 圖模型在方面級情感分析任務中的應用
圖模型在方面級情感分析任務中的應用

引言
方面級情感分析(Aspect-based Sentiment Analysis, ABSA)是一項細粒度的情感分析任務,主要針對句子級別的文本,分析文本中相關的方面項(Aspect Term)、觀點項(Opinion Term)、方面類別(Aspect Category)和情感極性(Sentiment Polarity),在不同的場景下對應著不同的子任務。
本次Fudan DISC實驗室將分享ACL 2022中關于方面級情感分析的三篇論文,其中兩篇介紹基于圖模型的方面級情感分析研究,一篇介紹用生成的方法進行ABSA的相關研究。
文章概覽
BiSyn-GAT+: 用于方面級情感分析的雙重語法感知圖注意網絡(BiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis)
論文地址:https://aclanthology.org/2022.findings-acl.144.pdf
該篇文章提出了一種雙語法感知圖注意網絡(BiSyn-GAT+),利用句子的短語結構樹和依存結構樹來建模每個方面詞的情感感知上下文(稱為上下文內)和跨方面的情感關系(稱為上下文間) 信息,首次在ABSA任務中引入了句子的短語結構樹的語法信息,四個基準數據集的實驗表明,BiSyn-GAT+ 始終優于最先進的方法。
用于方面情感三元組提取的增強多通道圖卷積網絡(Enhanced Multi-Channel Graph Convolutional Network for Aspect Sentiment Triplet Extraction)
論文地址:https://aclanthology.org/2022.acl-long.212.pdf
該篇文章旨在抽取句子中的情感三元組,提出了一個增強多通道圖卷積網絡模型來充分利用單詞之間的關系。該模型為 ASTE 任務定義了 10 種類型的關系,通過將單詞和關系鄰接張量分別視為節點和邊,將句子轉換為多通道圖,從而學習關系感知節點表示,同時設計了一種有效的詞對表示細化策略,顯著提高了模型的有效性和魯棒性。
Seq2Path:生成情感元組作為樹的路徑(Seq2Path: Generating Sentiment Tuples as Paths of a Tree)
該篇文章提出了 Seq2Path 來生成情感元組作為樹的路徑,通過生成的方法來解決ABSA中的多種子任務。樹結構可以用于表示“1對n”的關系,并且樹的路徑是獨立的并且沒有順序。通過引入額外的判別標記并應用數據增強技術,可以自動選擇有效路徑,從而解決ABSA中常見的五類子任務。
論文細節

