") 什么是基礎(chǔ)模型
什么是基礎(chǔ)模型

基礎(chǔ)模型是在大量無標(biāo)簽數(shù)據(jù)集上訓(xùn)練的 AI 神經(jīng)網(wǎng)絡(luò),可處理從翻譯文本到分析醫(yī)學(xué)影像等各種工作。
1956 年,一間錄音室里的麥克風(fēng)開著,磁帶在不停地轉(zhuǎn)動(dòng),Miles Davis Quintet 正在里面為 Prestige Records 錄制幾十首曲子。
當(dāng)一名錄音工程師問起下一首歌曲叫什么時(shí),Davis 回答道:“等我演奏完后,再告訴你它叫什么。”
如同這位多產(chǎn)的爵士樂小號(hào)手兼作曲家一樣,研究人員也一直在以瘋狂的速度生成 AI 模型,探索新的架構(gòu)和用例。他們把精力都放到了開拓新領(lǐng)域上,因此有時(shí)會(huì)讓其他人來分類他們的工作。
一支百來名斯坦福大學(xué)研究人員組成的團(tuán)隊(duì)在 2021 年夏天發(fā)布了一篇論文,共同完成了這項(xiàng)工作。
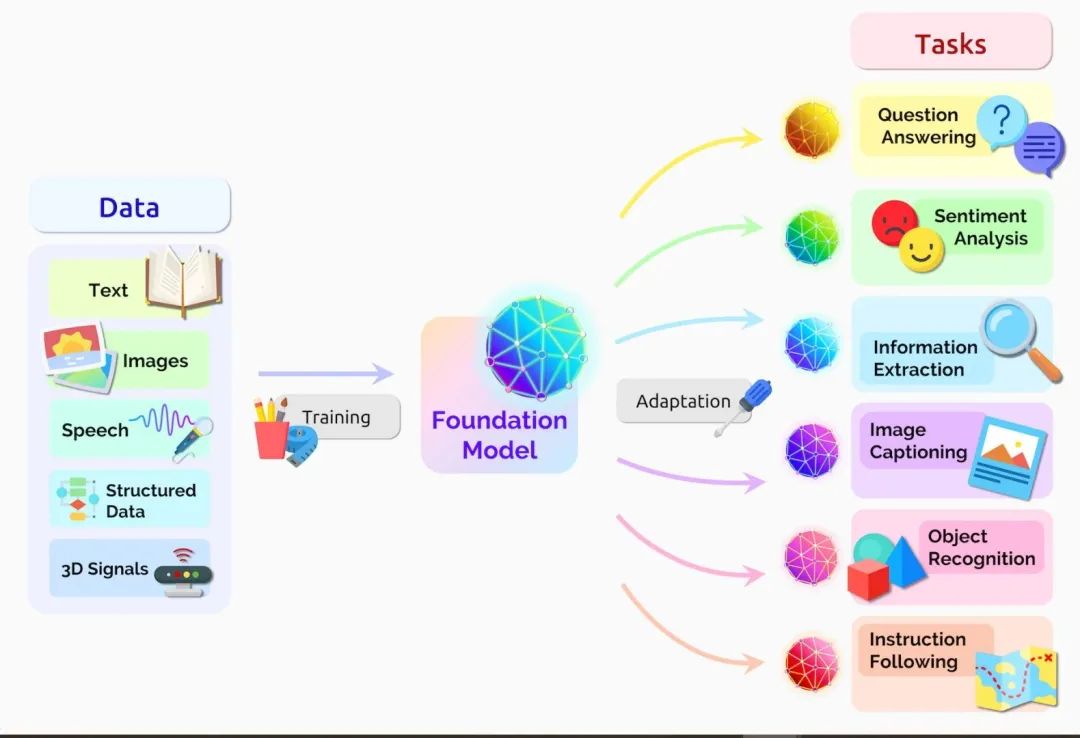
研究人員在 2021 年的一篇論文中表示,基礎(chǔ)模型的用途正在變得越來越廣泛。
他們把 Transformer 模型、大型語言模型(LLM)和其他仍在構(gòu)建的神經(jīng)網(wǎng)絡(luò)歸入到這個(gè)被他們稱之為基礎(chǔ)模型的重要新類別中。
基礎(chǔ)模型的定義
這篇論文將基礎(chǔ)模型定義為一種在大量原始數(shù)據(jù)的基礎(chǔ)上通過無監(jiān)督學(xué)習(xí)訓(xùn)練而成的 AI 神經(jīng)網(wǎng)絡(luò),可適應(yīng)各種任務(wù)。
他們在論文中寫道:“過去幾年中,基礎(chǔ)模型的規(guī)模和范圍超出了我們的想象。”
在定義這個(gè)總括性的類別時(shí)考慮了兩個(gè)重要的概念:是否讓數(shù)據(jù)采集變得更容易以及是否有無邊無垠的可能性。
沒有標(biāo)簽,但有無限的可能性
