") 基于BIO序列標注的方法和基于片段的圖解析方法
基于BIO序列標注的方法和基于片段的圖解析方法

主要貢獻:片段語義角色標注目前的兩種主流方法分別為:基于BIO序列標注的方法和基于片段的圖解析方法。該論文提出一種新的基于詞的圖解析方法,將片段圖解析方法的搜索空間從O(n^3)降低到O(n^2),從而大幅度提升了模型的訓練和解碼效率,且性能超過了前人結(jié)果。
-01-
摘要
該論文的出發(fā)點是將端到端基于片段的(span-based)語義角色標注(SRL)轉(zhuǎn)換為基于詞的(word-based)圖解析(graph parsing)任務。其中主要的挑戰(zhàn)是如何在詞級別上表示片段信息。該論文通過借鑒中文分詞(CWS)和命名實體識別(NER)的研究成果,提出了四種不同的圖表示方案,即BES、BE、BIES和BII。此外,根據(jù)SRL結(jié)構(gòu)的約束,作者還提出了一個簡單的約束Viterbi過程,以保證輸出圖的合法性。作者在兩個廣泛使用的CoNLL05和CONLL12基準數(shù)據(jù)集上進行了實驗。結(jié)果表明,在端到端和謂詞給定的所有設置下,在沒有和有預訓練語言模型的情況下,該論文提出的基于word的圖解析方法都取得了比以前方法更好的性能。更重要的是,該論文提出的方法推理速度很快,在不使用預訓練模型(PLMs)的情況下,每秒可以解析669個句子;在使用PLMs的情況下,每秒可以解析252個句子。
-02-
背景介紹
語義角色標注是自然語言處理(NLP)中一個必不可少的任務,它使用謂詞-論元的結(jié)構(gòu)去表示一個淺層的句子語義。SRL結(jié)構(gòu)能夠幫助解決很多下游NLP任務,比如機器翻譯和問答。
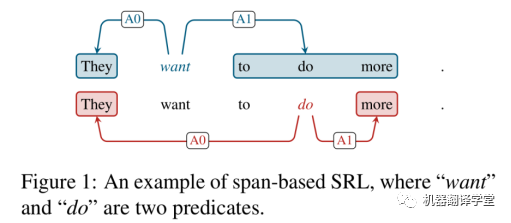
SRL存在兩個形式,分別基于詞(word-based)和片段(span-based),劃分依據(jù)取決于一個論元是包含單個單詞還是一個片段。對比基于word的SRL來說,基于span的SRL是更加復雜的。上圖1也展示了一個基于span的樣例,語義角色被邊的標簽所劃分,比如施事(agent)“A0”和受事(patient)“A1”。
隨著深度學習的發(fā)展,尤其是預訓練模型的提出,基于span的SRL近些年也取得了巨大的進展,吸引了研究人員們的關注。該工作主要關注端到端基于span的SRL任務,并提出了一個模型可以同時識別輸入句子中的謂詞和論元。這里端到端是指一個句子中所有的謂詞和論元都是通過單個模型同時推斷得到的。
基于span的圖解析方法直接把所有的詞片段考慮為候選論元節(jié)點,并將他們鏈接到謂詞節(jié)點上。然而,對于一個句長為n的句子,計算候選謂詞和候選論元的復雜度分別為O(n)和O(n^2),從而導致了一個非常大的搜索空間O(n^3),使得這種方法效率較低。在以往的一些工作,通常使用啟發(fā)式剪枝技術來提高效率。
針對端到端基于span的 SRL,該論文首次提出了一種基于word的圖解析方法。由于圖網(wǎng)絡中的每個節(jié)點只對應于單個單詞,關鍵的挑戰(zhàn)是如何在基于單詞的圖中表示基于span的論元。一旦解決了這個問題,就可以在現(xiàn)有的基于單詞的圖解析模型基礎上構(gòu)建解析器。該工作的主要貢獻點如下:
1: 提出了一種新的基于word的圖解析方法,可以用于端到端基于span的SRL。通過簡單的修改,該方法也可以應用于謂詞給定的設置。
