") 一種用于自監(jiān)督單目深度估計(jì)的輕量級CNN和Transformer架構(gòu)
一種用于自監(jiān)督單目深度估計(jì)的輕量級CNN和Transformer架構(gòu)
摘要
大家好,今天為大家?guī)淼奈恼?Lite-Mono:A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation 自監(jiān)督單目深度估計(jì)不需要地面實(shí)況訓(xùn)練,近年來受到廣泛關(guān)注。
設(shè)計(jì)輕量級但有效的模型非常有意義,這樣它們就可以部署在邊緣設(shè)備上。許多現(xiàn)有的體系結(jié)構(gòu)受益于以模型大小為代價(jià)使用更重的主干。
在本文中,我們實(shí)現(xiàn)了與輕量級ar結(jié)構(gòu)相當(dāng)?shù)慕Y(jié)果。具體來說,我們研究了cnn和transformer的有效結(jié)合,并設(shè)計(jì)了一個(gè)混合架構(gòu)Lite-Mono。提出了連續(xù)擴(kuò)展卷積(CDC)模塊和局部全局特征交互(LGFI)模塊。
前者用于提取豐富的多尺度局部特征,后者利用自注意機(jī)制將長范圍的全局信息編碼到特征中。實(shí)驗(yàn)證明,我們的完整模型在精度上優(yōu)于Monodepth2,可訓(xùn)練參數(shù)減少了80%左右。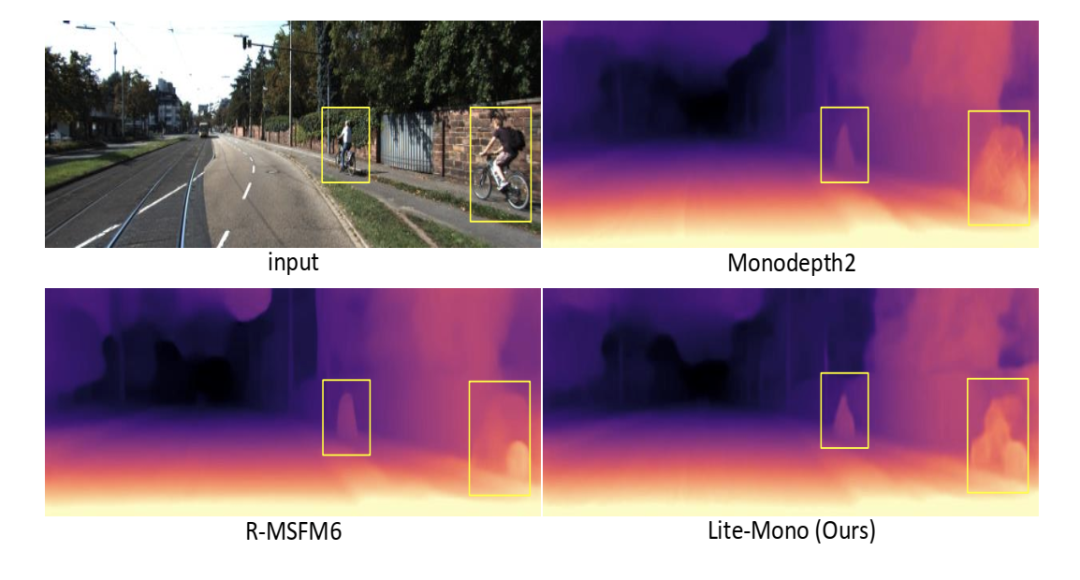
圖1 我們的完整模型Lite-Mono的參數(shù)比Monodepth2[15]和R-MSFM[44]少,但生成的深度圖更準(zhǔn)確。
主要工作與貢獻(xiàn)
綜上所述,我們的貢獻(xiàn)如下:
我們提出了一種新的輕量級架構(gòu),稱為Lite-Mono,用于自監(jiān)督單目深度估計(jì)。我們證明了它的有效性與模型大小和FLOPs
