 一文速覽醫學多模態進展
一文速覽醫學多模態進展

引言:目前,自然圖像-文本的多模態預訓練模型已經在各種各樣的下游任務上取得了非常好的效果,但是由于域之間的差異很難直接遷移到醫學領域。同時,獲取有標注的醫學圖像領域的數據集通常需要大量的專業知識和較高的成本,所以從對應的放射學報告中得到有效監督從而提高性能成為一種可能。本文主要介紹醫學的多模態模型的進展,這些模型方法在下游的分類、分割、檢索、圖像生成等任務上均取得了性能的提升。
Contrastive Learning of Medical Visual Representations from Paired Images and Text
http://arxiv.org/abs/2010.00747
這篇文章提出了ConVIRT框架,核心思想其實就是多模態的對比學習,是CLIP之前的工作,CLIP文中也有說受到ConVIRT的啟發,其使用其實的是ConVIRT的簡化版本。ConVIRT的整體架構如下:
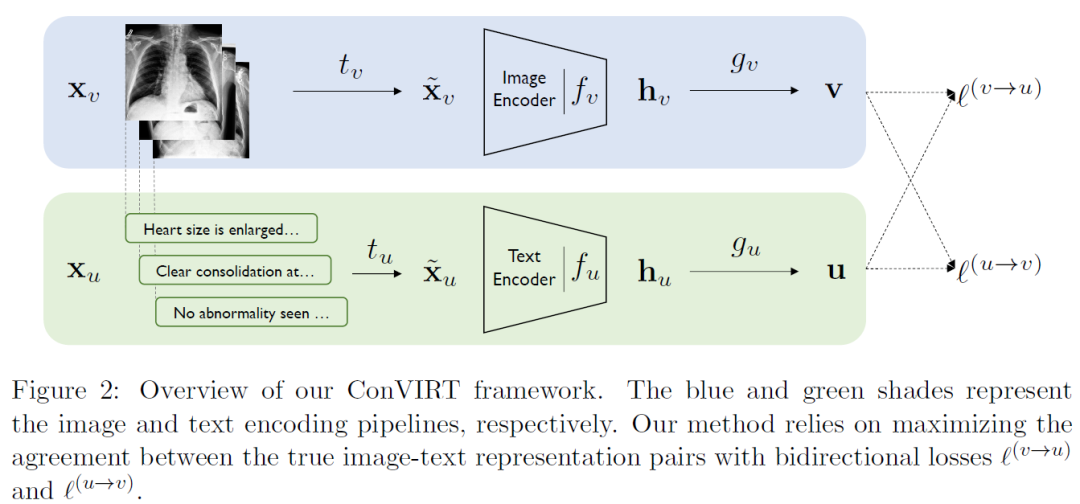
主要流程比較直觀:一張圖片先做隨機變換得到不同的視圖,然后進入Image Encoder,最后接一個非線性變化得到512維的特征表示;對與該圖片配對的放射學報告,首先進行隨機采樣得到其中的某句話,然后進入TextEncoder,最后通過得到512維的特征表示;最后分別對圖片和文本計算infoNCE loss。 GLoRIA: A Multimodal Global-Local Representation Learning Framework for Label-efficient Medical Image Recognition【ICCV2021】
https://ieeexplore.ieee.org/document/9710099/
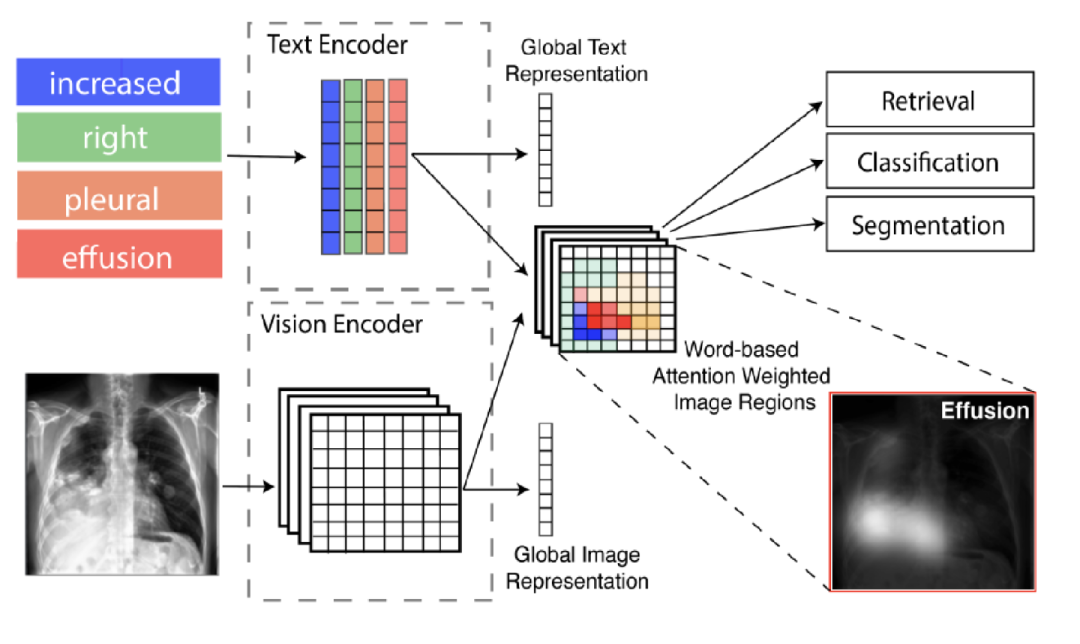
本文主要從全局和局部進行醫學圖像的表示學習,提出GLoRIA模型,主要使用注意機制,通過匹配放射學報告中的單詞和圖像子區域來學習圖像的全局-局部表示。其中創建上下文感知的局部圖像表示是通過學習基于特定單詞的重要圖像子區域的注意力權重。如下圖中基于單詞“effusion”(積液)得到的圖像區域積液的權重就比較大。
