") 通用視覺GPT時刻來臨?智源推出通用分割模型SegGPT
通用視覺GPT時刻來臨?智源推出通用分割模型SegGPT
ChatGPT 引發(fā)了語言大模型狂潮,AI 另一個重大領(lǐng)域 —— 視覺 —— 的 GPT 時刻何時到來?
前兩天,機器之心介紹了Meta 最新研究成果Segment Anything Model (SAM)。該研究引起了AI社區(qū)廣泛討論。
而據(jù)我們所知,幾乎同一時間,智源研究院視覺團隊也推出通用分割模型 SegGPT(Segment Everything In Context)—— 利用視覺提示(prompt)完成任意分割任務(wù)的通用視覺模型。

論文地址:https://arxiv.org/abs/2304.03284
代碼地址:https://github.com/baaivision/Painter
Demo:https://huggingface.co/spaces/BAAI/SegGPT
SegGPT 與 Meta AI 圖像分割基礎(chǔ)模型 SAM 同時發(fā)布,兩者的差異在于 :
SegGPT “一通百通”:給出一個或幾個示例圖像和意圖掩碼,模型就能 get 用戶意圖,“有樣學(xué)樣” 地完成類似分割任務(wù)。用戶在畫面上標(biāo)注識別一類物體,即可批量化識別分割同類物體,無論是在當(dāng)前畫面還是其他畫面或視頻環(huán)境中。
SAM “一觸即通”:通過一個點或邊界框,在待預(yù)測圖片上給出交互提示,識別分割畫面上的指定物體。
無論是 “一觸即通” 還是 “一通百通”,都意味著視覺模型已經(jīng) “理解” 了圖像結(jié)構(gòu)。SAM 精細(xì)標(biāo)注能力與 SegGPT 的通用分割標(biāo)注能力相結(jié)合,能把任意圖像從像素陣列解析為視覺結(jié)構(gòu)單元,像生物視覺那樣理解任意場景,通用視覺 GPT 曙光乍現(xiàn)。
