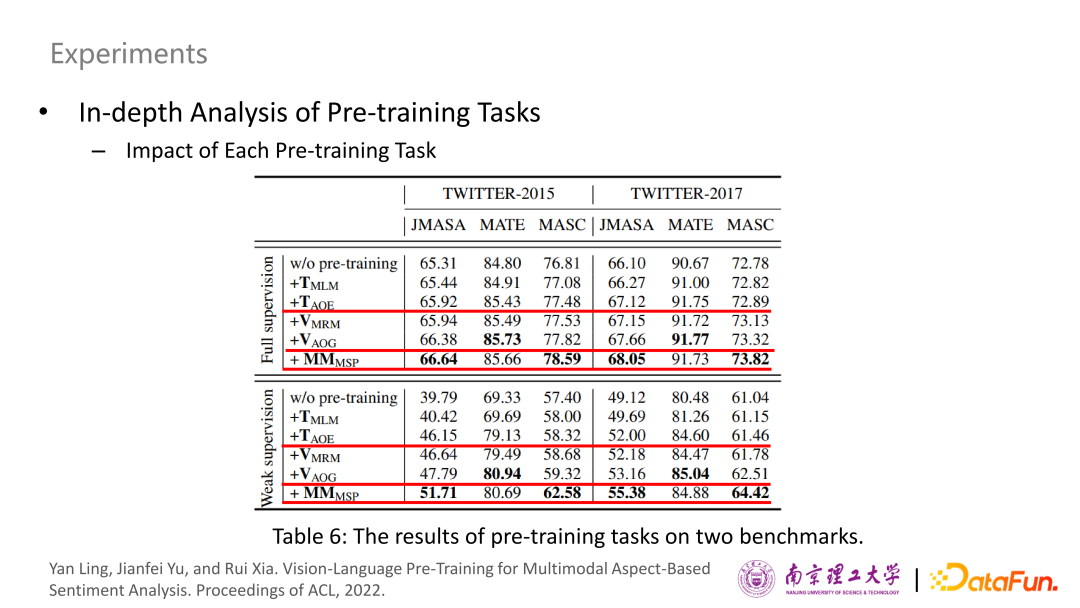
為了探究每個(gè)預(yù)訓(xùn)練任務(wù)的影響,使用完整訓(xùn)練數(shù)據(jù)集和弱監(jiān)督設(shè)置下僅隨機(jī)選擇200個(gè)訓(xùn)練樣本的全監(jiān)督設(shè)置上進(jìn)行了訓(xùn)練。可以看到兩個(gè)比較通用的預(yù)訓(xùn)練任務(wù) MLM 和 MRM,它們的提升都非常有限,說明這種比較通用的預(yù)訓(xùn)練任務(wù)對于下游任務(wù)的幫助并不大。但是反觀與下游息息相關(guān)的預(yù)訓(xùn)練任務(wù),都對提升模型的表現(xiàn)有所幫助,提升的效果很顯著。
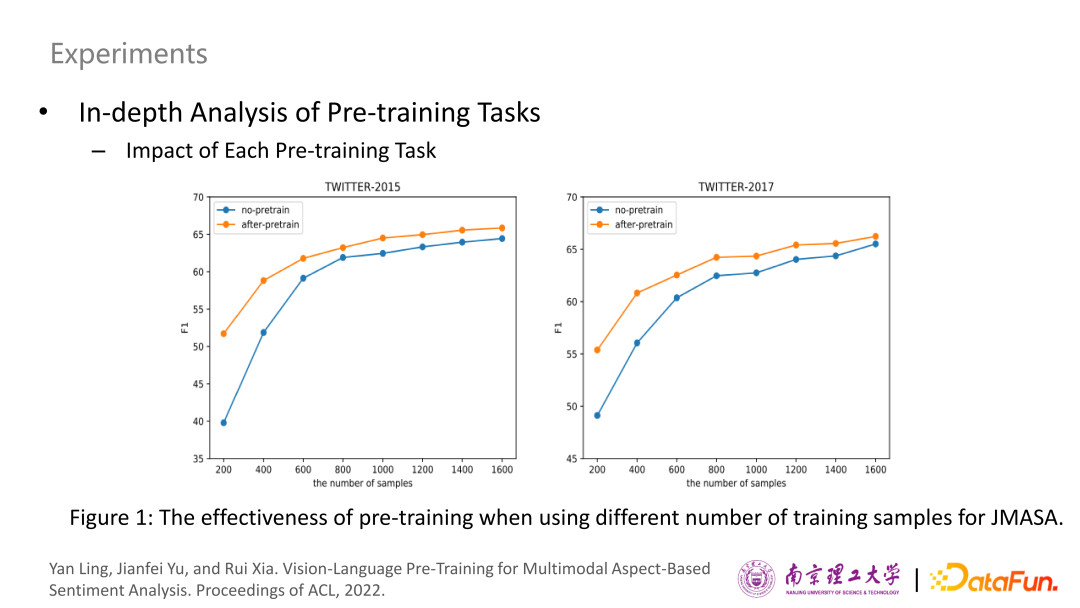
在采用不同數(shù)量的樣本進(jìn)行下游訓(xùn)練時(shí),比較了有和沒有預(yù)訓(xùn)練的結(jié)果,使用JMASA任務(wù)作為例子來觀察其影響。如圖所示,當(dāng)樣本量較小時(shí),預(yù)訓(xùn)練可以帶來巨大的改進(jìn)。相比之下,當(dāng)樣本量增大時(shí),預(yù)訓(xùn)練帶來的改進(jìn)相對較小。這進(jìn)一步說明了預(yù)訓(xùn)練方法的魯棒性和有效性,特別是在小樣本的場景中。
小結(jié):
提出了一個(gè)特定任務(wù)的視覺-文本(vision-language)預(yù)訓(xùn)練框架,生成一個(gè)基于BART的生成式框架多模態(tài)模型。
針對文本、視覺、和多模態(tài),分別設(shè)計(jì)了三種特定任務(wù)的預(yù)訓(xùn)練任務(wù)。
實(shí)驗(yàn)證明了預(yù)訓(xùn)練方法在三個(gè)不同的子任務(wù)上都取得到非常好的性能。
 04 總結(jié)
04 總結(jié)
以上主要介紹了針對多模態(tài)屬性級情感分析三個(gè)不同的子任務(wù),并介紹了這幾年在每個(gè)子任務(wù)上的一個(gè)代表性工作。第一個(gè)聚焦于多模態(tài)交互和視覺偏差,第二個(gè)聚焦于圖像和文本之間的細(xì)粒度和粗粒度的對齊,第三個(gè)聚焦于任務(wù)特定的視覺語言的預(yù)訓(xùn)練。