下圖是進行全局和局部學習的方法圖。給定一對醫學圖像和報告,首先使用圖像編碼器和文本編碼器分別提取圖像和文本特征。
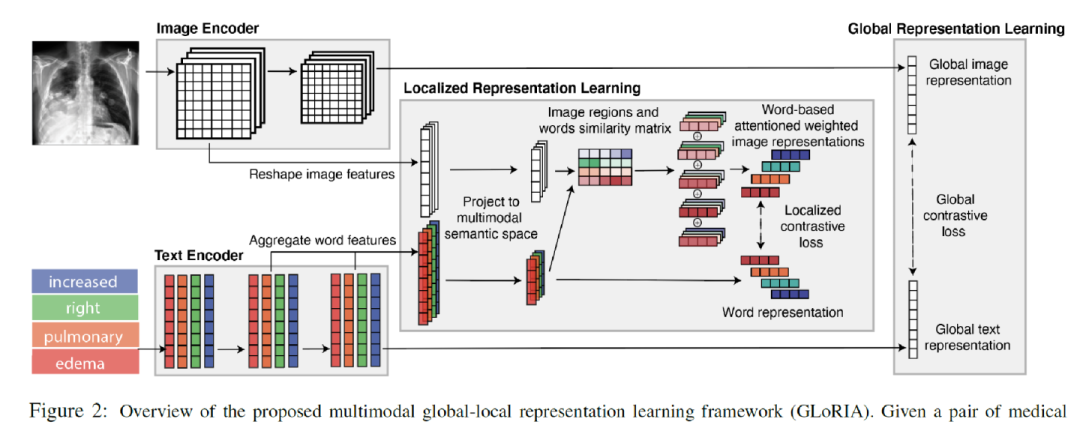
全局圖像-文本表示是通過全局對比損失進行學習的。為了學習局部表征,首先基于圖像子區域特征和詞級特征計算相似性矩陣,以生成注意力加權圖像表示(Attention weighted image representation)。首先計算文本和圖像特征的所有組合之間的點積相似性:
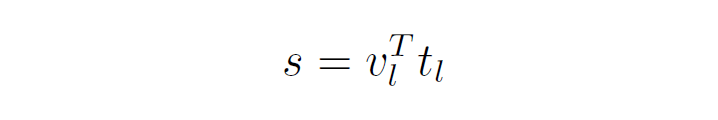
上式得到的表示的是個單詞和個圖像子區域的相似性矩陣,表示的就是第個單詞和第個圖像子區域之間的相似性。之后通過下面的softmax得到注意力權重:
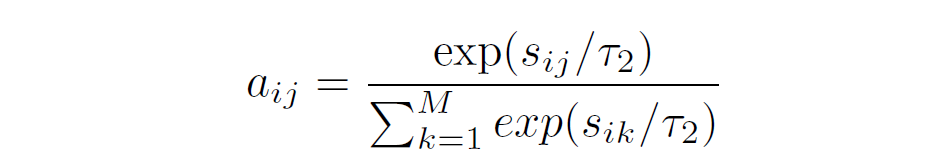
對于報告中的每個單詞,我們根據其與所有圖像子區域的相似性計算注意力加權圖像表示:
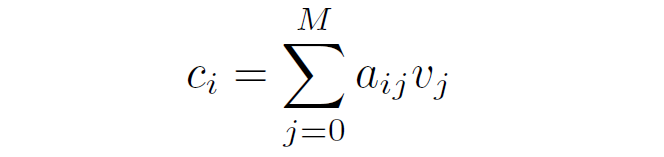
之后通過局部的對比損失來實現這一目標:使用函數計算單詞與其相應的注意力加權圖像特征之間的相似性。
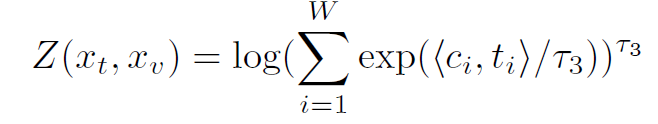
在給定詞表示的情況下,Local contrastive loss的目標是使注意加權圖像區域表示的后驗概率最大化:
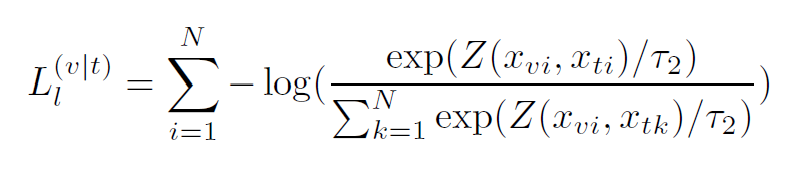
本文主要在圖像分類、檢索和分割上進行性能評估。其中分類和檢索也是結合全局和局部圖像文本相似性去實現的。具體來說:通過圖像和文本表示提取特征后,基于全局圖像和文本表示計算全局相似度;利用基于詞的注意加權圖像表示和對應的詞表示計算局部相似度。通過全局相似度和局部相似度的平均得到最終的圖像文本相似度。
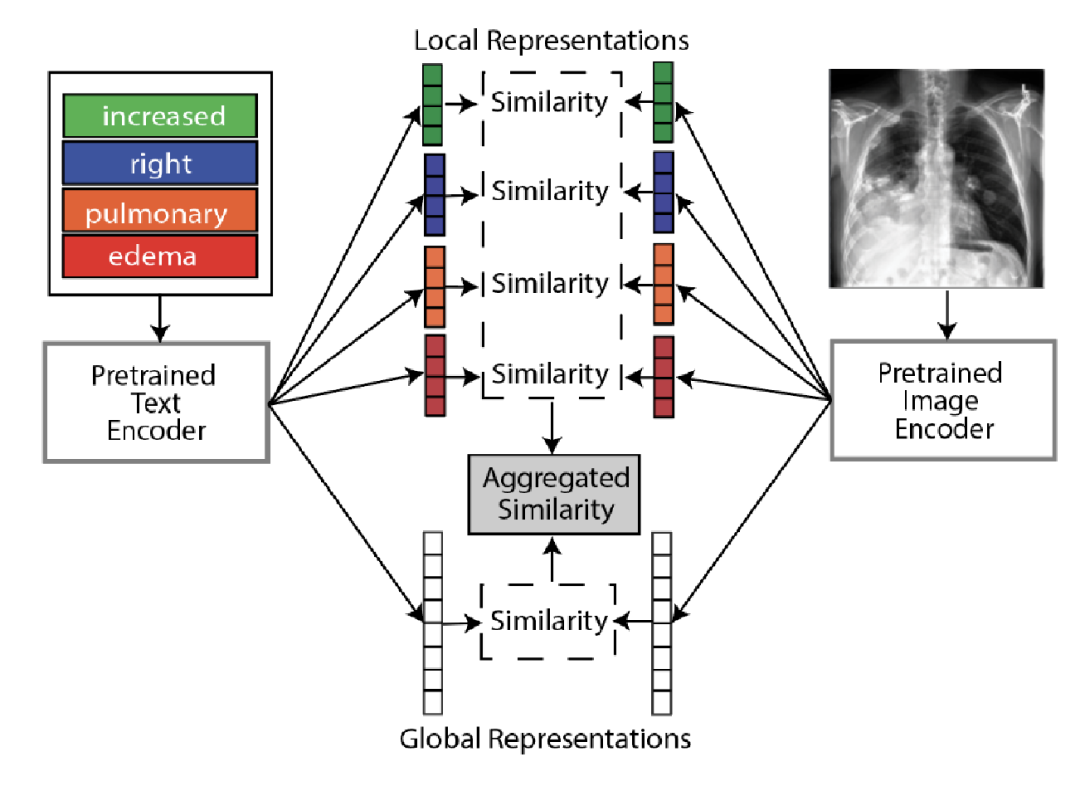
但對于分類來說,其沒有具體的文本表示,GLoRIA的做法是預生成合理的文本,以描述分類類別中每種疾病子類型、嚴重程度和位置。通過隨機組合子類型、嚴重性和位置的可能單詞生成文本提示來作為每個分類類的文本。 MedCLIP: Contrastive Learning from Unpaired Medical Images and Text【EMNLP 2022】