動機
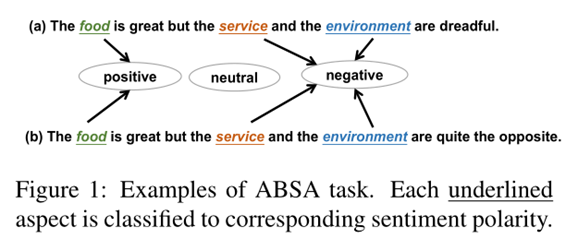
該篇文章中的ABSA旨在識別句子中給定方面的情感極性。之前的許多工作主要是用有注意力機制的RNN、CNN提取序列特征,這些模型通常假設更接近目標方面詞的單詞更可能與其情緒相關。但這種假設很可能并不成立,在圖1中可以看到,“service”更接近“great”而不是“dreadful”,所以這些方法可能會錯誤地將不相關的意見詞“great”分配給“service”,導致情感判斷錯誤。
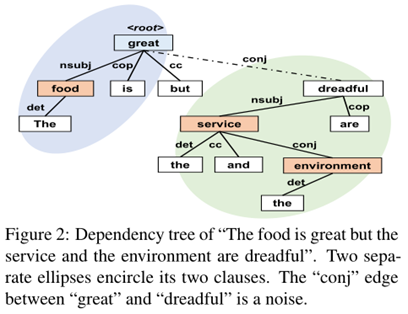
近期的工作主要研究如何通過GNN利用依存結構樹等非序列信息來建模方面詞,然而依存結構樹的固有性質可能會引入噪聲,如圖 2中“great”和“dreadful”之間的“conj”關系,conjunct表示連接兩個并列的詞,這可能會影響到對great和dreadful的建模,即上下文內建模,此外,依存結構樹僅僅揭示了單詞之間的關系,因此在大多數情況下無法模擬句子間的復雜關系,例如條件、協同、反義等關系,也就無法捕捉方面詞之間的情感關系,即上下文間建模。
基于以上的兩個發現,在本文中,作者考慮利用短語結構樹的句法信息來解決這兩個問題。短語結構樹中通常包含短語分割和分層組合結構,有助于正確對齊方面和表示方面情感的單詞。前者可以自然地將一個復雜的句子分成多個子句,后者可以區分方面詞之間的不同關系來推斷不同方面之間的情感關系。
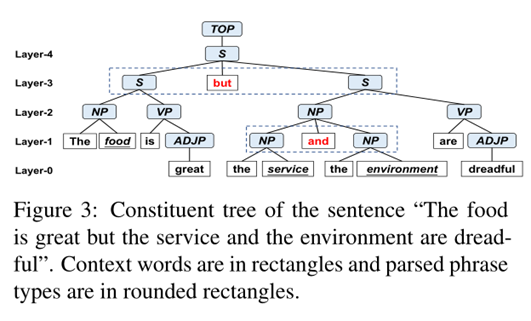
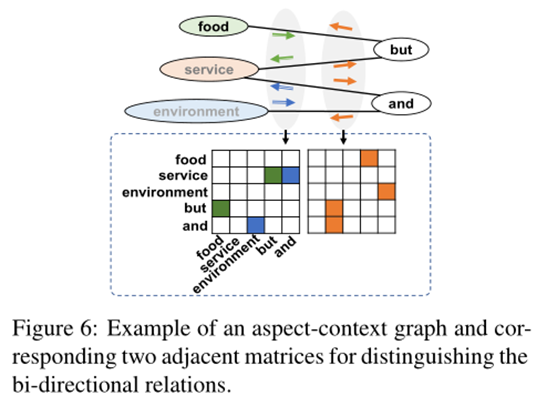
如圖 3 所示,“but”等短語分割詞可以很自然地將原句切分為兩個子句,同時,在Layer-1中,“and”可以體現出“service”和“environment”的協同關系,而Layer-3中的“but”可以體現出“food”和“service”或“environment”之間的反義關系。
任務定義
在給定方面詞,判斷情感極性的設定中,表示長度為的句子,表示預定義的方面詞集合。對于每個句子,表示句子中包含的方面詞,任務目標就是輸入句子和句子中的若干方面詞,得到每一個對應的情感極性。
模型
本文提出的模型如圖4所示:
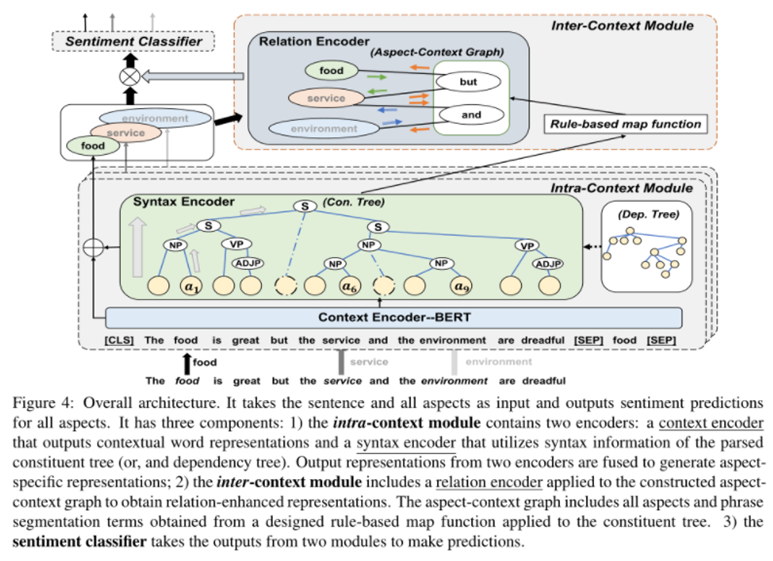
該模型以句子和文本中出現的所有方面詞作為輸入,輸出方面詞的預測情感。其中一共包含三個組件:
一是上下文內模塊(Intra-Context Module),對輸入文本進行編碼以獲得針對目標方面詞的方面特定表示,其中包含兩個編碼器,分別是上下文編碼器和利用短語結構樹和依存結構樹中句法信息的句法編碼器。
二是上下文間模塊(Inter-Context Module),其中包含一個關系編碼器,用于從構建的方面-上下文圖中得到關系增強的表示,方面-上下文圖是由給定句子的所有方面詞以及短語分割項組成,短語分割項是通過規則方法從短語構成樹中得到的。
三是情感分類器,綜合利用上述兩個模塊的輸出表示預測情感。
1. 上下文內模塊
上下文內模塊利用上下文編碼器和句法編碼器對每個方面詞的情感感知上下文進行建模,并為每個目標方面詞生成方面特定表示。對于多方面詞的句子將多次使用此模塊,每次處理一個目標方面詞。
上下文編碼器利用BERT進行編碼,輸入序列如式1所示,經過BERT可以得到如式2所示的文本表示,由于BERT分詞后每個單詞可能被拆分為多個子詞,因此通過式3對多個子詞的表示取平均,得到每個單詞對應的文本表示。句法編碼器由幾個分層圖注意力塊堆疊而成,每個塊中由多個圖注意力層組成,這些層在短語結構樹和依存結構樹上對句法信息進行分層編碼,關鍵在于圖的構建。
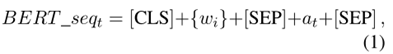
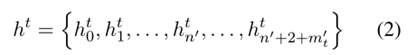
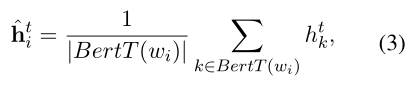
根據短語結構樹的句法結構,本文以自底向上的方式進行編碼,短語結構樹的每一層由組成輸入文本的幾個短語組成,每個短語代表一個獨立的語義單元。
例如,圖3中的就是{The food is great, but, the service and the environment are dreadful},根據這些短語,可以通過式4構造顯示單詞連接的鄰接矩陣CA,如果兩個單詞在該層的同一短語中,則矩陣對應位置為1,否則為0。具體的模塊圖如圖5所示,左邊這一列就是得到的鄰接矩陣CA。