2: 借鑒中文分詞(CWS)和命名實體識別(NER)的研究思路,作者提出了4個圖方案,其中BES方案穩(wěn)定優(yōu)于其他方案。
3: 同時,由于圖解析模型可能會輸出不合法的圖,不能正確地轉(zhuǎn)換為SRL結(jié)構(gòu)。為了解決這一問題,作者提出了一個簡單的約束Viterbi過程(constrained Viterbi procedure),用于非法圖的后處理。
4: 作者在CoNLL05和CoNLL12基準數(shù)據(jù)集上進行了實驗。在端到端和謂詞給定的所有設置下,無論是否使用PLMs,該論文提出的方法都能取得比以前方法更好的性能。并且模型推斷速度要快得多,在不使用PLMs和使用PLMs的情況下,每秒分別可以分析669/252個句子。
-03-
方法
3.1 圖構(gòu)造方案
該工作把端到端基于span的SRL看作是一個基于word的圖解析任務。但是所面臨的一個關鍵挑戰(zhàn)是需要設計一個合適的圖方案使得在不產(chǎn)生歧義的情況下,讓所有的謂詞和基于span的論元能夠在同一個圖中被正確表示。并且,這個圖在沒有性能損失的情況下,也可以被轉(zhuǎn)換成其對應SRL結(jié)構(gòu)。方案具體設計如下所述。
3.1.1 SRL-Graph轉(zhuǎn)換
該工作設計了四種不同的方案來將基于span的SRL結(jié)構(gòu)轉(zhuǎn)換為基于word的圖。其基本的想法是連接論元的詞語到其對應的謂詞,并且標記出語義角色標簽和詞在論元中的位置。具體來講,該工作在句子的開頭添加一個偽“Root”節(jié)點,并且把所有的謂詞連接到這個節(jié)點,其所構(gòu)造的邊為“PRD”。這樣的設計能夠?qū)崿F(xiàn)通過一個端到端的方式直接預測謂詞和論元。通過借鑒CWS和NER的思想,該工作提出兩種論元到其對應謂詞的策略:boundary-attach和all-attach。boundary-attach表示僅僅連接論元開頭和結(jié)尾的詞語到對應的的謂詞上。而all-attach表示連接論元中所有的單詞到其對應謂詞。該工作又分別為這兩種策略設計了兩個連接的方案,對應如下:
Boundary-attach:BES和BE
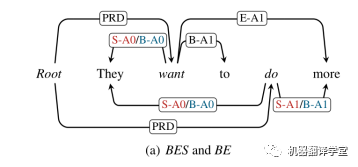
如上圖所示,對應了該工作所設計的boundary-attach的兩種方案BES和BE,分別為紅色和藍色。當論元包含多個單詞的時候,兩種方案均只需要把論元的開頭和結(jié)尾的單詞連接到對應謂詞,并使用“B-r”和“E-r”作為對應的邊標簽,其中r表示這個原始的語義角色標簽。
當論元只有一個單詞的時候, BE方案僅僅使用“B-r”作為標簽。而為了區(qū)分論元包含多個詞和單個詞的情況,BES方案使用額外的“S-r”作為標簽。
All-attach: BIES 和 BII
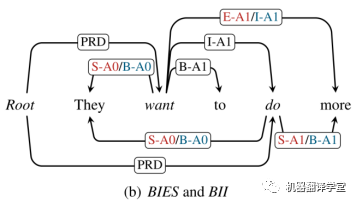
如上圖所示,對應了該工作所設計的all-attach的兩種方案BIES和BII,分別為紅色和藍色。在這個BII方案中,第一次詞被標記為“B-r”,然后后面的詞語被標記為“I-r”。對于BIES方案,其開頭詞語和結(jié)尾詞語的標記方法和BES類似,仍為“B-r”和“E-r”,中間的單詞被標記為“I-r”。
3.1.2 SRL-Graph恢復