http://arxiv.org/abs/2210.10163
這篇文章提出了MedCLIP模型,出發點一方面是醫學圖像文本數據集比互聯網上的一般圖像文本數據集要少幾個數量級,另一方面是以前的方法會遇到許多假陰性,即來自不同患者的圖像和報告可能具有相同的語義,但被錯誤地視為負樣本。所以MedCLIP通過將圖片文本對進行解耦然后進行對比學習,通過引入外部醫學知識而減少假陰性。
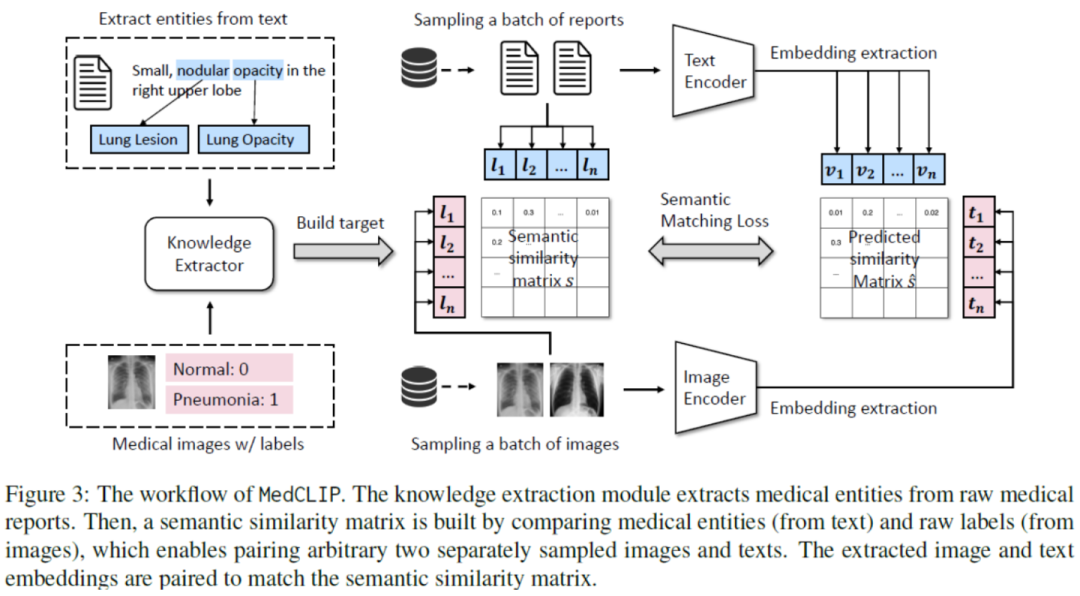
假設有個成對的圖像文本樣本、個標記的圖像和個醫學句子。以前的方法只能使用對樣本,但MedCLIP將個圖像文本對分別解耦為個圖像和個句子。最終能夠通過遍歷所有可能的組合來獲得圖像文本對,所以這樣就可以得到倍的監督信號。 為了完成額外的監督,MedCLIP利用外部醫學知識來構建知識驅動的語義相似性。這里MedCLIP使用了外部工具MetaMap,MetaMap是可以從原始句子中提取統一醫學語言系統(UMLS)中定義的實體。遵循之前工作的做法,主要關注14種主要實體類型。同樣,對于帶有診斷標簽的圖像,也是利用MetaMap將原始類映射到UMLS概念,從而與文本中的實體對齊,例如,“Normal”映射到“No Findings”。接下來就可以從提取的圖像和文本實體中構建multi-hot向量,分別為和。因此,通過這種方式統一了圖像和文本的語義。對于任何圖像和文本,MedCLIP就可以通過比較相應的和來衡量它們的語義相似性。 MedCLIP通過構建的語義標簽和來連接圖像和文本,首先可以得到soft targets:
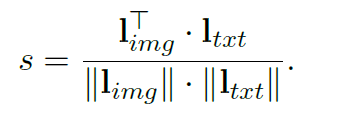
表示的就是醫學語義的相似性。對圖片和文本分別進行softmax:
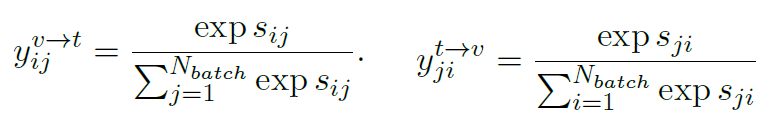
另外我們也可以通過直接將圖像和文本特征計算余弦相似性得到logit,同樣進行softmax處理:
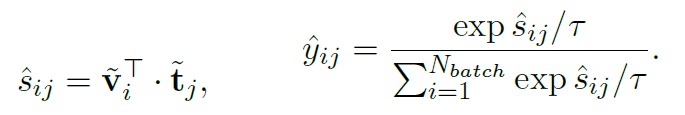
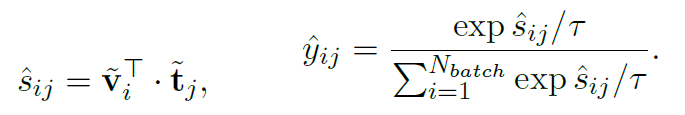
因此,Semantic Matching Loss是logits和soft targets之間的交叉熵:
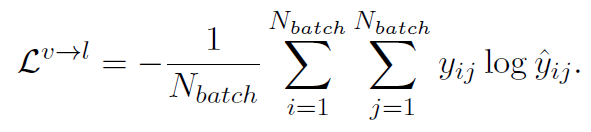
Multi-Granularity Cross-modal Alignment for Generalized Medical Visual Representation Learning【NIPS 2022】
http://arxiv.org/abs/2210.06044
這篇文章提出MGCA框架,通過多粒度跨模態對齊學習通用醫學視覺表示。如下圖所示,醫學圖像和放射學報告會在不同層級自然而然表現出多粒度語義對應關系:疾病層級、實例層級和病理區域層級。
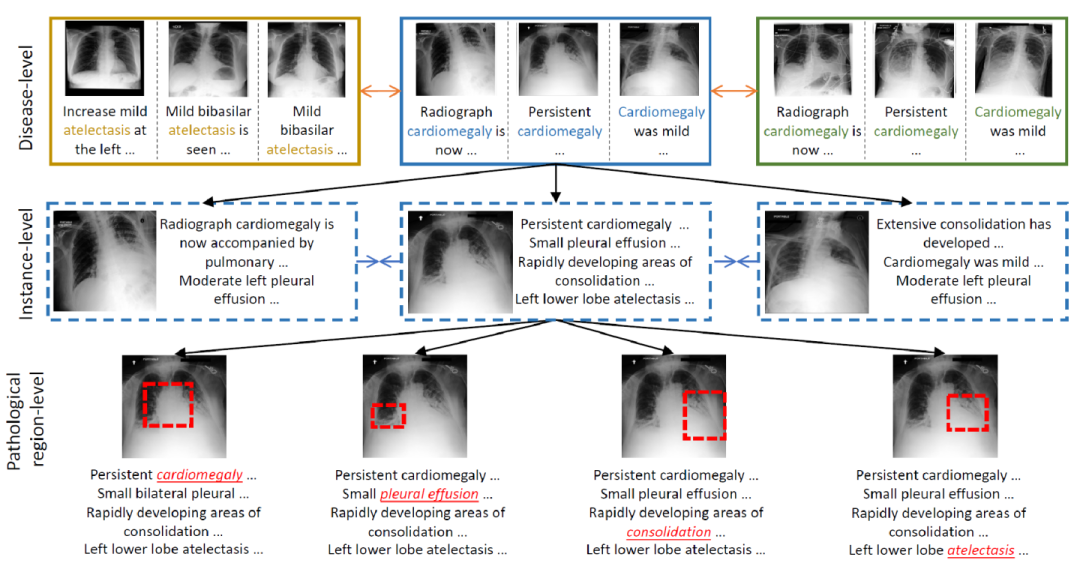
圖像和文本首先分別經過圖像和文本編碼器,得到一系列token表示,然后通過下面三個模塊實現三個粒度的對應:
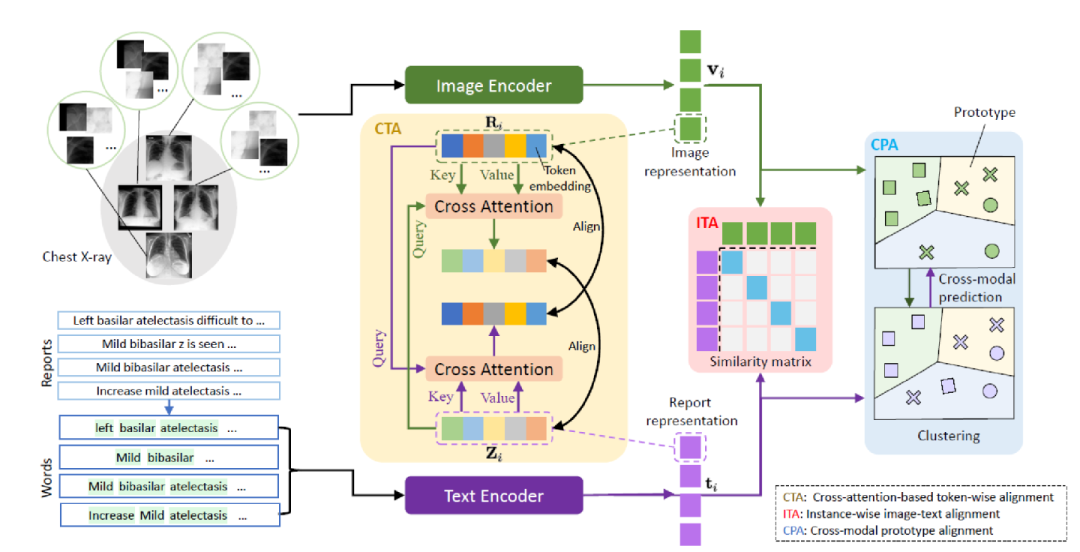
Instance-wise Image-Text Alignment (ITA):進行實例級別的對齊,即圖像文本的對比損失。 Cross-attention-based Token-wise Alignment (CTA):基于交叉注意力機制的token級別的對齊。這個模塊的出發點對應到前面的病理區域級別,用CTA模塊來顯式匹配和對齊局部的醫學圖像和放射學報告。思路是進行token級別的對齊,使用交叉注意計算生成的視覺和文本token之間的一個匹配。形式上,對于第個圖像文本對中的第個視覺token,我們讓去和對應的文本中的所有token計算其對應的跨模態文本嵌入,看作得到了和圖片token相似的文本信息。
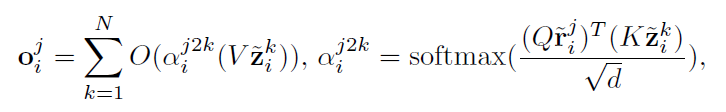
之后采用local image-to-text alignment 損失來將圖片token接近其交叉模態文本嵌入,但將推離其他跨模態文本嵌入,同時考慮到不同的視覺標記具有不同的重要性(例如,包含病理的視覺標記顯然比具有不相關信息的視覺標記更重要),我們在計算LIA損失時為視覺token分配權重。因此,如下:
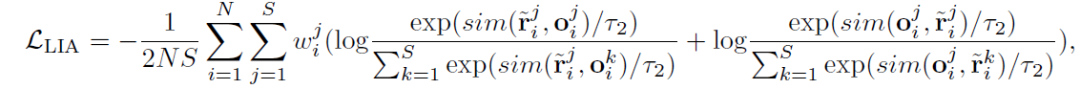