SegGPT 是智源通用視覺模型 Painter(CVPR 2023)的衍生模型,針對分割一切物體的目標(biāo)做出優(yōu)化。SegGPT 訓(xùn)練完成后無需微調(diào),只需提供示例即可自動推理并完成對應(yīng)分割任務(wù),包括圖像和視頻中的實例、類別、零部件、輪廓、文本、人臉等等。
該模型具有以下優(yōu)勢能力:
1. 通用能力:SegGPT 具有上下文推理能力,模型能夠根據(jù)提供的分割示例(prompt),對預(yù)測進行自適應(yīng)的調(diào)整,實現(xiàn)對 “everything” 的分割,包括實例、類別、零部件、輪廓、文本、人臉、醫(yī)學(xué)圖像、遙感圖像等。
2. 靈活推理能力:支持任意數(shù)量的 prompt;支持針對特定場景的 tuned prompt;可以用不同顏色的 mask 表示不同目標(biāo),實現(xiàn)并行分割推理。
3. 自動視頻分割和追蹤能力:以第一幀圖像和對應(yīng)的物體掩碼作為上下文示例,SegGPT 能夠自動對后續(xù)視頻幀進行分割,并且可以用掩碼的顏色作為物體的 ID,實現(xiàn)自動追蹤。
案例展示
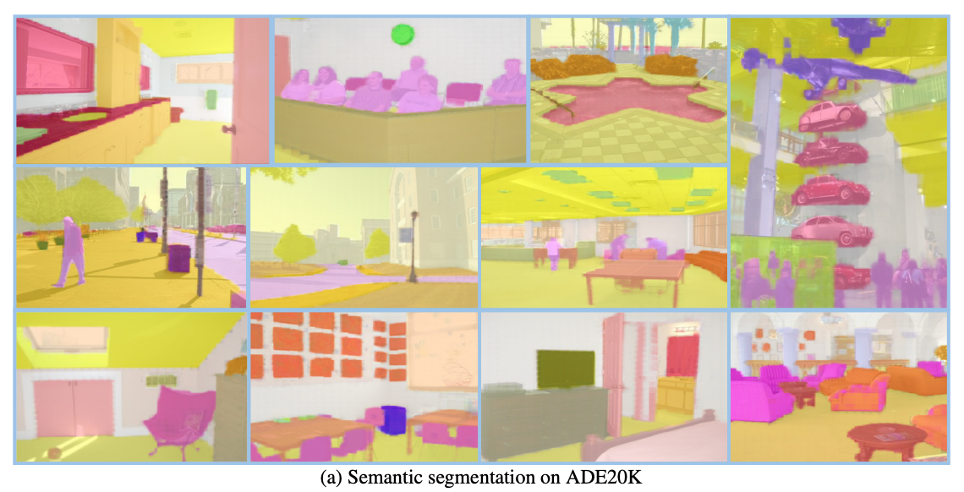
1. 作者在廣泛的任務(wù)上對 SegGPT 進行了評估,包括少樣本語義分割、視頻對象分割、語義分割和全景分割。下圖中具體展示了 SegGPT 在實例、類別、零部件、輪廓、文本和任意形狀物體上的分割結(jié)果。

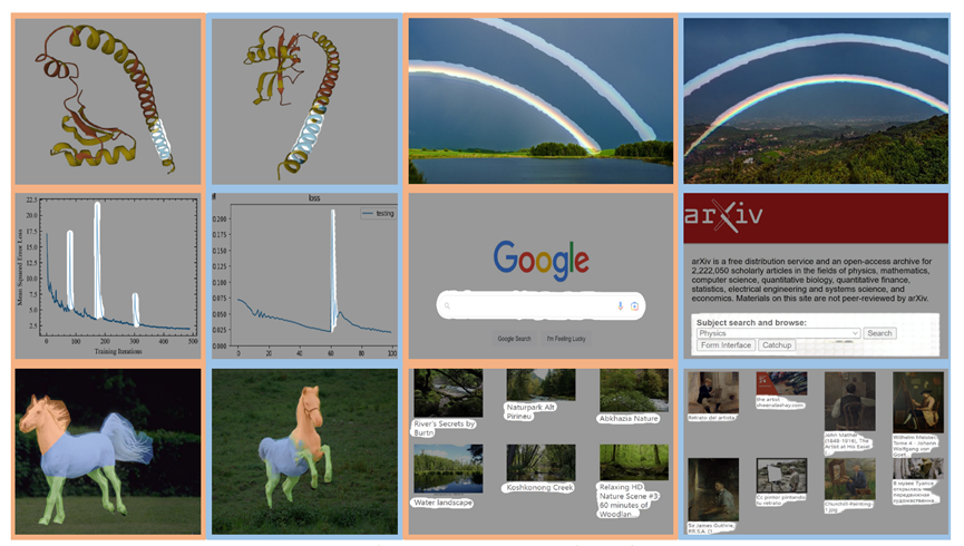
2. 標(biāo)注出一個畫面中的彩虹(上圖),可批量化分割其他畫面中的彩虹(下圖)

3. 用畫筆大致圈出行星環(huán)帶(上圖),在預(yù)測圖中準(zhǔn)確輸出目標(biāo)圖像中的行星環(huán)帶(下圖)。


4. SegGPT 能夠根據(jù)用戶提供的宇航員頭盔掩碼這一上下文(左圖),在新的圖片中預(yù)測出對應(yīng)的宇航員頭盔區(qū)域(右圖)。

訓(xùn)練方法