基礎(chǔ)模型通常使用無標(biāo)簽數(shù)據(jù)集進(jìn)行學(xué)習(xí),節(jié)省了手動(dòng)描述大量數(shù)據(jù)集內(nèi)各個(gè)項(xiàng)目的時(shí)間和費(fèi)用。
早期的神經(jīng)網(wǎng)絡(luò)會(huì)被針對特定任務(wù)進(jìn)行嚴(yán)格的調(diào)整。在經(jīng)過略微調(diào)整后,基礎(chǔ)模型就可以負(fù)責(zé)從翻譯文本到分析醫(yī)學(xué)影像等各類工作。
該團(tuán)隊(duì)在其研究中心網(wǎng)站上表示,基礎(chǔ)模型正展現(xiàn)出“驚人的行為”并且正在被大規(guī)模部署。到目前為止,團(tuán)隊(duì)內(nèi)部研究人員已經(jīng)發(fā)布了 50 多篇關(guān)于基礎(chǔ)模型的論文。
中心主任 Percy Liang 在第一次基礎(chǔ)模型研討會(huì)開場演講中表示:“我認(rèn)為我們現(xiàn)在只開發(fā)了現(xiàn)今基礎(chǔ)模型很小一部分的能力,更不用說未來的模型了。”
AI 的涌現(xiàn)和同質(zhì)化
在那次演講中,Liang 創(chuàng)造了兩個(gè)術(shù)語來描述基礎(chǔ)模型:
涌現(xiàn)指仍在發(fā)掘的 AI 特征,比如基礎(chǔ)模型中的許多新生技能。他還把 AI 算法和模型架構(gòu)的混合稱為同質(zhì)化,該趨勢推動(dòng)了基礎(chǔ)模型的形成(見下圖)。
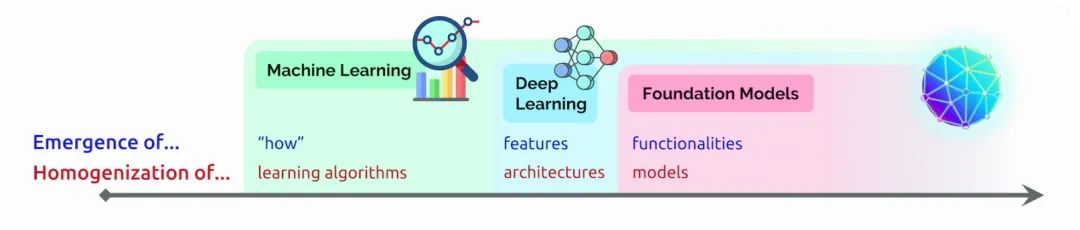
這個(gè)領(lǐng)域正在繼續(xù)快速發(fā)展。
在該團(tuán)隊(duì)定義基礎(chǔ)模型一年后,其他科技觀察家創(chuàng)造了一個(gè)與之相關(guān)的術(shù)語——生成式 AI。這個(gè)總括性的術(shù)語指 Transformer 、大型語言模型、擴(kuò)散模型等憑借創(chuàng)造文本、圖像、音樂、軟件等內(nèi)容的能力拓展人們想象力的神經(jīng)網(wǎng)絡(luò)。
風(fēng)投公司紅杉資本的高管在最近的 AI 播客節(jié)目中表示,生成式 AI 可能創(chuàng)造數(shù)萬億美元的經(jīng)濟(jì)價(jià)值。