Cross-modal Prototype Alignment (CPA):ITA 和 CTA 都將來自不同實例的樣本視為負對,所以可能會把有許多類似的語義的樣本在嵌入空間推開,例如相同的疾病的對。因此,CPA模塊是為了進行疾病級別的對齊。首先使用迭代的聚類算法Sinkhorn-Knopp,文本和圖像分別被聚類算法預測結果是和,同時有個可學習的原型聚類中心,,可以直接計算得到圖像/文本和每個類中心的softmax概率:
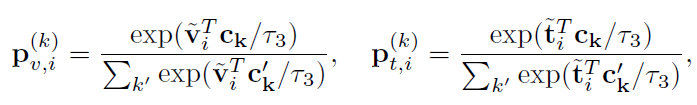
跨模態疾病水平(即原型)對齊是通過進行跨模態預測和優化以下兩個交叉熵損失來實現的。使用 作為“偽標簽”來訓練圖像表示,作為“偽標簽”來訓練文本表示:
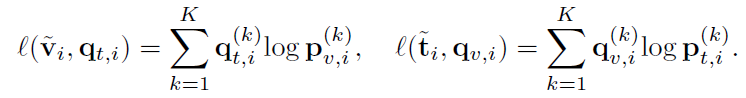
最后,CPA損失是所有圖像報告對中兩個預測損失的平均值:
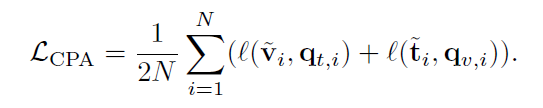
MGCA總的目標是三個模塊目標的加權和。 LViT: Language meets Vision Transformer in Medical Image Segmentation
http://arxiv.org/abs/2206.14718
LViT 模型主要用于醫學圖像分割,是一個雙 U 結構,由一個 U 形 CNN 分支和一個 U 形 Transformer 分支組成。CNN 分支負責圖片輸入和預測輸出,ViT 分支用于合并圖像和文本信息,利用 Transformer 處理跨模態信息。
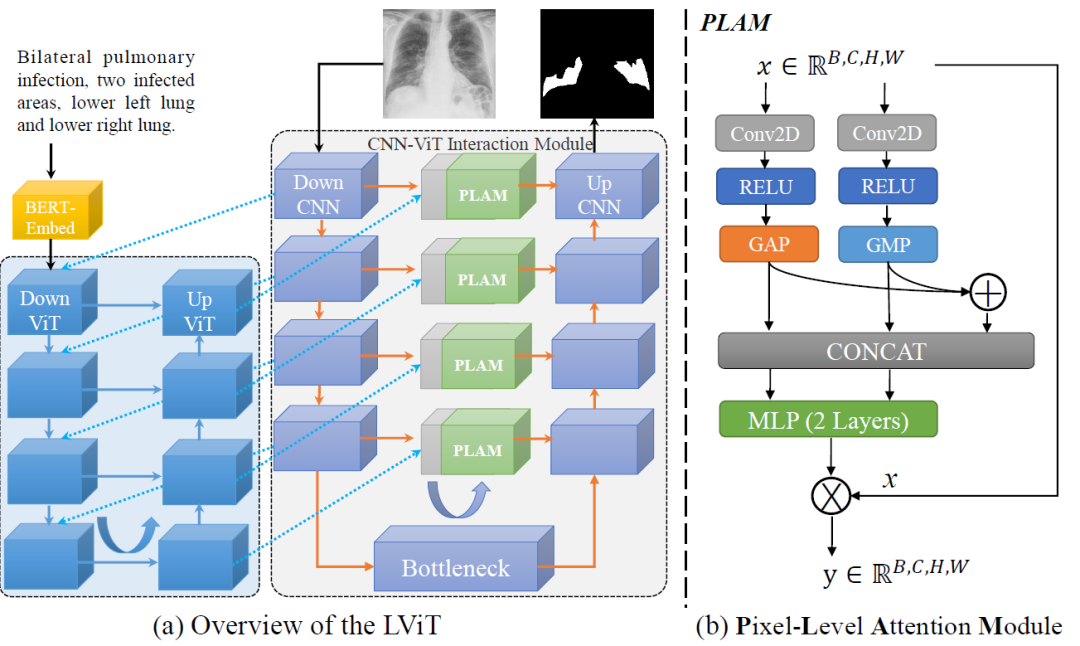
U 形 ViT 分支設計用于合并圖像特征和文本特征。第一層DownViT模塊接收文本特征輸入和來自第一層DownCNN模塊的圖像特征輸入。特定的跨模態特征合并操作由以下等式表示:
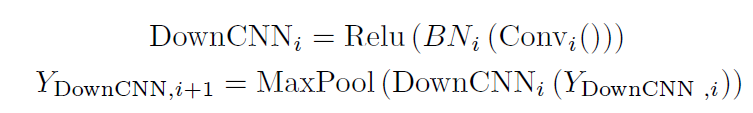
后續 DownViT 模塊既接收來自上層 DownViT 模塊的特征,又接收來自相應層的 DownCNN 模塊的特征。 然后,對應尺寸的特征通過 UpViT 模塊傳輸回 CNN-ViT 交互模塊。并且該特征與相應層的 DownCNN 模塊中的特征合并。這將最大限度地提取圖像全局特征,并避免由于文本注釋的不準確性而導致的模型性能振蕩。 PLAM模塊的設計如上圖b所示,旨在保留圖像的局部特征,并進一步合并文本中的語義特征;
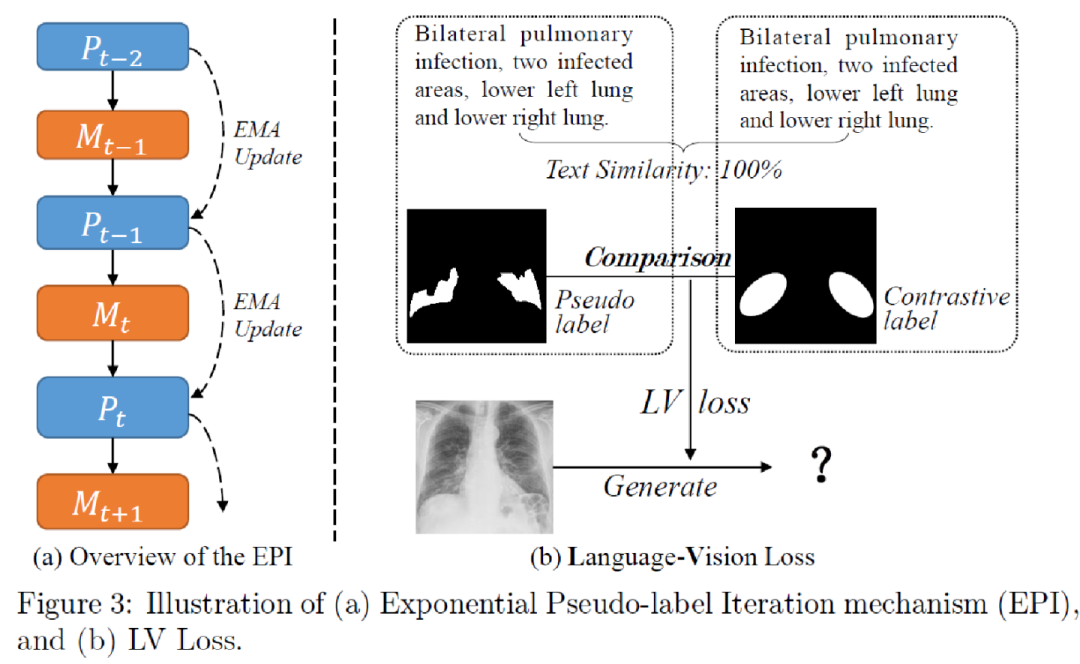