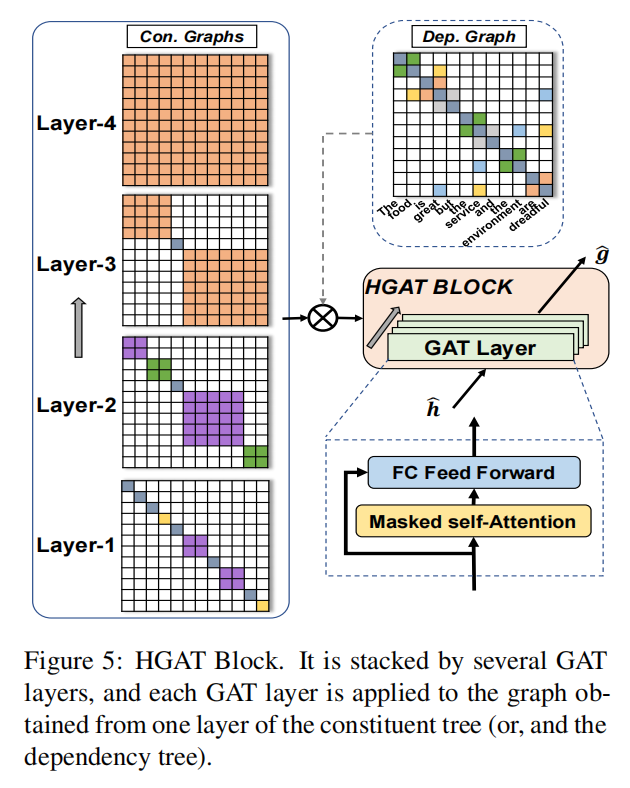
接著介紹 HGAT 塊,一個 HGAT 塊由幾個 GAT 層堆疊,這些 GAT 層利用掩碼自注意力機制聚合來自鄰居的信息,并使用全連接層將表示映射到相同的語義空間。注意力機制可以分配給具有更多相關詞的鄰居更高的權重。其表示如式 5,6,7 所示,其中表示第層中的鄰居集合,是衡量兩個詞相關性的評分函數,式 7 就是將層中兩個詞之間的相關性進行歸一化得到第 l 層中使用的權重,式 6 中的是經過掩碼自注意機制后的表示。
||表示向量連接。是注意力頭的數量。是第層中的最終表示,式 5 就是將層中的最終表示和層中經過掩碼自注意機制后的表示拼接起來再過一個全連接層。堆疊的 HGAT 塊將前一層塊的輸出作為輸入,第一個 HGAT 塊的輸入是式 3 中得到的。
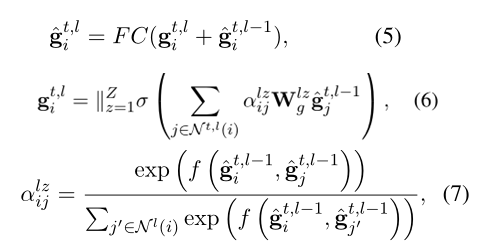
本文還探索了結構和依存兩種句法信息的融合,可以將依存結構樹視為無向圖并構造鄰接矩陣 DA,如果兩個詞在依存結構樹中直接連接,那矩陣中的元素為1,否則為0。通過逐位點乘、逐位相加和條件逐位相加三種方式拼接兩個矩陣信息。最終上下文內模塊的輸出如式12所示,包含了上下文信息和句法信息。
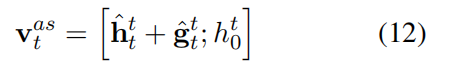
2. 上下文間模塊
上下文內模塊中沒有考慮方面詞之間的相互影響。因此,在上下文間模塊中,本文構建了一個方面-上下文圖來對各方面詞之間的關系建模。該模塊僅適用于多方面詞句子,將來自上下文內模塊的所有方面詞的方面特定表示作為輸入,并輸出每個方面詞的關系增強表示。
方面詞之間的關系可以通過一些短語分割詞來表示,比如連詞。因此,本文設計了一個基于規則的映射函數 PS,可以返回兩個方面詞的短語分割詞。具體來說,給定兩個方面詞,PS函數首先在短語結構樹中找到它們的最近共同祖先(LCA),它包含兩個方面詞的信息并且具有最少的無關的上下文。我們將來自 LCA 的,在兩個方面分開的子樹之間的分支,稱為“Inner branches”。PS函數就會返回“Inner branches”中的所有文本詞。否則將返回輸入文本中兩個方面詞之間的單詞。在圖3中,給定方面詞food和service,LCA節點是第四層中的S,具有三個分支,此時的inner branch就是中間的but,反映兩個方面詞之間的情感關系。
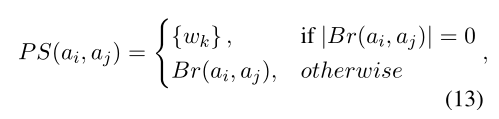
在方面上下文圖構建中,本文認為一個方面詞的影響范圍應該是連續的,方面詞之間的相互影響會隨著距離增加而衰減,考慮所有方面對會引入由長距離引起的噪聲并增加計算開銷,所以本文只對相鄰的方面詞之間的關系進行建模。在通過 PS 函數得到相鄰方面詞之間的短語分割詞后,本文通過將方面詞與相應的短語分割詞相連接以構建方面上下文圖。為區分方面上下文之間的雙向關系,本文構建了兩個對應的鄰接矩陣。第一個處理句子中所有奇數索引方面詞到相鄰的偶數索引方面詞的影響,第二個反之。用之前從上下文內模塊中學到的和經過BERT編碼的短語分割詞為輸入,將上述介紹的HGAT塊作為關系編碼器,輸出為每個方面詞對應的關系增強表示。
將上下文內模塊和上下文間模塊的輸出組合起來形成最終表示,然后將其送入全連接層,即情感分類器中,得到三種情感極性的概率。損失函數就是情感標簽和預測結果之間的交叉熵損失。
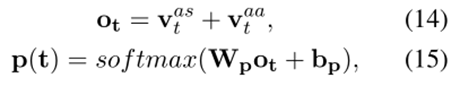
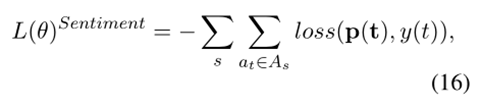
結果
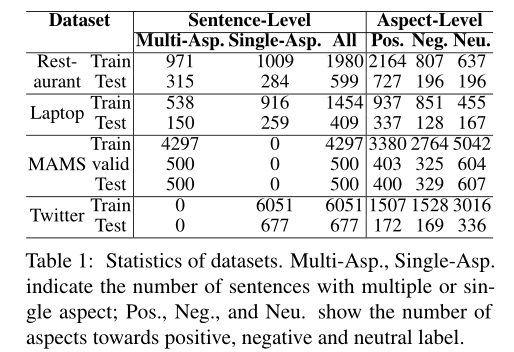
本文的實驗在四個英文數據集上進行,分別是SemEval2014的laptop、restaurant和MAMS、Twitter數據集。其中laptop和restaurant數據集中的句子有包含多方面詞的,也有包含單方面詞的。MAMS 中的每個句子至少包含兩個不同情感的方面詞。Twitter中的句子只包含一個方面詞。數據集統計數據如表 1 所示。
解析器使用SuPar,利用CRF constituency parser (Zhang et al., 2020)得到短語結構樹,利用deep Biaffine Parser (Dozat and Manning, 2017)得到依存結構樹。
Baseline一共分為三組,分別是無句法信息的基線模型,有句法信息的基線模型和建模了方面詞之間關系的基線模型。