基礎(chǔ)模型簡史
企業(yè)家兼 Google Brain 前高級(jí)研究科學(xué)家 Ashish Vaswani 表示:“我們已進(jìn)入到一個(gè)通過神經(jīng)網(wǎng)絡(luò)這樣的簡單方法就能成倍增加新能力的時(shí)代。”他曾領(lǐng)導(dǎo) 2017 年那篇關(guān)于 Transformer 的開創(chuàng)性論文的研究工作。
這篇論文啟發(fā)了創(chuàng)建 BERT 和其他大型語言模型的研究人員。2018 年末的一篇 AI 報(bào)告寫道,2018 年是自然語言處理的“分水嶺”。
谷歌將 BERT 作為開源軟件發(fā)布,催生了一系列后續(xù)產(chǎn)品并點(diǎn)燃了一場構(gòu)建更大、更強(qiáng)的大型語言模型的競賽。之后,谷歌將該技術(shù)應(yīng)用于其搜索引擎,使用戶可以使用簡單的句子提問。
2020 年,OpenAI 的研究人員發(fā)布了另一個(gè)具有里程碑意義的 Transformer—GPT-3。僅僅過了幾周,人們就用它來創(chuàng)作詩歌、程序、歌曲、網(wǎng)站等等。
研究人員表示:“語言模型對社會(huì)有著各種有益的用途。”
他們的工作也顯示了這些模型龐大的規(guī)模和計(jì)算量。GPT-3 是在一個(gè)含近萬億個(gè)單詞的數(shù)據(jù)集上訓(xùn)練的,并且擁有高達(dá) 1750 億個(gè)參數(shù)。而參數(shù)量是衡量神經(jīng)網(wǎng)絡(luò)能力和復(fù)雜性的一個(gè)關(guān)鍵指標(biāo)。
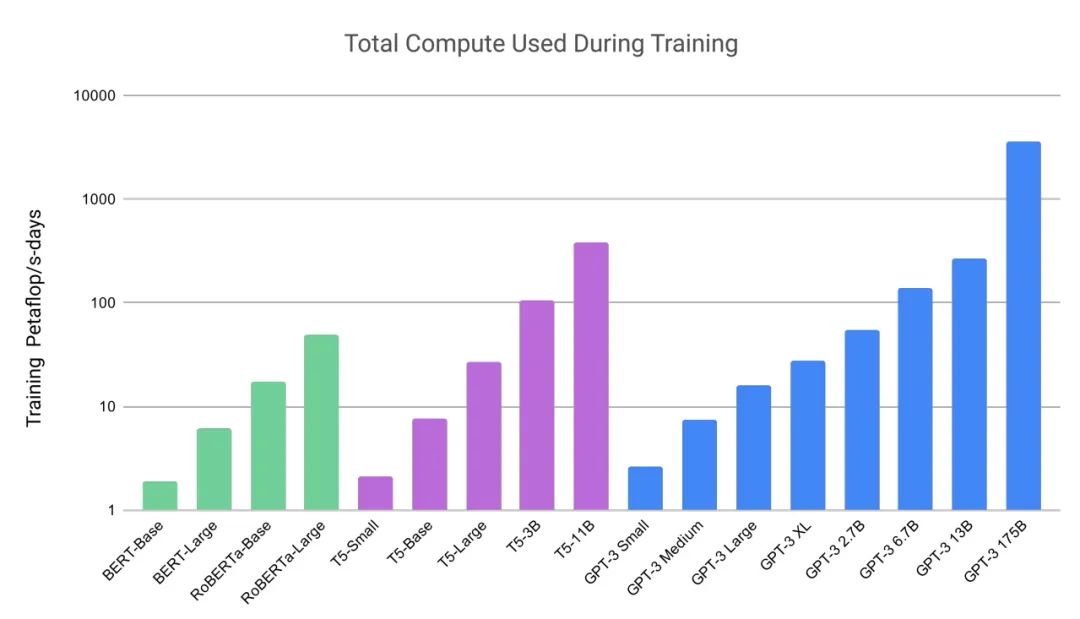
基礎(chǔ)模型算力需求的增長。
(來源:GPT-3論文)
Liang 在談到 GPT-3 時(shí)說道:“我只記得當(dāng)時(shí)我被它能做的事情嚇了一跳。”
而在 10000 個(gè) NVIDIA GPU 上訓(xùn)練而成的最新版本——ChatGPT 更加轟動(dòng),在短短兩個(gè)月內(nèi)就吸引了超過 1 億用戶。ChatGPT 幫助許多人了解了可以如何使用這項(xiàng)技術(shù),它的發(fā)布被稱為人工智能的“iPhone 時(shí)刻”。