在評估階段,輸入一個句子,圖解析模型根據(jù)選擇的方案,輸出一個最優(yōu)的圖。這之后的主要工作是如何將這個圖恢復到對應的SRL結(jié)構(gòu)。
假如該輸出的圖是沒有標簽沖突的,那么可以直接進行恢復。比如對應BES方案,圖中“Root”節(jié)點的全部孩子節(jié)點(word)可以被認為是謂詞。然后對應每一個謂詞,使用邊標注來恢復所有其對應的論元。一個論元對應成對的標簽,比如“B-A0”和“E-A0”,或者是一個單獨的標簽,比如“S-A0”。
但是在實際過程中,保證被輸出圖的合法性是非常困難的,往往并不能直接根據(jù)上述的規(guī)則將圖恢復為SRL結(jié)構(gòu)。為了解決這個問題,該工作基于一個受約束的Viterbi解碼方法提出了一個簡單并且高效的后處理方法,具體描述在章節(jié)3.3中。
3.2 模型
基于上面提出的方案,我們可以將基于span的作為基于word的圖解析任務進行處理。該論文的模型框架包括兩個階段: 1)預測所有邊 2)為邊分配標簽。
3.2.1 編碼器
雙向LSTM:模型的輸入單詞w_{i}是由三部分組成,
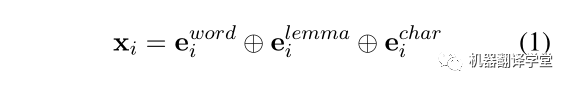
從左至右依次是詞向量、引理向量(lemma embedding)和char LSTM表示向量。將送入三層BiLSTM編碼器中,計算得到每個單詞的表示。
預訓練模型:該論文也嘗試分別使用ELMo和BERT兩個預訓練模型作為編碼器。其中,使用ELMo三層輸出的和作為表示,使用BERT最后四層輸出的和作為表示。
3.2.2 邊預測
在語義依存圖解析(SDGP)中,邊的預測問題被看作是0/1的二分類問題。這里的1代表在給定的單詞對之間存在一條邊,0則代表給定的單詞對之間不存在邊。當計算得到的存在邊的概率大于0.5時,就認為兩個單詞之間存在邊。
對于該論文提出的方法來說,僅僅使用一階子樹是不夠的,原因在于一階模型做了強假設,即邊是相互獨立的,因此在計算logits的時候只需要關注當前兩個單詞之間的信息。然而,在該論文的例子中,圖中的邊通常具有很強的相關性。例如,在BE方案中,一條“B-*”的邊通常調(diào)用一條“E-*”的邊,反之亦然,以形成一個完整的論元。所以該論文通過增加二階子樹的三種情況將模型從一階擴展至二階。該論文使用MFVI(mean field variational inference,平均場變分推斷)來計算logits。(注:這部分內(nèi)容讀者可以參考論文《Second-order semantic dependency parsing with end-to-end neural networks》(https://arxiv.org/pdf/1906.07880.pdf);一階、二階子樹參考下圖例子。
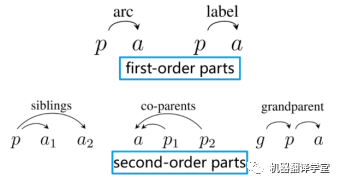
(圖片源自【王新宇- Second-Order Semantic Dependency Parsing with End-to-End Neural Networks】 https://www.bilibili.com/video/BV1bE411f7b9))
logits的計算分成兩部分:第一部分是一階分數(shù)s(i,j),使用兩個MLP和BiAffine計算得到。第二部分是二階分數(shù),使用三個MLP和TriAffine計算得到。如下圖所示。