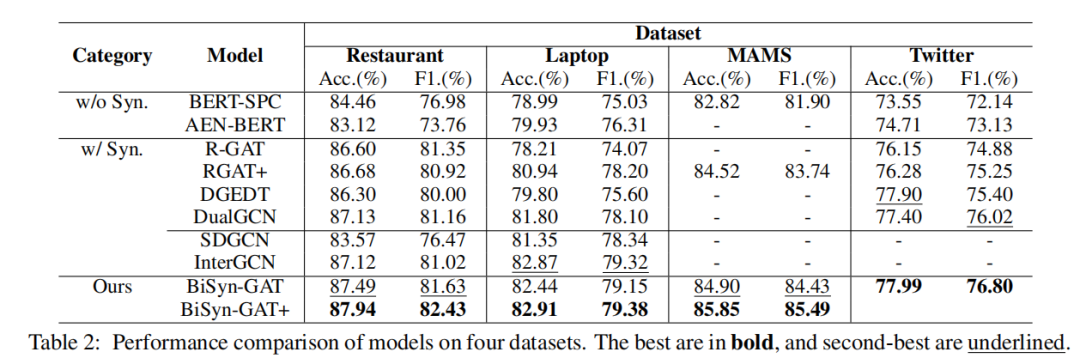
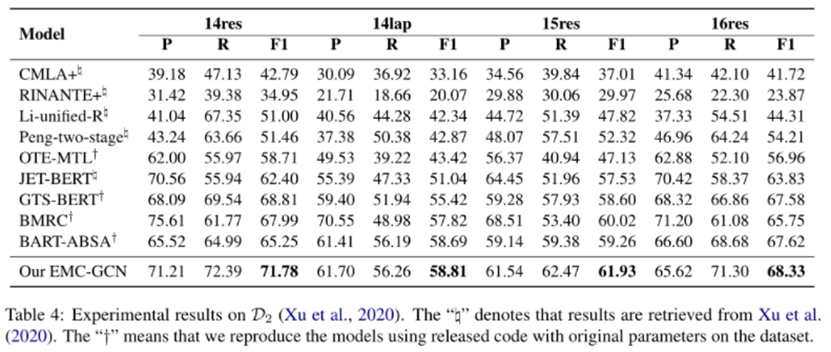
最終的實驗結果如表2所示,本文的完整模型有一個加號,沒有加號的是去掉上下文間模塊后的模型。本文提出的模型要優于所有基線模型。具有句法信息的模型要優于沒有句法信息的模型,本文的模型優于僅使用依賴信息的模型,說明組成樹可以提供有用的信息。從最后兩行的比較中可以看出,建模方面詞之間的關系可以顯著提高性能。
此外,作者還做了許多消融實驗,探索了模型中各個模塊的作用,比較了不同解析器帶來的影響和不同的方面上下文圖構建方式帶來的影響,最終的結果就是每個模塊都有其用處,把各類模塊都加上得到的結果才是最優的。
2

動機
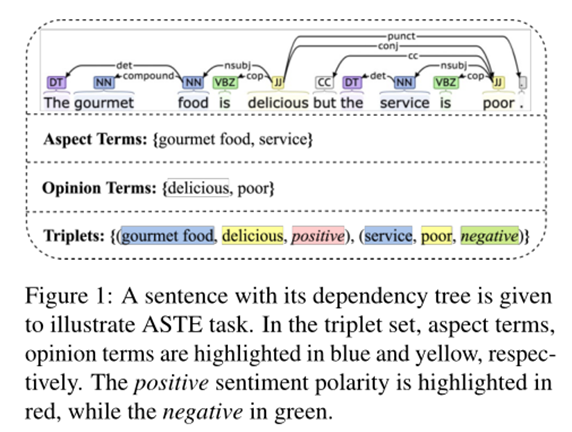
情感三元組抽取任務旨在從句子中提取方面情感三元組,每個三元組包含三個元素,即方面詞、觀點詞以及對應情感。如圖1所示,藍色代表方面詞,黃色代表觀點詞,紅色和綠色表示情感,輸入為句子,期待的輸出為下面的三元組。先前的方法主要為Pipeline方法,或者將其建模為多輪閱讀理解任務,再或者通過新的標注方案進行聯合抽取來解決。盡管之前的工作取得了顯著成果,但仍然存在一些挑戰。
在ASTE任務中,很自然地會面臨兩個問題,一是如何利用單詞之間的各種關系來幫助 ASTE 任務,詞對(“food”,“delicious”),“food”是“delicious”的觀點目標,被賦予了積極的情感極性,需要基于單詞之間的關系來學習任務相關的單詞表示。二是如何利用語言特征來幫助 ASTE 任務,可以觀察到方面詞通常是名詞,觀點詞通常是形容詞,因此名詞和形容詞組成的詞對往往形成方面-觀點對,從句法依存樹的角度觀察,food是delicious的名詞性主語,依存類型為nsubj,說明不同的依存類型可以幫助方面詞、觀點詞的抽取和匹配。基于以上兩點觀察,本文提出了一種增強多通道圖卷積網絡模型來解決上述問題,設計了十種單詞關系來建模單詞之間的關系概率分布,充分利用了四種語言特征并細化詞對表示。
任務定義
給定一個輸入句子,包含個單詞,目標是從中抽取出一批三元組,其中和分別表示方面項和意見項,表示情感極性。
除了任務形式定義,本文為 ASTE 定義了句子中單詞之間的十種關系,如表1所示。
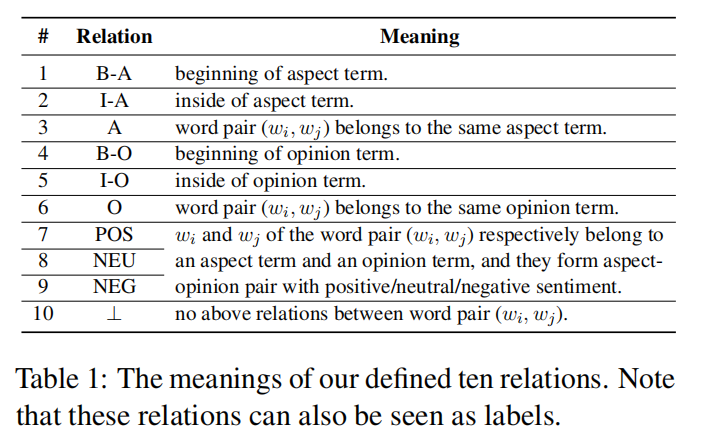
與前人的工作相比,本文定義的關系引入了更準確的邊界信息,其中的四個關系或標簽 {B-A, I-A, B-O, I-O} 旨在提取方面詞和意見詞,B 和 I 分別表示術語的開頭和內部。A 和 O 子標簽旨在確定詞語的作用,即為方面詞或意見詞。表 1 中的 A 和 O 關系用于檢測由兩個不同的詞組成的詞對是否分別屬于同一個方面或意見詞。三個情感關系檢測詞對是否匹配,同時判斷了詞對的情感極性,可以使用表格填充的方法構建關系表,圖3就是一個例子,每個單元格對應一個具有關系的詞對。