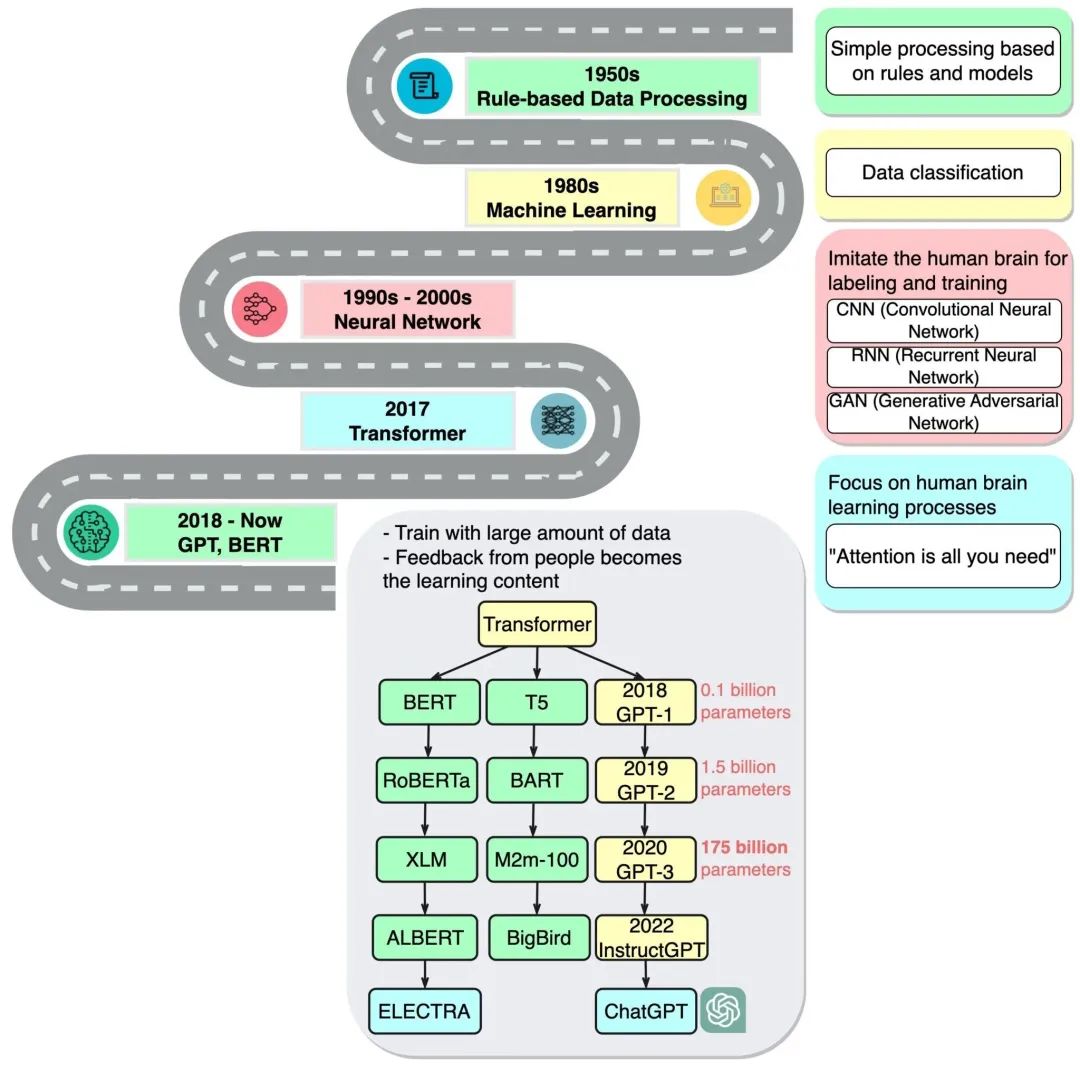
從早期 AI 研究到 ChatGPT 的時(shí)間線。
(來源:blog.bytebytego.com)
從文本到圖像
大約在 ChatGPT 首次亮相的同時(shí),另一類被稱為擴(kuò)散模型的神經(jīng)網(wǎng)絡(luò)也引起了轟動(dòng)。其將文本描述轉(zhuǎn)化為藝術(shù)圖像的能力吸引了眾多業(yè)余用戶用它們來創(chuàng)造驚艷的圖像并在社交媒體上瘋傳。
第一篇描述擴(kuò)散模型的論文在 2015 年悄無聲息地發(fā)布,但就像 Transformer 一樣,這項(xiàng)新技術(shù)很快就火遍全球。
根據(jù)牛津大學(xué) AI 研究員 James Thornton 維護(hù)的一份清單,研究人員去年發(fā)布了 200 多篇關(guān)于擴(kuò)散模型的論文。
Midjourney 首席執(zhí)行官 David Holz 透露,其基于擴(kuò)散模型的文本-圖像轉(zhuǎn)換服務(wù)已有 440 多萬用戶。他在一次采訪中表示,為這些用戶提供服務(wù)需要超過 1 萬顆 NVIDIA GPU,這些 GPU 主要用于 AI 推理。
數(shù)十種正在使用的模型
目前有數(shù)以百計(jì)的基礎(chǔ)模型。有一篇論文對 50 多個(gè)主要的 Transformer 模型進(jìn)行了編目和分類(見下方表格)。
斯坦福大學(xué)的研究小組對 30 個(gè)基礎(chǔ)模型進(jìn)行了基準(zhǔn)測試。他們表示,該領(lǐng)域的發(fā)展太快,以至于他們沒能在這次測試對一些最新和突出的模型進(jìn)行評估。
初創(chuàng)企業(yè) NLP Cloud 是領(lǐng)先初創(chuàng)企業(yè)培育計(jì)劃——NVIDIA 初創(chuàng)加速計(jì)劃的成員。該公司表示其在為航空公司、藥店和其他用戶服務(wù)的一項(xiàng)商業(yè)產(chǎn)品中使用了大約 25 個(gè)大型語言模型。專家們預(yù)計(jì),越來越多的模型將在如 Hugging Face 的模型中心等網(wǎng)站開放源碼。