與競爭較大的模型相比,所提出的架構(gòu)在KITTI[13]數(shù)據(jù)集上顯示出更高的精度。它用最少的可訓(xùn)練參數(shù)達(dá)到了最先進(jìn)的水平。在Make3D[31]數(shù)據(jù)集上進(jìn)一步驗(yàn)證了模型的泛化能力。為了驗(yàn)證不同設(shè)計(jì)方案的有效性,還進(jìn)行了額外的消融實(shí)驗(yàn)
在Nvidia Titan XP和Jetson Xavier平臺上測試了該方法的推理時(shí)間,驗(yàn)證了該方法在模型復(fù)雜度和推理速度之間的良好平衡。
算法流程
1.總體結(jié)構(gòu)
多篇論文證明,一個(gè)好的編碼器可以提取更多有效的特征,從而改善最終結(jié)果[15,17,42]。本文著重設(shè)計(jì)了一種輕量級編碼器,可以對輸入圖像中的有效特征進(jìn)行編碼。圖2顯示了建議的體系結(jié)構(gòu)。它由一個(gè)編解碼器DepthNet(章節(jié)3.2)和一個(gè)PoseNet(章節(jié)3.3)組成。DepthNet估計(jì)輸入圖像的多尺度反深度圖,PoseNet估計(jì)兩個(gè)相鄰幀之間的相機(jī)運(yùn)動(dòng)。然后生成重建目標(biāo)圖像,計(jì)算損失以優(yōu)化模型(章節(jié)3.4)。
增強(qiáng)局部特特征:使用較淺的網(wǎng)絡(luò)而不是較深的網(wǎng)絡(luò)可以有效地減小模型的大小。如前所述,淺層cnn的接受野非常有限,而使用擴(kuò)張卷積[41]有助于擴(kuò)大接受野。通過疊加提出的連續(xù)擴(kuò)張卷積(CDC),網(wǎng)絡(luò)能夠在更大的區(qū)域“觀察”輸入,同時(shí)不引入額外的訓(xùn)練參數(shù)。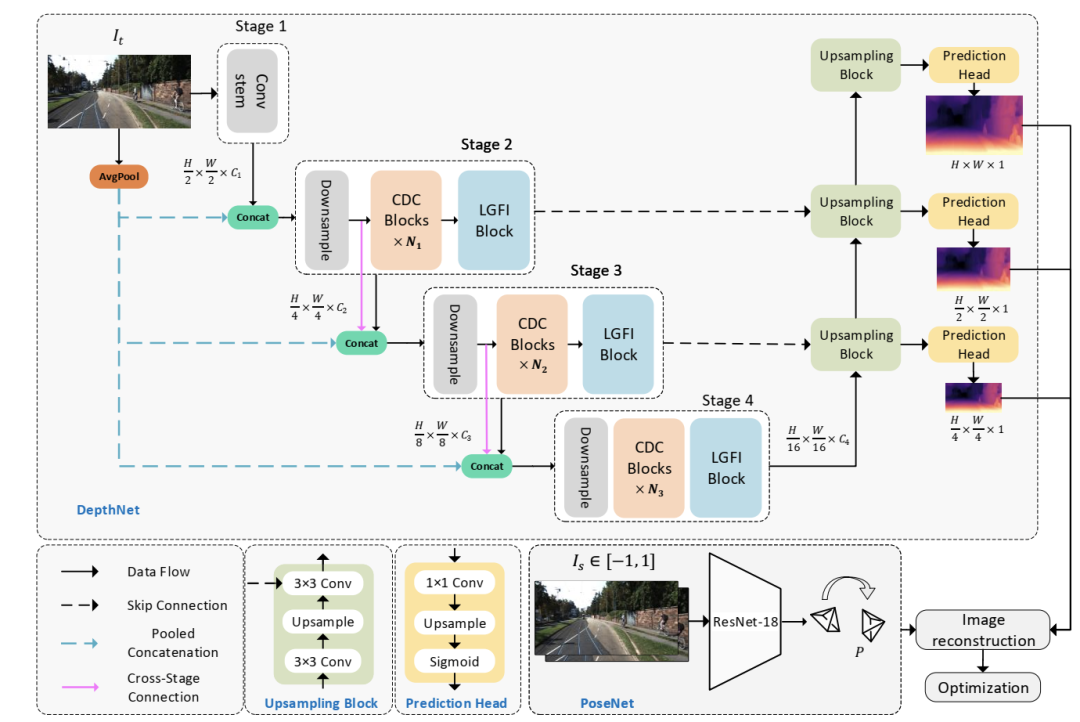