在得到表格后需要對其進行解碼,ASTE 任務的解碼細節如算法1所示。為簡單起見,此處使用上三角表來解碼三元組,因為是標準情況下關系是對稱的。首先僅使用基于主對角線的所有詞對之間的預測關系來提取方面詞和觀點詞。其次,需要判斷提取的方面詞和觀點詞是否匹配。具體來說,對于方面項和意見項,我們計算所有單詞對的預測關系,其中和。如果預測關系中存在任何情感關系,則認為方面詞和觀點詞是配對的,否則這兩個不配對。最后,為了判斷方面-觀點對的情感極性,將預測最多的情感關系視為情感極性。經過這樣的流程,可以收集到一個三元組。

模型
接著介紹一下本文提出的模型架構。首先利用BERT編碼輸入,接著利用一個biaffine attention模塊來對句子中單詞之間的關系概率分布進行建模,并使用一個向量來表示它。接著每種關系對應一個通道,形成一個多通道的GCN模型,同時,為增強模型,為每個詞對引入了四種類型的語言特征,并對biaffine 模塊中獲得的鄰接張量添加約束,最后利用方面和意見提取的隱含結果精煉詞對表示并進行分類。
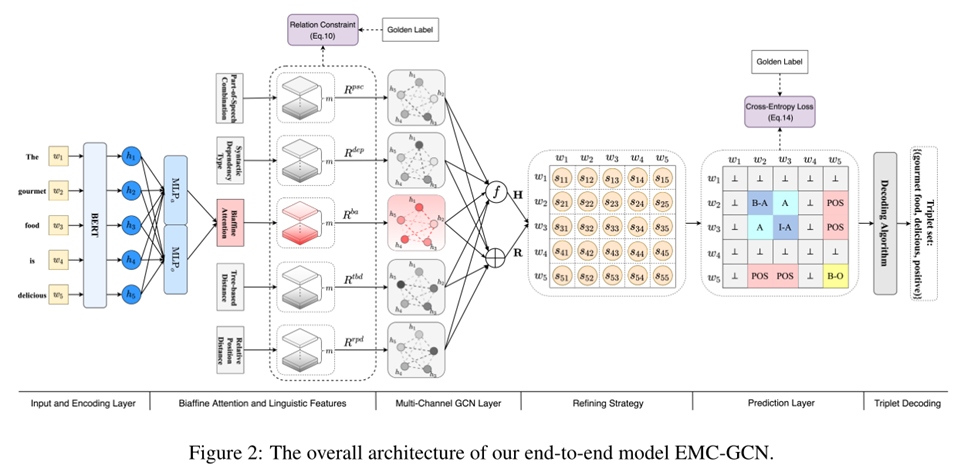
1.輸入與編碼層 & 雙仿射注意模塊
在輸入與編碼層,利用BERT 作為句子編碼器來提取隱藏上下文表示。接著利用Biaffine Attention模塊來捕獲句子中每個詞對的關系概率分布,其過程如式1234所示。經過BERT后的隱藏上下文表示經過兩個MLP層分別得到和,通過式3得到表示,其中的、和是可訓練的權重和偏差,中間的加號表示連接。表示詞對的第個關系類型的分數,這里就是做了一個歸一化。鄰接張量就是上面這個過程的矩陣化表示,其形狀為,為關系類型的數量,每個通道就對應著一個關系類型。
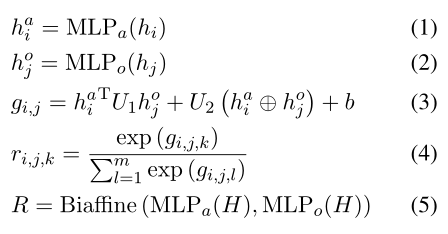
2. 多通道GCN
多通道的GCN模型則是沿著每個通道為Biaffine Attention 模塊得到的中的每個節點聚合信息。表示的第個通道切片,和是可學習的權重和偏差。是激活函數。是平均池化函數,可以將所有通道的隱藏節點表示聚合起來。