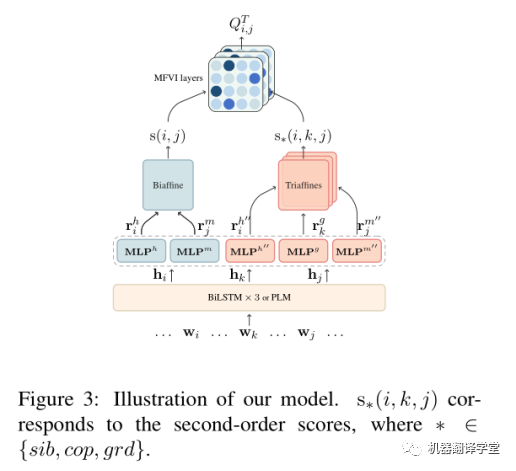
有了一階和二階分數(shù)之后,再使用MFVI方法迭代聚合得到最終的和。(注:MFVI的迭代計算過程可以參考這個視頻(https://www.bilibili.com/video/BV1bE411f7b9))
3.2.3標簽預測
類似于計算邊的分數(shù),該論文使用兩個MLP和多個BiAffine來計算標簽分數(shù)。每一個標簽的分數(shù)都由一個獨立的BiAffine計算得到。
3.2.4模型訓練
整個模型的損失由邊預測和標簽預測兩個模塊組成,如下所示.給定一句話X和對應的真實答案圖G,C代表X全連接的圖,CG代表不正確的邊的集合。第一個公式計算邊預測的損失,其含義為讓模型預測出正確邊概率更大的同時,讓模型預測錯誤的邊的概率更小。第二個公式計算標簽預測的損失。
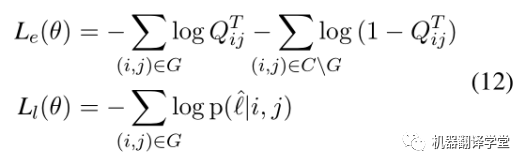
最后,對兩個損失通過超參λ加權(quán),這里λ= 0.06。
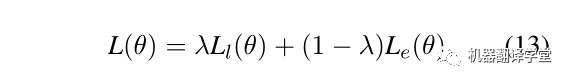
3.3沖突消除
在使用圖解析模型預測出結(jié)果后,該工作使用一個簡單的過程檢查是否生成圖是合法的。具體操作為,對于每一個謂詞,首先掃描這個謂詞的所有邊從左到右。例如,在這個BES方案下,一個“B-*”邊后面必須是一個“E-*”邊;“S-*”邊和“E-*”后面可以是一個“B-*”邊,或者是一個“S-*”邊。假如該生成圖是合法的,可以直接使用前面章節(jié)中所描述的過程將其恢復成一個SRL結(jié)構(gòu)。
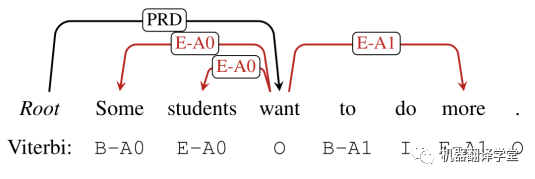
然而,在實際中,所生成圖有可能會包含沖突。如上圖所示的一個例子,紅色的邊包含了沖突關系。如果兩條邊都被標記為“E-*”,其將不可能恢復為相應的論元。另外一個沖突為,僅僅存在一個單獨的邊標記“B-*”或“E-*”,比如上圖中的“E-A1”。
約束Viterbi
該工作使用一個約束解碼方法來解決對應的沖突。在恢復一個論元的過程中,如果發(fā)生沖突,則重新標記句子中所有的謂詞。但是,將約束Viterbi應用于SDGP框架中并不簡單。
拿BES方案舉例來說(其他方案對應的處理過程也是類似的),在第一階段中,表示這個該邊在最終圖中存在的概率;但是在第二階段中,表示這個邊被標記為的概率。可以看出沒有包含“I”和“O”,二者分別表示這個詞分別在一個論元或者不在任何論元中,在這個序列標注過程中它們是不可缺少的。
為了解決該問題,該工作添加兩個偽標簽“O/I”到標簽集合中,并重新分配標簽的概率分布:
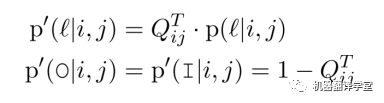
這里,是類似“B-A0”這些標準標簽的概率。由于“O”和“I”意味著沒有邊指向這個詞,所以和的概率相同,但是“I”有一個額外的含義:左邊有一個不成對的“B-*”。因此,可以通過控制轉(zhuǎn)換矩陣來解決沖突。
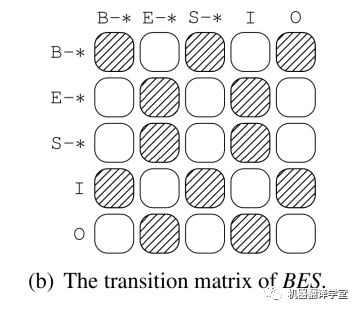
如上圖,不允許從“E-*”到“E-*”的轉(zhuǎn)換。所以上述例子中的“Some”和“students”的標簽要重新進行標記為“B-A0”和“E-A0”。最終,得到了語義角色為“A0”的論元span“Some students”。
-04-
實驗