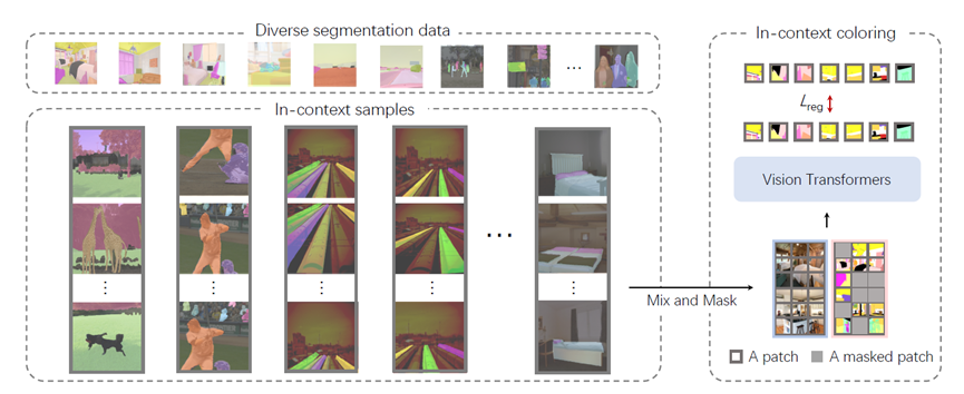
SegGPT 將不同的分割任務(wù)統(tǒng)一到一個通用的上下文學(xué)習(xí)框架中,通過將各類分割數(shù)據(jù)轉(zhuǎn)換為相同格式的圖像來統(tǒng)一各式各樣的數(shù)據(jù)形式。
具體來說,SegGPT 的訓(xùn)練被定義為一個上下文著色問題,對于每個數(shù)據(jù)樣本都有隨機的顏色映射。目標(biāo)是根據(jù)上下文完成各種任務(wù),而不是依賴于特定的顏色。訓(xùn)練后,SegGPT 可以通過上下文推理在圖像或視頻中執(zhí)行任意分割任務(wù),例如實例、類別、零部件、輪廓、文本等。
Test-time techniques
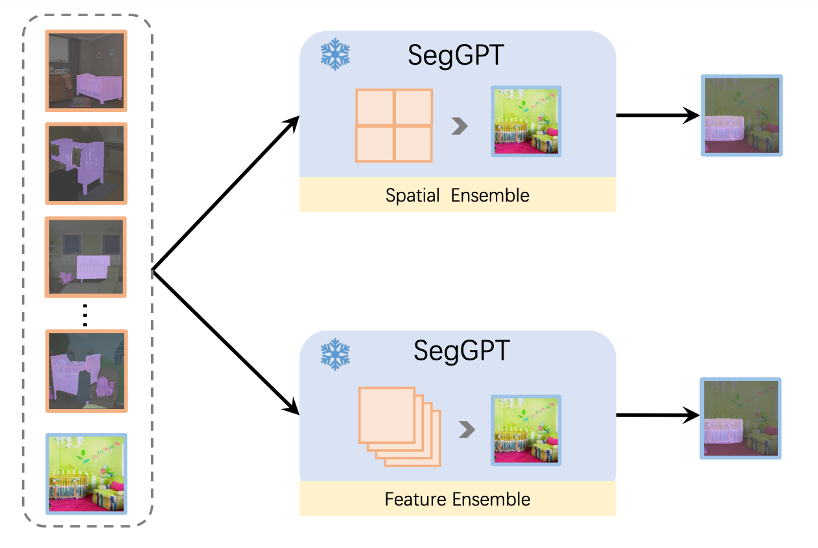
如何通過 test-time techniques 解鎖各種能力是通用模型的一大亮點。SegGPT 論文中提出了多個技術(shù)來解鎖和增強各類分割能力,比如下圖所示的不同的 context ensemble 方法。所提出的 Feature Ensemble 方法可以支持任意數(shù)量的 prompt 示例,實現(xiàn)豐儉由人的推理效果。
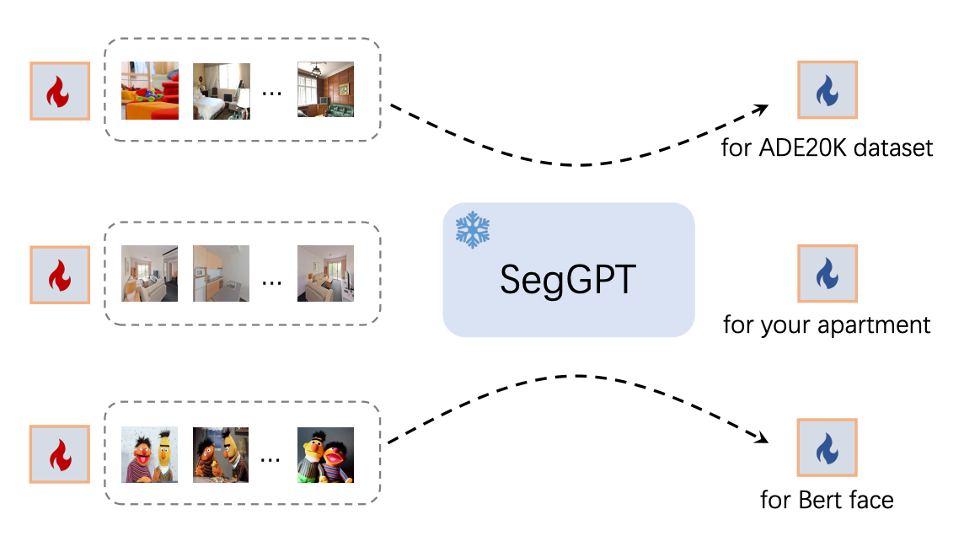
此外,SegGPT 還支持對特定場景優(yōu)化專用 prompt 提示。對于針對性的使用場景,SegGPT 可以通過 prompt tuning 得到對應(yīng) prompt,無需更新模型參數(shù)來適用于特定場景。比如,針對某一數(shù)據(jù)集自動構(gòu)建一個對應(yīng)的 prompt,或者針對一個房間來構(gòu)建專用 prompt。如下圖所示:
結(jié)果展示
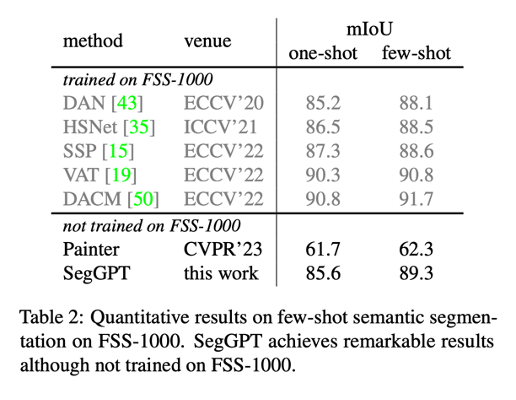
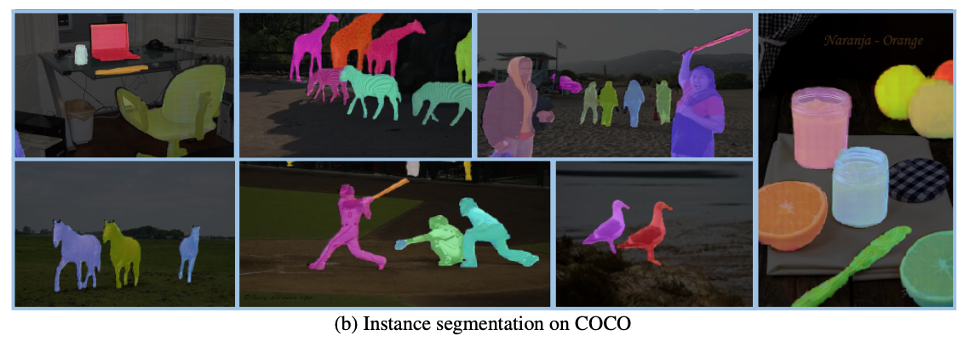