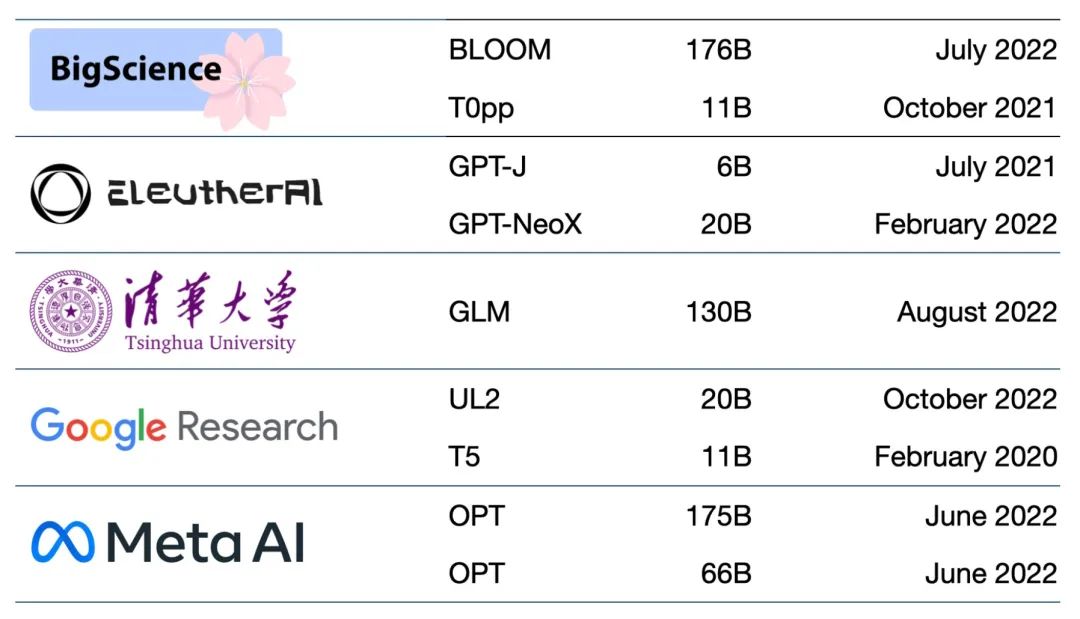
專家們指出,越來越多的基礎(chǔ)模型正在開放源碼。
基礎(chǔ)模型也在不斷變得更大、更復(fù)雜。所以許多企業(yè)已經(jīng)在定制預(yù)訓(xùn)練的基礎(chǔ)模型來加快向 AI 轉(zhuǎn)型的速度,而不是從頭開始構(gòu)建新的模型。
云中的基礎(chǔ)模型
一家風(fēng)險(xiǎn)投資公司列出了從廣告生成到語義搜索等 33 個(gè)生成式 AI 用例。
各大云服務(wù)使用基礎(chǔ)模型已經(jīng)有一段時(shí)間了。例如微軟 Azure 與 NVIDIA 一起為其 Translator 服務(wù)構(gòu)建了一個(gè) Transformer。該 Transformer 幫助救災(zāi)人員在應(yīng)對 7.0 級(jí)地震時(shí)理解海地克里奧爾語。
今年 2 月,微軟宣布計(jì)劃使用 ChatGPT 和相關(guān)創(chuàng)新來改進(jìn)其瀏覽器和搜索引擎,表示:“我們將這些工具視為網(wǎng)絡(luò)中的 AI 副駕駛。”
谷歌發(fā)布了實(shí)驗(yàn)性對話式 AI 服務(wù) Bard,計(jì)劃將其眾多產(chǎn)品與 LaMDA、PaLM、Imagen、MusicLM 等基礎(chǔ)模型相結(jié)合。
該公司的博客寫道:“AI 是我們今天正在研究的最具影響力的技術(shù)。”
初創(chuàng)企業(yè)也從中獲益
初創(chuàng)企業(yè) Jasper 預(yù)計(jì)其為 VMware 等公司編寫文案的產(chǎn)品將帶來 7500 萬美元的年收入。該企業(yè)正在領(lǐng)導(dǎo)由十幾家公司組成的文本生成領(lǐng)域,其中包括 NVIDIA 初創(chuàng)加速計(jì)劃成員 Writer。
該領(lǐng)域的其他初創(chuàng)加速計(jì)劃成員包括:位于東京的 rinna 和特拉維夫的 Tabnine。前者創(chuàng)造出了被日本數(shù)百萬人使用的聊天機(jī)器人;后者運(yùn)營的一項(xiàng)生成式 AI 服務(wù)將全球一百萬開發(fā)者所編寫的代碼中的 30%自動(dòng)化。