該論文在CoNLL05和CoNLL12兩個數(shù)據(jù)集上進行了實驗。作者首先在CoNLL05數(shù)據(jù)集上面測試了四種構(gòu)建方案。結(jié)果如下表所示,從整體上來看,我們可以得到結(jié)論:BES > BE > BIES > BII。
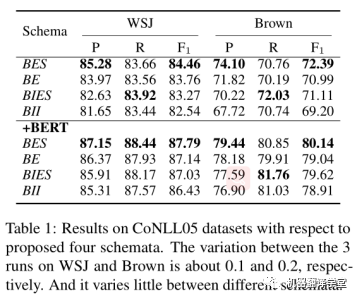
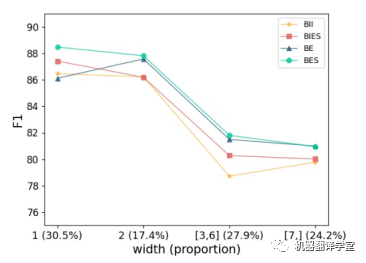
如下圖所示,作者根據(jù)論元的寬度將論元分為四類,給出了每個類別在真實答案數(shù)據(jù)中的比例,并報告每一類的F1值。首先,可以看到BES和BIES在1-width論元上要好得多。這表明,用“S-r”單獨表示寬度為1的論元是必要的。然后,可以發(fā)現(xiàn)BE和BES在包含多個單詞的論元上比BII和BIES表現(xiàn)更好。我們知道BE和BES是邊界附加策略的結(jié)果,它更關注邊界信息。因此,可以得出結(jié)論,邊界信息對多詞論元的識別更有幫助。
同時,作者還測試了該論文所提方法與其他方法推理速度的對比,結(jié)果如下表所示。該論文所提出的方法相比之前基于span的SRL模型,推理效率得到大幅度提高。

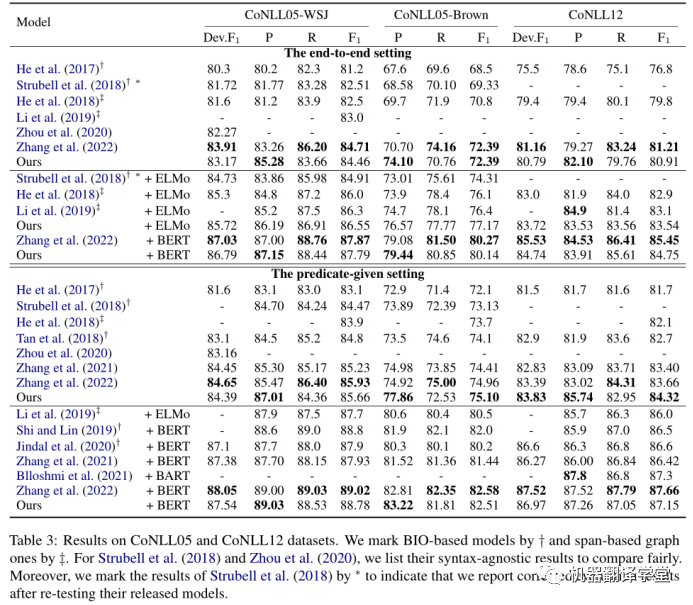
最后,作者還將該論文的方法分別在CoNLL05和CoNLL12兩個數(shù)據(jù)集上面與其他同類型方法進行對比。結(jié)果如下表所示。
-05-
總結(jié)
該論文提出了四種新的圖表示方案,用于將原始的基于span的SRL結(jié)構(gòu)轉(zhuǎn)換為基于word的圖。基于此方案,該論文將基于span的SRL轉(zhuǎn)換為一個基于word的圖解析任務,并得到了一個更快更準的解析器。此外,作者還提出了一種簡單的基于約束Viterbi的后處理方法來處理輸出圖中的沖突。實驗表明,該論文提出的解析器:1)相比之前的解析器效率大幅度提高,每秒可以解析600多個句子;2)在CoNLL05和CoNLL12數(shù)據(jù)集上的性能始終優(yōu)于之前的結(jié)果。對四種方案的深入對比表明,邊界信息在識別論元時起著重要作用。此外,區(qū)分單詞論元和多詞論元也可以提高最終的性能。這些發(fā)現(xiàn)可能有助于研究人員在未來從新的角度思考SRL。
-
BIO
+關注
關注
0文章
6瀏覽量
9476 -
數(shù)據(jù)集
+關注
關注
4文章
1224瀏覽量
25530 -
nlp
+關注
關注
1文章
490瀏覽量
22655 -
訓練模型
+關注
關注
1文章
37瀏覽量
3975
原文標題:COLING'22 Best Paper | 蘇大提出:又快又準的端到端跨語義角色標注作為基于詞的圖解析
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
PAD貼片電阻識別標注方法
科學數(shù)據(jù)時間序列的預測方法
DNA片段拼接中的預歸并重復序列屏蔽方法
基于運行序列的軟件故障診斷方法
AutoCAD內(nèi)常用術語的自動標注方法
音箱功率的標注方法
貼片電阻阻值標注方法詳解
新聞圖像人臉標注方法
NLP:序列標注
汽車電路圖的標注及閱讀方法
基于強化學習的壯語詞標注方法
基于序列標注的實體識別所存在的問題
焊接符號標注實例及方法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論