展望未來工作,第一個(gè)點(diǎn)是多模態(tài)屬性級情感分析模型的可解釋性,一個(gè)方面可以通過可視化的方式來分析模型學(xué)到的知識正確性,另一方面是進(jìn)行對抗攻擊,把測試集中圖像和文本進(jìn)行隨機(jī)替換和變化,看模型預(yù)測的變化。第二個(gè)點(diǎn)是相關(guān)多模態(tài)任務(wù)的擴(kuò)展,比如說多模態(tài)的信息抽取、多模態(tài)的實(shí)體鏈接、多模態(tài)的實(shí)體消歧、多模態(tài)的關(guān)系或者事件抽取以及多模態(tài)的知識圖譜的構(gòu)建和補(bǔ)全。

審核編輯:劉清
-
ACL
+關(guān)注
關(guān)注
0文章
61瀏覽量
12364 -
多模態(tài)組網(wǎng)
+關(guān)注
關(guān)注
0文章
4瀏覽量
2435 -
Mate
+關(guān)注
關(guān)注
2文章
55瀏覽量
4978
原文標(biāo)題:面向社交媒體的多模態(tài)屬性級情感分析研究
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
電機(jī)聯(lián)軸控制的旋轉(zhuǎn)機(jī)械定轉(zhuǎn)子模態(tài)分析
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

基于MindSpeed MM玩轉(zhuǎn)Qwen2.5VL多模態(tài)理解模型

?多模態(tài)交互技術(shù)解析
海康威視發(fā)布多模態(tài)大模型文搜存儲系列產(chǎn)品
智譜 GLM-PC 開放體驗(yàn),多模態(tài) Agent 升級

黑芝麻智能與Nullmax推出A2000多模態(tài)大模型智駕方案
商湯日日新多模態(tài)大模型權(quán)威評測第一
一文理解多模態(tài)大語言模型——下






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論