圖2 擬議的Lite-Mono概述。我們的Lite-Mono有一個(gè)用于深度預(yù)測的編碼器-解碼器DepthNet,以及一個(gè)常用的PoseNet[15,44]來估計(jì)相鄰單目幀之間的姿勢。深度網(wǎng)絡(luò)的編碼器由四個(gè)階段組成,我們提出使用連續(xù)擴(kuò)張卷積(CDC)模塊和局部全局特征交互(LGFI)模塊來提取豐富的層次特征。這些模塊的詳細(xì)信息如圖3所示。
低計(jì)算量的全局信息:增強(qiáng)的局部特征不足以在沒有Transform的幫助下學(xué)習(xí)輸入的全局表示來建模遠(yuǎn)程信息。原Transformer[8]中的MHSA模塊的計(jì)算復(fù)雜度與輸入維數(shù)呈線性關(guān)系,因此限制了輕量化模型的設(shè)計(jì)。局部全局特征交互(Local-Global Features Interaction, LGFI)模塊采用跨協(xié)方差注意力[1]來計(jì)算沿特征通道的注意力,而不是跨空間維度計(jì)算注意力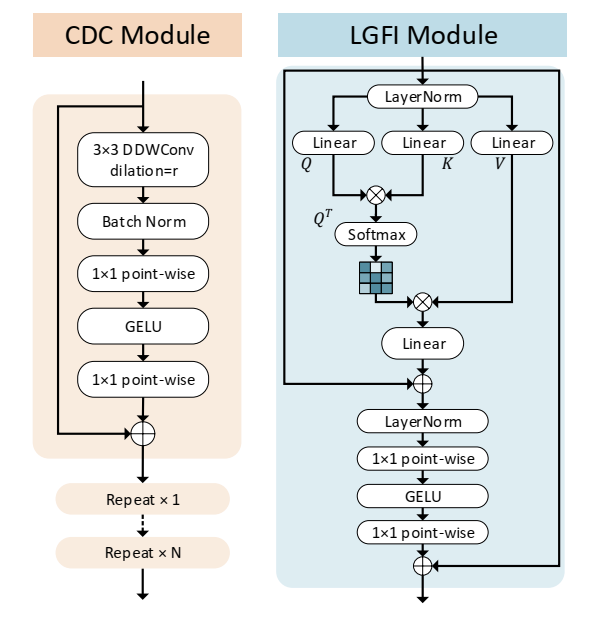
圖3 所提出的連續(xù)擴(kuò)展卷積(CDC)模塊和局部全局特征交互(LGFI)模塊的結(jié)構(gòu)。在每個(gè)階段,不同擴(kuò)張速率的CDC模塊重復(fù)N次。
2.DepthNet
2.1 編碼器
深度編碼器。Lite-Mono在四個(gè)階段聚合了多尺度特征。大小為H ×W ×3的輸入圖像首先被輸入到卷積干中,在那里圖像被3 ×3卷積向下采樣。接下來進(jìn)行兩個(gè)額外的3個(gè)×3卷積(stride =1)進(jìn)行局部特征提取,我們得到大小為H2 ×W2 ×C1的特征映射。