醫(yī)療平臺(tái)
初創(chuàng)企業(yè) Evozyne 的研究人員利用 NVIDIA BioNeMo 中的基礎(chǔ)模型生成了兩種新的蛋白質(zhì)。其中一種蛋白質(zhì)可以治療一種罕見的疾病,另一種可以幫助捕捉大氣中的碳。
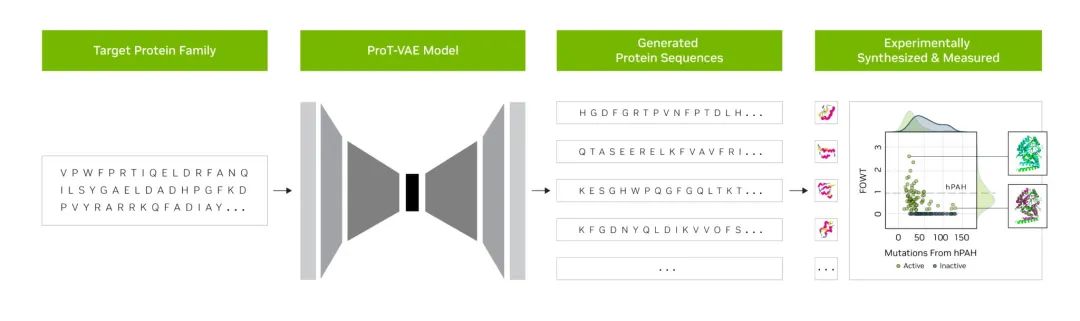
Evozyne 和 NVIDIA 在一篇聯(lián)合論文中描述了一種用于創(chuàng)建蛋白質(zhì)的混合基礎(chǔ)模型。
BioNeMo 是用于藥物研發(fā)的生成式 AI 軟件平臺(tái)和云服務(wù)。它提供各種用于訓(xùn)練、運(yùn)行推理和部署自定義生物分子 AI 模型的工具,包括由 NVIDIA 和阿斯利康聯(lián)合開發(fā)的化學(xué)生成式 AI 模型——MegaMolBART。
阿斯利康分子 AI、發(fā)現(xiàn)科學(xué)和研發(fā)部門主管 Ola Engkvist 在宣布該模型時(shí)表示:“正如 AI 語言模型可以學(xué)習(xí)句子中單詞之間的關(guān)系一樣,我們的目標(biāo)是讓在分子結(jié)構(gòu)數(shù)據(jù)上訓(xùn)練的神經(jīng)網(wǎng)絡(luò)能夠?qū)W習(xí)真實(shí)分子中原子之間的關(guān)系。”
佛羅里達(dá)大學(xué)的學(xué)術(shù)健康中心與 NVIDIA 研究人員聯(lián)合創(chuàng)建了大型語言模型 GatorTron,該模型能夠從大量臨床數(shù)據(jù)中提煉出加速醫(yī)學(xué)研究的洞察。
斯坦福大學(xué)的一座中心正在使用最新的擴(kuò)散模型來推進(jìn)醫(yī)學(xué)成像。NVIDIA 還幫助醫(yī)療公司和醫(yī)院將 AI 用于醫(yī)學(xué)影像,以便加快對致命疾病的診斷。
商業(yè) AI 基礎(chǔ)模型