為了擴展 LViT 的半監督版本,LViT使用指數偽標簽迭代機制(EPI)。其中表示模型的預測,通過不簡單地使用一代模型預測的偽標簽作為下一代模型的目標從而避免偽標簽質量下降。因此,EPI可以逐步優化模型對每個未標記像素的分割預測結果,并對噪聲標簽具有魯棒性。
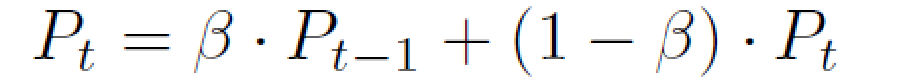
為了進一步利用文本信息來指導偽標簽的生成,設計了Languane-Vision Loss函數。首先計算對應于偽標簽的文本特征向量和用于對比標簽的文本特征向量之間的余弦相似性TextSim。之后根據TextSim,選擇相似度最高的對比文本,并找到與該文本對應的圖像mask。然后再計算圖片的偽標簽和對比標簽之間的相似性:
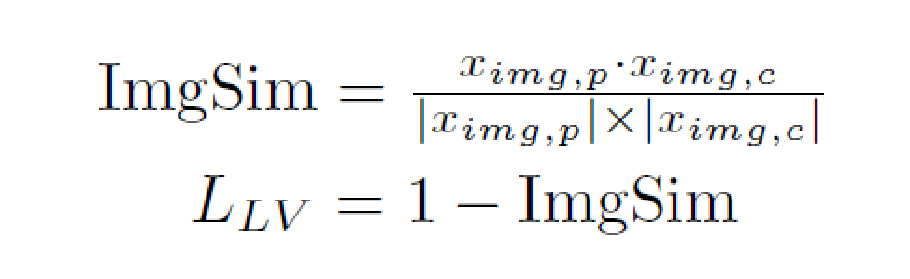
對比標簽主要提供近似位置的標簽信息,而不是邊界的細化。因此的主要目的是避免差異顯著的分割錯誤或錯誤標記病例。因此只在未標記的情況下使用LV損失,在沒有標簽的情況下,可以避免偽標簽質量的急劇惡化。 Adapting Pretrained Vision-Language Foundational Models to Medical Imaging Domains
http://arxiv.org/abs/2210.04133
目前許多生成模型雖然表現出了出色的生成能力,但它們通常不能很好地推廣到特定領域,例如醫學圖像領域。但是,利用生成模型生成一些醫學圖像出來可能有助于緩解醫療數據集的匱乏。因此,這項工作主要是研究將大型預訓練基礎模型的表示能力擴展到醫學概念,具體來說,本文是利用擴散模型stable diffusion生成醫學圖像。
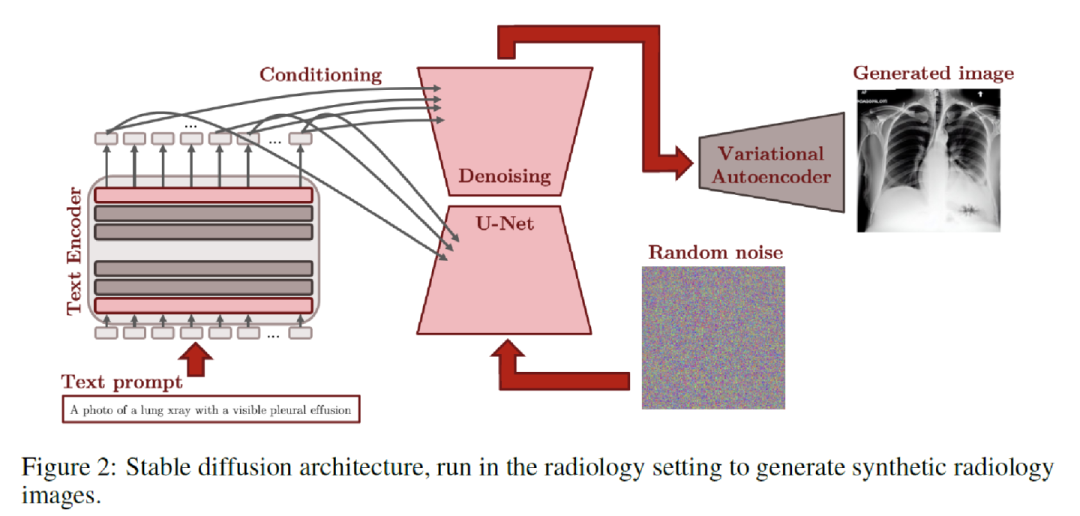
主要是利用了穩定擴散模型的架構,將整個設定轉化為了放射學的圖像和文本。具體流程如上圖二所示,給定隨機噪聲進行去噪,在這個過程中會有文本作為條件去影響去噪的過程,最后使用VAE的解碼器進行圖像的生成。整個工作是比較偏實驗和驗證性的。主要從stable diffusion的各個模塊進行訓練,包括VAE、Text Encoder、Textual Projection、Textual Embeddings Fine-tuning、U-Net Fine-tuning。