在第二階段,將特征與池化后的三通道輸入圖像進(jìn)行拼接,再使用stride =2的3 ×3卷積對特征圖進(jìn)行下采樣,得到大小為H 4 H 4 ×W4 ×C2的特征圖。在下采樣層中,將特征與平均池化的輸入圖像進(jìn)行拼接,可以減少特征尺寸減小所造成的空間信息損失,這是受到ESPNetv2[3]的啟發(fā)。然后,我們使用提出的連續(xù)擴(kuò)張卷積(CDC)模塊和局部-全局特征交互(LGFI)模塊來學(xué)習(xí)豐富的分層特征表示。
2.2 連續(xù)擴(kuò)張卷積(CDC
連續(xù)擴(kuò)張卷積(CDC)。提出的CDC模塊利用擴(kuò)張卷積提取多尺度局部特征。不同于只在網(wǎng)絡(luò)的最后一層使用并行擴(kuò)張卷積模塊[6],我們在每個(gè)階段插入幾個(gè)連續(xù)的不同擴(kuò)張速率的擴(kuò)張卷積,以實(shí)現(xiàn)足夠的多尺度上下文聚合。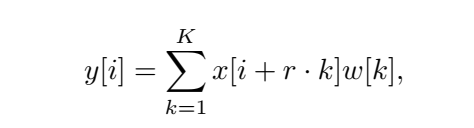
2.3局部全局特征交互(LGFI)
給定一個(gè)維度為H的輸入特征映射X ×W ×C,我們可以將其投影到相同維度的查詢Q =XWq,鍵K =XWk,值V =XWv,其中Wq、Wk和Wv是權(quán)重矩陣。我們使用交叉協(xié)方差注意[1]來增強(qiáng)輸入X: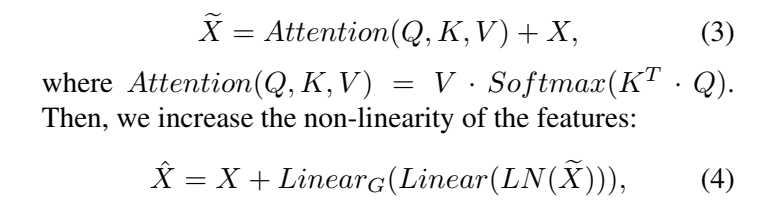
2.4 解碼器
不同于使用復(fù)雜的上采樣方法[44]或引入額外的注意模塊[3],我們使用了從[15]改編而來的深度解碼器。作為 如圖2所示,它使用雙線性上采樣來增加空間維度,并使用卷積層來連接編碼器的三個(gè)階段的特征。每個(gè)向上采樣塊跟隨一個(gè)預(yù)測頭,分別以全分辨率、12分辨率和14分辨率輸出逆深度圖。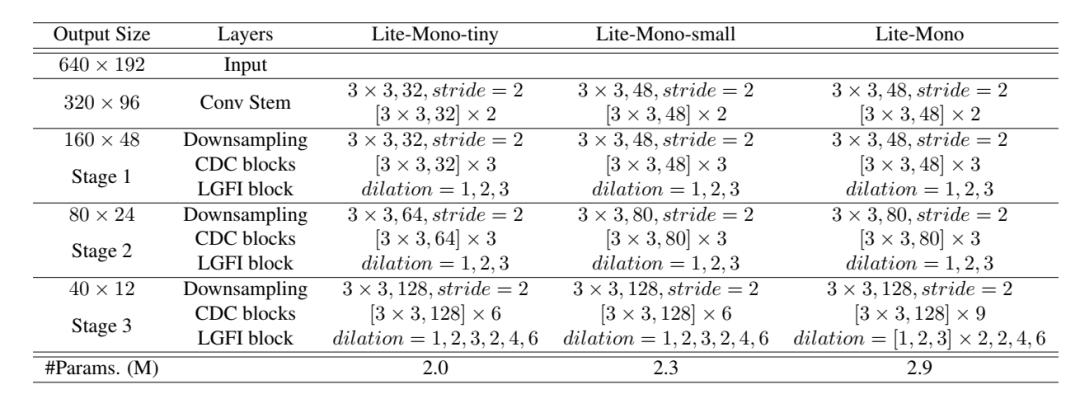
圖3 網(wǎng)絡(luò)結(jié)構(gòu)表
實(shí)驗(yàn)結(jié)果 ?