另一個(gè)新框架 NVIDIA NeMo Megatron 旨在讓所有企業(yè)能夠創(chuàng)建自己的十億或萬億參數(shù) Transformer 來驅(qū)動(dòng)自定義聊天機(jī)器人、個(gè)人助手和其他 AI 應(yīng)用。
它創(chuàng)造了擁有 5300 億個(gè)參數(shù)的 Megatron-Turing 自然語言生成模型(MT-NLG)。該模型驅(qū)動(dòng)了 2022 年 NVIDIA GTC 大會(huì)上發(fā)表了部分主題演講的“Toy Jensen”虛擬化身。
與 NVIDIA Omniverse 等 3D 平臺(tái)相連的基礎(chǔ)模型將是讓 3D 互聯(lián)網(wǎng)——元宇宙的開發(fā)變得更加簡單的關(guān)鍵。這些模型將驅(qū)動(dòng)娛樂和工業(yè)用戶的應(yīng)用與資產(chǎn)。
工廠和倉庫已在數(shù)字孿生內(nèi)使用基礎(chǔ)模型,依靠這種逼真的模擬尋找更高效的工作方式。
基礎(chǔ)模型可以讓訓(xùn)練在工廠車間和物流中心協(xié)助人類的自動(dòng)駕駛汽車和機(jī)器人變得更輕松,還可以通過創(chuàng)造現(xiàn)實(shí)環(huán)境來幫助訓(xùn)練自動(dòng)駕駛汽車。
基礎(chǔ)模型每天都能出現(xiàn)新的用途,但隨之而來的還有應(yīng)用方面的挑戰(zhàn)。
有幾篇關(guān)于基礎(chǔ)和生成式 AI 模型的論文描述了一些風(fēng)險(xiǎn),比如:
放大用于訓(xùn)練模型的大量數(shù)據(jù)集內(nèi)所隱含的偏見
在圖像或視頻中加入不準(zhǔn)確或誤導(dǎo)性的信息
侵犯現(xiàn)有作品的知識(shí)產(chǎn)權(quán)
斯坦福大學(xué)的一篇關(guān)于基礎(chǔ)模型的論文寫道:“鑒于未來的 AI 系統(tǒng)可能會(huì)嚴(yán)重依賴基礎(chǔ)模型,我們整個(gè)行業(yè)必須共同為基礎(chǔ)模型制定更嚴(yán)格的原則并提供如何負(fù)責(zé)任地開發(fā)和部署基礎(chǔ)模型方面的指導(dǎo)。
目前的一些保障措施包括過濾提示和它們的輸出結(jié)果、在使用中重新校準(zhǔn)模型、清洗大規(guī)模數(shù)據(jù)集等。