模型只需少數(shù) prompt 示例,在 COCO 和 PASCAL 數(shù)據(jù)集上取得最優(yōu)性能。SegGPT 顯示出強大的零樣本場景遷移能力,比如在少樣本語義分割測試集 FSS-1000 上,在無需訓(xùn)練的情況下取得 state-of-the-art 性能。
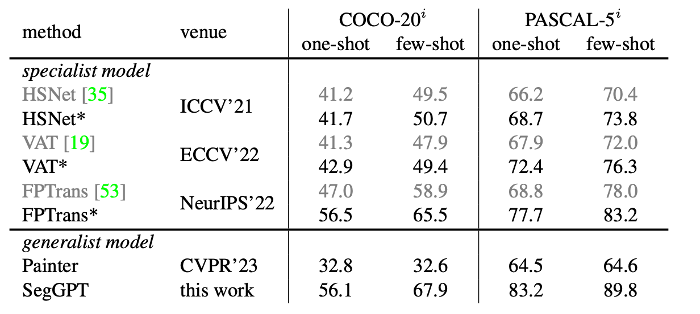
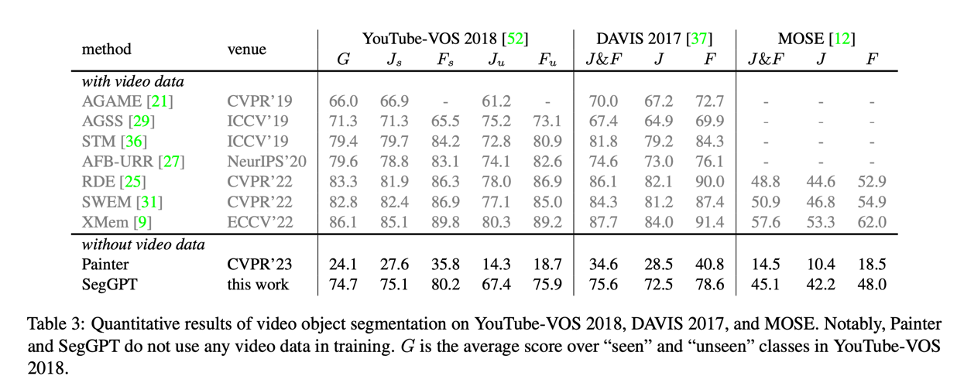
無需視頻訓(xùn)練數(shù)據(jù),SegGPT 可直接進行視頻物體分割,并取得和針對視頻物體分割專門優(yōu)化的模型相當(dāng)?shù)男阅堋?/p>
以下是基于 tuned prompt 在語義分割和實例分割任務(wù)上的效果展示:
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
88文章
34421瀏覽量
275741 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
15961
原文標(biāo)題:通用視覺GPT時刻來臨?智源推出通用分割模型SegGPT
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
?VLM(視覺語言模型)?詳細(xì)解析

BlackBerry QNX推出通用嵌入式開發(fā)平臺
海康威視推出視覺大模型系列攝像機
OpenAI即將發(fā)布GPT-4.5與GPT-5
OpenAI即將推出GPT-5模型
通用大模型在垂直行業(yè)的應(yīng)用
用于任意排列多相機的通用視覺里程計系統(tǒng)
深信服發(fā)布安全GPT4.0數(shù)據(jù)安全大模型
通用大模型評測標(biāo)準(zhǔn)正式發(fā)布
英偉達(dá)預(yù)測機器人領(lǐng)域或迎“GPT-3時刻”
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論