3. 語言特征
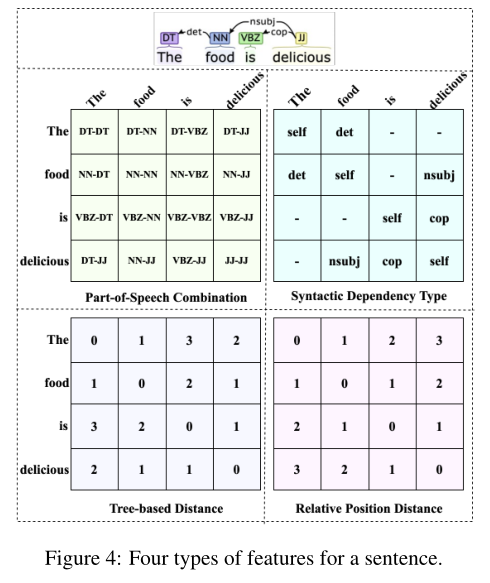
為增強EMC-GCN 模型,本文為每個詞對引入了四種類型的語言特征,如圖 4 所示,包括詞性組合、句法依賴類型、基于樹的距離和相對位置距離。對于句法依賴類型,需要為每個詞對添加一個自依賴類型。一開始隨機初始化這四個鄰接張量,以以句法依賴類型特征為例,如果和之間存在依賴弧,并且依賴類型為 nsubj,則通過一個可訓練的嵌入查找表,將初始化為 nsubj 的嵌入,否則用維零向量進行初始化。隨后,使用這些鄰接張量重復圖卷積操作以獲得節點表示、、和,最后分別將平均池化函數和連接操作應用于所有節點表示和所有邊。
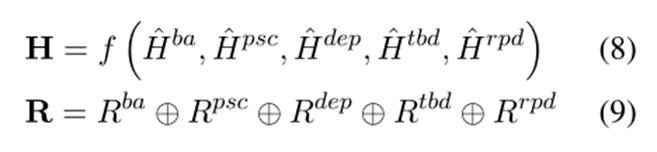
4.關系損失 & 細化策略
為了精確捕捉單詞之間的關系,我們對從 biaffine 模塊獲得的鄰接張量添加了一個損失,同樣,對語言特征產生的四個其他鄰接張量也添加了約束損失。
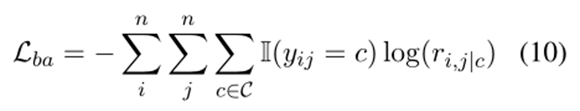
為了獲得用于標簽預測的詞對的表示,我們將它們的節點表示、和它們的邊表示連接起來。受多標簽分類任務中的分類器鏈方法啟發,在判斷詞對是否匹配時又引入了方面和意見提取的隱含結果,具體來說,假設是方面詞,是意見詞,那么詞對更有可能被預測為情感關系,因此引入了和來細化詞對的表示。最后將詞對表示輸入線性層,然后使用 softmax 函數生成標簽概率分布。
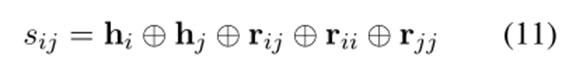

訓練時的損失函數如式13所示,其中的是用于ASTE任務的標準交叉熵損失函數,如式14所示,系數和用于調整對應關系約束損失的影響。
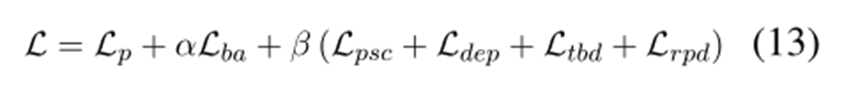
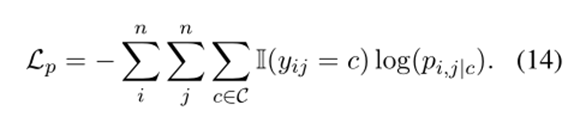
結果
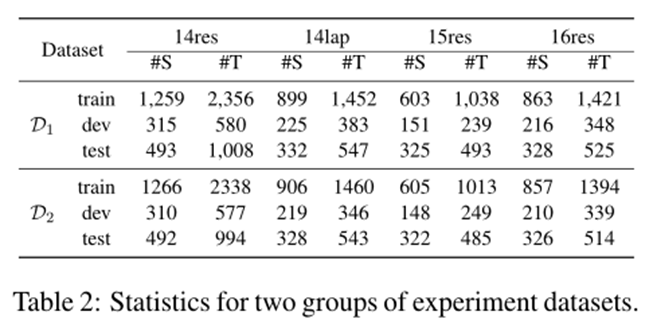
本文實驗的數據集也是在SemEval挑戰賽的數據集基礎上,D1由[Wu et al. (2020a)],D2由[Xu et al. (2020)]做了進一步的標注,這兩組數據集的統計數據如表2所示。
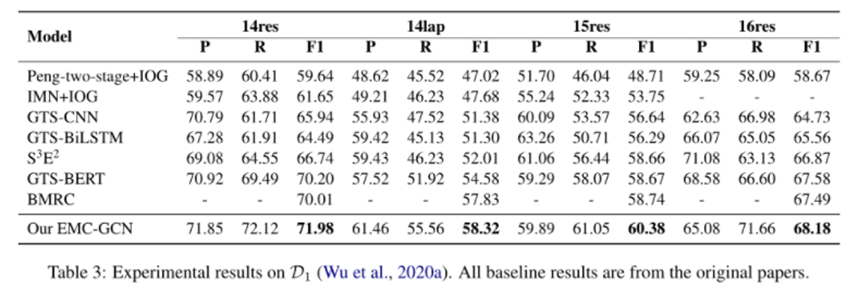
本文實驗比較的基線模型主要流水線模型、一些端到端方法的模型和基于機器閱讀理解的模型。

在 F1 指標下,EMC-GCN 模型在兩組數據集上優于所有其他方法。端到端和基于 MRC 的方法比流水線方法取得了更顯著的改進,因為它們建立了這些子任務之間的相關性,并通過聯合訓練多個子任務來緩解錯誤傳播的問題。
此外,文章還進行了一些消融實驗分析,實驗發現提出的十種關系和細化策略都對性能提升有幫助。作者通過可視化通道信息和語言特征信息,發現這些模塊都如預期一樣有效,有助于傳遞詞之間的信息,通過樣例分析對比其他模型,發現EMC-GCN模型可以更好地提取句子中的情感三元組。
3