? 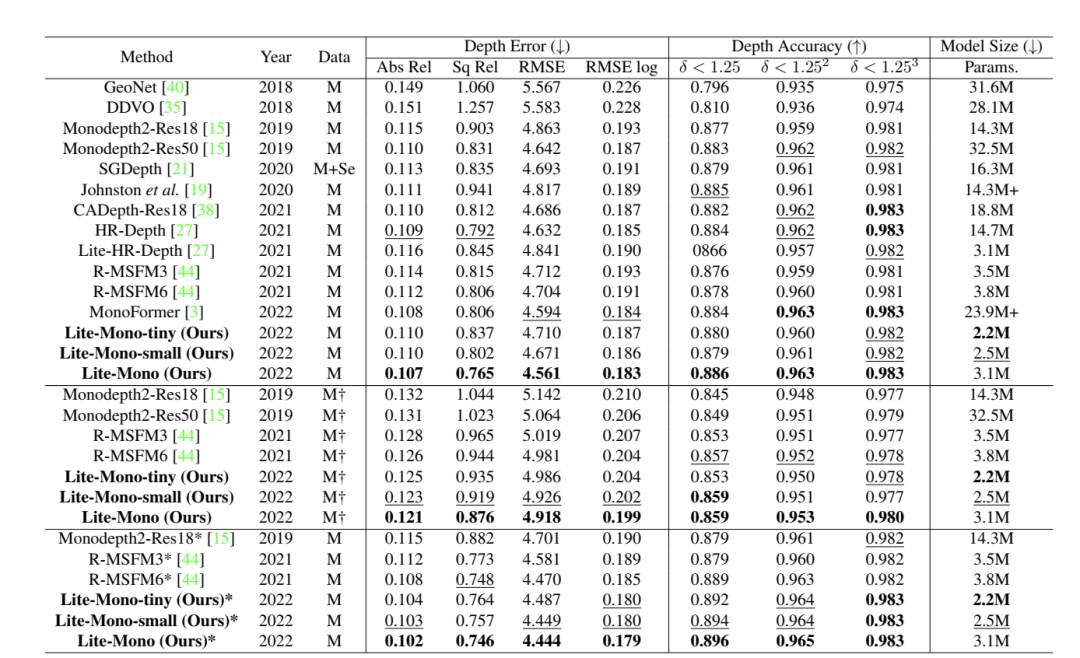
表1我們的模型與KITTI基準(zhǔn)上使用特征分割[9]的一些最近的代表性方法的比較。除非另有說明,否則所有輸入圖像都將調(diào)整為640 ×192。最佳和次優(yōu)結(jié)果分別用粗體和下劃線突出顯示。”M”:KITTI單目視頻,“M+Se”:單目視頻+語義分割,“*”:輸入分辨率1024 ×320,“My”:未經(jīng)ImageNet預(yù)訓(xùn)練[7]。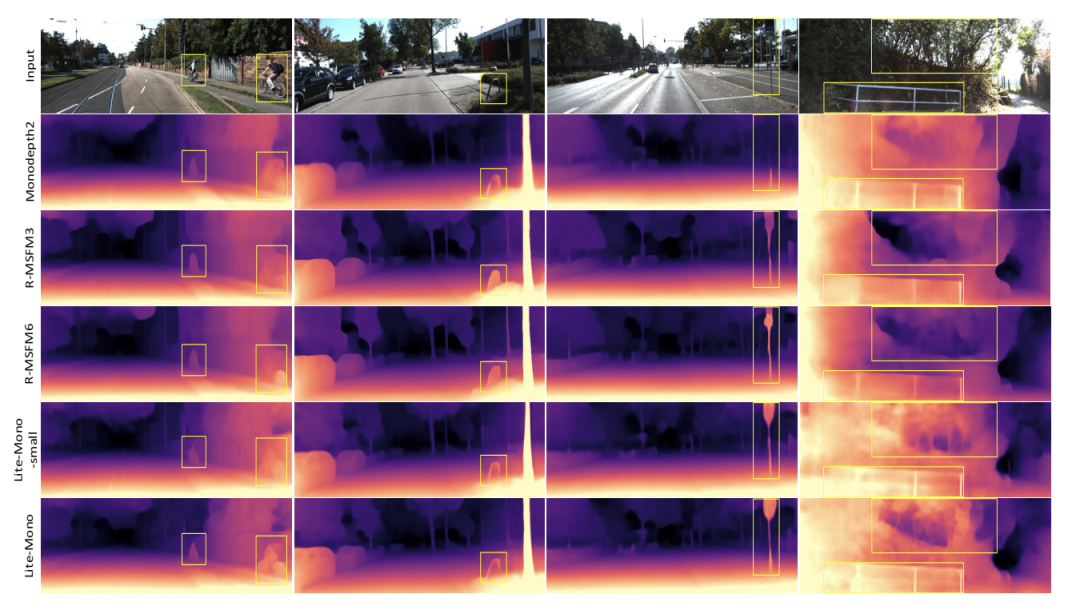
圖4 KITTI的定性結(jié)果。我們分別展示了Monodepth2 [15],R-MSFM3 [44],R-MSFM6 [44],Lite-Mono-small(我們的)和Lite-Mono(我們的)生成的一些深度圖。Monodepth2和R-MSFM的接受域有限,因此它們的深度預(yù)測有些不準(zhǔn)確。相反,我們的模型可以產(chǎn)生更好的結(jié)果
圖5 Make3D數(shù)據(jù)集上的定性結(jié)果。我們比較Monodepth2[15]和R-MSFM[44]。我們的模型可以感知不同大小的物體 圖3KITTI數(shù)據(jù)集上的DRAFT預(yù)測示例。從(a)輸入的RGB圖像中,我們顯示(b)光流估計(jì),(c)深度估計(jì),和(d)從深度和場景流估計(jì)中預(yù)測的光流 。
審核編輯:劉清
-
RGB
+關(guān)注
關(guān)注