通過兩個簡單的prompt:“肺部射線照片”和“帶有可見胸腔積液的射線照片”來測試不同設置下的生成能力。并通過定量的FID指標進行評估。
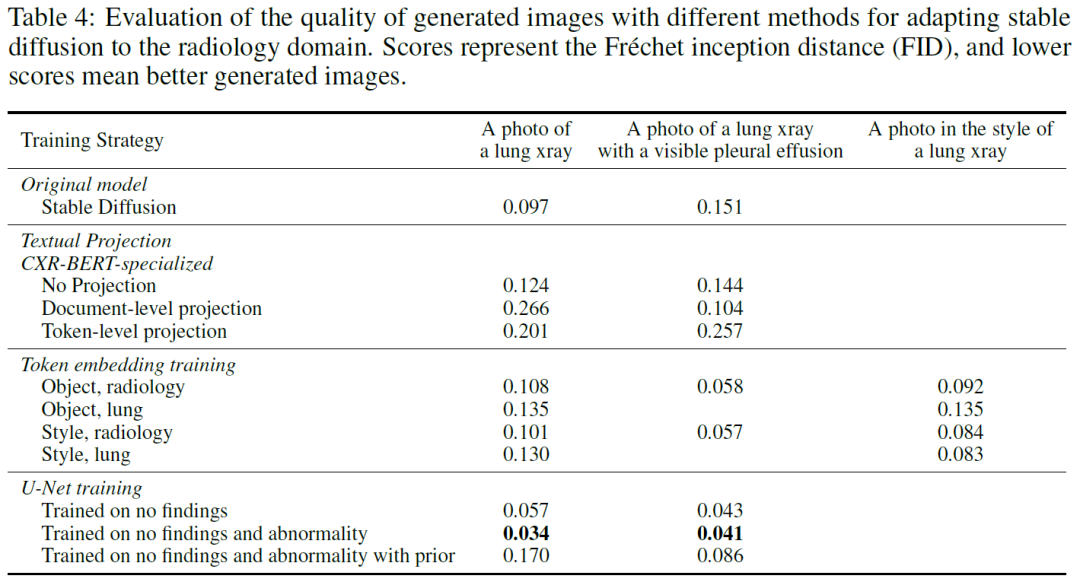
從定性和定量的結果來看,表現最好的是U-Net訓練的第二種設定,能夠生成較好的圖片的同時還能匹配文本的語義,能夠理解有無“胸腔積液”的區別。 Generalized radiograph representation learning via cross-supervision between images and free-text radiology reports【Natural Machine Intelligence 2022】
https://arxiv.org/abs/2111.03452
本文提出REFERS模型,主要通過在圖像和文本對上進行交叉監督學習去得到放射學表征。
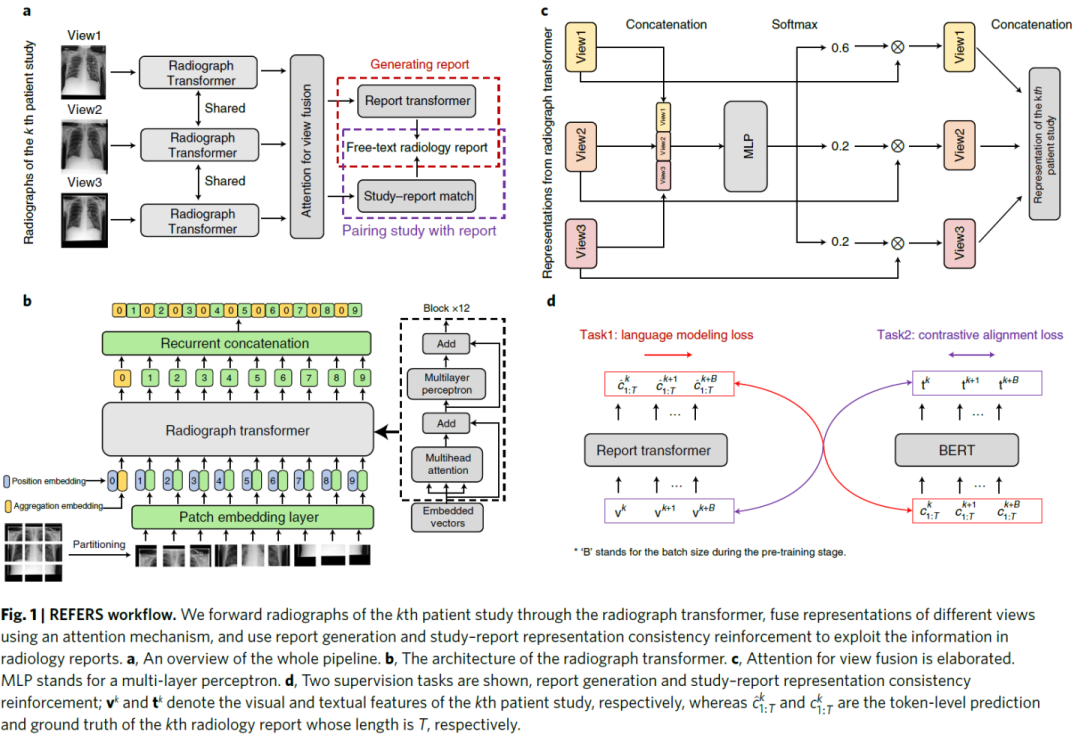
主要考慮到每項患者研究通常都有一份自由文本報告但是通常涉及不止一張 X 光片。首先通過radiograph transformer來提取不同視圖的相關特征表示。為了充分利用每份報告的信息,設計了一個基于注意力機制的視圖融合模塊,以同時處理患者研究中的所有射線照片并融合多個特征。 接下來進行交叉監督學習,從自由文本放射學報告中獲取監督信號。主要通過兩個任務:reportgeneration和study–report representation consistency reinforcement實現監督。第一項任務采用原始放射學報告中的自由文本來監督radiograph transformer的訓練過程。第二項任務加強了患者研究的視覺表示與其相應報告的文本表示之間的一致性。第一項任務主要通過report transformer在給定圖像和前面的token的條件下進行token的生成:
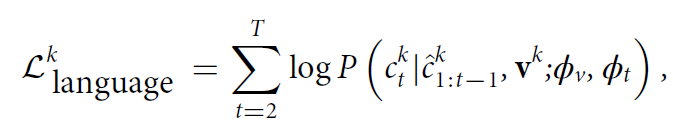
第二項任務通過圖像和文本的對比來實現。 RoentGen: Vision-Language Foundation Model for Chest X-ray Generation