動機
在本文中,作者以 ASTE 為默認任務來說明想法。ABSA任務方面最近的趨勢是設計一個統一的框架來同時處理多個 ABSA 任務,而不是為每個 ABSA 任務使用單獨的模型,如Seq2Seq 模型已被充分應用到其中。輸入文本后,輸出是一系列情感元組,但這種設計仍存在兩種問題,一是順序,元組之間的順序并不自然存在,二是依賴關系,的生成不應該以為條件。也就是說,為什么必須是第一個元組而不是?為什么后面必須跟而不是或結束符?
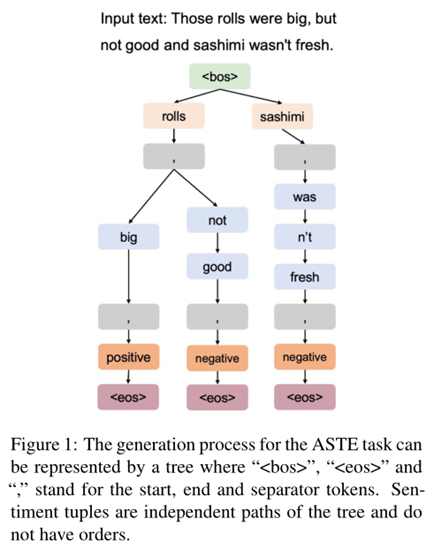
基于以上發現,作者認為樹結構是表示輸出的更好選擇。樹可以表示一對多的關系,其中一個token在生成期間其后可以跟隨多個有效token,而在序列中只能表示一對一的關系,一個token在生成期間其后緊跟一個token,也就是貪心的策略。如圖 1 中的示例,兩個情感元組(“rolls”、“big”、“positive”)和(“rolls”、“not good”、“negative”)共享相同的方面詞“rolls”,體現了一對多的關系。
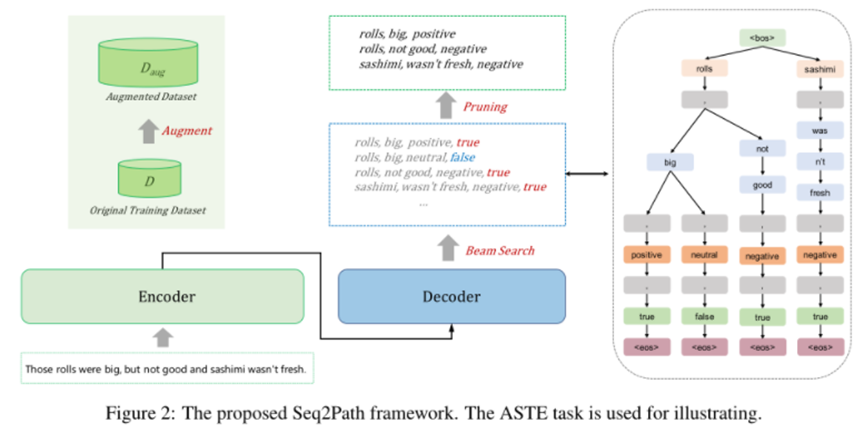
在本文中,作者將 ABSA 任務形式化為樹的路徑序列問題,提出了Seq2Path方法,其中的每個情感元組都是樹的路徑,可以獨立生成。只要給定輸入文本,就可以獨立確定任何有效的情感元組。例如,可以在不知道是一個有效的情感元組的情況下,確定是一個有效的情感元組。具體來說,在訓練時,將每個情感元組視為一個獨立的目標,使用普通的 Seq2Seq 模型來學習每個目標并計算平均損失。在推理時,使用Beam Search來生成多條路徑及其概率。此外,本文還引入了一個判別標記來自動從Beam Search中選擇正確的路徑,為數據集擴充了判別標記的負樣本數據。
任務定義
方面級情感分析的輸入為文本,在五個子任務上輸出的目標序列為:

其中,a表示方面項,o表示觀點項,s表示情感極性。
模型
Seq2Path的框架如圖2所示。里面的編碼器-解碼器架構就是普通的 Seq2Seq 架構,主要有以下幾點區別:一是每個情感元組將被視為一個獨立的目標,會訓練一個普通的 Seq2Seq 模型并計算平均損失。二是token的生成過程會形成一棵樹,將Beam Search用于并行和獨立地生成路徑。三是輸入是文本,輸出是帶有判別標記v的情感元組。由于判別標記沒有負樣本,因此還必須構建一個增強數據集進行訓練。
對于輸入句子,期望輸出一組元組,如前面所述,集合可以表示為一棵樹,其中的每個對應樹的一條路徑,就是路徑的總數。訓練的損失函數定義為這條路徑上的平均損失。就是普通的 Seq2Seq 損失,是每個時間步的損失。
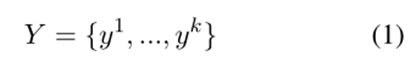
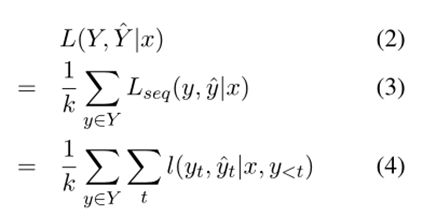
在推理階段,我們應用帶有約束解碼的束搜索方法。束搜索算法根據條件概率在每一步為輸入序列選擇多個備選方案。通過束搜索,我們輸出概率遞減的 top-k 路徑,這些路徑表示路徑有效的可能性。在解碼期間也使用約束解碼,不去搜索整個詞匯表,而是在輸入文本和任務特定標記中選擇token進行輸出。首先,我們刪除了一些重疊的預測,如果束搜索同時返回了“”和“”,選擇序列概率較高的那個。如果同時返回“”和““,其中和重疊,也選擇序列概率較高的那個。然后輸出判別標記為true的,過濾其他無效路徑。
由于判別標記沒有負樣本,因此數據增強步驟是必要的。為了自動選擇有效路徑,在每個負樣本的末尾附加一個判別標記 v = “false”。本文用以下兩種方式生成負樣本,D1數據集是為了提高模型匹配元組元素的能力,隨機替換元組中的元素,生成“rolls, was not fresh, positive, false”, “sashimi, big,negative, false”等。D2數據集是為提高模型過濾大部分不良泛化情況的能力,首先用幾個小epoch訓練模型,然后使用束搜索生成負樣本。增廣數據集就是正負樣本的并集。
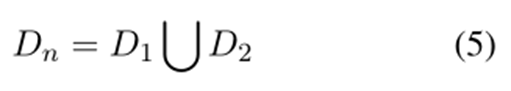
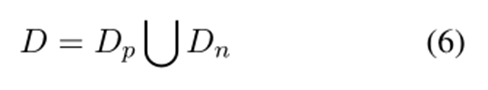
我們希望判別標記 v 能夠過濾無效路徑,又不希望模型的生成模仿負樣本,因此這里應用了一個技巧性的損失掩碼。假設,如果 y 是負樣本,即 y 的驗證標記為“false”,則損失掩碼為如式7所示,如果 y 是正樣本,即 y 的驗證標記為“true”,則損失掩碼如式8所示。損失掩碼意味著在損失計算中跳過了一些token,如下圖所示。除了判別令牌和“”令牌之外的所有令牌都被屏蔽。為帶有損失掩碼的損失,其中只有的標記參與損失計算,可以得到如式9所示的損失函數,最終數據集的總體損失如式10所示。
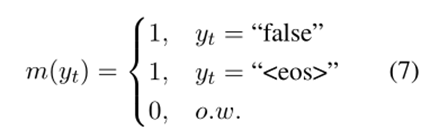
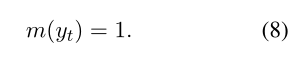
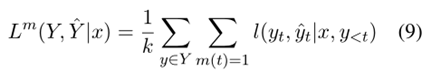
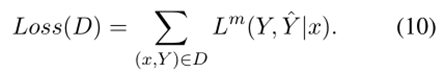
Seq2Path 的流程總結為算法1,首先生成負樣本數據進行數據增強。其次用普通的Seq2Seq方法訓練模型,使用損失掩碼。在推理時使用束搜索,生成前k條路徑并剪枝。