4文章
804瀏覽量
59649 -
編解碼器
+關(guān)注
關(guān)注
0文章
272瀏覽量
24666 -
CDC
+關(guān)注
關(guān)注
0文章
57瀏覽量
18145
原文標(biāo)題:CVPR 2023 | Lite-Mono:一種用于自監(jiān)督單目深度估計(jì)的輕量級CNN和Transformer架構(gòu)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于transformer和自監(jiān)督學(xué)習(xí)的路面異常檢測方法分享

一種超輕量級的flashKV數(shù)據(jù)存儲方案分享
基于單目圖像的深度估計(jì)算法,大幅度提升基于單目圖像深度估計(jì)的精度

一種輕量級時(shí)間卷積網(wǎng)絡(luò)設(shè)計(jì)方案

采用自監(jiān)督CNN進(jìn)行單圖像深度估計(jì)的方法

一種新的輕量級視覺Transformer
介紹第一個(gè)結(jié)合相對和絕對深度的多模態(tài)單目深度估計(jì)網(wǎng)絡(luò)
一種端到端的立體深度感知系統(tǒng)的設(shè)計(jì)

動(dòng)態(tài)場景下的自監(jiān)督單目深度估計(jì)方案
單目深度估計(jì)開源方案分享

【AIBOX 應(yīng)用案例】單目深度估計(jì)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論