http://arxiv.org/abs/2211.12737
本文提出了RoentGen,是用于合成高保真的胸片的生成模型,能夠通過自由形式的醫學語言文本prompt進行插入、組合和修改各種胸片的成像,同時能夠具有相應醫學概念的高度的圖像相關性。
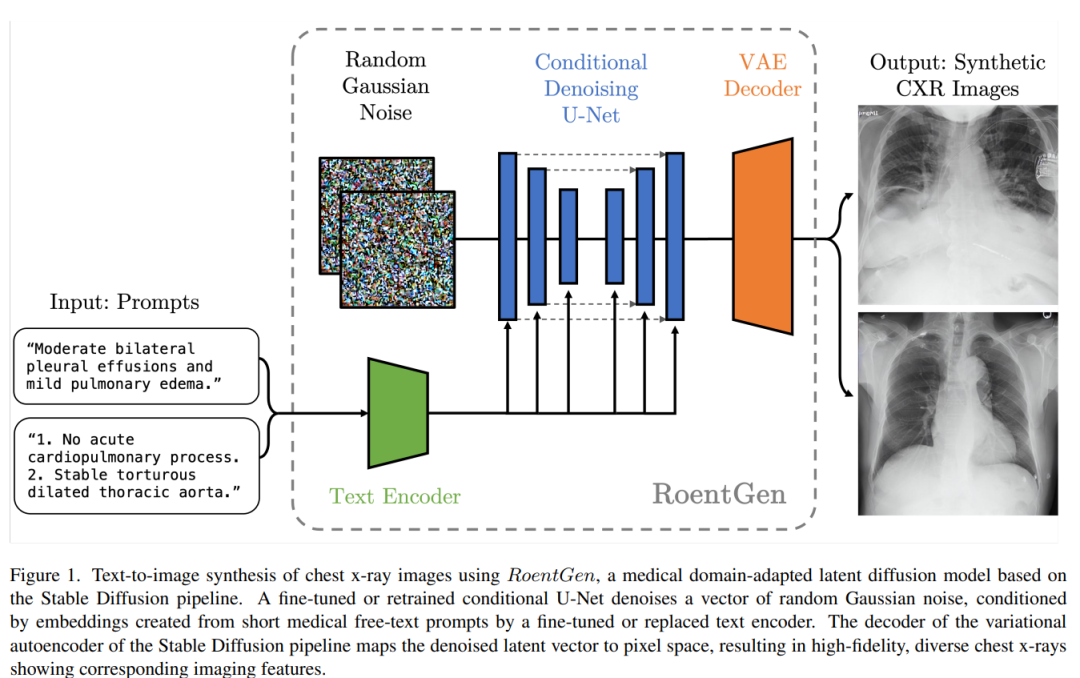
使用RoentGen對胸部X射線圖像進行文本到圖像合成流程如上圖所示。使用微調或重新訓練的U-Net 對隨機高斯噪聲進行降噪,同時此過程中會有文本編碼器從醫療文本提示得到的編碼。最后VAE的解碼器將去噪的向量映射到像素空間,從而產生高保真、多樣化的胸部射線圖像。 其中,微調或重新訓練的具體方式是這樣的:使用文本編碼器和VAE,對提示和相應的圖像進行編碼,并將采樣噪聲添加到后者的潛在表示中,之后U-Net進行預測原始采樣噪聲:
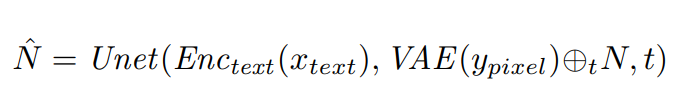
計算真實噪聲和預測噪聲之間的MSE loss,由此提高生成能力:
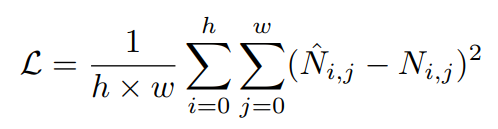
總結:目前醫學多模態通過不同的模型設計從而學習局部語義、獲取更多相關知識信息、盡可能利用現有數據集、生成圖像以盡可能彌補數據量少的問題,在下游的多種任務上得到了性能提升。如何進一步學習更加通用的醫學模型、如何將其應用到實際中是仍然值得思考和探索的。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3786瀏覽量
137573 -
圖像
+關注
關注
2文章
1094瀏覽量
41124 -
數據集
+關注
關注
4文章
1223瀏覽量
25346
原文標題:一文速覽醫學多模態進展
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態大模型

移遠通信智能模組全面接入多模態AI大模型,重塑智能交互新體驗

移遠通信智能模組全面接入多模態AI大模型,重塑智能交互新體驗

商湯“日日新”融合大模型登頂大語言與多模態雙榜單
?多模態交互技術解析

海康威視發布多模態大模型文搜存儲系列產品

商湯日日新多模態大模型權威評測第一
亥步多模態醫療大模型發布:人工智能引領醫療新紀元

一文理解多模態大語言模型——上






 工商網監
工商網監
評論