NVIDIA 應(yīng)用深度學(xué)習(xí)研究副總裁 Bryan Catanzaro 表示:“這些都是我們這些研究人員正在努力解決的問題。為了真正能夠廣泛部署這些模型,我們必須在安全方面投入大量人力物力。”
這是 AI 研究人員和開發(fā)人員在創(chuàng)造未來的過程中所需要探索的又一個(gè)領(lǐng)域。
審核編輯 :李倩
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103443 -
AI
+關(guān)注
關(guān)注
88文章
35016瀏覽量
278822 -
模型
+關(guān)注
關(guān)注
1文章
3516瀏覽量
50348 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25408
原文標(biāo)題:什么是基礎(chǔ)模型?
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
FA模型卡片和Stage模型卡片切換
FA模型和Stage模型API切換概述
從FA模型切換到Stage模型時(shí):module的切換說明
FA模型綁定Stage模型ServiceExtensionAbility介紹
FA模型訪問Stage模型DataShareExtensionAbility說明
Stage模型啟動(dòng)FA模型PageAbility方法
如何將一個(gè)FA模型開發(fā)的聲明式范式應(yīng)用切換到Stage模型
KaihongOS操作系統(tǒng)FA模型與Stage模型介紹
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
【「大模型啟示錄」閱讀體驗(yàn)】營銷領(lǐng)域大模型的應(yīng)用
【「大模型啟示錄」閱讀體驗(yàn)】對大模型更深入的認(rèn)知
【「大模型啟示錄」閱讀體驗(yàn)】如何在客服領(lǐng)域應(yīng)用大模型
什么是大模型、大模型是怎么訓(xùn)練出來的及大模型作用







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論