結果
該篇文章在四個廣泛使用的基準數據集上進行,分別為SemEval2014 Restaurant, Laptop,SemEval2015 Restaurant和SemEval2016 Restaurant,根據ABSA的不同子任務,采取了以下的基線方法進行比較。

整體的實驗結果如表2、3、4、5、6所示,總體而言,本文提出的方法幾乎所有子任務上的F1 分數都達到了SOTA。
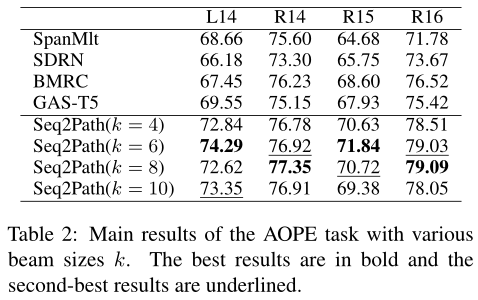
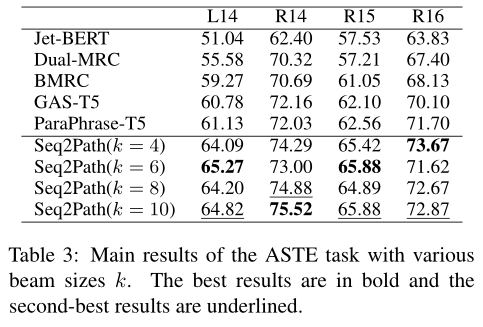
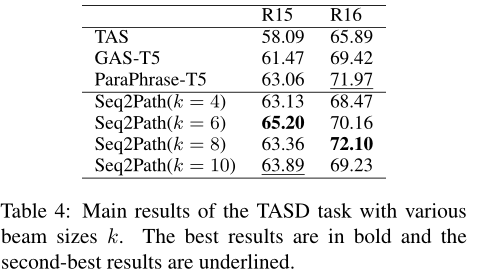
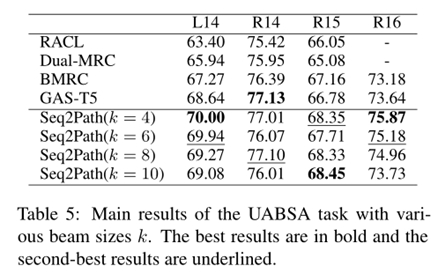
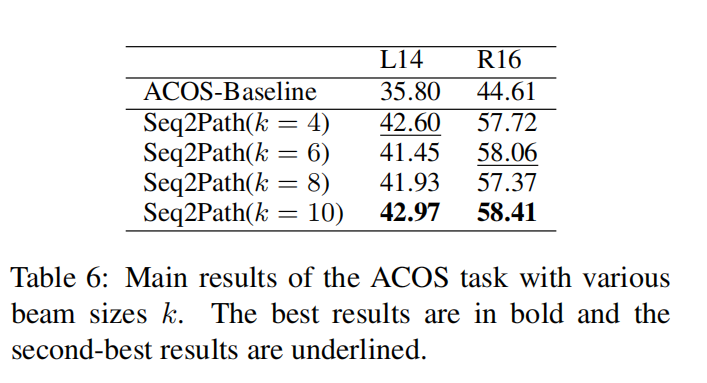
最后作者也進行了一些實驗分析。首先分析束尺寸對性能的影響,總體而言,較小的束尺寸會導致更差的召回率,較大的束尺寸會導致更差的精度。然而,通過剪枝過程,無論 k 的選擇如何,在前面幾張實驗表中得到的性能相比其他方法都是最優的,而最佳k的選擇則取決于任務和數據集。盡管束搜索需要更大的 GPU 內存,但 Seq2Path 可以使用更短的最大輸出序列長度,從而減少內存消耗。其次是數據增強的消融研究,數據集 D1 對 F1 分數的影響較小,數據集 D2 對 F1 分數有重大影響,說明利用少量epoch訓練得到的模型得到負樣本可以有效提高模型性能。
總結
此次 Fudan DISC 解讀的三篇論文圍繞方面級情感分析展開,介紹了圖模型在方面級情感分析任務中的應用,利用依存解析圖和句子結構圖,可以為建模方面表示提供更精細的信息。最后,本文還介紹了一種Seq2Path的模型,改善了先前Seq2Seq方法解決ABSA任務時面臨的順序、依賴等問題。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3793瀏覽量
137885 -
ACL
+關注
關注
0文章
61瀏覽量
12431 -
GAT
+關注
關注
0文章
7瀏覽量
6427 -
cnn
+關注
關注
3文章
354瀏覽量
22724
原文標題:ACL'22 | 基于圖模型的方面級情感分析研究
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大模型在半導體行業的應用可行性分析
TaskPool和Worker的對比分析
PID串級控制在同步發電機勵磁控制中的應用
FA模型卡片和Stage模型卡片切換
NVIDIA大語言模型在推薦系統中的應用實踐






 工商網監
工商網監
評論